Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 3091
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
según tengo entendido hay 4 parámetros a optimizar
Sin embargo, hay que tener en cuenta que estos valores pueden depender de la métrica de rendimiento elegida y del valor del umbral
Demasiado corto para entender qué son estos parámetros. aquí hay más del artículo página 13 (si el paquete reproduce completamente los métodos del artículo, pero quizás algo más añadido/sustraído)
Overfit statistics
El marco introducido en la Sección 2 nos permite caracterizar la fiabilidad-
bilidad delbacktest de una estrategia en términos de cuatro análisis complementarios:
1. Probability of Backtest Overfitting (PBO): La probabilidad de que laconfiguración del modelo
seleccionada como óptima IS tenga un rendimiento inferior al me-
diano de las N configuraciones del modelo OOS.
2. Degradación del rendimiento: Determina hasta qué punto un mayor per-
formance IS conduce a un menor rendimiento OOS, un hecho asociado
a los efectos de memoria analizados en Bailey et al. [1].
3. Probabilidad de pérdida: La probabilidad de que el modelo seleccionado como óptimo
IS produzca una pérdida OOS.
4. Dominancia estocástica: Este análisis determina si el pro-
cesoutilizado para seleccionar una estrategia IS es preferible a elegir al azar
una configuración de modelo entre las N alternativas.
A continuación se analiza cada punto con más detalle.
Es demasiado corto para entender lo que estos parámetros son. aquí hay más de la página 13 del artículo (si el paquete reproduce completamente los métodos en el artículo, pero tal vez algo más fue añadido / restado).
el paquete es simplemente horrible, nunca he visto tal partak en años
el código es terrible
la documentación es prácticamente inútil
no entiendo como llegó a CRAN.
Todavía no puedo entender, ¿hay un sistema de comercio se investiga dividido en lotes o se trata de varios TS (en esta biblioteca)?
Todavía no puedo entender, hay un sistema de comercio se estudia dividido en lotes o se trata de varios TS (en esta biblioteca).
Selección del mejor modelo entre un conjunto de modelos obtenidos con diferentes parámetros/hiperparámetros. La entrada es una matriz, donde cada columna es una previsión de uno de los modelos.
O tal vez no. Yo tampoco lo he averiguado todavíaSelección del mejor modelo entre el conjunto de modelos obtenidos con diferentes parámetros/hiperparámetros. La entrada es una matriz en la que cada columna es una predicción de uno de los modelos.
Esto ya lo he resuelto.
No entiendo cómo trabajar con el resultado
Doy una columna (una TS)
resultado
doy 5 columnas (cinco CT)
También obtengo una fila.
Debería haber 5 filas, o si es el resultado de la mejor TS, debería haber un mndex de la mejor....
Mataría a este autor
Selección del mejor modelo entre el conjunto de modelos obtenidos con diferentes parámetros/hiperparámetros. La entrada es una matriz en la que cada columna es una predicción de uno de los modelos.
O tal vez no. Yo tampoco lo he averiguado todavíaSe puede interpretar como tomar los retornos de beneficios TS de diferentes secciones de mercado (parámetros /hiperparámetros) ????
diferentes secciones de mercado == parámetros/hiperparámetros?
Puede interpretarse como la obtención de beneficios de TC de diferentes partes del mercado (parámetros/hiperparámetros ) ????
Exactamente profit retournals.
diferentes partes del mercado == parámetros/hiperparámetros?
Como entendí exactamente ajustes: diferentes períodos de MA, SL, etc..
También recibo una línea
Debería haber 5 líneas, o si es el mejor TC, debería haber un mndex de los mejores...
Como resultado, se obtiene la evaluación global del modelo (y probablemente de los datos predictores y objetivo)
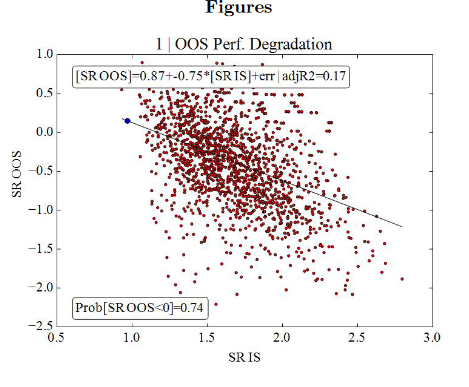
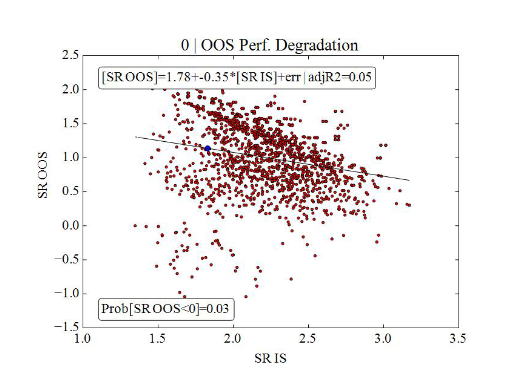
Un mal modelo da tales resultados (sólo el 17% de los resultados OOS por encima de 0).
Un buen modelo - 95% de resultados OOS por encima de 0
Son los retornados los que han llegado.
Ya sabes, ganancias y pérdidas, ¿verdad?
Así que tomamos los retornados de los estados cuando la posición está abierta.
Como yo lo entiendo, es la configuración: diferentes períodos de MA, SL, etc.
En lugar de diferentes ajustes de la TS, sólo voy a tomar el comercio en diferentes áreas, creo que se puede equiparar.
ya sabes, pérdidas y ganancias, ¿verdad?
Así que tomamos retournals de esos estados cuando la posición está abierta.
Si.
en lugar de diferentes configuraciones de TS solo tomare operaciones en diferentes secciones, creo que se puede equiparar.
No estoy seguro.
Y en general. leer el artículo para entender lo que está haciendo, hay limitaciones. Por ejemplo, es necesario dar obviamente ajustes exitosos, no -1000000 a +1000000. Si usted da todo en una fila, el promedio de OOS estará en la parte inferior y no tiene sentido comparar con él. Un rango muy estrecho de 0,95...,0,98 también es malo desde el punto de vista de la RD: los resultados serán muy parecidos.
sí
no estoy seguro.
Y en general. leer el artículo para entender lo que está haciendo, hay limitaciones. Por ejemplo, es necesario dar obviamente ajustes exitosos, no -1000000 a +1000000. Si usted da todo en una fila, el promedio de OOS estará en la parte inferior y no tiene sentido comparar con él. Un rango muy estrecho de 0,95...,0,98 también es malo - los resultados serán muy parecidos.
Entiendo que usted debe presentar un TS rentable y no cualquier cosa....
Ya he esbozado el algoritmo para probar esto, pero sólo hay un matiz con las métricas
¿Debo optimizar las 4 + 1 métricas?
O sólo