L'Apprentissage Automatique dans le trading : théorie, modèles, pratique et trading algo - page 27
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Bonjour !
J'ai une idée, je veux la vérifier, mais je ne connais pas l'outil pour la mettre en œuvre... J'ai besoin d'un algorithme qui puisse prédire quelques points d'avance, disons 3 ou 5 (de préférence un réseau neuronal).
Bonjour !
J'ai une idée, je veux la vérifier, mais je ne connais pas l'outil pour la mettre en œuvre... J'ai besoin d'un algorithme qui serait capable de prédire pour quelques points d'avance, disons pour 3 ou 5 (de préférence un réseau neuronal).
Je n'ai travaillé qu'avec des classifications auparavant, donc je ne comprends même pas à quoi cela devrait ressembler, je ne peux pas conseiller quelqu'un sur la façon de le faire ou recommander un paquet en R.
p.s. Excellent article Alexey
Il s'agit de paquets qui extrapolent les tendances existantes, comme les prévisions. Les différentes cannelures sont très intéressantes.
Il semble assez solide.
Donc, aucun résultat utile ?
Lorsque j'ai exécuté l'algorithme pour la première fois, sur une petite quantité de données initiales, il n'y a pas eu de résultat positif, j'ai obtenu environ 50 % d'erreur avec le pca conscient de l'y et le pca simple. Maintenant, j'ai obtenu un ensemble plus complet de données de mt5 - presque tous les indicateurs standard avec tous leurs tampons, certains indicateurs sont répétés plusieurs fois avec différents paramètres. J'ai créé des conseillers-experts pour certains indicateurs et je les ai utilisés pour optimiser les paramètres des indicateurs afin de réaliser des transactions plus rentables. Sur de telles données, le simple pca fait toujours 50% d'erreur, mais avec y-aware, l'erreur dans le test frontal tombe sensiblement à 40%. Il est très intéressant de constater que l'algorithme y-aware prend simplement les données brutes et crée un classificateur qui fonctionne correctement dans 6 cas sur 10. Conclusion - vous avez besoin de plus de données brutes.
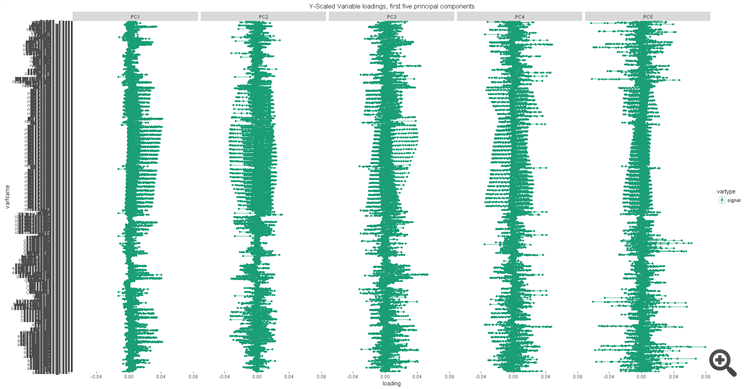
Mais c'est là que s'arrêtent tous les bons points. Il faut 73 composants standard pour une précision de 95 %. Les charges des prédicteurs dans les composantes fluctuent d'un niveau plus élevé à un niveau plus faible, sans qu'il y ait de leader clair. En d'autres termes, il n'existe aucune indication permettant de sélectionner certains prédicteurs. Le modèle fonctionne d'une manière ou d'une autre, mais on ne sait pas très bien ce qu'il faut en faire pour améliorer les résultats ou comment en tirer une utilité de prédicteur.
L'importance de la composante :
chargements des prédicteurs pour les 5 premières composantes :
ARIMA
Mais arima prend des décisions par séries temporelles et j'ai besoin que le modèle prenne des décisions à partir de mon ensemble de données, c'est-à-dire une matrice avec des prédicats et produise une prévision pour plusieurs barres à venir.
Personne ne vous empêchera de former un réseau neuronal avec plusieurs neurones de sortie - chacun pour un horizon de planification différent. En même temps, il sera intéressant d'observer les résultats.
Lorsque j'ai exécuté l'algorithme pour la première fois, sur une petite quantité de données initiales, il n'y a pas eu de résultat positif, j'ai obtenu environ 50 % d'erreur avec le pca conscient de l'y et le pca simple. Maintenant, j'ai obtenu un ensemble plus complet de données de mt5 - presque tous les indicateurs standard avec tous leurs tampons, certains indicateurs sont répétés plusieurs fois avec différents paramètres. J'ai créé des conseillers experts pour certains indicateurs et je les ai utilisés pour optimiser les paramètres des indicateurs afin d'obtenir des transactions plus rentables. Sur de telles données, le simple pca fait encore 50% d'erreur, mais avec y-aware, l'erreur dans le test frontal tombe sensiblement à 40%. Il est intéressant de constater que l'algorithme y-aware prend simplement les données brutes et crée un classificateur qui fonctionne correctement dans 6 cas sur 10. Conclusion - vous avez besoin de plus de données brutes.
Mais c'est là que s'arrêtent tous les bons points. Il faut 73 composants standard pour une précision de 95 %. Les charges des prédicteurs dans les composantes fluctuent d'un niveau plus élevé à un niveau plus faible, sans qu'il y ait de leader clair. En d'autres termes, il n'existe aucune indication permettant de sélectionner certains prédicteurs. Le modèle fonctionne d'une manière ou d'une autre, mais on ne sait pas ce qu'il faut en faire pour améliorer les résultats ou comment en tirer une utilité de prédicteur.
l'importance du composant :
Chargements des prédicteurs sur les 5 premières composantes :
l'a déjà fait, le réseau neuronal n'apprend pas sur un horizon plus large avec l'objectif que je lui ai fixé.
C'est bien qu'il n'ait pas appris, parce que vous apprenez sur le bruit. Mais si c'était le cas, ce serait un graal et il serait sur real.....
Je suis occupé ici à essayer d'éliminer le bruit. C'est pourquoi nous prenons tant de prédicteurs dans l'espoir que quelque chose subsiste.