Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 851
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
2 Klassen
Geladen 1 Kern
Einstellung , rfeControl = rfeControl(number = 1,repeats = 1) - reduzierte Zeit auf 10-15 Minuten. Änderungen in den Ergebnissen - 2 Paare von Prädiktoren wurden ausgetauscht, aber im Großen und Ganzen sind sie ähnlich wie die Standardwerte.
Na bitte, deine 10 Minuten auf einen Kern sind meine 2 auf 4, und zwei Minuten kann ich mir nicht merken.
Ich warte nie stundenlang auf etwas, wenn 10-15 Minuten nicht funktionieren, dann stimmt etwas nicht, und mehr Zeit zu investieren, bringt nichts. Jede Optimierung bei der Erstellung eines stundenlangen Modells ist eine völlige Verkennung der Modellierungsideologie, die besagt, dass das Modell so grob wie möglich und auf keinen Fall so genau wie möglich sein sollte.
Nun zur Auswahl der Prädiktoren.
Warum tun Sie das und warum? Welches Problem versuchen Sie zu lösen?
Das Wichtigste bei der Auswahl ist der Versuch, das Problem der Umschulung zu lösen. Ist Ihr Modell übertrainiert? Wenn nicht, kann die Auswahl das Lernen beschleunigen, indem die Anzahl der Prädiktoren reduziert wird. Eine Verringerung der Anzahl ist jedoch viel effektiver, wenn die Hauptkomponenten isoliert werden. Sie haben keine Auswirkungen, aber sie können die Anzahl der Prädiktoren um eine Größenordnung reduzieren und damit die Geschwindigkeit der Modellanpassung erhöhen.
Zunächst einmal: Warum brauchen Sie es?
Ich habe ein weiteres interessantes Paket zum Herausfiltern von Prädiktoren gefunden. Er wird FSelector genannt. Es bietet etwa ein Dutzend Methoden zum Herausfiltern von Prädiktoren, einschließlich Entropie.
Ich habe eine Datei mit Prädiktoren und einem Ziel von hier genommen -https://www.mql5.com/ru/forum/86386/page6#comment_2534058
Die Bewertung des Prädiktors nach jeder Methode habe ich in der Grafik am Ende dargestellt.
Blau ist gut, rot ist schlecht (für den Corrplot wurden die Ergebnisse auf [-1:1] skaliert, für die genaue Auswertung siehe Ergebnisse von cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable) usw.)
Sie können sehen, dass X3, X4, X5, X19, X20 von fast allen Methoden gut bewertet werden, Sie können mit ihnen beginnen und dann versuchen, weitere hinzuzufügen/zu entfernen.
Die Modelle in Rattle haben jedoch den Test mit diesen 5 Prädiktoren auf Rat_DF2 nicht bestanden, auch hier ist kein Wunder geschehen. D.h. selbst mit den verbleibenden Prädiktoren müssen Sie die Modellparameter anpassen, eine Kreuzvalidierung durchführen und selbst Prädiktoren hinzufügen/entfernen.
Ich habe dasselbe mit CORElearn gemacht und dabei Daten aus Vladimirs Artikeln verwendet.
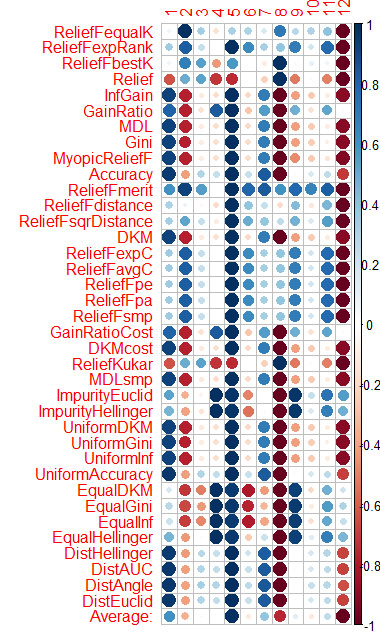
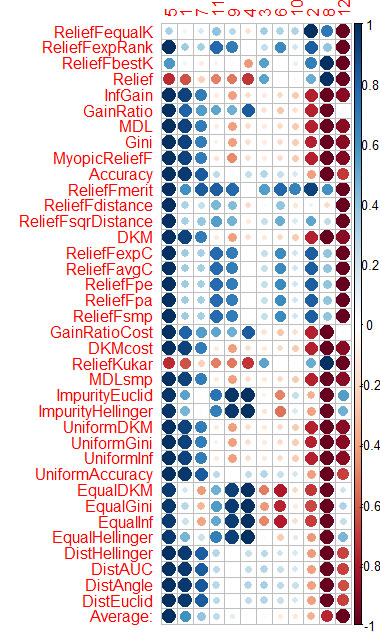
Ich habe den Durchschnitt der Spalten berechnet (die unterste Zeile ist Durchschnitt) und danach sortiert. Auf diese Weise ist es einfacher, die gesamte Bedeutung wahrzunehmen.
Es dauerte 1,6 Minuten - und das bei 37 bearbeiteten Algorithmen. Die Geschwindigkeit ist viel besser als bei Caret (16 Minuten), mit ähnlichen Ergebnissen.
Ich habe dasselbe mit CORElearn gemacht und dabei Daten aus Vladimirs Artikeln verwendet.
Ich habe den Durchschnitt nach Spalten berechnet (die unterste Zeile Durchschnitt) und danach sortiert. Auf diese Weise ist es einfacher, die gesamte Bedeutung wahrzunehmen.
Es dauerte 1,6 Minuten, und es waren 37 Algorithmen erforderlich.
Was ist also das Fazit? Haben Sie die Frage nach der Bedeutung der Prädiktoren beantwortet oder nicht, denn ich verstehe diese Bilder überhaupt nicht.
Für mich ist es jetzt überhaupt kein Problem mehr, ein Modell zu erstellen und auszuwählen. Ich wähle Prädiktoren aus, dann erstelle ich 10 Modelle auf der Grundlage dieser Prädiktoren, und dann wählt die gegenseitige Information dasjenige aus, das am besten funktioniert. Wissen Sie, wie man das macht? Es ist eine mentale Herausforderung!!! Also gut, wer immer das Problem löst, ist der Beste !!!!!
Es ist mir gelungen, eine Reihe von Modellen zu bekommen. Und eigentlich vporez: Welches der Modelle funktioniert und warum??????
Oder besser gesagt, sie funktionieren alle, aber nur einer von ihnen kann wählen. Und warum?
Was ist also das Fazit? Haben Sie die Frage nach der Bedeutung der Prädiktoren beantwortet oder nicht, denn ich verstehe diese Bilder überhaupt nicht.
Für mich ist es jetzt überhaupt kein Problem mehr, ein Modell zu erstellen und auszuwählen. Ich wähle Prädiktoren aus, erstelle daraufhin 10 Modelle und wähle dann anhand der gegenseitigen Informationen dasjenige aus, das am besten funktioniert. Wissen Sie, wie man das macht? Es ist eine mentale Herausforderung!!! Also gut, wer immer das Problem löst, ist der Beste !!!!!
Es ist mir gelungen, eine Reihe von Modellen zu bekommen. Und eigentlich vporez: Welches der Modelle funktioniert und warum??????
Oder besser gesagt, sie funktionieren alle, aber nur einer von ihnen kann wählen. Und warum?
Vtreat sortiert die Prädiktoren sehr ähnlich (wichtig zuerst)
5 1 7 11 4 10 3 9 6 2 12 8
Und hier ist die Sortierung nach Mittelwert in CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
Ich glaube nicht, dass ich mir die Mühe machen werde, weitere Prädiktorauswahlpakete zu verwenden.
Vtreat ist also ausreichend. Allerdings wird die Interaktion der Prädiktoren nicht berücksichtigt. Wahrscheinlich auch.
Es treibt mir die Tränen in die Augen, wenn ich sehe, dass Sie immer wieder die Bedeutung von Prädiktoren für einige Teile der Marktgeschichte hervorheben. Warum? Das ist eine Entweihung der statistischen Methoden.
In der Praxis hat sich gezeigt, dass der Fehler von 30 % auf fast 50 % ansteigt, wenn Prädiktor Nummer 2 in das NS eingespeist wird.
und beim OOS, wie ändert sich der Fehler?
Wie ändert sich der Fehler beim OOS?
in ähnlicher Weise. Wie in Vladimirs Artikel - die Daten stammen von dort.
Was ist, wenn es sich um ein anderes OOS handelt?
In der Praxis habe ich festgestellt, dass der Fehler von 30 % auf fast 50 % ansteigt, wenn man den NS mit Prädiktor Nummer 2 füttert.
Geben Sie die Prädiktoren ein und speisen Sie die normalisierten Zeitreihen in das NS ein. Der NS wird die Prädiktoren selbst finden - +1-2 Schichten, und schon haben Sie es