Hearst-Index - Seite 22
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
Ich bin verwirrt über Ihr "Kein einziger brauchbarer" nach den Worten "... und in der Literatur". In der Literatur gibt es viele verschiedene Ansätze, die leicht voneinander abweichende Ergebnisse liefern, was nicht verwunderlich ist, da es sich um Schätzungen handelt. Allerdings gilt auch: Je größer die Stichprobe ist, desto genauer sollten diese Schätzungen sein und desto "gleicher" sind sie untereinander. Ich würde nur zustimmen, dass ein funktionierender Hurst-Algorithmus in den Foren schwer zu finden ist.
Was in die Eingabe des Algorithmus einfließt, ist dem Algorithmus egal. Füttern Sie den Preis, und Sie werden etwas um einen bekommen. Für das Wesen des Algorithmus gilt, dass der Preis ein starkes Langzeitgedächtnis hat, da er relativ weit von den ursprünglichen Werten entfernt bleibt. Futtermittelpreiserhöhungen - Sie erhalten etwa 0,5, was wiederum gerechtfertigt ist, weil ihre relativen Veränderungen groß und fast zufällig sind. Trends und/oder Zyklen nähren - Ausdauer gewinnen. Rauschen reduziert im Allgemeinen den Index. Ich sehe, dass die Frage "Ist unser Preis verrauscht oder ein fairer Marktpreis?" nicht Gegenstand des Hearst-Algorithmus ist, das ist ein anderer Bereich.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Im Allgemeinen gilt: je länger, desto besser. Nach dem Algorithmus in Peters' Buch ist diejenige Länge besser, die die größte Anzahl ganzer Teiler hat.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Es werden zwei Modelle unterschieden:
1. Der Prozess hat einen "stabilen" Hurst-Index. Das heißt, der Index ist eine Konstante und ändert sich nicht mit der Zeit (während des gesamten Bestehens des Prozesses). In diesem Fall wird die Definition als ein Minimum - ein statistisch signifikantes Segment - genommen, d. h. ein Segment, das eine sichere Schätzung der Verteilung des Prozesses ermöglicht. Oder ohne sich die Mühe zu machen - in einem möglichst großen Segment.
2. Der Indikator ist eine Funktion, möglicherweise sehr komplex, möglicherweise zufällig. In diesem Fall gibt es keine objektiven Kriterien für die Auswahl der BP-Länge. Eine Schätzung des Index für den allgemeinen Fall ist weder im Zeit- noch im Frequenzbereich möglich, es sei denn, man ist ein Hellseher.
Wichtig ist, dass die RS-Analyse eine der gröbsten Methoden ist, dass ihre Schätzung immer verzerrt ist und dass der Stichprobenumfang in keiner Weise hilfreich ist. Um eine korrekte Berechnung des Hurst-Indexes zu erhalten, verwenden Sie eine Wavelet-basierte Schätzung (der Algorithmus ist z. B. in Mathlab zu finden).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
Hearst für Preis ist ~1, aber hier was?
Das Einzige, was ich in diesem Fall tun kann, ist darauf hinzuweisen, dass die Datei _hurst_classik keine Hurst- oder R/S-Analyse enthält. Die Bezeichnung "R/S" selbst dient dazu, die Zeile neu zu skalieren. Aber die _hurst_classik, die einen Anspruch auf _RS_Analiz hat, re-mastert nicht, sondern nimmt z.B. trivialerweise die Differenz zwischen Höchst- und Mindestpreis.
Außerdem berechnet die R/S-Analyse, um Hearst zu erreichen, die Steigung der Kurve und benötigt dafür viele Punkte auf der Ebene log(R/S) - log(n) anstelle von einem. In diesem Wunder _RS_Analiz gibt es so etwas nicht.
Der Hauptpunkt meines Beitrags war "BP-Modell identifizieren", aber das ist Ihnen nicht aufgefallen.
Wenn wir über Modelle der ARFIMA-Klasse oder ähnliches sprechen, bin ich wirklich nicht daran interessiert, denn diese Modelle sind wachsende "nakuya", deren Zweck es ist, Geld für Investmentfonds zu sammeln. Diese "Wissenschaft" wird als Kabinett-Wissenschaft bezeichnet, weil sie nur zu dem Zweck geschaffen wird, die wissenschaftliche Grundlage für ein bekanntes gewünschtes Ergebnis, in der Regel eine Preisvorhersage, zu optimieren.
Wenn wir über Modelle der ARFIMA-Klasse oder ähnliches sprechen, bin ich wirklich nicht daran interessiert, weil diese Modelle "naqui" wachsen, deren Zweck es ist, Geld für Investmentfonds zu sammeln. Diese "Wissenschaft" wird als Kabinett-Wissenschaft bezeichnet, weil sie nur zu dem Zweck geschaffen wird, einen wissenschaftlichen Rahmen an ein bewusst gewünschtes Ergebnis, in der Regel eine Preisvorhersage, anzupassen.
Lassen Sie uns keine Schätzungen vornehmen. Wir sprechen jetzt über Ansätze, die das BP-Modell verwenden, und solche, die es überhaupt nicht verwenden.HILFE BEI DER BERECHNUNG DES HEARST-INDIKATORS!!!*
*kleine Anmerkung: wie Peters
Ich habe den ganzen Thread von Anfang bis Ende gelesen: Ja, ich habe nicht erwartet, dass jeder, von angesehenen Akademikern bis hin zu gewöhnlichen Zuschauern, seine eigene Meinung darüber hat, was Hirst ist und wie er gezählt und interpretiert werden sollte. Am nächsten am Original war Eric Nyman in seinem Artikel und Buch. Aber... wir (in Russland sozusagen) haben immer noch kein adäquates Werkzeug für die Erstellung von Diagrammen, wie sie in Peters' Buch vorgestellt werden.
Ich habe also versucht, die Abfolge der Schritte, die Peters in seinem ersten Buch "Chaos und Ordnung in der Welt des Kapitals" beschrieben hat, so genau wie möglich nachzuahmen, um die R/S-Statistiken für den S&P 500 zu berechnen.
1. Wir nehmen die Monatscharts des S&P 500 vom 01.01.1950 bis zum 01.07.1988.
2. Wir laden sie in das technische Analyseprogramm (ich verwende WealthLab und C#, hier und im Folgenden werde ich den WL/C#-Code verwenden)
3. Rechnen Sie Preise in Renditen um, indem Sie die Formel aus Peters Buch verwenden: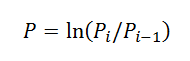
4. Peters selbst erwähnt nicht, dass die einmal errechneten Renditen wieder in eine kumulierte Reihe umgewandelt werden: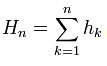 . Dies ist jedoch offensichtlich, basierend auf den R/S-Spread-Werten, die er hat, außerdem steht es auch ausdrücklich in der Quelle, ich zitiere: "Für jedes natürliche n setzen wir die Werte zusammen (siehe obige Formel) und berechnen die folgenden numerischen Merkmale der resultierenden Teilfolge".
. Dies ist jedoch offensichtlich, basierend auf den R/S-Spread-Werten, die er hat, außerdem steht es auch ausdrücklich in der Quelle, ich zitiere: "Für jedes natürliche n setzen wir die Werte zusammen (siehe obige Formel) und berechnen die folgenden numerischen Merkmale der resultierenden Teilfolge".
5. Die resultierende Reihe wird in k Perioden unterteilt, wobei die Länge jeder Periode N von 6 bis 231 Monaten oder Beobachtungen beträgt.
6. Dies ist ein wichtiger Punkt. Wird die ganzzahlige Anzahl von Perioden nicht erreicht (es bleiben ungenutzte Daten übrig), werden sie verworfen. Wenn der Rest jedoch zu groß ist (z. B. 462 / 232 = 233 und 230 im Rest), erhält man einen falschen Wert. Soweit ich weiß, verwendet Peters Verschiebungen, aber das ist eine sehr fummelige Option in Bezug auf die Programmierung, und ich verwerfe die Periode einfach, wenn ihr Rest größer als 6 ist. Da benachbarte Perioden fast den gleichen R/S-Wert haben, ist dies die richtige Option.
7. R wird dann anhand der Formel berechnet:
8. R wird durch die Standardabweichung (berechnet mit dem Indikator WL) geteilt und logarithmiert: log10(R/S).
9. Der aktuelle Zeitraum wird logarithmiert: log10(N);
10. Das erhaltene Verhältnis log10(R/S) zu log10(N) wird in die Datei geschrieben.
Wenn der Optimierer durch N von 6 (wie Peters) bis 231 (Mindestanzahl der Experimente ist 2) geht, dann erhalten wir eine Tabelle mit zwei Spalten in doppelt logarithmischer Skala: 1. Periode 2.
Jetzt beginnt der interessanteste Teil. Wenn Sie diese Tabelle in Excel grafisch darstellen, erhalten Sie das folgende Ergebnis:
Das Original ist auf der rechten Seite abgebildet. Wie Sie sehen können, gibt es eine gewisse Ähnlichkeit, aber dennoch nicht dasselbe. Insbesondere stellt sich heraus, dass die anfängliche Zahl leicht überschätzt ist (0,33 gegenüber etwa 0,31), und zweitens beginnen die endgültigen Werte plötzlich drastisch zu sinken, was im Prinzip nicht der Fall sein sollte. Seinem Diagramm zufolge sollte sich nur der Neigungswinkel am Ende der Reihe ändern, was darauf hindeutet, dass der Memory-Effekt begrenzt ist.
Bislang habe ich an dieser Stelle aufgehört. Ich habe noch nicht beschlossen, die U/V-Statistiken anzuwenden, da es nur teilweise Überschneidungen mit dem Original gibt.
Die Umrechnung der R/S-Werte in Hearst ergibt ebenfalls etwas überhöhte Ergebnisse. Wenn das Hearst-Ergebnis ist: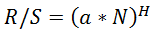 dann erhalten wir mit der Excel-Formel LOG(HERST(10;B1);C1*0,5), wobei B1 der aktuelle R/S-Wert ist.
dann erhalten wir mit der Excel-Formel LOG(HERST(10;B1);C1*0,5), wobei B1 der aktuelle R/S-Wert ist.
Nachfolgend finden Sie den WL/C#-Code zur Berechnung der R/S-Statistiken:
p.s. Lustig, MQL4 hat keine Schlüsselwörter wie overide und using, aber die Syntax noch hebt sie:)Gibt es eine Berechnung des Hurst-Indexes in Matcad (benötige Formeln in diskreter Form)?
Bislang habe ich nur dies gefunden
Datei mit Ansätzen zur Zeitreihenanalyse im Anhang. Von dort habe ich diese Formeln übernommen.
Entschuldigung, natürlich.
Ist es interessant? Wenn ich mir diese Formeln anschaue, sehe ich keinen Sinn darin, sie auf den Devisenmarkt anzuwenden.
Es ist einfacher, eine Serie zu erstellen, die den Devisenhandel beschreibt. Es gibt sie bereits, Menschen haben dafür Nobelpreise gewonnen. Aber das Ergebnis ist sehr durchschnittlich. Es ist immer notwendig, zuerst den Durchschnitt zu schätzen - den Fehler, und dann zu versuchen, die Minuspunkte von der Wahrscheinlichkeit in Verbindung mit den Fehlern zu entfernen, und dann, sich damit zu beschäftigen.
Entschuldigung, natürlich.
Also, ist es interessant? Wenn ich mir die Formeln ansehe, sehe ich überhaupt keinen Sinn darin, sie auf den Devisenmarkt anzuwenden.
Es ist einfacher, selbst eine Serie zu erstellen, die Forex beschreibt. Es gibt sie bereits, man hat einen Nobelpreis dafür bekommen. Aber das Ergebnis ist sehr, sehr mittelmäßig. Zuerst muss man immer den Durchschnitt - den Fehler - schätzen, und dann versuchen, die Minuspunkte der Wahrscheinlichkeit in Verbindung mit den Fehlern zu entfernen, und sich dann damit beschäftigen.
Entschuldigung. Aber für die Zukunft sollten wir uns darauf einigen, in diesem Thread keine müßigen Gedanken zu posten. Die einen interessieren sich für die "Forex-Reihe", die anderen für die Statistiken von Hearst. Jeder soll seinen eigenen Thread haben.
Ich poste eine Tabelle vom Typ CSV in doppelter logarithmischer Skala: Schätzung R/S bis Periode.