
Redes neurais de maneira fácil (Parte 44): Explorando habilidades de forma dinâmica

Introdução
Ao resolver problemas de previsão em um ambiente estocástico complexo, é bastante difícil, e muitas vezes impossível, treinar um único modelo que apresente resultados aceitáveis fora do conjunto de treinamento. Ao mesmo tempo, dividir a tarefa em sub tarefas menores aumenta significativamente a eficácia do modelo geral. Em artigos anteriores, já discutimos a construção de modelos hierárquicos, cuja arquitetura permite dividir a resolução da tarefa em várias sub tarefas, cada uma sendo resolvida por um modelo mais simples. Isso levanta a questão de como treinar habilidades de forma adequada, identificáveis pelo comportamento do modelo em diferentes estados.
No artigo anterior, introduzimos o método DIAYN, que permite treinar habilidades distintas. Isso possibilita a construção de um modelo capaz de modificar o comportamento do agente de acordo com o estado atual. Lembre-se de que o algoritmo DIAYN recompensa comportamentos imprevisíveis, o que permite treinar habilidades com comportamentos altamente variáveis. Mas, há uma desvantagem. Tais habilidades se tornam difíceis de prever, o que complica o processo de planejamento e controle do agente.
Nesta perspectiva, surge a questão de como treinar habilidades cujo comportamento seja facilmente previsível, sem abrir mão da diversidade de comportamentos. Essa tarefa é abordada pelos autores do método Dynamics-Aware Discovery of Skills (DADS), que foi apresentado ao mundo em 2020. Ao contrário do DIAYN, o método DADS busca treinar habilidades que não apenas possuam diversidade comportamental, mas também sejam previsíveis.
1. Visão geral da arquitetura e principais etapas do DADS
Explorar uma variedade de comportamentos individuais e suas interações com o ambiente permite usar o controle baseado em modelo para planejar no espaço comportamental, em vez do espaço de ações. Nesse sentido, a questão principal é como podemos obter tais comportamentos, considerando que eles podem ser aleatórios e imprevisíveis? O método Dynamics-Aware Discovery of Skills (DADS) propõe um sistema de aprendizado por reforço não supervisionado para aprender habilidades de baixo nível, com o objetivo explícito de facilitar o controle baseado em modelo.
As habilidades adquiridas usando DADS são diretamente otimizadas para previsibilidade, fornecendo uma base sólida para o desenvolvimento de modelos de previsão. A característica fundamental das habilidades é que elas são adquiridas inteiramente por meio de exploração autônoma. Isso significa que o repertório de habilidades e seu modelo preditivo são desenvolvidos antes da formulação da tarefa e do design da função de recompensa. Assim, com quantidade suficiente de dados, é possível compreender de forma abrangente o ambiente e desenvolver habilidades de comportamento nele.
Assim como no método DIAYN, o algoritmo DADS usa duas modelos durante o processo de treinamento: o modelo de habilidades (agente) e o discriminador (modelo de dinâmica das habilidades).
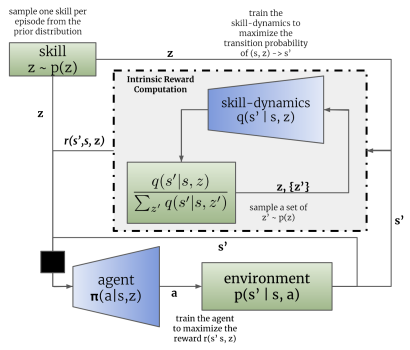
O treinamento dos modelos é realizado de forma sequencial e iterativa. Primeiro, o discriminador é treinado para prever os estados futuros com base no estado atual e na habilidade utilizada. Para isso, o modelo do agente recebe como entrada o estado atual e um vetor de identificação da habilidade. O agente gera uma ação que é executada no ambiente. Como resultado da execução da ação, o agente passa para um novo estado no ambiente.
Por sua vez, o discriminador, com base nos mesmos dados iniciais, tenta prever o novo estado do ambiente. Neste caso, o funcionamento do discriminador se assemelha ao de um autocodificador discutido anteriormente. No entanto, neste caso, o decodificador não reconstrói os dados originais, mas faz uma previsão do próximo estado. E, assim como treinamos autocodificadores, treinamos o discriminador usando o método de descida de gradiente.
Como se pode notar, aqui reside a primeira diferença entre os algoritmos DIAYN e DADS. No DIAYN, com base no novo estado, determinávamos a habilidade que nos levou a esse estado. O discriminador DADS realiza o inverso. Com base nos dados de entrada e na habilidade conhecida, ele prevê o estado subsequente do ambiente.
É importante destacar que o processo é iterativo. Por isso, não buscamos alcançar a máxima verossimilhança imediatamente. Ao mesmo tempo, para treinar o agente, precisamos de pelo menos uma aproximação inicial.
Após o primeiro conjunto de iterações de treinamento do discriminador, passamos para o treinamento do agente (modelo de habilidades). Vale ressaltar que diferentes conjuntos de dados de treinamento são utilizados para treinar o discriminador e o agente. No entanto, isso não implica na necessidade de criar conjuntos de treinamento separados. Utilizamos o mesmo buffer de reprodução de experiência. Apenas em cada iteração, formamos aleatoriamente dois conjuntos de dados de treinamento distintos a partir desse buffer.
Da mesma forma que no método DIAYN, o treinamento do modelo de habilidades é realizado por meio de métodos de aprendizado por reforço, com base nas recompensas geradas pelo discriminador. A diferença, como sempre, está nos detalhes. No DADS, é utilizada uma fórmula matemática diferente para calcular as recompensas. Não entrarei agora em todos os cálculos matemáticos e na fundamentação desse método. Você pode consultar esses detalhes no artigo original. Vou me concentrar apenas na fórmula final das recompensas.
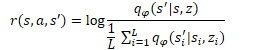
Na fórmula apresentada, q(s'|s,z) representa a saída do discriminador para um estado específico s e uma habilidade z. E L representa o número de habilidades. Desse modo, no numerador da fórmula de recompensa, temos o estado previsto para a habilidade analisada. E no denominador, a média dos estados previstos para todas as habilidades possíveis.
O uso dessa função de recompensa permite abordar a tarefa mencionada anteriormente. Visto que no numerador estamos usando o estado previsto para a habilidade atual, estamos recompensando a ação do agente que leva a esse estado previsto. Isso garante a previsibilidade do comportamento das habilidades.
Ao mesmo tempo, o uso da média dos estados para todas as habilidades possíveis no denominador nos permite recompensar mais o comportamento da habilidade que difere mais do comportamento médio.
Dessa forma, o método DADS alcança um equilíbrio entre previsibilidade e diversidade de habilidades. Isso permite treinar habilidades que possuem comportamentos estruturados e previsíveis, ao mesmo tempo em que mantém a capacidade de explorar o ambiente.
Deve-se notar que o feedback do discriminador e o treinamento do modelo de habilidades levam a alterações no comportamento do agente. Como resultado, o comportamento do agente será diferente dos exemplos acumulados no buffer de reprodução de experiência. Portanto, para obter os melhores resultados, usamos um processo iterativo com treinamento sequencial do discriminador e do agente. Durante esse processo, o treinamento do modelo é repetido várias vezes. Além disso, os autores do método sugerem o uso de um coeficiente de importância ao treinar o discriminador, que é determinado pela relação entre a probabilidade de executar uma ação com a política atual do agente e a probabilidade de executar essa ação no buffer de reprodução de experiência. Isso permite dar mais atenção ao comportamento estabelecido do agente e, ao mesmo tempo, diminuir o impacto das ações aleatórias.
É importante observar que o método DADS foi originalmente proposto para treinar habilidades e criar um modelo do ambiente. Como pode ser notado, o treinamento de habilidades previsíveis e de um modelo de dinâmica, que permite prever com uma boa probabilidade o novo estado do ambiente, possibilita o planejamento de vários passos à frente. Durante o planejamento, é possível fazer a transição de ações específicas para operar com conceitos mais abstratos de habilidades. As ações específicas serão determinadas pelo agente de acordo com a habilidade planejada.
No entanto, neste estágio, não ousamos avançar para o planejamento de longo prazo e optamos por treinar um planejador para determinar a habilidade em cada passo, como implementado no artigo anterior.
2. Implementação em MQL5
Após considerar os aspectos teóricos do método Dynamics-Aware Discovery of Skills, passamos à implementação prática do algoritmo. Antes de entrar na implementação do algoritmo em si, vamos definir a arquitetura dos modelos.
Em nossa implementação, usaremos 3 modelos, assim como na implementação do método DIAYN. São eles: o agente (modelo de habilidades), o discriminador (modelo de dinâmica) e o planejador.
O algoritmo prevê que o agente, com base no estado atual e na habilidade escolhida, determine a ação a ser executada. Portanto, a dimensão dos dados de entrada deve ser suficiente para registrar um vetor de descrição do estado atual e um vetor one-hot que identifica a habilidade escolhida.
Na saída do agente, obtemos um vetor de distribuição de probabilidade no espaço das ações possíveis. Como pode ser notado, os dados de entrada, a função e o resultado do agente são completamente análogos às características correspondentes do agente do método DIAYN. Nesta implementação, deixaremos a arquitetura do agente inalterada, o que nos permitirá comparar o funcionamento dos dois métodos de treinamento de habilidades na prática. No entanto, isso não significa que não possa ser utilizada outra arquitetura de modelo.
Lembrando, na arquitetura do agente, utilizamos uma camada de normalização em lote para tornar os dados de entrada comparáveis.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados normalizados são processados por um bloco de 2 camadas convolucionais e de subamostragem, permitindo a extração de padrões e tendências nos dados de entrada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados processados após as camadas convolucionais são transmitidos para um bloco de tomada de decisão, que inclui camadas totalmente conectadas e um modelo de quantil totalmente parametrizado FQF.
O uso do FQF na saída do bloco de tomada de decisão nos permite obter previsões mais precisas de recompensas após a realização de ações. Isso leva em consideração não apenas o valor médio, mas também a distribuição de probabilidade, levando em conta a estocasticidade do ambiente.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Como mencionado anteriormente, nesta implementação, optamos por não criar um modelo do ambiente para fazer previsões a vários passos à frente. Assim como antes, iremos determinar a habilidade usada a cada passo. Por isso, a arquitetura e as abordagens de treinamento do planejador também foram mantidas inalteradas. Aqui, usamos uma camada de normalização em lote para tornar os dados brutos comparáveis. O bloco de tomada de decisão consiste em camadas totalmente conectadas e um modelo FQF. Seus resultados são transformados em uma distribuição de probabilidade usando uma camada SoftMax.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
No entanto, na arquitetura do modelo do discriminador, fizemos algumas mudanças. Como lembrete, no algoritmo DADS, um modelo de Dinâmica é usado como o discriminador. De acordo com o algoritmo em questão, ele deve prever o novo estado do ambiente com base no estado atual e na habilidade escolhida. Além disso, o modelo de Dinâmica no método DADS é usado para prever os estados futuros ao planejar vários passos à frente. Mas, como mencionado anteriormente, não iremos construir planos de longo prazo. Assim, podemos desviar um pouco da previsão de todos os indicadores de estados futuros do ambiente. Como você sabe, a descrição do estado do ambiente é composta por dois grandes blocos:
- dados históricos de movimento de preços e métricas de indicadores analisados
- indicadores da situação da conta atual
O impacto de um trader individual no estado do mercado financeiro é tão insignificante que pode ser negligenciado. Por isso, as ações do nosso agente não afetam os dados históricos. Isso significa que faz sentido excluí-los da formação de recompensas internas ao treinar nosso agente. E, como não planejaremos a longo prazo, a previsão desses indicadores não faz sentido. Desse modo, para formar recompensas internas, é suficiente prever os indicadores de estado futuro da conta.
Também é importante observar um ponto adicional. Dê uma olhada na fórmula de formação de recompensas internas do agente. Além do estado previsto para a habilidade analisada, ela também utiliza a média do estado previsto para todas as habilidades possíveis. Assim, para determinar uma única recompensa, teremos que prever os estados futuros para todas as habilidades. Para acelerar o processo de treinamento dos modelos, foi decidido criar uma saída multi-cabeça para o modelo. Isso significa que, com base apenas nos dados de entrada, o modelo retornará os estados previstos para todas as habilidades possíveis.
Dessa forma, a camada de dados da modelo Discriminador é comparável à camada correspondente do modelo Planejador e deve ser suficiente para registrar a descrição do estado do sistema sem levar em consideração a habilidade escolhida.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; }
Os dados iniciais obtidos passam por um pré-processamento na camada de normalização em lote e são transmitidos para um bloco de tomada de decisão, composto por um perceptron totalmente conectado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; }
A saída do modelo também utiliza uma camada totalmente conectada. Seu tamanho é o produto do número de habilidades treináveis pelo número de elementos para descrever um estado do sistema. Neste caso, estamos especificando o número de elementos para descrever o estado da conta.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills*AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; }
É importante notar que, embora tenhamos decidido usar valores relativos para as métricas de descrição do estado da conta no artigo anterior, esses valores não são normalizados. Portanto, ao prever esses valores, não podemos usar uma única função de ativação. Portanto, a saída do modelo discriminador utiliza uma camada neural sem função de ativação.
O código completo que descreve a arquitetura de todos os modelos utilizados está reunido na função "CreateDescriptions," que foi colocada no arquivo de biblioteca "Trajectory.mqh." Mover essa função do arquivo do EA para o arquivo de biblioteca permite o uso da mesma arquitetura de modelos em todas as etapas de treinamento e elimina a necessidade de copiar manualmente a descrição da arquitetura dos modelos entre os EAs.
Durante o processo de treinamento dos modelos e testando os resultados obtidos, usaremos três EAs. Semelhante ao treinamento dos modelos usando o método DIAYN. O EA para a coleta de dados primários de treinamento, "Research.mq5", foi transferido quase sem modificações. As alterações se limitaram apenas ao nome do arquivo para armazenar os modelos e às soluções arquitetônicas descritas acima. O código completo do EA está disponível em anexo.
As principais alterações para a implementação do algoritmo DADS foram feitas no EA de treinamento dos modelos, "Study.mq5." Em primeiro lugar, houve um controle para garantir a conformidade da arquitetura dos modelos com as constantes previamente declaradas, que é feito no método OnInit. Aqui, ajustamos o controle de acordo com as arquiteturas dos modelos modificadas.
Discriminator.getResults(DiscriminatorResult); if(DiscriminatorResult.Size() != NSkills * AccountDescr) { PrintFormat("The scope of the discriminator does not match the skills count (%d <> %d)", NSkills * AccountDescr, Result.Total()); return INIT_FAILED; } Scheduler.getResults(SchedulerResult); Scheduler.SetUpdateTarget(MathMax(Iterations / 100, 500000 / SchedulerBatch)); if(SchedulerResult.Size() != NSkills) { PrintFormat("The scope of the scheduler does not match the skills count (%d <> %d)", NSkills, Result.Total()); return INIT_FAILED; } Actor.getResults(ActorResult); Actor.SetUpdateTarget(MathMax(Iterations / 100, 500000 / AgentBatch * NSkills)); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
E, claro, foram feitas mudanças significativas no método de treinamento dos modelos, "Train." Para começar, vamos analisar dois novos métodos auxiliares. O primeiro método é "GetNewState." No corpo deste método, vamos calcular o estado previsto das métricas de saldo com base no estado anterior da conta, na ação planejada e na conhecida movimentação de preços "futura."
Gostaria de destacar que este método determina especificamente o estado calculado do saldo, não o previsto. Há um grande significado por trás desse cálculo. A previsão das métricas de saldo é realizada pelo modelo de Dinâmica (Discriminador). Neste método em questão, estamos determinando o estado calculado do saldo com base no conhecimento do movimento de preços subsequente do buffer de experiência. A necessidade desse cálculo decorre da alta probabilidade de ação do agente no buffer ser diferente da ação gerada pelo agente, levando em consideração a habilidade usada e a estratégia de comportamento atualizada. Os dados no buffer de experiência permitem calcular com precisão as métricas de estado da conta e posições abertas para qualquer ação do agente, sem a necessidade de repetir a ação no testador de estratégia. Isso nos permite expandir significativamente o conjunto de dados de treinamento e, assim, aumentar a qualidade do treinamento dos modelos. Funcionalidade semelhante já foi implementada no artigoanterior. No entanto, agora foi colocada em um método separado devido a múltiplas chamadas a essa funcionalidade durante o treinamento dos modelos.
Os parâmetros do método recebem um array dinâmico das métricas de descrição da conta na fase de tomada de decisão, o identificador da ação e o valor do lucro/perda da movimentação de preços subsequente para 1 lote de uma posição longa. Como resultado das operações, esse método retornará um vetor de valores descrevendo o estado subsequente, levando em consideração a ação especificada.
No corpo do método, criamos um vetor para armazenar os resultados e copiamos os valores iniciais nele na forma do estado original da conta.
vector<float> GetNewState(float &prev_account[], int action, double prof_1l) { vector<float> result; //--- result.Assign(prev_account);
Em seguida, ocorre uma ramificação dependendo da ação realizada. No caso de uma operação de negociação de abertura ou aumento de posição, calculamos um novo valor para as posições abertas na direção correspondente. Em seguida, calculamos a variação acumulada de lucro/perda para cada direção, levando em consideração o tamanho da posição aberta e o movimento subsequente de preços. O valor acumulado de lucro/perda na conta é a soma dos dois indicadores calculados anteriormente. Somando esse valor ao indicador de saldo, obtemos o patrimônio da conta.
switch(action) { case 0: result[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; case 1: result[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break;
No caso de fechar todas as posições abertas, simplesmente adicionamos o valor acumulado de lucro atual ao saldo atual. O valor resultante é copiado para o equilíbrio e a margem livre. Todos os outros indicadores são redefinidos.
case 2: result[0] += result[4]; result[1] = result[0]; result[2] = result[0]; for(int i = 3; i < AccountDescr; i++) result[i] = 0; break;
A recálculo de indicadores em caso de espera (inatividade do agente) é semelhante às operações de abertura de posição, com exceção da alteração no tamanho das posições abertas. Ou seja, recalculamos apenas os indicadores de lucro acumulado e equidade para posições previamente abertas.
case 3: result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; } //--- return result return result; }
Após o recálculo de todos os indicadores, retornamos o vetor resultante à função chamadora.
O segundo método que adicionaremos será usado para calcular o valor do incentivo interno para o agente com base nas previsões do discriminador, na habilidade escolhida e no estado anterior da conta.
Observe que o agente recebe recompensa por uma ação específica. No entanto, não especificamos a ação escolhida pelo agente nos parâmetros do método. Na verdade, aqui podemos notar uma diferença entre a previsão do agente e a recompensa recebida. Afinal, existe a possibilidade de que a ação escolhida pelo agente não leve ao estado previsto pelo discriminador. Claro, durante o treinamento do agente e do discriminador, a probabilidade desse desvio diminuirá. No entanto, ele ainda existirá. Ao mesmo tempo, é importante que a recompensa corresponda à ação que leva ao estado previsto. Caso contrário, não teremos um comportamento previsível das habilidades. É por isso que determinaremos a ação recompensada a partir dos dois estados subsequentes: o atual e o previsto para a habilidade escolhida.
Bem, a função "GetAgentReward" recebe o skill escolhido, o vetor de resultados da propagação do discriminador e o array de descrição do estado anterior do saldo como parâmetros. O resultado esperado da função é um vetor de recompensas do agente.
No corpo do método, realizaremos um pequeno trabalho preparatório. O vetor de resultados da propagação do discriminador contém estados previstos para todas as habilidades possíveis. E para determinar a recompensa, precisamos isolar habilidades individuais e calcular os valores médios para cada métrica. Operações matriciais nos ajudarão a realizar essa tarefa. Primeiro, precisamos reformatar o vetor de resultados do discriminador em uma matriz.
Criamos uma nova matriz com uma linha e o número de colunas igual ao número de elementos no vetor de resultados do discriminador. Copiamos os valores do vetor para a matriz e, em seguida, reformatamos a matriz em um formato retangular. Nesse formato, o número de linhas corresponderá ao número de habilidades, e o número de colunas será igual ao tamanho do vetor de descrição de um estado. É muito importante, neste caso, usar o método Reshape em vez de Resize. Isso ocorre porque o primeiro redistribui os valores existentes na nova matriz. O segundo apenas altera o número de linhas e colunas sem redistribuir os elementos existentes. Nesse caso, perderíamos todos os dados, exceto para a primeira habilidade. As linhas adicionadas seriam preenchidas com valores aleatórios.
vector<float> GetAgentReward(int skill, vector<float> &discriminator, float &prev_account[]) { //--- prepare matrix<float> discriminator_matrix; discriminator_matrix.Init(1, discriminator.Size()); discriminator_matrix.Row(discriminator,0); discriminator_matrix.Reshape(NSkills, AccountDescr); vector<float> forecast = discriminator_matrix.Row(skill);
Agora, para extrair o vetor de estado previsto da habilidade desejada, é suficiente extrair os valores da linha correspondente.
Em seguida, precisamos determinar a ação pela qual o agente receberá recompensas. O principal indicador de uma operação de negociação para nós é a mudança na posição. Sim, admitimos que pode haver muitas nuances aqui. Mas, o uso delas nos ajudará a identificar operações que, com uma probabilidade razoável, nos aproximarão do estado previsto. É isso que torna nosso modelo controlável e previsível.
Em primeiro lugar, determinamos a mudança na posição em cada direção. Se observarmos uma redução no tamanho das posições abertas em ambas as direções, consideramos a ação de fechar posições como a mais provável. Caso contrário, damos preferência à maior mudança na posição. Acreditamos que, nessa direção, uma nova negociação foi aberta ou uma posição existente foi aumentada.
No caso de mudanças iguais, simplesmente esperamos. De acordo com a teoria das probabilidades, usando valores de ponto flutuante, esse resultado é o menos provável. Por isso, queremos estimular o modelo a agir de forma mais ativa.
//--- check action int action = 3; float buy = forecast[5] - prev_account[5]; float sell = forecast[6] - prev_account[6]; if(buy < 0 && sell < 0) action = 2; else if(buy > sell) action = 0; else if(buy < sell) action = 1;
Agora que determinamos a ação recompensada e preparamos os dados para cálculos, podemos prosseguir para o preenchimento do vetor de recompensas.
Primeiro, criamos um vetor de valores zero com base na dimensão do espaço de ações. Em seguida, dividimos o vetor de valores previstos da habilidade desejada pelo vetor de valores médios previstos de todas as habilidades. Pegamos a média desse vetor resultante. Admitimos a possibilidade de obter um valor negativo como resultado dessas operações. Portanto, calculamos o valor absoluto de seu logaritmo. Isso não entra em conflito com a tarefa principal, pois nosso objetivo é maximizar a recompensa para ações que se afastam o máximo possível do vetor médio. Como uma alternativa que também evita a divisão por zero, sugeriria usar a distância euclidiana entre o vetor da habilidade analisada e o vetor médio. A qualidade de ambos os métodos pode ser testada na prática.
//--- calculate reward vector<float> result = vector<float>::Zeros(NActions); float mean = (forecast / discriminator_matrix.Mean(0)).Mean(); result[action] = MathLog(MathAbs(mean)); //--- return result return result; }
O valor da recompensa obtida é armazenado no elemento do vetor correspondente à ação previamente definida. Ao concluir as operações da função, retornamos o vetor de recompensas obtido ao programa chamador.
Após a conclusão do trabalho preparatório, avançamos para o procedimento de treinamento de nossos modelos, chamado de Train. Aqui, começamos declarando várias variáveis locais e determinando o número de trajetórias carregadas anteriormente na amostra de treinamento.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action; int skill, shift;
Em seguida, realizamos o sistema de ciclos para o processo de treinamento dos modelos. Deve-se observar que, de acordo com o algoritmo DADS, o treinamento dos modelos ocorre sequencial e iterativamente. Primeiro treinamos o Discriminador (fase 0). Em seguida, o Agente (fase 1). Por último, mas não menos importante, o Planejador (fase 2). E todo o processo se repete por várias iterações. O número de iterações é definido nos parâmetros externos do EA. Além disso, nos parâmetros externos do EA, especificamos o tamanho do lote de treinamento para cada fase.
Agora, no corpo da função, vamos declarar um sistema de loops aninhados. O loop externo determina o número de iterações no processo de treinamento. O loop interno determinará a fase do treinamento.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { for(int phase = 0; phase < 3; phase++) {
Deve ser observado que o loop interno poderia ter sido substituído por uma sequência de operações. No entanto, esse método permitiu evitar a repetição de operações comuns, como carregar o estado inicial do buffer de reprodução antes da propagação dos modelos.
As operações de cada fase de treinamento são repetidas no tamanho do lote de treinamento, que é especificado nos parâmetros externos do EA para cada fase separadamente. Portanto, primeiro determinamos o tamanho do lote apropriado para cada fase. Em seguida, criamos outro loop aninhado com o número necessário de repetições.
int batch = 0; switch(phase) { case 0: batch = DiscriminatorBatch; break; case 1: batch = AgentBatch; break; case 2: batch = SchedulerBatch; break; default: PrintFormat("Incorrect phase %d"); batch = 0; break; } for(int batch_iter = 0; batch_iter < batch; batch_iter++) {
Em seguida, começa o processo de treinamento real dos modelos. Primeiro, precisamos preparar os dados iniciais. Esses dados são selecionados aleatoriamente do buffer de reprodução de experiência. Aqui, escolhemos aleatoriamente uma passagem e um estado dessa passagem.
int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Em seguida, carregamos os dados de descrição do estado atual do sistema no buffer de dados.
State.AssignArray(Buffer[tr].States[i].state);
Depois, convertemos para unidades relativas e adicionamos os dados do estado da conta.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Nesta etapa, podemos realizar a propagação pelos modelos. No entanto, antes de prosseguirmos com a ramificação das operações, dependendo da fase atual de treinamento, ainda precisamos preparar os dados que serão necessários em cada fase das operações para calcular o estado futuro estimado da conta.
bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Somente após a execução de todas as operações em comum, passamos para a divisão do fluxo de operações, dependendo da fase atual de treinamento.
Conforme mencionado anteriormente, o processo de treinamento começa com o treinamento do modelo Discriminador. Primeiro, realizamos a propagação do modelo com base nos dados de entrada preparados anteriormente e verificamos a correta execução das operações.
switch(phase) { case 0: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Lembre-se de que a saída do Discriminador nos fornece um vetor de estados previstos para todas as habilidades em estudo. Portanto, para preparar os valores de destino, também precisaremos gerar estados de destino para todas as habilidades. Para fazer isso, realizamos um loop pelo número de habilidades estudadas. No corpo do loop, realizamos a propagação do nosso agente para cada habilidade individualmente.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Com base nos resultados da propagação, amostramos a ação do agente. Gostaria de enfatizar o ato de amostrar a ação, pois isso ajuda a diversificar ao máximo as ações do agente e contribui para um estudo abrangente do ambiente.
Com base no estado inicial do sistema, na ação amostrada e no movimento de preços conhecido do buffer de reprodução de experiência, calculamos o próximo estado da conta e preenchemos o bloco correspondente de valores-alvo do Discriminador. Em seguida, passamos para a próxima habilidade.
action = Actor.getSample(); account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); shift = skill * AccountDescr; DiscriminatorResult[shift] = (account[0] - PrevBalance) / PrevBalance; DiscriminatorResult[shift + 1] = account[1] / PrevBalance; DiscriminatorResult[shift + 2] = (account[1] - PrevEquity) / PrevEquity; DiscriminatorResult[shift + 3] = account[2] / PrevBalance; DiscriminatorResult[shift + 4] = account[4] / PrevBalance; DiscriminatorResult[shift + 5] = account[5]; DiscriminatorResult[shift + 6] = account[6]; DiscriminatorResult[shift + 7] = account[7] / PrevBalance; DiscriminatorResult[shift + 8] = account[8] / PrevBalance; }
Após a preparação dos dados de destino, realizamos a retropropagação do Discriminador.
if(!Result) { Result = new CBufferFloat(); if(!Result) { PrintFormat("Error of create buffer %d", GetLastError()); ExpertRemove(); break; } } Result.AssignArray(DiscriminatorResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
No próximo bloco, analisaremos as iterações da próxima fase do processo de treinamento - o treinamento do Agente. Lembro que preparamos os dados de entrada antes de dividir o fluxo de operações com base na fase de treinamento atual. Logo, agora temos o buffer de dados formado. Assim sendo, realizamos com confiança a propagação do Discriminador e extraímos os resultados das operações, pois eles serão necessários para a formação de recompensas internas.
case 1: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Discriminator.getResults(DiscriminatorResult);
A seguir, assim como na fase de treinamento anterior, realizamos um processo cíclico de varredura sequencial das habilidades para o estado atual.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
No corpo do loop, realizamos as operações de propagação do agente, formação do vetor de recompensas e retropropagação do modelo.
reward = GetAgentReward(skill, DiscriminatorResult, Buffer[tr].States[i].account); Result.AssignArray(reward); StateSkill.AssignArray(Buffer[tr].States[i + 1].state); account = GetNewState(Buffer[tr].States[i].account, Actor.getAction(), prof_1l); shift = skill * AccountDescr; StateSkill.Add((account[0] - PrevBalance) / PrevBalance); StateSkill.Add(account[1] / PrevBalance); StateSkill.Add((account[1] - PrevEquity) / PrevEquity); StateSkill.Add(account[2] / PrevBalance); StateSkill.Add(account[4] / PrevBalance); StateSkill.Add(account[5]); StateSkill.Add(account[6]); StateSkill.Add(account[7] / PrevBalance); StateSkill.Add(account[8] / PrevBalance); if(!Actor.backProp(Result, DiscountFactor, GetPointer(StateSkill), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } } break;
Como pode ser observado, a abordagem completa de todas as habilidades não corresponde exatamente à paradigma geralmente usada de estados aleatórios. Continuamos a aderir à amostragem para partes da definição de trajetória e estado inicial. No entanto, ao realizar uma busca completa das habilidades para um estado específico, nosso objetivo é destacar a atenção do modelo para os indicadores de identificação da habilidade. Afinal, são as mudanças nas habilidades que devem sinalizar ao modelo a necessidade de mudar a estratégia de comportamento.
O próximo estágio na nossa implementação do algoritmo DADS é o treinamento do planejador. Este processo é praticamente idêntico ao funcional da implementação do método DIAYN. Primeiro, realizamos uma propagação pelo planejador e obtemos a distribuição probabilística das habilidades. No entanto, ao contrário da implementação anterior, não faremos amostragem ou seleção gananciosa de habilidades. Entendemos que, em condições reais, não existem fronteiras claras que definam uma estratégia ou outra. Essas fronteiras são altamente difusas. E todas as divisões estão cheias de várias permissões e compromissos. Nessas circunstâncias, a decisão de transmitir a distribuição completa de probabilidades ao agente para tomar decisões faz sentido.
case 2: if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Scheduler.getResults(SchedulerResult);
Quero chamar a atenção para o fato de que, durante o treinamento do agente, fornecemos a ele identificadores de habilidades claramente definidos. O experimento de fornecer a distribuição completa de probabilidades ao agente para tomar decisões torna-se ainda mais interessante. Afinal, esses dados de entrada ultrapassam os limites do conjunto de treinamento, tornando o comportamento do modelo imprevisível.
State.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } action = Actor.getAction();
Com base nos resultados da propagação, selecionamos gananciosamente a ação do agente. Nosso objetivo é treinar o planejador para gerenciar a política de tomada de decisões em um nível de habilidades. Isso só é possível usando habilidades previsíveis, cujo comportamento é definido por uma estratégia significativa e consistente.
A seguir, calculamos o estado futuro estimado dos indicadores de descrição da conta e, com base neles, formamos o vetor de recompensas do modelo. Lembro que usamos a alteração relativa do saldo da conta como recompensa externa do modelo.
account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); SchedulerResult = SchedulerResult * (account[0] / PrevBalance - 1.0); Result.AssignArray(SchedulerResult); State.AssignArray(Buffer[tr].States[i + 1].state); State.Add((account[0] - PrevBalance) / PrevBalance); State.Add(account[1] / PrevBalance); State.Add((account[1] - PrevEquity) / PrevEquity); State.Add(account[2] / PrevBalance); State.Add(account[4] / PrevBalance); State.Add(account[5]); State.Add(account[6]); State.Add(account[7] / PrevBalance); State.Add(account[8] / PrevBalance); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
Após a preparação do vetor de recompensas do modelo e do estado subsequente do sistema, realizamos a retropropagação do modelo do planejador.
default: PrintFormat("Wrong phase %d", phase); break; } } } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Para encerrar as operações no corpo dos ciclos de treinamento dos modelos, exibimos uma mensagem informativa ao usuário sobre o progresso do processo de treinamento dos modelos.
Outros métodos e funções do EA, bem como o EA para testar o modelo treinado, foram transferidos sem modificações. O código completo de todos os programas usados no artigo está disponível como um anexo no diretório "MQL5\Experts\DADS".
3. Testes
O treinamento dos modelos foi realizado com base em dados históricos dos primeiros 4 meses de 2023 do instrumento EURUSD no intervalo de tempo H1. Todos os parâmetros dos indicadores foram mantidos em seus valores padrão. Conforme observado, os parâmetros de teste foram mantidos inalterados em relação ao artigo anterior. Isso permite a comparação dos resultados entre os dois métodos de treinamento de habilidades.
Para verificar a eficácia do modelo treinado, realizamos testes no testador de estratégia no período de maio de 2023. Ou seja, o teste do modelo treinado foi realizado fora do conjunto de treinamento em um período de 25% do conjunto de treinamento.
Como resultado desses testes, o modelo demonstrou a capacidade de gerar lucro, com um fator de lucro de 1,75 e um fator de recuperação de 0,85. A porcentagem de negociações lucrativas foi de 52,64%. Além disso, o lucro médio por negociação superou em 57,37% a média das negociações com prejuízo (2,99 em comparação com -1,90).



Também é digno de nota o uso quase uniforme de todas as habilidades. Todas as habilidades foram envolvidas no processo de teste.
Vale ressaltar que, durante o teste do modelo treinado, o Agente não recebeu apenas uma habilidade escolhida gananciosamente, mas uma distribuição completa de probabilidade gerada pelo Planejador. Além disso, cada ação do Agente foi escolhida com base em uma estratégia gananciosa de recompensa máxima prevista. Esse método dá ao Planejador controle total sobre o funcionamento do modelo e elimina a estocasticidade nas ações do Agente que pode ocorrer com amostragem. Lembre-se de que esse é exatamente o método que usamos para treinar o modelo do Planejador.
É interessante notar que o experimento com a escolha gananciosa de habilidades resultou em resultados semelhantes. A escolha gananciosa de habilidades aumentou o fator de lucro para 1,80. Além disso, a porcentagem de negociações lucrativas aumentou 0,91%, atingindo 53,55%. Nesse caso, também observamos um aumento no lucro médio por negociação para 3,08.

Considerações finais
Neste artigo, apresentamos mais um método de treinamento de habilidades sem supervisão, o "Dynamics-Aware Discovery of Skills" (DADS). O uso desse método permite o treinamento de várias habilidades capazes de explorar efetivamente o ambiente. Ao mesmo tempo, as habilidades treinadas por esse método têm um comportamento bastante previsível. Isso facilita o treinamento do Planejador e, em geral, aumenta a estabilidade do modelo treinado.
Na parte prática do artigo, implementamos o algoritmo discutido usando a linguagem MQL5 e testamos o modelo construído. Os resultados dos testes foram promissores, demonstrando a capacidade do modelo de gerar lucro fora do conjunto de treinamento.
No entanto, todos os programas apresentados e usados no artigo são apenas para fins de demonstração e não estão prontos para uso em negociações reais.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | Study.mql5 | EA | EA para treinamento de modelos |
| 3 | Test.mq5 | EA | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | FQF.mqh | Biblioteca de classe | Biblioteca de classes de preparação de modelos totalmente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para a criação de uma rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12750
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso