Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 1489
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Wenn jemand HMM versteht, dann bitte helfen Sie mir das Problem zu lösen, wenn das Problem lösbar ist, dann werde ich den Gral teilen)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Wenn jemand HMM versteht, dann bitte helfen Sie mir das Problem zu lösen, wenn das Problem lösbar ist, dann werde ich den Gral teilen)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Nun, der Zustand ist markovianisch, aber was ist das Modell?
das bedeutet, dass Sie mehr Punkte für das quadratische Fenster benötigen, mindestens
und wenn eine Zufallsreihe eingespeist wird, von welcher anderen Art von Vorhersage als 50\50 kann man dann sprechen?das bedeutet, dass Sie zumindest mehr Punkte für das quadratische Fenster benötigen
Ich habe Ihnen gesagt, dass ich sogar mehrere tausend Punkte genommen habe.
und wenn eine zufällige Reihe eingegeben wird, von welcher Art von Vorhersage außer 50/50 können wir dann sprechen?
Was macht das für einen Unterschied, die Daten sind dieselben, das Modell ist dasselbe
ich prognostiziere neue Daten mit der gesamten Funktion im Paket (wie in allen Beispielen im Netz ...) die Ergebnisse sind großartig
Ich verwende das gleiche Modell zur Vorhersage der gleichen Daten , aber mit gleitendem Fenster, und das Ergebnis ist anders, inakzeptabel.
Das ist die Frage - was ist das Problem?Ich habe Ihnen gesagt, dass ich sogar mehrere Tausend Punkte genommen habe.
Was macht das für einen Unterschied, die Daten sind dieselben, das Modell ist dasselbe
Ich prognostiziere neue Daten mit der gesamten Funktion in das Paket (wie in allen Beispielen auf dem Netz ...) die Ergebnisse sind groß
ich die gleichen Daten mit dem gleichen Modell in einem gleitenden Fenster vorhersage und das Ergebnis ist anders, inakzeptabel.
Das ist die eigentliche Frage - was ist das Problem?Ich weiß nicht, was für ein Modell Sie haben und woher Sie die Daten haben. ohne Pakete, was soll das bringen?
Vielleicht gibt es einen gcp, der keinen zufälligen Zustand ausgibt, deshalb wird er im ersten Fall vorhergesagt. Versuchen Sie, das Saatgut für Zug und Test zu ändern, um zu sehen, dass es im 1. Fall unmöglich ist, irgendetwas vorherzusagen, sonst weiß ich nicht, wie ich helfen kann, die Idee ist nicht klar
Die Aufteilung erfolgt auf der Grundlage der Klassifizierungswahrscheinlichkeit. Genauer gesagt, nicht nach der Wahrscheinlichkeit, sondern nach dem Klassifizierungsfehler. Denn bei der Trainingsübung ist alles bekannt, und wir haben keine Wahrscheinlichkeit, sondern eine genaue Schätzung.
Es gibt zwar unterschiedliche Trennungsfaktoren, d. h. Verunreinigungsmaße (linke oder rechte Probenahme).
Ich habe mich auf die Verteilung der Klassifizierungsgenauigkeit über die Stichprobe bezogen, nicht auf die Gesamtzahl, wie es jetzt gemacht wird.
Es ist nicht klar, um welches Modell es sich handelt und woher Sie die Daten beziehen. Was ist der Sinn, wenn es keine Pakete gibt?
Vielleicht gibt es einen gcp, der keine Randomisierung gibt, deshalb wird er im 1. Fall vorhergesagt. Versuchen Sie, das Saatgut sowohl für train als auch für test zu ändern, um zu sehen, ob es auch im ersten Fall unmöglich ist, eine Vorhersage zu treffen.
Hier ist die Datei, es gibt Preise und zwei Spalten mit Prädiktoren "data1" und "data2".
Sie trainieren ein HMM mit nur zwei Zuständen(auf einer Datenspur ohne Lehrer) für diese beiden Spalten ("data1" und "data2") in Python oder wie auch immer. Sie fassen den Preis nicht an, aber Sie tun es zur Visualisierung
Dann nimmt man den Viterbi-Algorithmus und entwickelt einen (Datentest).
erhalten wir zwei Zustände, die wie folgt aussehen sollten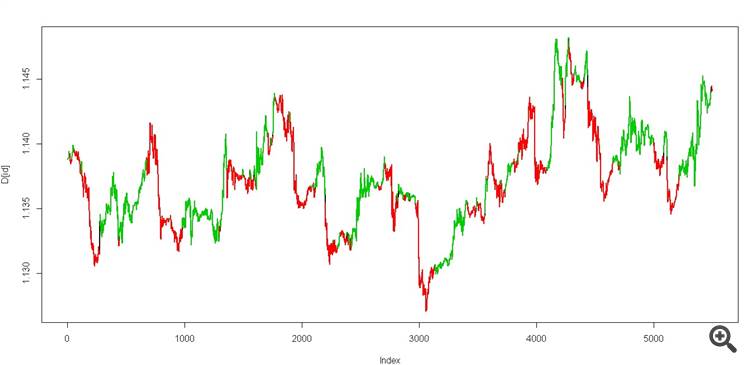
es ist ein echter Gral))
Versuchen Sie dann, den gleichen Viterbi im gleitenden Fenster mit den gleichen Daten zu berechnen
Hier ist eine Datei mit Preisen und zwei Spalten mit Prädiktoren "data1" und "data2".
Sie trainieren ein HMM mit nur zwei Zuständen(auf einer Datenspur) unter Verwendung dieser beiden Spalten ("data1" und "data2") in Python oder einer anderen Programmiersprache. Sie fassen den Preis überhaupt nicht an, sondern verwenden ihn nur zur Visualisierung.
Dann nimmt man den Viterbi-Algorithmus und (Datentest)
erhalten wir zwei Zustände, die wie folgt aussehen sollten
Das ist ein echter Gral.)
Versuchen Sie dann die gleiche Viterbi-Berechnung im gleitenden Fenster mit den gleichen Daten
Senk, ich schaue mir das später an, ich sage dir Bescheid, denn ich arbeite mit einem Markovianer.
senk, ich werde mir das später ansehen und Ihnen Bescheid geben, da ich selbst mit Markovs arbeite.
Glück gehabt?
Glück gehabt?
Noch nicht auf der Suche, freier Tag ) Ich werde es Ihnen mitteilen, wenn ich Zeit habe, später in der Woche, meine ich.
Ich habe mir die Pakete bis jetzt angesehen. Ich denke, es passt zuhttps://hmmlearn.readthedocs.io/en/latest/tutorial.html