
Теория категорий в MQL5 (Часть 7): Мульти-, относительные и индексированные домены
Введение
В предыдущей статье мы рассмотрели, как изменения в конусах и композициях могут повлиять на результаты анализа чувствительности, давая возможности для построения системы в зависимости от индикаторов и торгуемых ценных бумаг. В этой статье мы подробнее рассмотрим различные типы специальных/уникальных доменов, с которыми можно столкнуться, а также изучим, как их отношения можно использовать для смягчения ожиданий волатильности цен.
Мультидомены
В теории категорий мультидомен (также известный как "мешок" или "куча") - генерализация домена, допускающая многократное вхождение одного и того же элемента. Определение домена, данное в первой статье серии, требовало, чтобы каждый элемент был уникальным. Мультидомены подходят для ситуаций, когда необходимо повторение элементов внутри домена для правильного захвата всех метаданных этих элементов в этом домене. Например, рассмотрим домен, состоящий из слов в этом английском предложении:
“Sets theory deals with sets, while category theory deals with sets of sets, sets of sets of sets, and so on.”
"Теория множеств имеет дело с множествами, в то время как теория категорий имеет дело с множествами множеств, множествами множеств множеств и так далее".
Скорее всего, состав домена будет представлен следующим образом:
{sets, theory, deals, with, while, category, of, and, so, on}
Однако, как видите, полный смысл предложения теряется. Чтобы получить эту дополнительную информацию, мультидомен X формально определяется как
X := (N, π)
- N является типичным доменным представлением X, поскольку он только перечисляет элементы в X без повторения.
- π - гомоморфизм из X в N.
π: X → N,
N часто называют множеством имен в X, а π - функция именования для X. Для имени x ∈ N, где π -1(x) ∈ X в качестве прообраза (preimage); количество элементов в π -1(x) называется кратностью (multiplicity) x.
Собрав все это вместе, мы получим следующую диаграмму.
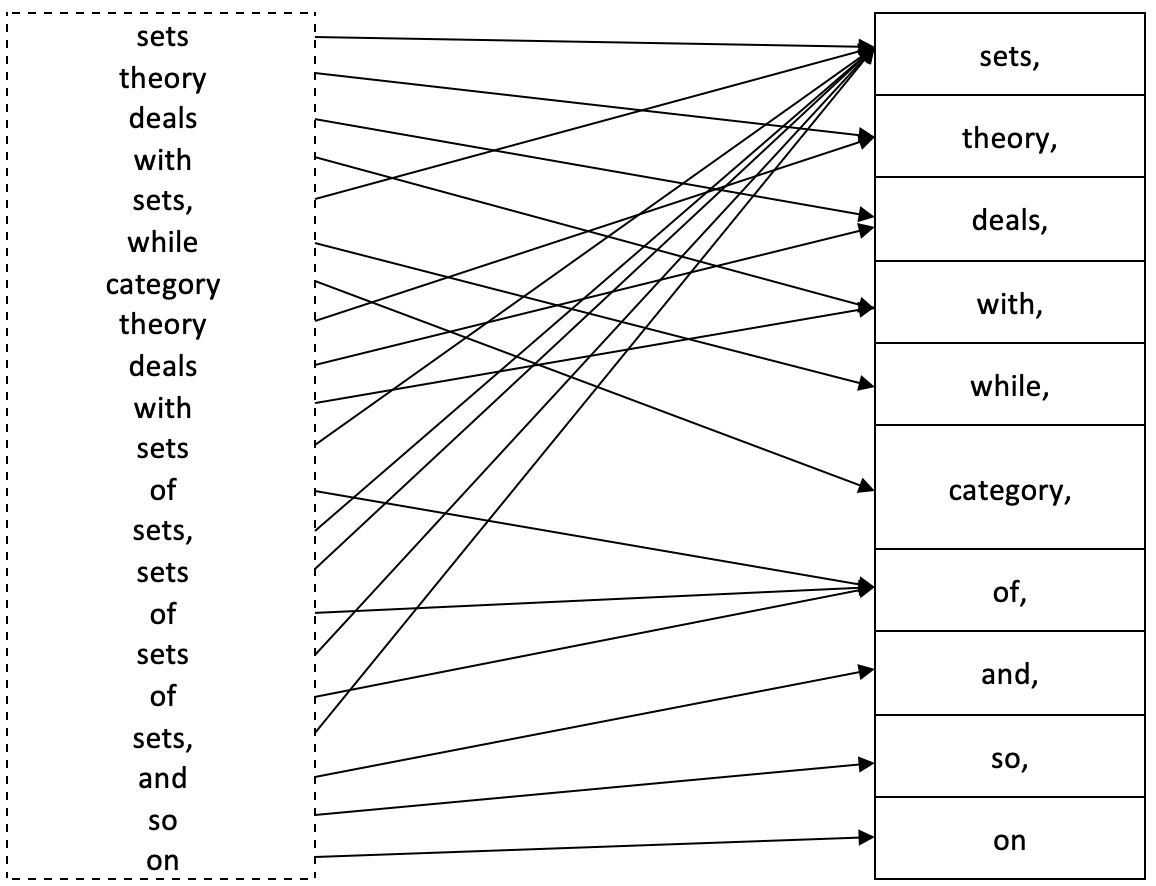
Таким образом, кратность "множеств" будет равна 8, "сделок" - 2, "category" - 1 и так далее.
Чтобы проиллюстрировать это с точки зрения трейдера, рассмотрим временной ряд цен. Если нас интересуют изменения в диапазоне ценового бара, и мы хотим предсказать эти изменения, используя предыдущее действие ценового бара, мы могли бы придумать два домена, которые объясняют эту взаимосвязь.
Если мы возьмем предыдущее поведение цены как многомерный набор данных, а изменения, которые мы хотим спрогнозировать, как одномерные, гомоморфизм между ними соединит обе области с задержкой обучения (training lag), равной, скажем, одному ценовому бару. Для большей ясности покажем это в виде диаграммы.

Это множество гомоморфизмов представляет собой многомерный домен, потому что при работе с несколькими точками данных (или даже с одной в некоторых случаях) у нас обязательно будут повторы в исходном домене. Для кодомена мы можем нормализовать все точки данных как целые числа в диапазоне от -100 до +100 как процентное представление величины результирующего изменения ценового диапазона. Эта нормализация означает, что у нас не будет повторов, поэтому элементы в домене кода можно отобразить следующим образом.
{-100, -80, -60, -40, -20, 0, 20, 40, 60, 80, 100}
Для общего размера 11. Мы можем продвинуть это множество гомоморфизмов еще на один шаг, рассматривая данные домена с более чем двумя измерениями. Предположим, при прогнозировании изменения диапазона ценового бара мы учитывали более одного лага? Взглянем на диаграмму ниже.

Это похоже на то, что у нас было выше, с той лишь разницей, что добавлены точки данных. В идеале нам нужно было бы обучить нашу модель накоплению достаточного количества точек данных в доменах и кодоменах. Чтобы использовать ее, мы могли бы использовать ряд методов при сопоставлении с кодоменом. В этой статье мы могли бы рассмотреть возможность использования подхода "победитель получает все" (winner takes-all) для выбора прогноза кодомена. Таким образом, такой подход будет точкой многомерных данных (которая просто представлена в виде вектора или массива, поскольку класс элементов является массивом) с ближайшим расстоянием от новых или текущих входных данных из всего состава домена. В коде это реализуется следующим образом.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int CTrailingCT::Morphisms_A(CHomomorphism<double,double> &H,CDomain<double> &D,CElement<double> &E,int CardinalCheck=4) { int _domain_index=-1,_codomain_index=-1; if(E.Cardinality()!=CardinalCheck){ return(_domain_index); } double _least_radius=DBL_MAX; for(int c=0;c<D.Cardinality();c++) { double _radius=0.0; m_element_a.Let(); if(D.Get(c,m_element_a)) { for(int cc=0;cc<E.Cardinality();cc++) { double _e=0.0,_d=0.0; if(E.Get(cc,_e) && m_element_a.Get(cc,_d)) { _radius+=pow(_e-_d,2.0); } } } _radius=sqrt(_radius); if(_least_radius>_radius) { _least_radius=_radius; _domain_index=c; } } // for(int m=0;m<H.Morphisms();m++) { m_morphism_ab.Let(); if(H.Get(m,m_morphism_ab)) { if(m_morphism_ab.Domain()==_domain_index) { _codomain_index=m_morphism_ab.Codomain(); break; } } } return(_codomain_index); }
Чтобы применить теорию категорий в этой модели, мы рассмотрим концепцию коммутации, которую уже затронули в предыдущих статьях. Если мы адаптируем диаграмму, показанную ниже, у нас будет мультидоменное расположение в гомоморфизмах π и π', а возможность коммутации просто означает, что у нас есть два способа проецировать изменения в ценовом диапазоне.
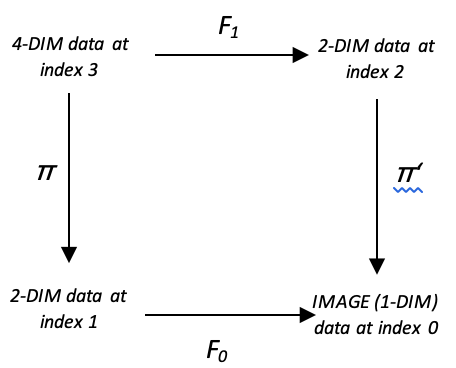
Применение этой особенности для получения прогноза становится возможным благодаря:
- Поиску среднего значения двух проекций
- Применения их максимума или
- Использования их минимума
Для общего кода мы предоставили возможность выбора между минимумом, средним значением и максимумом, как показано во фрагменте кода ниже.
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for short position. | //+------------------------------------------------------------------+ bool CTrailingCT::CheckTrailingStopShort(CPositionInfo *position,double &sl,double &tp) { //--- check if(position==NULL) return(false); Refresh(); m_element_a.Let(); m_element_b.Let(); m_element_c.Let(); m_element_bd.Let(); m_element_cd.Let(); SetElement_A(StartIndex(),m_element_a); int _b_index=Morphisms_A(m_multi_domain.ab,m_multi_domain.ab.domain,m_element_a,4); int _c_index=Morphisms_A(m_multi_domain.ac,m_multi_domain.ac.domain,m_element_a,2); SetElement_B(StartIndex(),m_element_b); SetElement_C(StartIndex(),m_element_c); int _b_d_index=Morphisms_D(m_multi_domain.bd,m_multi_domain.bd.domain,m_element_b,2); int _c_d_index=Morphisms_D(m_multi_domain.cd,m_multi_domain.cd.domain,m_element_c,2); int _bd=0,_cd=0; if(m_multi_domain.bd.codomain.Get(_b_d_index,m_element_bd) && m_element_bd.Get(0,_bd) && m_multi_domain.cd.codomain.Get(_c_d_index,m_element_cd) && m_element_cd.Get(0,_cd)) { m_high.Refresh(-1); m_low.Refresh(-1); int _x=StartIndex(); double _type=0.5*((_bd+_cd)/100.0); //for mean if(m_type==0){ _type=fmin(_bd,_cd)/100.0; } //for minimum else if(m_type==2){ _type=fmax(_bd,_cd)/100.0; } //for maximum double _atr=fmax(2.0*m_spread.GetData(_x)*m_symbol.Point(),m_high.GetData(_x)-m_low.GetData(_x))*(_type); double _sl=m_high.GetData(_x)+(m_step*_atr); double level =NormalizeDouble(m_symbol.Ask()+m_symbol.StopsLevel()*m_symbol.Point(),m_symbol.Digits()); double new_sl=NormalizeDouble(_sl,m_symbol.Digits()); double pos_sl=position.StopLoss(); double base =(pos_sl==0.0) ? position.PriceOpen() : pos_sl; sl=EMPTY_VALUE; tp=EMPTY_VALUE; if(new_sl<base && new_sl>level) sl=new_sl; } //--- return(sl!=EMPTY_VALUE); }
Если мы запустим тесты на EURGBP на дневном таймфрейме с 2022.01.01 по 2022.08.01 и воспользуемся простым сигналом, таким как встроенный Awesome Oscillator (SignalAO.mqh), мы получим следующий отчет.

В качестве контроля, если мы аналогичным образом запустим тот же сигнал, но с использованием одного из встроенных классов трейлинга, который использует скользящую среднюю, за тот же период и тот же дневной период с тем же типом задания размера позиции (фиксированная маржа), мы получим следующие результаты.

Это говорит о возможности использования нескольких доменов не только для прогнозирования изменений в диапазоне ценовых баров для обоснования решений по трейлинг-стопу, но, возможно, даже для принятия решений по управлению сигналами или капиталом. В этой статье мы рассмотрели только трейлинг-стопы. Я предлагаю читателям изучить два других способа применения самостоятельно.
Относительные домены
Относительные домены (relative domains) расширяют концепцию мультидоменов, но в Википедии еще нет страницы по этому вопросу. Однако если мы вернемся к нашему первому примеру, в котором использовалось простое предложение для определения нескольких доменов, мы бы сделали еще один шаг вперед, имея кодомен N в качестве словаря всех английских слов. Это означало бы, что любое английское предложение будет иметь гомоморфизм с N. Гомоморфизм предложения A в предложение B будет переводить каждое слово, найденное где-то в A, к тому же слову, которое находится где-то в B.
Хотя формально A, отображающий относительные домены на N, представленный как f: (E,π) à (E’,π’), представляют собой функцию f: E àE’, приводящую к перемещению следующего треугольника
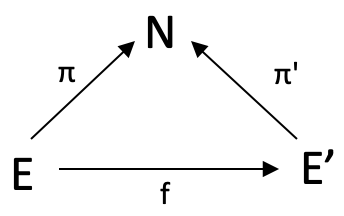
Чтобы проиллюстрировать это с трейдерской точки зрения, воспользуемся морфизмом f, изменив наше квадратное перемещение, использованное выше, чтобы оно представляло собой простой треугольник без домена D. При использовании f мы будем искать веса морфизмов между двумя доменами E и E', которые для наших демонстрационных целей, как и выше, являются многомерными данными с нулевым индексом и индексом 1. "Многомерность" просто означает, что мы измеряем и регистрируем более одной точки данных. В нашем случае это изменения максимумов и минимумов. Итак, поскольку мы уже знаем возможное изменение ценового диапазона для бара с индексом 1 (наш лаг), мы должны использовать морфизм f для преобразования нашей текущей точки данных, чье возможное изменение мы еще не знаем, и найти, какой из элементов в E' ближе всего к совпадению с ней. Элемент кодомена ближайшего совпадения по π' даст нам прогнозируемое изменение.
Тесты показывают следующие результаты.

Как вы можете заметить, отчет идентичен первому, однако в дополнительных тестах, которые я провел, были небольшие улучшения, которые здесь не публикуются. Имейте в виду, что все эти советники используют один и тот же сигнал входа (встроенный сигнал Awesome Oscillator) с единственным изменением в реализации трейлинг-стопа.
Индексированные домены
Индексированные домены (indexed domains) эквивалентны относительным доменам в том смысле, что они берут элементы домена N и превращают их в домены, так что каждый из этих новых доменов имеет отношение к элементам в E и E'. В качестве быстрого примера рассмотрим школу с набором классов (N). У каждого класса есть домен учеников, которые его посещают (E), и у каждого класса также есть домен стульев (E'). Таким образом, домены E и E' называются доменами с N-индексом из-за их отношения к классу.
Для трейдеров мы увеличим наш домен N, который имел 11 значений, до 11 доменов. Каждый домен будет фиксировать более мелкие приращения изменения ценового диапазона. Например, вместо элемента, представленного числом 40 (40% изменений), мы могли бы иметь 9 новых изменений в домене:
{32.5, 35.0, 37.5, 40.0, 42.5, 45.0, 47.5, 50.0}
Затем этот домен сопоставляется со всеми элементами в E и E', что в нашем случае в последнем примере представляло собой многомерные данные, фиксирующие изменения с одной и двумя задержками. Если мы сделаем шаг назад и рассмотрим более общие применения индексированных доменов для трейдеров, мы можем составить довольно большой список. Вот пять возможных вариантов использования.
Скользящие средние - популярный индикатор, используемый трейдерами для сглаживания краткосрочных колебаний рыночных данных и определения ценовых тенденций. Этот метод включает в себя вычисление средней цены актива внутри временного окна, а затем нанесение на график для выявления закономерностей и трендов.
Индексированные множества и теория категорий могут дать возможность взглянуть на скользящие средние иначе. Как уже упоминалось, индексированное множество — это набор элементов, которые индексируются другим доменом. В контексте скользящих средних индексированный домен может представлять собой разные периоды для расчета скользящей средней, поскольку каждый период представляет собой буфер периодов скользящей средней, который можно рассматривать как область.
Наши E и E' могут быть скользящей средней, рассчитанной по типичной цене, и скользящей средней, рассчитанной по медианной цене соответственно. Помимо двух, рассмотренных в этой статье, могут быть и другие такие домены, например, в данном случае MA по цене закрытия или средневзвешенной цене и так далее. Достаточно сказать, что эту классификацию субдоменов можно изучать вне теории категорий. Тем не менее, теория категорий вносит свой вклад в это исследование, сосредотачивая внимание на отношениях относительного домена. Морфизмы между E и E' (f), например, между MA медианной цены в период 21 и MA медианной цены, скажем, в период 34, могут иметь много применений. Одним из таких может быть построение ленты скользящей средней, с помощью которой, если мы отследим изменения весов в этих морфизмах, мы сможем посчитать, сколько тренду осталось для продолжения и скоро ли произойдет разворот.
В дополнение к применению в сопровождении открытых позиций путем классификации и прогнозирования волатильности цен, может быть полезно перечислить несколько других применений мульти- и индексированных доменов в теории категорий для трейдеров. Вот некоторые из них, касающиеся выбора входного сигнала.
- Анализ стакана цен. При регистрации ордеров на покупку и продажу в стакане цен как нескольких доменов (поскольку конкретная ценная бумага может быть куплена или продана в разное время и с разным распределением, что означает, что домен ценных бумаг будет иметь "повторы"), трейдер может определить, где сконцентрированы спрос и предложение на ценную бумагу. Если мультидомен на покупку больше, чем мультидомен на продажу, это может быть сигналом к покупке, а если мультидомен на продажу больше, это может быть сигналом к продаже.
- Анализ портфеля. Мультидомены могут представлять портфель трейдера, где каждый элемент представляет определенную ценную бумагу или актив (почему? Потому что каждая ценная бумага может быть хеджирована опционными контрактами или другими производными инструментами, что означает, что они появляются более одного раза). Проанализировав такой мультидомен ценных бумаг и сосредоточившись на их результатах, трейдер может принять решение о покупке большего количества ценных бумаг с хорошими показателями и закрытии позиций или даже открытии коротких позиций по ценным бумагам с низкими показателями.
- Управление рисками. Мультидомены могут отражать распределение риска по портфелю трейдера при просмотре, скажем, просадок производительности в прошлых торговых сессиях (каждый нормализованный диапазон просадок может появляться несколько раз в разных сессиях, что приводит к применению мультидоменов). Если мультидомен ценных бумаг с высоким риском больше, чем мультидомен ценных бумаг с низким риском, это может быть сигналом к продаже некоторых ценных бумаг с высоким риском и покупке некоторых ценных бумаг с низким риском.
- Торговые стратегии. Мультидомены могут представлять торговые стратегии, где каждый элемент является конкретным торговым решением, таким как размещение рыночных ордеров, отложенные ордера, стоп-ордер или фиксация прибыли (такие решения неизбежно повторяются, и последовательность, в которой они принимаются, имеет значение, что означает, что мультидомен поможет получить информацию об этой последовательности и поможет в дальнейшем анализе). Анализируя множество успешных сделок, трейдер может принять решение о реализации аналогичной длинной стратегии для этих сделок.
- Технические индикаторы. Мультидомены могут представлять технические индикаторы, такие как скользящие средние или полосы Боллинджера, регистрируя их нормализованные значения за изучаемый период (нормализованные значения для каждого интервала обязательно повторяются на протяжении исследуемого интервала и, отмечая последовательность этих повторений в пределах мультидомена, мы делаем анализ более полным). Если мультидомен значений конкретного технического индикатора выше или ниже определенного порога, это можно использовать как сигнал на покупку или продажу.
- Корреляции. Мультидомен может представлять корреляции между различными ценными бумагами или активами. Значения корреляции обычно находятся в диапазоне от -1,0 до +1,0, и если эти значения нормализовать, скажем, до первого десятичного знака, они дадут такие значения, как {1,0, 0,4, -0,7, 0,1,…} и т. д. Такие корреляции могут быть измерены для активов или во временных окнах одного и того же актива, что вновь означает неизбежность повторов. Размещая эти повторения в нескольких доменах, которые, скажем, имеют отношение к кодомену, в котором перечислены имена безопасности, анализ не упускает значимости каждого значения корреляции. Если мультидомен ценных бумаг, которые сильно коррелируют с ценными бумагами с бычьим импульсом, больше, чем у ценных бумаг с медвежьим импульсом, это может быть сигналом к покупке, а обратная ситуация сигнализирует о продаже.
- Анализ временных рядов. Мультидомены могут представлять данные временных рядов, что позволяет трейдерам анализировать тренды и закономерности с течением времени. Опять же, со временем у нас обязательно будут повторяться одни и те же шаблоны тренда, поэтому простое перечисление каждого из них один раз в домене не скажет вам, какой последовательности во временном ряду следует каждый шаблон. Таким образом, мультидомены были бы полезны здесь. Если значения за определенный период времени выше или ниже среднего, это может указывать на ситуацию перепроданности и быть сигналом к покупке или продаже при изменениях или учете дополнительных факторов в зависимости от стратегии.
- Анализ настроений. Мультидомены могут показывать настроения участников рынка. Если мы определяем настроение большинства участников, то это значение, если его правильно измерить и нормализовать (например, индекс волатильности CBOE (VIX)), обязательно будет повторяться в течение анализируемого периода. Если мультидомены охватывают все эти значения в их последовательности, а текущее положительное настроение больше, чем отрицательное, это может быть более четким сигналом к покупке из-за дополнительной зафиксированной информации в мультидомене, чем при использовании отдельных значений.
- Торговые сигналы. Мультидомены могут представлять торговые сигналы, если у вас есть более одного демо-счета, каждый из которых настроен на получение сигналов по подписке. Паттерны каждого сигнала на покупку и продажу в различных объемах обязательно будут повторяться при их изучении в виде таблицы. Типичный домен, который пропускает такие повторы, теряет такую информацию, как объем сделки, связанный с каждым решением по сигналу. Это может исказить анализ относительной эффективности этих сигналов.
- Рыночные данные. Мультидомены могут представлять рыночные данные, такие как объем, в установленные интервалы времени, особенно если суммы объемных контрактов нормализованы в квартили для упрощения интерпретации. Эти нормализованные суммы в течение периода проверки ценной бумаги обязательно повторяются. Поскольку мультидомены допускают такой повтор, становится легко провести более точный анализ с любым кодоменом, который вы выберете для сопряжения с доменом объема.
Также может быть полезно перечислить возможные варианты использования индексированных доменов для управления капиталом трейдеров:
- Взвешивание рыночной капитализации. Индексированные домены могут представлять рыночную капитализацию различных акций в портфеле. На приведенной выше диаграмме будет использоваться домен N. Домены E, E' и остальные будут представлять акции в пределах определенной группы рыночной капитализации. Функция f будет определять относительный размер акций в составе портфеля.
- Факторное инвестирование. Индексированные домены могут исследовать различные факторы, влияющие на эффективность акций или портфелей, такие как стоимость, импульс и рост. На приведенной выше диаграмме нормализованные контрольные показатели производительности будут находиться в N, в то время как E, E' и другие домены будут представлять факторы. Морфизм f устанавливает относительную важность каждого фактора.
- Паритет рисков. Подход паритета риска к построению портфеля направлен на распределение инвестиционного капитала на основе риска, чтобы оптимально диверсифицировать инвестиции, рассматривая риск и доходность всего портфеля как одно целое. В этом случае наш весовой коэффициент риска будет находиться в N. E, E' и другие домены будут представлять отдельные активы, а функция f будет определять относительный вес активов.
- Умная бета. Умная бета-версия стремится объединить преимущества пассивного инвестирования и активных стратегий инвестирования, используя правила построения индексов, альтернативные традиционным индексам, основанным на рыночной капитализации. Особое внимание уделяется устранению неэффективности рынка на основе правил и прозрачности. Домен N будет иметь нормализованные контрольные показатели производительности, в то время как E и E' могут быть активными и пассивными ETF соответственно. Функция f определяет их относительное взвешивание.
- Метод стоимостной оценки рисков (Value at risk, VaR). VaR — это способ количественной оценки риска потенциальных убытков по открытой торговой позиции. Эта метрика может быть рассчитана исторически, с использованием методов дисперсии-ковариации, или методом Монте-Карло. Инвестиционные банки обычно применяют моделирование VaR к риску в масштабах всей компании, так как отделы торговых операций могут непреднамеренно подвергнуть фирму излишнему риску, торгуя сильно коррелированными активам. Масштаб максимальных убытков будет в домене N. E и E' будут активами разных типов, например акциями и облигациями, а f может быть относительным весом портфеля, полученным на основе результатов прошлых сделок.
Заключение
Мы рассмотрели мультимножества, относительные множества и индексированные множества и их потенциальное применение для классификации и прогнозирования волатильности цен. До сих пор я избегали называть домены множествами. Хотя домены и более уместны, поскольку они являются общим термином для других "типов множеств", таких как топологии и симплициальные комплексы, и для других форматов, таких приложений и примеров в этом цикле статей у нас не будет. Поэтому в дальнейшем я буду использовать понятие "множество" для обозначения того, что называл доменами в этой и предыдущих статьях.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/12470
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Хорошая работа.
Рад, что вам понравилось. Будьте здоровы.
Жаль, что топологии и упрощенные комплексы не будут рассмотрены.