Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 1180
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Ivan Negreshniy, no entiendo, he creado el modelo en CatBoost, pero cómo se supone que se conecta, ¿es el puente/canal de EA a python, donde se pasarán los valores del predictor, y en la dirección opuesta se recibirá el resultado de los cálculos - una clase concreta?
Por lo que entiendo, CatBoost permite descargar un código del modelo que no entiendo, pero lo adjuntaré para estimación del profesional, a no ser que se pueda integrar en MQL de alguna manera y no usar python entonces? Y, CatBoost tiene librerías en C++, ¿no pueden hacerlas funcionar en MQL y no usar python y comandos de consola?
Lo que no está claro, el puente es necesario para la automatización de extremo a extremo del trabajo con los datos y los modelos directamente desde el Asesor Experto, incluyendo la creación, la configuración, la formación, etc. Y lo que CatBoost vuelca en los archivos es la serialización de un modelo particular, que puede ser utilizado sólo para los cálculos.
Por supuesto, se puede crear un EA basado en estos archivos en el editor, pero no será muy diferente de un EA habitual con una lógica rígida, y si este es el objetivo, IMHO, es mucho más fácil lograrlo a través de la formación utilizando plantillas, que sugerí. https://www.mql5.com/ru/forum/270216
Como todo lo que hay está entrenado y generado automáticamente, y el código de cada árbol se convierte en una función lógica separada, que puede ser más fácil de analizar y más rápida de ejecutar, si se completa, podemos comparar después.
En primer lugar, me cuesta mucho trabajo.
La mayoría de los predictores agrupan indicadores y los encajan en el ATR diario. El resto del trabajo de las series temporales son predictores de caracterización.
Tengo dos preguntas
1) Por favor, explique lo que significa - un montón deindicadores y encajarlos en el diario ATR.
2) ¿Por qué catbust? ¿Estás seguro de que es mejor que otros potenciadores?
Lo que no está claro aquí, el puente es necesario para la automatización de extremo a extremo de trabajar con datos y modelos directamente desde el EA, incluyendo la creación, configuración, formación, etc,
Ya veo, es decir, se trata principalmente de la posibilidad de crear tu propia interfaz para trabajar con la biblioteca MoD, ¿no? Esto equivale a que ahora estoy planeando hacer la misma interfaz pero a través de la activación de un archivo exe y la alimentación de comandos en él. En general, sí es interesante hacerlo a través de python, pero no tengo esos conocimientos, por desgracia.
y lo que CatBoost vuelca en los archivos es la serialización de un modelo específico, que sólo puede utilizarse para los cálculos.
Por supuesto, podemos crear un EA basado en estos archivos en el editor, pero no será muy diferente de un EA habitual con una lógica rígida, y si este es el objetivo, entonces IMHO, es mucho más fácil de lograr a través de la formación con la ayuda de plantillas, que sugerí. https://www. mql5.com/ru/forum/270216
Si entiendes este código, tal vez puedas decirme cómo traducirlo en forma legible, por ejemplo dando a cada regla una descripción acabada, como hago con las hojas después de procesar los modelos desde R
No puedo entender el algoritmo de encriptación en este código - ¿puede hacer su descripción / intérprete (tal vez por una cuota)?
Y si ese es el objetivo, en mi opinión, es mucho más fácil conseguirlo mediante el aprendizaje de patrones, que es lo que he sugerido. https://www.mql5.com/ru/forum/270216
Como allí todo se entrena y se genera automáticamente, y el código de cada uno de los árboles se convierte en función separada y lógica, que tal vez es más fácil para el análisis y más rápido en tiempo de ejecución, si se termina, podemos comparar más tarde.
El objetivo no es sólo obtener un modelo, sino obtener hojas, evaluarlas y luego generar nuevos modelos basados en estas hojas.
Yo estaba leyendo ese tema y no entiendo muy bien, el proceso de construcción de redes automáticas se creó sobre la base de los indicadores desnudos y el marcado, la información se transfiere a la plantilla, mientras que tengo el post-procesamiento de los indicadores, además de utilizar algunos de mis indicadores, que no quiero hacer público, por lo que resulta que el método no está disponible, y de nuevo - no se puede obtener hojas de ella ...
Tengo dos preguntas
1) Por favor, explique qué significaagrupar indicadores y encajarlos en el ATR diario
2) ¿Por qué catbust? ¿Está seguro de que es mejor que otros refuerzos? o andamios
1. esta es mi visión del mercado, es decir, el precio tiene un plan de movimiento, que se define por ATR al principio del día, entonces dependiendo de los obstáculos (niveles de resistencia (niveles de hacer / revisar las decisiones de negociación por los participantes del mercado), que son, incluyendo los indicadores), este plan se lleva a cabo o no. Los predictores describen estos obstáculos en relación con el plan de movimiento. Así que, esto es lo que parece gráficamente - una cuadrícula a lo largo del rango ATR con diferentes indicadores dentro
Capturas de pantalla de la plataforma MetaTrader
Si-9.18, M1, 2018.08.30
JSC ''Otkritie Broker'', MetaTrader 5, Real
Para la memoria
2. CatBoost - acaba de recibir ayuda para configurarlo. Además, es evidente que funciona más rápido que mi enfoque anterior de la creación de modelos en R y al mismo tiempo era más eficiente, hay documentación y comandos a través de DOS :) En comparación con otras herramientas, por ejemplo Deductor Studio, es más estable y los modelos salen mejor, además este último es de pago, aquí todo es gratis.
Tal vez le interese, me encontré con
Quiero hacer un sistema de optimización de árboles, más precisamente construyendo árboles con el optimizador... es un tema interesante, pero no sé por dónde empezar :))
https://explained.ai/
Gracias por la preocupación.
La barrera del idioma hace que la lectura sea insoportable, y los traductores hacen que el texto sea tonto o gracioso... por desgracia.
traduce una palabra a la vez, usando el plugin del traductor de google para chrome.
Yo uso el pluginImTranslator en chrome, funciona bien cuando traduces un párrafo de una vez, cuando seleccionas las palabras y haces clic con el botón derecho en el menú contextual
no es necesario hacer clic en Google
¿Qué tipo de plugin es? Antes funcionaba en Chrome, luego dejó de hacerlo y no sé cómo configurarlo.
Ya veo, es decir, es en primer lugar una oportunidad para crear su propia interfaz para trabajar con la biblioteca MoD, ¿verdad? Esto equivale a que ahora estoy planeando hacer la misma interfaz pero a través de la activación de un archivo exe y la alimentación de comandos en él. En general, sí es interesante hacerlo vía python, pero no tengo esos conocimientos, lamentablemente.
Si entiendes este código, puedes decirme cómo traducirlo en forma legible, por ejemplo, dando a cada regla una descripción acabada, por ejemplo, como hago para las hojas después de procesar los modelos desde R
No puedo entender el algoritmo de encriptación en este código - ¿puedes hacer su descripción/interpretación (tal vez por una tarifa)?
El objetivo no es sólo obtener un modelo, sino obtener hojas, evaluarlas y luego generar nuevos modelos basados en esas hojas.
He leído ese tema, pero no lo entiendo, el proceso de construcción de redes automáticas se creó sobre la base de los indicadores desnudos y el marcado, la información se transfiere a la plantilla, en mi caso hay un post-procesamiento de los indicadores, además de utilizar algunos de mis indicadores, que no quiero hacer público, por lo que resulta que el método no está disponible, y de nuevo - no se puede obtener hojas de ella ...
No entiendo por qué puede ser necesario editar manualmente las divisiones y las hojas que deciden los árboles, sí tengo todas las ramificaciones convertidas automáticamente en un operador lógico, pero sinceramente no recuerdo que yo mismo las haya corregido nunca.
Y en general, vale la pena cavar el código CatBoost, ¿cómo puedo saber con seguridad.
Por ejemplo, arriba puse a prueba en python mi red neuronal con aprendizaje por tabla de multiplicación por dos, y ahora la tomé para probar árboles y bosques (DecisionTree, RandomForest, CatBoost)
y aquí está el resultado - obviamente no está a favor de CatBoost, como dos veces dos es cero cinco...:)
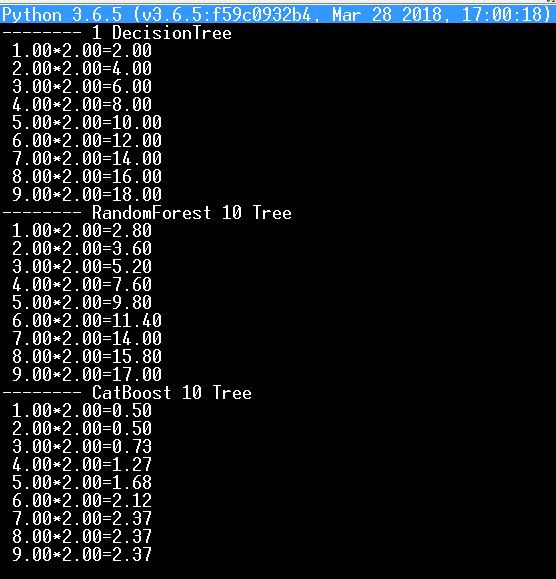
es cierto que si se toman miles de árboles, los resultados mejoran.No entiendo por qué es necesaria la edición manual de las divisiones y hojas de los árboles de decisión, sí tengo todas las ramas convertidas automáticamente en operadores lógicos, pero francamente no recuerdo, que alguna vez las haya corregido yo mismo.
Y en general vale la pena cavar el código de CatBoost, ¿cómo puedo saber con seguridad.
Por ejemplo, arriba puse a prueba en python mi red neuronal con aprendizaje por tabla de multiplicación por dos, y ahora la tomé para probar árboles y bosques (DecisionTree, RandomForest, CatBoost)
y aquí está el resultado - claramente no está a favor de CatBoost, como dos veces dos es cero cinco...:)
vamos, es imposible que forest o boosting no pueda con la tabla de multiplicar
Ni hablar, es imposible que un bosque o boosting no pueda con la tabla de multiplicar.