
Нейросети — это просто (Часть 44): Изучение навыков с учетом динамики

Введение
При решении задач прогнозирования в сложном стохастическом окружении довольно сложно, а часто и невозможно, обучить какую-то одну модель, которая бы демонстрировала приемлемые результаты в работе вне обучающей выборки. В то же время разбитие задачи на более мелкие подзадачи значительно повышает результативность совокупной модели. В предыдущих статьях мы уже познакомились с построением иерархических моделей. Их архитектура позволяет разделить решение задачи на несколько подзадач. И каждая подзадача будет решаться отдельной более простой моделью. И здесь возникает вопрос корректного обучения навыков, которые легко можно идентифицировать по поведению модели в том или ином состоянии.
В предыдущей статье мы познакомились с методом DIAYN, который позволяет обучить разделимые навыки. Что позволяет построить модель, способную изменять поведение агента в зависимости от текущего состояния. Напомню, что алгоритмом DIAYN предусмотрено вознаграждение за непредсказуемое поведение. Это позволяет обучить навыки с максимально разнообразным поведением. Но есть и обратная сторона медали. Подобные навыки становятся плохо прогнозируемыми. А это осложняет процесс планирования и управления агентом.
В этой парадигме становится вопрос обучения навыков, поведение которых было бы легко предсказуемым. При этом мы не готовы пожертвовать разнообразием их поведения. Подобная задача решается авторами метода Dynamics-Aware Discovery of Skills (DADS), который был представлен миру в 2020 году. В отличие от DIAYN, метод DADS стремится обучить навыки, которые не только обладают разнообразием в поведении, но также являются предсказуемыми.
1. Обзор архитектуры и основных шагов DADS
Изучение множества отдельных поведений и соответствующих изменений окружающей среды позволяет использовать модельно-предиктивное управление для планирования в пространстве поведения, а не в пространстве действий. В этой связи основной вопрос заключается в том, как мы можем получить такие поведения, учитывая, что они могут быть случайными и непредсказуемыми? Метод Dynamics-Aware Discovery of Skills (DADS) предлагает систему бесконтрольного обучения с подкреплением для изучения низкоуровневых навыков с явной целью облегчить модельно-основанное управление.
Навыки, полученные с использованием DADS, напрямую оптимизируются для предсказуемости, обеспечивая лучшее представление, на основе которого можно изучать прогностические модели. Ключевой особенностью навыков является то, что они приобретаются полностью через автономное исследование. Это означает, что репертуар навыков и их предиктивная модель изучаются до того, как осуществляется постановка задачи и разработка функции вознаграждения. Таким образом, при достаточном количестве можно довольно полно изучить окружающую среду и выработать навыки поведения в ней.
Как и в методе DIAYN, в процессе обучения навыком алгоритмом DADS используются 2 модели: модель навыков (агент) и дискриминатор (модель динамики навыков).
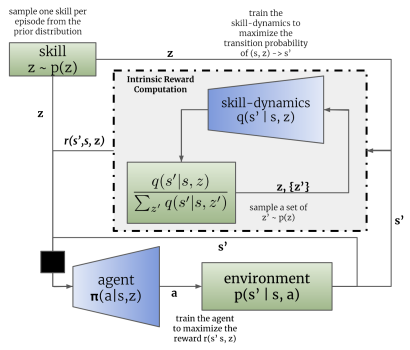
Обучение моделей осуществляется последовательно и итерационно. Сначала обучается дискриминатор прогнозировать будущее состояния на основании текущего состояния и используемого навыка. Для этого на вход модели агента подаются текущее состояние и one-hot вектор идентификации навыка. Агентом генерируется действие, которое выполняется в окружающей среде. В результате осуществления действия агент переходит в новое состояние окружающей среды.
В свою очередь дискриминатор на основании тех же самых исходных данных пытается спрогнозировать новое состояние окружающей среды. В данном случае работа дискриминатора напоминает работу ранее рассмотренного атоэнкодера. Только в данном случае декодер восстанавливает из латентного состояния не исходные данные, а прогнозирует следующее состояние. И так же, как мы обучали автоэнкодеры, мы обучаем дискриминатор методом градиентного спуска.
Как можно заметить, здесь кроется первое различие алгоритмов DIAYN и DADS. В DIAYN на основании нового состояния мы определяли навык, который нас привел в это состояние. Дискриминатор DADS выполняет обратный функционал. На основании исходных данных и известного навыка он прогнозирует последующее состояние окружающей среды.
Здесь надо отметить, что процесс итерационный. Поэтому мы не пытаемся сразу достигнуть максимального правдоподобия. В то же время, для обучения агента нам потребуются хотя бы первичное приближение.
После первого пакета итераций обучения дискриминатора мы переходим к обучению агента (модели навыков). Сразу скажем, что для обучения дискриминатора и агента используются различные пакеты исходных данных. Однако это не означает о необходимости создания отдельных обучающих выборок. Мы используем один и тот же буфер воспроизведения опыта. Только на каждой итерации мы случайным образом формируем 2 отдельных пакета обучающих данных из этого буфера.
Аналогично методу DIAYN, обучение модели навыков осуществляется методами обучения с подкреплением на основании вознаграждения генерируемым дискриминатором. Отличие, как всегда, в деталях. В DADS используется другая математическая формула для формирования вознаграждения. Я не буду сейчас останавливаться на всех математических выкладках и обосновании подхода. Вы можете ознакомиться с ними в оригинальной статье. Остановлюсь лишь на финальной формуле вознаграждения.
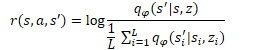
В представленной формуле q(s'|s,z) представляет собой выход дискриминатора для отдельно взятых исходного состояния s и навыка z. А L определяет количество навыков. Таким образом, в числителе формулы вознаграждения мы видим прогнозное состояние для анализируемого навыка. А в знаменателе среднее прогнозное состояние для всех возможных навыков.
Использование подобной функции вознаграждения позволяет решать поставленную выше задачу. Так как в числителе мы используем прогнозное состояние для текущего навыка, то мы и вознаграждаем такое действие агента, которое ведет к достижению прогнозного состояния. Этим достигается прогнозируемость поведения навыков.
В то же время, использование в знаменателе среднего состояния для всех возможных навыков позволяет нам вознаграждать больше такое поведение навыка, которое будет максимально отличаться от среднестатистического.
Таким образом, в методе DADS достигается баланса между предсказуемостью и разнообразием навыков. Это позволяет обучать навыки, которые обладают структурированным и предсказуемым поведением, одновременно сохраняя способность к исследованию окружающей среды.
Нужно обратить внимание на тот момент, что поведение обратной связи от дискриминатора и обучения модели навыков ведет к изменению поведения агента. И как следствие, его поведение будет отличаться от примеров, накопленных в буфере воспроизведения опыта. Поэтому, для достижения оптимального результата мы и используем итерационный процесс с последовательным обучением дискриминатора и агента. В ходе которого процесс обучения модель повторяется несколько раз. Кроме того, авторы метода при обучении дискриминатора предлагают использовать коэффициент важности, который определяется отношением вероятности выполнения действия с использованием текущей политики агента к вероятности выполнения этого действия в буфере воспроизведения опыта. Это позволяет больше внимания уделять устоявшемуся поведению агента. При этом будет нивелироваться влияние случайных действий.
Следует отметить, что метод DADS изначально был предложен для обучения навыков и создания модели окружающей среды. Как можно заметить, обучение прогнозируемых навыком и модели динамик, позволяющей прогнозировать с достаточной долей вероятности новое состояние окружающей среды, позволяет осуществлять планирование на несколько шагов вперед. При этом в процессе планирования можно перейти от конкретных действий к оперированию более обобщающим понятием навыков. А конкретные действия будут определяться агентом в соответствии с запланированным навыком.
Однако, на данном этапе я не рискнул переходить к долгосрочному планированию и остановился на обучении планировщика для определения навыка на каждый отдельный шаг, как и было реализовано в предыдущей статье.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода Dynamics-Aware Discovery of Skills мы переходим к практической реализации алгоритма. И прежде, чем перейти непосредственно к реализации алгоритма, мы определимся с архитектурой моделей.
В своей реализации мы будем использовать 3 модели, как и в случае реализации метода DIAYN. Это агент (модель навыков), дискриминатор (модель динамик) и планировщик.
Алгоритмом предусматривается, что агент на основании текущего состояния и выбранного навыка определяет действие к выполнению. Следовательно, размер слоя исходных данных должен быть достаточным для записи вектора описания текущего состояния и one-hot вектора идентификация выбранного навыка.
На выходе агента мы получаем вектор вероятностного распределения пространства возможных действий. Как можно заметить, исходные данные, функционал и результат Агента полностью аналогичны соответствующим характеристикам Агента метода DIAYN. В данной реализации мы оставим и архитектуру Агента без изменений. Это позволит нам на практике сравнить работу 2 рассмотренных методов обучения навыков. Однако, это вовсе не означает, что не может быть использована другая архитектура модели.
Напомню, в архитектуре агента мы использовали слой пакетной нормализации для приведения исходных данных в сопоставимый вид.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Нормализованные данные обрабатываются блоком из 2 сверточных и подвыборочного слоя, что позволяет выделить отдельные паттерны и тренды в исходных данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Обработанные данные после сверточных слоев передаются в блок принятия решений, который содержит полносвязные слои и полностью параметризированную квантильную модель FQF.
Использование FQF на выходе блока принятия решений позволяет нам получить более точные прогнозы вознаграждений после совершения действий. Которые учитывают не только их среднее значение, но и вероятностное распределение с учетом стохастичности окружающей среды.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Как уже было сказано выше, в данной реализации мы не стали создавать модель окружающей среды для построения прогнозов на несколько шагов вперед. Мы, как и ранее, будем определять используемый навык на каждом шагу. Поэтому архитектуру и подходы к обучению планировщика мы также оставили без изменений. Здесь мы используем слой пакетной нормализации для приведения сырых исходных данных в сопоставимый вид. Блок принятия решений состоит из полносвязных слоев и модели FQF. А его результаты переводятся в область вероятностного распределения с помощью слоя SoftMax.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
А вот в архитектуру модели дискриминатора мы внесли изменения. Напомню, что алгоритмом DADS в качестве дискриминатора используется модель Динамик. Согласно рассматриваемого алгоритма она должна спрогнозировать новое состояние окружающей среды на основании текущего состояния и выбранного навыка. Также модель Динамик в методе DADS используется для прогнозирования будущих состояний при построении планов на несколько шагов вперед. Н,о как уже было сказано выше, мы не будем строить длительных планов. А значит, мы можем немного отклониться от прогнозирования всех показателей будущего состояния окружающей среды. Как вы знаете, описание состояния окружающей среды у нас состоит из 2 больших блоков:
- исторических данных ценового движения и показателей анализируемых индикаторов
- показатели текущего состояния счета.
Влияния отдельно взятого трейдера на состояние финансового рынка настолько ничтожно, что им можно пренебречь. Следовательно, действия нашего агента не оказывают влияния на исторические данные. А значит, логично их исключить из формировании внутреннего вознаграждения при обучении нашего Агента. А так как мы не будем строить далеко идущих планов, то и прогнозирование этих показателей не имеет смысла. Таким образом, для формирования внутреннего вознаграждения нам достаточно спрогнозировать показатели будущего состояния счета.
Следует обратить внимание ещё на один момент. Посмотрите на формулу формирования внутреннего вознаграждения Агента. В ней помимо прогнозного состояния для анализируемого навыка используется ещё и среднее прогнозное состояние для всех возможных навыков. А значит для определения одного вознаграждения нам предстоит спрогнозировать будущие состояния для всех навыков. С целью ускорения процесса обучения моделей было принято решения о создании многоголового выхода модели. Когда на основании только одних исходных данных модель будет возвращать прогнозные состояния для всех возможных навыков.
Таким образом, слой исходных данных модели Дискриминатора сопоставим с аналогичным слоем модели Планировщика и должен быть достаточным для записи описания состояния системы без учета выбранного навыка.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; }
Полученные исходные данные проходят первичную обработку в слое пакетной нормализации и передаются в блок принятия решения, состоящий из полносвязного перцептрона.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; }
На выходе модели также используется полносвязный слой. Его размер равен произведению количества обучаемых навыков на количество элементов для описания одного состояния системы. В данном случае мы указываем количество элементов описания состояния счета.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills*AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; }
Стоит отметить, что хотя мы и определились в предыдущей статье использовать относительные значения показателей описания состояния счета, тем не менее данные значения не представляются нормализованными. И при их прогнозировании мы не можем использовать какую-либо одну функцию активации. Поэтому на выходе модели дискриминатора используется нейронный слой без функции активации.
Полный код описания архитектур всех используемых моделей собран в функции CreateDescriptions, которая вынесена в файл библиотеки "Trajectory.mqh". Перенос данной функции из файла советника в файл библиотеки позволяет использовать одну архитектуру моделей на всех стадиях обучения и исключает необходимость ручного копирования описания архитектуры моделей между советниками.
В процессе обучения моделей и тестирования полученных результатов мы будем использовать 3 советника. Аналогично обучению моделей методом DIAYN. Советник сбора первичных данных для обучения моделей "Research.mq5" был перенесен полностью практически без изменений. Изменения коснулись лишь названия файла для записи моделей и описанных выше архитектурных решений. С полным кодом советника можно познакомиться во вложении.
Основные же изменения для реализации алгоритма DADS были внесены в советник обучения моделей "Study.mq5". Прежде всего это контроль соответствия архитектуры моделей предварительно объявленным константам, который осуществляется в методе OnInit. Здесь подстроили контроли под измененные архитектуры моделей.
Discriminator.getResults(DiscriminatorResult); if(DiscriminatorResult.Size() != NSkills * AccountDescr) { PrintFormat("The scope of the discriminator does not match the skills count (%d <> %d)", NSkills * AccountDescr, Result.Total()); return INIT_FAILED; } Scheduler.getResults(SchedulerResult); Scheduler.SetUpdateTarget(MathMax(Iterations / 100, 500000 / SchedulerBatch)); if(SchedulerResult.Size() != NSkills) { PrintFormat("The scope of the scheduler does not match the skills count (%d <> %d)", NSkills, Result.Total()); return INIT_FAILED; } Actor.getResults(ActorResult); Actor.SetUpdateTarget(MathMax(Iterations / 100, 500000 / AgentBatch * NSkills)); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Ну и конечно, довольно крупные изменения внесены в метод обучения моделей Train. Для начала мы рассмотрим 2 новых вспомогательных метода. Первый метод GetNewState. В теле данного метода мы будем формировать расчетное состояние показателей баланса на основании предыдущего состояния счета, планируемого действия и известного "будущего" движения цены.
Хочу обратить внимание, что в методе определяется именно расчетное состояние баланса, а не прогнозное. За игрой слой кроется большой смысл. Прогнозное значение показателей баланса осуществляется моделью Динамик (Дискриминатором). А в рассматриваемом методе мы определяем расчетное состояние баланса на основании знания последующего движения цены из буфера воспроизведения опыта. Необходимость подобного расчета вызвано большой вероятностью расхождения действия агента из буфера обмена и действием, сгенерированным агентом с учетом используемого навыка и обновленной стратегией поведения. Данные буфера воспроизведения опыта позволяют с достаточной точностью посчитать показатели состояния счета и открытых позиций для любого действия агента без необходимости повторения действия в тестере стратегий. Это позволяет нам значительно расширить обучающую выборку и тем самым повысить качество обучения моделей. Подобный функционал уже был реализован в предыдущей статье. А выведение в отдельный метод вызвано множественным обращением к данному функционалу в процессе обучения моделей.
В параметрах метод получает динамический массив показателей описания счета на этапе принятия решения, идентификатор действия и значение прибыли/убытка от последующего движения цены в расчете на 1 лот длинной позиции. В результате операций данный метод вернет вектор значений описания последующего состояния счета с учетом указанного действия.
В теле метода мы создаем вектор для записи результатов и переносим в него начальные значения в виде исходного состояния счета.
vector<float> GetNewState(float &prev_account[], int action, double prof_1l) { vector<float> result; //--- result.Assign(prev_account);
Дале осуществляется разветвление в зависимости от совершаемого действия. В случае совершения торговой операции открытия или доливки позиции мы рассчитываем новое значение открытых позиций в соответствующем направлении. Далее мы рассчитываем изменение накопленной прибыли/убытка по каждому направлению с учетом размера открытой позиции и последующего движения цены. Значение накопленной прибыли/убытка на счете равняется сумме 2 рассчитанных выше показателей. Сложив полученное значение с показателем баланса, мы получаем эквити счета.
switch(action) { case 0: result[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; case 1: result[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break;
В случае закрытия всех открытых позиций мы просто прибавляем значение накопленной прибыли к текущему балансу. Полученное значение копируем в эквити и свободную маржу. А остальные показатели обнуляем.
case 2: result[0] += result[4]; result[1] = result[0]; result[2] = result[0]; for(int i = 3; i < AccountDescr; i++) result[i] = 0; break;
Пересчет показателей при выжидании (отсутствии действий агента) аналогичны торговым операция открытия позиции, за исключением изменения объема открытых позиций. То есть мы только пересчитываем показатели накопленной прибыли/убытка и эквити для ранее открытых позиций.
case 3: result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; } //--- return result return result; }
После пересчета всех показателей мы возвращаем полученный вектор значений вызывающей программе.
Второй метод, который мы добавим, будет случить для вычисления размера внутреннего вознаграждения агенту на основании прогнозных значений дискриминатора, выбранного навыка и предыдущего состояния счета.
Обратите внимание, что агент получает вознаграждение за конкретное действие. Но в параметрах метода мы не указываем действие, выбранное агентом. На самом деле здесь можно заметить некий разрыв между прогнозом агента и получаемым вознаграждением. Ведь существует вероятность того, что выбранное агентом действие не приведет в спрогнозированное дискриминатором состояние. Конечно, в процессе обучения агента и дискриминатора вероятность такого разрыва будет снижаться. Тем не менее она останется. В то же время нам важно, чтобы вознаграждение соответствовало действию, ведущему в прогнозное состояние. Иначе мы не получим прогнозируемого поведения навыков. Именно поэтому мы будем определять вознаграждаемое действие из 2 последующих состояний: текущего и прогнозного для выбранного навыка.
Итак, функция GetAgentReward в параметрах получает выбранный навык, вектор результатов прямого прохода дискриминатора и массив описания предыдущего состояния баланса. В результате работы функции мы планируем получить вектор вознаграждений агента.
В теле метода мы проведем небольшую подготовительную работу. Вектор результатов прямого прохода дискриминатора содержит прогнозные состояния для всех возможных навыков. А для определения вознаграждения нам предстоит выделить отдельные навыки и посчитать средние значения в разрезе отдельных показателей. Справиться с этой задачей нам помогут матричные операции. Для начала нам необходимо переформатировать вектор результатов дискриминатора в матрицу.
Мы создаем новую матрицу размером в 1 строку и количество столбцов равно количеству элементов в векторе результатов дискриминатора. Скопируем значения из вектора в матрицу. После чего переформатируем матрицу в прямоугольную. В которой количество строк будет соответствовать количеству навыков, а количество столбцов будет равняться размеру вектора описания одного состояния. Очень важно в данном случае использовать метод Reshape, а не Resize. Так как первый перераспределяет имеющиеся значения по матрице нового формата. А второй только изменяет количество строк и столбцов без перераспределения имеющихся элементов. В таком случае мы просто потеряем все данные, кроме первого навыка. А добавленные строки будут заполнены случайными значениями.
vector<float> GetAgentReward(int skill, vector<float> &discriminator, float &prev_account[]) { //--- prepare matrix<float> discriminator_matrix; discriminator_matrix.Init(1, discriminator.Size()); discriminator_matrix.Row(discriminator,0); discriminator_matrix.Reshape(NSkills, AccountDescr); vector<float> forecast = discriminator_matrix.Row(skill);
Теперь для извлечения вектора прогнозного состояния интересующего нас навыка достаточно извлечь значения соответствующей строки.
Далее нам предстоит определить действие, за которое агент получит вознаграждения. Основным индикатором торговой операции у нас служит изменение позиции. Да, мы допускаем, что здесь может быть много условностей. Но их использование поможет нам определить операции, которые помогут с достаточной долей вероятности приблизиться к прогнозному состоянию. Именно это делает нашу модель управляемой и прогнозируемой.
Прежде всего, мы определяем изменение позиции по каждому направлению. Если мы имеем снижение размера открытых позиций по обоим направлениям, то считаем действие закрытия позиций наиболее вероятным. В противном случае мы отдаем предпочтение наибольшему изменению позиции. Считаем, что в этом направлении была открыта новая сделка или осуществлена доливка.
В случае же равенства изменений мы просто выжидаем. По теории вероятности с использованием значений с плавающей запятой такой исход менее всего вероятный. И тем самым мы хотим стимулировать модель к активным действиям.
//--- check action int action = 3; float buy = forecast[5] - prev_account[5]; float sell = forecast[6] - prev_account[6]; if(buy < 0 && sell < 0) action = 2; else if(buy > sell) action = 0; else if(buy < sell) action = 1;
Теперь, когда мы определили вознаграждаемое действие и подготовили данные для вычислений мы можем перейти непосредственно к заполнению вектора вознаграждений.
Вначале мы формируем вектор нулевых значений по размерности пространства действий. Дале мы разделим вектор прогнозных значений интересующего нас навыка на вектор средних прогнозных показателей по всем навыкам. Из полученного вектора возьмем среднее значение. Мы допускаем вероятность получения отрицательно значения в результате выполнения данных операций. Поэтому в логарифм мы возьмем абсолютное его значение. Это абсолютно не противоречит первичной задаче. Ведь нам важно максимизировать вознаграждение для наиболее не стандартных действий, которые максимально далеки от вектора средних значений. В качестве альтернативного решения, которое поможет также исключить деление на ноль, могу предложить использовать эвклидово расстояние между вектором анализируемого навыка и вектором средних значений. Качество работы подходов предлагаю проверить на практике.
//--- calculate reward vector<float> result = vector<float>::Zeros(NActions); float mean = (forecast / discriminator_matrix.Mean(0)).Mean(); result[action] = MathLog(MathAbs(mean)); //--- return result return result; }
Полученное значение вознаграждения записываем в элемент вектора, который соответствует ранее определенному действию. В завершение операций функции мы возвращаем полученный вектор вознаграждений вызывающей программе.
После завершения подготовительной работы мы переходим к процедуре обучения наших моделей Train. Здесь мы сначала объявляем ряд локальных переменных и определяем количество ранее загруженных траекторий обучающей выборки.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action; int skill, shift;
Далее мы организовываем систему циклов процесса обучения моделей. Сразу надо сказать, что согласно алгоритму DADS обучение моделей осуществляется последовательно и итерационно. Первым мы обучаем Дискриминатор (фаза 0). Затем Агента (фаза 1). И последний по списку, но не по значению Планировщик (фаза 2). И весь процесс повторяется несколько итераций. Количество итераций задается во внешних параметрах советника. Кроме того, во внешних параметрах советника мы укажем размер пакета обучения для каждой фазы.
Сейчас же в теле функции мы объявим систему вложенных циклов. Внешний цикл определяет количество итераций процесса обучения. А вложенный цикл определит фазу обучения.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { for(int phase = 0; phase < 3; phase++) {
Надо сказать, что вложенный цикл можно было заменить на последовательность операций. Но такой подход позволил исключить копирование общих операций, таких как загрузка исходного состояния из буфера воспроизведения перед прямым проходом моделей.
Операции каждой фазы обучения повторяются в размере пакета обучения, который указывается во внешних параметрах советника для каждой фазы отдельно. Поэтому мы сначала определим размер соответствующего пакета обучения. А затем создадим еще один вложенный цикл с необходимым количеством повторений.
int batch = 0; switch(phase) { case 0: batch = DiscriminatorBatch; break; case 1: batch = AgentBatch; break; case 2: batch = SchedulerBatch; break; default: PrintFormat("Incorrect phase %d"); batch = 0; break; } for(int batch_iter = 0; batch_iter < batch; batch_iter++) {
Далее начинается процесс непосредственного обучения моделей. Вначале нам необходимо подготовить исходные данные. Их мы случайным образом выбираем из буфера воспроизведения опыта. Здесь мы случайным образом выбираем проход и состояние из этого прохода.
int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
После чего загружаем данные описания текущего состояния системы в буфер данных.
State.AssignArray(Buffer[tr].States[i].state);
Затем мы переводим в относительные единицы и добавляем буфер данные о состоянии счета.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
На этом этапе мы можем осуществить прямой проход моделей. Но, прежде чем перейти к разветвлению потока операций в зависимости от текущей фазы обучения, мы еще подготовим данные, которые нам понадобятся на каждой фазе операций для вычисления расчетного будущего состояния счета.
bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
И только после выполнения всех общих операций мы переходим к разделению потока операций в зависимости от текущей фазы обучения.
Как уже было сказано выше, процесс обучения начинается с обучения модели дискриминатора. Первым делом мы осуществляем прямой проход модели на основании ранее подготовленных исходных данных и проверяем корректность выполнения операций.
switch(phase) { case 0: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Напомню, что на выходе дискриминатора мы получаем вектор прогнозных состояний для всех изучаемых навыков. Следовательно, для подготовки целевых значений нам предстоит также сгенерировать целевые состояния для всех навыков. С этой целью мы организуем цикл по числу изучаемых навыков. И в теле цикла осуществим прямой проход нашего агента для каждого отдельного навыка.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
По результатам прямого прохода мы семплируем действие агента. Хочу акцентировать внимание именно на семплировании действия. Так как это поможет максимально разнообразить действия агента и способствует всестороннему изучению окружающей среды.
На базе исходного состояния системы, семплированного действия и известного из буфера воспроизведения опыта последующего движения цены мы расчетным путем определяем следующее состояние счета и заполняем соответствующей блок целевых значений дискриминатора. И переходим к работе со следующим навыком.
action = Actor.getSample(); account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); shift = skill * AccountDescr; DiscriminatorResult[shift] = (account[0] - PrevBalance) / PrevBalance; DiscriminatorResult[shift + 1] = account[1] / PrevBalance; DiscriminatorResult[shift + 2] = (account[1] - PrevEquity) / PrevEquity; DiscriminatorResult[shift + 3] = account[2] / PrevBalance; DiscriminatorResult[shift + 4] = account[4] / PrevBalance; DiscriminatorResult[shift + 5] = account[5]; DiscriminatorResult[shift + 6] = account[6]; DiscriminatorResult[shift + 7] = account[7] / PrevBalance; DiscriminatorResult[shift + 8] = account[8] / PrevBalance; }
После подготовки целевых данных мы осуществляем обратный проход дискриминатора.
if(!Result) { Result = new CBufferFloat(); if(!Result) { PrintFormat("Error of create buffer %d", GetLastError()); ExpertRemove(); break; } } Result.AssignArray(DiscriminatorResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
В следующем блоке мы рассмотрим итерации следующей фазы процессе обучения — обучение Агента. Напомню, что исходные данные мы подготовили до разделения потока операций в зависимости от фазы обучения. А значит к текущему моменту мы уже имеем сформированный буфер исходных данных. Поэтому мы смело выполняем прямой проход дискриминатор и извлекаем результаты операций, так как они нам понадобятся для формирования внутреннего вознаграждения.
case 1: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Discriminator.getResults(DiscriminatorResult);
Далее, как и на предыдущей фазе обучения, мы организовываем цикличный процесс последовательного перебора вех навыков для текущего состояния.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
В теле цикла мы организовываем операции прямого прохода агента, формирования вектора вознаграждения и обратного прохода модели.
reward = GetAgentReward(skill, DiscriminatorResult, Buffer[tr].States[i].account); Result.AssignArray(reward); StateSkill.AssignArray(Buffer[tr].States[i + 1].state); account = GetNewState(Buffer[tr].States[i].account, Actor.getAction(), prof_1l); shift = skill * AccountDescr; StateSkill.Add((account[0] - PrevBalance) / PrevBalance); StateSkill.Add(account[1] / PrevBalance); StateSkill.Add((account[1] - PrevEquity) / PrevEquity); StateSkill.Add(account[2] / PrevBalance); StateSkill.Add(account[4] / PrevBalance); StateSkill.Add(account[5]); StateSkill.Add(account[6]); StateSkill.Add(account[7] / PrevBalance); StateSkill.Add(account[8] / PrevBalance); if(!Actor.backProp(Result, DiscountFactor, GetPointer(StateSkill), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } } break;
Как можно заметить, полный перебор навыков немного не соответствует общей ранее используемой парадигме использования случайных состояний. Части определения траектории и исходного состояния мы остаемся верны семплированию. А вот полным перебором навыков для одного отдельно взятого состояния мы хотим акцентировать внимание модели именно на показателях идентификации навыка. Ведь именно изменения навыка должно быть сигналом модели для изменения стратегии поведения.
Следующим этапом нашей реализации алгоритма DADS идет процесс обучения планировщика. Данный процесс практически полностью повторяет аналогичный функционал в реализации метода DIAYN. Вначале осуществляется прямой проход планировщика и получаем вероятностное распределение навыков. Но в отличии от предыдущей реализации мы не будем ни семплировать, ни осуществлять жадный отбор навыка. Мы понимаем, что в реальных условиях нет четких границ разделения той или иной стратегии. Эти границы сильно размыты. И все разделения переполнены различными допусками и компромиссами. В таких условиях напрашивается решение передать полное распределение вероятностей агенту для принятия решений.
case 2: if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Scheduler.getResults(SchedulerResult);
Хочу обратить внимание, что в процессе обучения агента ему передавались четко выраженные идентификаторы навыков. И тем более интересным становится эксперимент с передачей полного распределения вероятностей агенту дальнейшего принятия решений. Ведь подобные исходные данные выходят за рамки обучающей выборки, что делает непредсказуемым поведедение модели.
State.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } action = Actor.getAction();
По результатам прямого прохода мы жадным образом отбираем действие агента. Ведь наша цель обучить планировщика для управления политикой принятия решений на уровне навыков. А это возможно только при использовании прогнозируемых навыков, поведение которых определяется осмысленной и последовательной стратегией.
Далее вы определяем расчетное последующее состояние показателей описания счета и на их основе формируем вектор вознаграждений модели. Напомню, что в качестве внешнего вознаграждения модели мы используем относительное изменение баланса счета.
account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); SchedulerResult = SchedulerResult * (account[0] / PrevBalance - 1.0); Result.AssignArray(SchedulerResult); State.AssignArray(Buffer[tr].States[i + 1].state); State.Add((account[0] - PrevBalance) / PrevBalance); State.Add(account[1] / PrevBalance); State.Add((account[1] - PrevEquity) / PrevEquity); State.Add(account[2] / PrevBalance); State.Add(account[4] / PrevBalance); State.Add(account[5]); State.Add(account[6]); State.Add(account[7] / PrevBalance); State.Add(account[8] / PrevBalance); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
После подготовки вектора вознаграждения модели и последующего состояния системы мы осуществляем обратный проход модели планировщика.
default: PrintFormat("Wrong phase %d", phase); break; } } } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
В завершение операций в теле системы циклов обучения моделей мы выводим сообщение информирования пользователя о ходе процесса обучения моделей.
Остальные методы и функции советника, равно как и советник для тестирования обученной модели были перенесены без изменений. А с полным кодом всех используемых в статье программ можно ознакомиться во вложении в каталоге "MQL5\Experts\DADS".
3. Тестирование
Обучение моделей осуществлялось на исторических данных за первые 4 месяца 2023 года инструмента EURUSD таймфрейм H1. Параметры всех индикаторов использовались по умолчанию. Как можно заметить, параметры тестирования взяты без изменений из предыдущей статьи. Это позволяет сравнить результаты работы 2 методов обучения навыков.
Для проверки результативности работы обученной модели было проведено тестирование в тестере стратегий на временном отрезке за май 2023 года. То есть тестирование обученной модели осуществлялось вне обучающей выборки на временном отрезке в 25% от обучающей выборки.
В результате данного тестирования модель продемонстрировала способность к генерированию прибыли с профит-фактором 1.75 и фактором восстановления 0.85. Доля прибыльных сделок составила 52.64%. При этом средний доход прибыль сделки на 57.37% превышает среднюю убыточную сделку (2.99 против -1.90).



Так же можно отметить и почти равномерное использование навыков. В процессе тестирования были задействованы все навыки.
Надо сказать, что в процессе тестирования обученной модели Агенту передавался не один жадно отобранный навык, а полное вероятностное распределение, сформированное планировщиком. При этом каждое действие агента было отобран с использованием жадной стратегии по максимальному прогнозируемому вознаграждению. Такой подход дает планировщику максимальный контроль над работой моделью и исключает стохастичность действий Агента, которая возможна при семплировании. Напомню, что именно так мы обучали модель Планировщика.
Примечательно будет отметить, что эксперимент с жадным выбором навыка показал схожие результаты. Жадный выбор навыка позволил увеличить профит-фактор до 1.80. А доля прибыльных сделок возросла на 0.91% до 53.55%. Здесь мы также наблюдаем и увеличение средней прибыльной сделки до 3.08.

Заключение
В данной статье мы познакомились с еще одним методом бесконтрольного обучения навыков Dynamics-Aware Discovery of Skills (DADS). Использование данного метода позволяет обучать разнообразные навыки, способные эффективно исследовать окружающую. В то же время навыки, обученные предложенным методом, имеют довольно прогнозируемое поведение. Это облегчает обучение планировщика. И в целом повышает стабильность работы обученной модели.
В практической части статьи мы реализовали рассмотренный алгоритм средствами MQL5 и провели тестирование построенной модели. В результате тестирования мы получили обнадеживающие результаты, которые демонстрируют способность модели к генерированию прибыли за пределами обучающей выборки.
Однако, все представленные и используемые в статье программы предназначены лишь для демонстрации работы подходов и не готовы для использования в реальной торговле.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mql5 | Советник | Советник обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | FQF.mqh | Библиотека класса | Библиотека класса организации работы полностью параметризированной модели |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования