Нейросети — это просто (Часть 45): Обучение навыков исследования состояний

Введение
Алгоритмы иерархического обучения с подкреплением позволяют успешно решать довольно сложные задачи. Это достигается путем деление общей проблемы на более мелкие подзадачи. И одной из основных проблем в данном контексте является правильный выбор и обучение навыков, позволяющих агенту эффективно действовать и, по возможности, максимально управлять средой для достижения поставленной цели.
Ранее мы уже познакомились с 2 алгоритмами обучения навыков DIAYN и DADS. В первом случае мы обучали навыки с максимальным разнообразием поведения. И тем самым хотели обеспечить максимальное исследование окружающей среды. При этом мы были готовы обучать навыки, которые бесполезны для решения нашей текущей задачи.
Во втором алгоритме (DADS) мы подходили к обучению навыков с точки зрения их влияния на окружающую среду. Здесь мы стремились прогнозировать динамику среды и использовать навыки, которые позволяют получить максимальную выгоду из изменений.
В обоих случаях, навыки из априорного распределения использовались в качестве исходных данных для агента и исследовались в процессе обучения. Практическое использование подобного подхода демонстрирует недостаточное покрытие пространства состояний. Следовательно, обученные навыки не способны эффективно взаимодействовать со всеми возможными состояниями окружающей среды.
В данной статье я предлагаю познакомиться с альтернативным методом обучения навыков Explore, Discover and Learn (EDL). EDL подходит к решению задачи с другой стороны, что позволяет преодолеть проблему ограниченного покрытия состояний и предложить более гибкое и адаптивное поведение агента.
1. Алгоритм "Explore, Discover and Learn" (исследуй, открывай и учись)
Метод Exploration, Discovery, and Learning (EDL) был представлена в научной статье "Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills" в августе 2020 года. И предлагает подход, который позволяет агенту обнаруживать и учиться использовать различные навыки в среде без какого-либо предварительного знания о состояниях и навыках. Он также позволяет обучать разнообразные навыки, охватывающие различные состояния, что способствует более эффективному исследованию и обучению агента в неизвестной среде.
Метод EDL имеет фиксированную структуру и состоит из 3 основных этапов: исследование, открытие и обучение навыков.
В отсутствие каких-либо предварительных знаний об окружающей среде и необходимых навыках мы начинаем свое исследование. На данном этапе нам предстоит создать обучающую выборку исходных состояний с максимальным охватом различных состояний, соответствующих всевозможному поведению окружающей среды. В своей работе мы будем использовать равномерную выборку из состояний системы за обучающий период. Но возможны и другие походы. Особенно в случаях обучения конкретных режимов поведения агента. Следует отметить, что EDL не требует доступа к траекториям или действиям, сделанным экспертной стратегией. Но и не исключает их использование.
На втором этапе мы осуществляем поиск навыков, скрытых в конкретных состояниях окружающей среды. Основополагающей идеей данного метода является наличие некой связи между состоянием (или пространством состояний) окружающей среды и конкретным навыком, который агент должен эксплуатировать. И нам предстоит определить подобные зависимости.
Необходимо отметить, что на данном этапе у нас нет никаких знаний о состояниях окружающей среды. Есть только выборка таких состояний. А тем более у нас отсутствуют знания о необходимых навыках. В то же время ранее мы отмечали, что метод EDL предусматривает открытие навыков без учителя. Для поиска указанных зависимостей алгоритмом предусмотрено использование вариационного автоэнкодера. На в ходе и выходе модели будут состояния окружающей среды. А в латентном состоянии автоэнкодера мы ожидаем получить идентификацию скрытого навыка, который вытекает из текущего состояния окружающей среды. В данном подходе энкодер нашего автоэнкодера выстраивает функцию зависимости навыка от текущего состояния окружающей среды. А декодер модели выполняет обратную функцию и выстраивает зависимость состояния от используемого навыка. Использование вариационного автоэнкодера позволяет перейти от четкого соответствия "состояние-навык" к некоему вероятностному распределению. Что в целом повышает стабильность работы модели в сложном стохастическом окружении.
Таким образом, при отсутствии дополнительных знаний о состояниях и навыках, использование вариационного автоэнкодера в методе EDL предоставляет нам возможность исследовать и открывать скрытые навыки, связанные с различными состояниями окружающей среды. А выстраивание функции зависимости между состоянием окружающей среды и необходимым навыком позволит нам в будущем новые состояния окружающей среды интерпретировать в совокупность наиболее релевантных навыков.
Обратите внимание, что в ранее рассмотренных методах мы сначала обучали навыки. А затем планировщик искал стратегию использования готовых навыков для достижения поставленной цели. В методе EDL обратный подход. Мы сначала выстраиваем зависимости между состоянием и навыками. И только затем обучаем навыки. Это позволяет более точно соотнести навыки с конкретными состояниями окружающей среды и определить, какие навыки наиболее эффективно применять в определенных ситуациях.
Заключительным этапом алгоритма является обучение модели навыков (Агента). Здесь происходит обучение стратегии агента, которая максимизирует взаимную информацию между состояниями и скрытыми переменными. Обучение агента осуществляется методами обучения с подкреплением. Формирование вознаграждения построено аналогично методу DADS, но авторы метода провели небольшое упрощение формулы. Напомню, в DADS внутреннее вознаграждение агента формировалось по формуле:
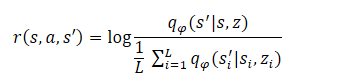
Из курса математики мы знаем, что
![]()
Следовательно:
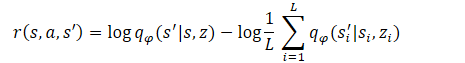
Как можно заметить, вычитаемое является константой для всех используемых навыков. Поэтому, для оптимизации политики мы можем использовать только уменьшаемое. Такой подход позволяет сократить объем вычислений без потери качества обучения модели.
![]()
Этот завершающий этап может быть рассмотрен как обучение стратегии, имитирующей декодер в рамках Марковского процесса принятия решений, то есть стратегии, которая будет посещать состояния, которые декодер сгенерирует для каждого скрытого навыка z. Следует отметить, что функция вознаграждения является фиксированной, в отличие от предыдущих методов, в которых она непрерывно изменяется в зависимости от поведения стратегии. Это делает процесс обучения более стабильным и повышает сходимость моделей.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов работы метода Exploration, Discovery, and Learning (EDL) мы переходим к практической части нашей статьи. И прежде чем приступить непосредственно к реализации метода средствами MQL5 необходимо немного рассказать об особенностях нашей реализации.
В разделе Тестирование предыдущей статьи была продемонстрирована близость результатов использования one-hot вектора и полного распределения для идентификации используемого навыка в исходных данных Агента. Это позволяет нам использовать тот или иной подход в зависимости от имеющихся у нас данных для снижения математических операций. Что в целом дает нам потенциальную возможность снижения количества выполняемых операций. А вместе с тем повышение скорости обучения и работы модели.
Второй момент, на который нужно обратить внимание, что на вход Планировщика и Агента мы подаём одни и те же исходные данные (исторические данные о движении цены, показатели индикаторов и состояние баланса). Правда на входе Агента к этим данным прибавляется ещё и идентификатор навыка.
С другой стороны, при изучении автоэнкодеров мы говорили, что латентное состояние автоэнкодера является сжатым представлением его исходных данных. То есть, конкатенируя вектор исходных данных с вектором латентных данных вариационного автоэнкодера мы дважды передаем одни и те же данные в их полном и сжатом представлении.
В случае использования аналогичных блоков предварительной обработки исходных данных такой подход может быть избыточным. И в данной реализации на вход Агента мы будем подавать только латентное состояние автоэнкодера, которое, по существу, уже содержит всю необходимую информацию. Это позволит нам значительно сократить объем выполняемых операций. А вместе с тем и общее время обучения моделей.
Конечно, такой подход возможен только при использовании аналогичных исходных данных на входе Планировщика и Агента. В принципе возможны и другие варианты. К примеру, автоэнкодер может выстраивать зависимости только между историческими данными и навыком без учета состояния счета. А на входе агента конкатенировать вектор латентного состояния автоэнкодера и вектора описания состояния счета. Не будет ошибкой и использование всех данных, как мы это делали при реализации ранее рассмотренных методов. В своей реализации вы можете экспериментировать с различными подходами.
Все подобные решения обязательно находят свое отражение в архитектуре моделей, которую мы указываем в функции CreateDescriptions. В параметрах методу мы передаем указатели на 2 динамических массива описания моделей планировщика и агента. Обратите внимание, при реализации метода EDL мы не создаем Дискриминатор, так как его роль выполняет декодер автоэнкодера (Планировщика).
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Первым мы создадим вариационный автоэнкодер Планировщика. На вход данной модели мы подаем исторические данные и состояние счета, что и отражается в размере слоя исходных данных. Как всегда, исходные данные проходят предварительную обработку в слое пакетной нормализации.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Далее идет сверточный блок для понижения размерности данных и выделения специфических признаков.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; }
Затем идут три полносвязных слоя с постепенным снижением размерности. Обратите внимание, что размер последнего слоя в 2 раза превышает количество обучаемых навыков. Это является отличительной особенностью вариационного автоэнкодера. Ведь в отличии от классического автоэнкодера, в вариационном автоэнкодере каждый признак представлен 2 параметрами: средним значением и дисперсией распределения.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Reparameterization trick осуществляется в следующем слое, который был создан специально для реализации вариационного автоэнкодера. Здесь же осуществляется и семплирование параметров из заданного распределения. Размер данного слоя соответствует количеству обучаемых навыков.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NSkills; if(!scheduler.Add(descr)) { delete descr; return false; }
Декодер реализован в виде 3 полносвязных слоев. Последний без функции активации, так как сложно определить функцию активации для ненормализованных данных.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!scheduler.Add(descr)) { delete descr; return false; }
Следует обратить внимание, что, как и при реализации предыдущего метода, мы не будем восстанавливать полностью исходные данные. Ведь влияние действий Агента на рыночную цену инструмента ничтожно мало. А состояние баланса, напротив, находится в прямой зависимости от используемой Агентом стратегии. Поэтому на выходе автоэнкодера мы будем восстанавливать только описание состояния счета.
После планировщика мы создаем описание архитектуры агента. Как уже было сказано выше, слой исходных данных Агента уменьшен до количества обучаемых навыков.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Использование скрытого состояния другой модели позволяет нам отказаться от блока предварительной обработки данных. Таким образом, сразу за слоем исходных данных идет блок принятия решений из 3 полносвязных слоев.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
На выходе модели мы используем блок полностью параметризированной квантильной функции, что позволяет более детально изучить распределение вознаграждений.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Как и ранее, функцию описания архитектуры моделей мы вынесли в включаемый файл "\EDL\Trajectory.mqh". Это позволяет нам использовать единую архитектуру моделей на всех этапах метода EDL.
После создания архитектуры моделей мы переходим к работе над экспертами для реализации изучаемого метода. Вначале мы создаем советник первого этапа — Исследования. Данный функционал выполняется в советнике "EDL\Research.mq5". Сразу скажем, что алгоритм данного советника практически полностью копирует одноименные советники из предыдущих статей. Но есть и отличия, обусловленные архитектурой моделей. В частности, в предыдущих реализациях алгоритм данного советника использовал только модель Агента, на вход которой подавались исходные данные и случайным образом сгенерированный идентификатор навыка. В данной реализации исторические данные мы подаём на вход планировщика. И после его прямого прохода мы извлекаем скрытое состояние, которое и подадим на вход Агента для принятия решения о действии. С полным кодом советника и всех его функций можно ознакомиться во вложении.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- if(!Scheduler.feedForward(GetPointer(State1), 1, false)) return; if(!Scheduler.GetLayerOutput(LatentLayer, Result)) return; //--- if(!Actor.feedForward(Result, 1, false)) return; int act = Actor.getSample(); //--- ........ ........ //--- }
Второй этап метода EDL — определение навыков. Как было сказано в теоретической части, на данном этапе мы будем обучать вариационный автоэнкодер. Этот функционал будет выполняться в советнике "StudyModel.mq5". Советник был создан на базе советников обучения моделей из предыдущих статей. Были лишь внесены изменения касательно алгоритма данного метода.
В функции OnInit инициализируется только одна модель Планировщика. Но основные изменения были внесены в функцию обучения модели Train. В начале функции мы, как и ранее объявляем внутренние переменны.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action;
Затем организовываем цикл обучения с количеством итераций, заданным во внешних параметрах советника.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
В теле цикла мы случайным образом выбираем из обучающей выборки сначала проход, а затем одно из состояний выбранного прохода. Данные описания выбранного состояния переносятся в буфер исходных данных для прямого прохода нашей модели. Данные итерации не отличаются от совершаемых нами ранее. Напомню, что информацию о состоянии счета мы заполняем в относительных величинах.
State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Далее мы определим прибыль на один лот от изменения цены в размере следующей свечи и сохраним в локальные переменные показатели баланса и эквити для последующих расчетов.
//--- bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1];
После завершения подготовительной работы мы осуществляем прямой проход нашей модели.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
За успешным осуществлением прямого прохода нам предстоит организовать обратный проход нашей модели. И здесь нам необходимо подготовить целевые значения нашей модели. И следуя логике обучения автоэнкодеров мы должны были бы использовать в качестве целевых значений буфер исходных данных. Но мы внесли изменения в архитектуру и логику обучения. Во-первых, на выходе мы генерируем не полный набор признаков исходных данных, а только параметры описания состояния счета.
Во-вторых, мы сделали небольшой шаг вперед. И хотели бы обучить модель генерировать прогнозное последующее состояние счета. При этом мы не будем генерировать состояние счета для всех возможных действий агента. На стадии обучения моделей мы можем "подглядеть" в обучающей выборке следующую свечу. И сделать максимально выгодное нам действие, которое бы максимизировало нашу прибыль. Таким образом мы формируем желаемое прогнозное состояние счета и используем его в качестве целевых значений обратного прохода модели.
if(prof_1l > 5 ) action = (prof_1l < 10 || Buffer[tr].States[i].account[6] > 0 ? 2 : 0); else { if(prof_1l < -5) action = (prof_1l > -10 || Buffer[tr].States[i].account[5] > 0 ? 2 : 1); else action = 3; } account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); Result.Clear(); Result.Add((account[0] - PrevBalance) / PrevBalance); Result.Add(account[1] / PrevBalance); Result.Add((account[1] - PrevEquity) / PrevEquity); Result.Add(account[2] / PrevBalance); Result.Add(account[4] / PrevBalance); Result.Add(account[5]); Result.Add(account[6]); Result.Add(account[7] / PrevBalance); Result.Add(account[8] / PrevBalance);
Обратите внимание, что при определении желаемого действия мы вводим ограничения:
- минимальная прибыль для открытия сделки,
- минимальное движение для закрытия сделки (выжидаем на небольших колебаниях),
- перед открытием новой позиции закрываем все противоположные сделки.
Таким образом, мы хотим сформировать прогнозную модель с желаемым поведением.
Сформированное прогнозное состояние счета мы переводим в плоскость относительных единиц и переносим в буфер данных. После чего осуществляем обратный проход нашей модели.
if(!Scheduler.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Как и ранее, в завершении итераций цикла мы выводим информационное сообщение для визуального контроля пользователем процесса обучения модели.
После завершения всех итераций цикла обучения модели мы очищаем блок комментариев на графике и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом советника обучения вариационного автоэнкодера планировщика можно ознакомиться во вложении.
После определения зависимостей между состояниями среды и навыками нам предстоит обучить нашего Агента необходимым навыкам. Этот функционал мы организуем в советнике "EDL\StudyActor.mq5". Сразу скажу, что в данном советнике мы эксплуатируем 2 модели (Планировщик и Агент). А обучать будем только одну (Агента). Поэтому в методе инициализации советника мы предварительно загружаем 2 модели. Но критическое завершение программы вызывает только невозможность загрузить Планировщик, который должен быть уже предварительно обучен.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load scheduler model: %d", GetLastError()); return INIT_FAILED; }
При возникновении ошибки загрузки модели Агента мы инициализируем создание новой модели.
if(!Actor.Load(FileName + "Act.nnw", dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *scheduler = new CArrayObj(); if(!CreateDescriptions(actor, scheduler)) { delete actor; delete scheduler; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete scheduler; return INIT_FAILED; } delete actor; delete scheduler; //--- }
И конечно, после загрузки или создания новой модели мы проверяем соответствие размеров нейронных слоев исходных данных и результатов выполняемого моделями функционалу.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } Actor.SetOpenCL(Scheduler.GetOpenCL()); Actor.SetUpdateTarget(MathMax(Iterations / 100, 10000)); //--- Scheduler.getResults(Result); if(Result.Total() != AccountDescr) { PrintFormat("The scope of the scheduler does not match the account description (%d <> %d)", AccountDescr, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); int inputs = Result.Total(); if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("Error of load latent layer %d", LatentLayer); return INIT_FAILED; } if(inputs != Result.Total()) { PrintFormat("Size of latent layer does not match input size of Actor (%d <> %d)", Result.Total(), inputs); return INIT_FAILED; }
После успешной загрузки и инициализации моделей. А также после прохождения всех контролей мы инициализируем событие начала процесса обучения модели и завершаем работу функции инициализации советника.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Процесс обучения Агента организован в методе Train. Первая часть метода включает выбор прохода, состояния и организация прямого прохода планировщика описана выше и в данный советник перенесена без изменений. Поэтому мы пропустим данный блок и сразу перейдем к организации прямого прохода нашего агента. Здесь все довольно просто. Мы лишь извлекаем латентное состояние автоэнкодера и передаем полученные данные на вход нашего Агента. При этом не забываем контролировать процесс выполнения операций.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { ........ ........ //--- if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Actor.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
После успешного выполнения операций прямого прохода нам предстоит организовать обратный проход модели нашего агента. Как было сказано в теоретическом блоке, обучение агента осуществляется методами обучения с подкреплением. И нам предстоит организовать формирование вознаграждений для сгенерированных при прямом проходе действий. Методом EDL предполагается обучение Агента на основе вознаграждений, генерируемых Дискриминатором. В данном случае его роль выполняет декодер автоэнкодера планировщика. Однако, мы сделали небольшое отступление от предложенного авторами метода принципа формирования вознаграждения. Что в целом не противоречит идеологии метода.
Как уже было сказано выше, в процессе обучения автоэнкодера мы использовали желаемое расчетное состояние нашего счета с учетом введенных ограничений. Сейчас же мы будем вознаграждать такое поведение агента, которое максимально нас приблизит к желаемому результату. И в качестве меры между желаемым и прогнозным состояниями нашего баланса мы будем использовать эвклидову метрику расстояния между 2 векторами. А чтобы максимальную награду получало действие, максимально приближающее нас желаемому состоянию, в качестве вознаграждения мы умножим полученное расстояние на "-1".
Такой подход позволяет нам организовать цикл и заполнить вознаграждения для всех возможных действий Агента, а не только для одного отдельно взятого действия. Что в целом повысит стабильность и производительность процесса обучения модели.
Scheduler.getResults(SchedulerResult); ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); reward[0] = reward[0] / PrevBalance - 1.0f; reward[3] = reward[2] / PrevBalance; reward[2] = reward[1] / PrevEquity - 1.0f; reward[1] /= PrevBalance; reward[4] /= PrevBalance; reward[7] /= PrevBalance; reward[8] /= PrevBalance; reward=MathPow(SchedulerResult - reward, 2.0); ActorResult[action] = -reward.Sum(); }
После завершения цикла перебора всех возможных действий агента мы получаем вектор расстояний от расчетных состояний после каждого возможного действия Агента до желаемого состояния, спрогнозированного нашим автоэнкодером. Напомню, что расстояния мы записали с обратным знаком. Поэтому максимальное расстояние у нас максимально отрицательное. Или попросту минимальное значение. Если мы вычтем данное минимальное значение из каждого элемента вектора, то обнулим вознаграждение для действия, максимально удаляющего нас от желаемого результата. А все остальные вознаграждения переведем в область положительных значений без изменения их структуры.
ActorResult = ActorResult - ActorResult.Min();
В данном случае мы намеренно не используем SoftMax. Ведь перевод в область вероятностей сохранит только структуру и нивелирует влияние самого удаления от желаемого результата. А это влияние имеет большую важность в процессе построения общей стратегии.
Кроме того, необходимо учитывать, что прогнозные состояния автоэнкодера не полностью соответствуют реальной стохастичности окружающей среды. Поэтому важно оценивать качество прогнозирования автоэнкодера. Качество обучения агента, в конечном счете, зависит от соответствия между прогнозируемыми состояниями автоэнкодера и реальными состояниями окружающей среды, с которыми агент взаимодействует.
Также хочу напомнить, что при построении своей стратегии Агентом учитывается не только текущее вознаграждение, но совокупная возможность получения вознаграждения до конца эпизода. И в данном случае мы будем использовать целевую модель (Target Net) для определения стоимости следующего состояния. Этот функционал уже реализован в модели полностью параметризированной квантильной функции. Но для его нормального функционирования нам необходимо в метод обратного прохода передать следующее состояние системы.
В данном случае нам необходимо сначала осуществить прямой проход автоэнкодера с использование следующего состояния системы из буфера воспроизведения опыта.
State.AssignArray(Buffer[tr].States[i+1].state); State.Add((Buffer[tr].States[i+1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i+1].account[1] / PrevBalance); State.Add((Buffer[tr].States[i+1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i+1].account[2] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[4] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[5]); State.Add(Buffer[tr].States[i+1].account[6]); State.Add(Buffer[tr].States[i+1].account[7] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[8] / PrevBalance); //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
И только потом мы можем извлечь сжатое представление следующего состояния системы из латентного состояния автоэнкодера. А затем осуществляем обратный проход нашего Агента.
if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } State.AssignArray(Result); Result.AssignArray(ActorResult); if(!Actor.backProp(Result,DiscountFactor,GetPointer(State),1,false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Далее мы информируем пользователя о ходе процесса обучения Агента и переходим к следующей итерации цикла.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения процесса обучения Агента мы очищаем поле комментариев и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом советника можно ознакомиться во вложении.
3. Тестирование
Тестирование эффективности подхода мы провели на исторических данных за 4 первых месяца 2023 года инструмента EURUSD. Как всегда, мы использовали таймфрейм H1. Параметры всех индикаторов использовались по умолчанию. Начале мы собрали базу примеров из 50 проходов. Среди которых были как прибыльные, так и убыточные проходы. Напомню, что ранее мы стремились использовать только прибыльные проходы. Тем самым мы хотели обучить навыки, способные генерировать прибыль. В данном случае мы добавили в базу примеров несколько убыточных проходов с целью продемонстрировать модели убыточные состояния. Ведь в реальной торговле мы допускаем риск просадок. Но хотели бы иметь стратегию выхода из них с минимальными потерями.
Затем мы осуществили обучение моделей. Сначала автоэнкодера, а потом агента.
Проверка работы обученной модели осуществлялось в тестере стратегий на исторических данных за май 2023 года. Эти данные не входили в обучающую выборку и позволяют проверить работу моделей на новых данных.
Надо сказать, что первые результаты оказались хуже наших ожиданий. К положительным результатам можно отнести довольно равномерное распределение используемых навыков на тестовой выборке. Но на этом заканчиваются положительные итоги нашего тестирования. После целого ряда итераций обучения автоэнкодера и агента нам так и не удалось получить модель, способную генерировать прибыль на обучающей выборке. Очевидно, проблема заключалась в неспособности автоэнкодера прогнозировать состояния с достаточной точностью. И в результате кривая баланса далека от желаемого результата.
Чтобы проверить наше предположение был создан альтернативный советник обучения агента "EDL\StudyActor2.mq5". Единственное отличие альтернативного варианта от ранее рассмотренного заключается в алгоритме формирования вознаграждения. Мы так же использовали цикл для прогнозирования изменения состояния счета. Только в этот раз в качестве вознаграждения мы использовали показатель относительного изменения баланса.
ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); ActorResult[action] = reward[0]/PrevBalance-1.0f; }
Агент, обученный с использованием измененной функции вознаграждения, показал довольно ровный прирост доходности на протяжении всего периода тестирования.


Важно отметить, что обучение агента с измененным подходом к формированию вознаграждения осуществлялось без переобучения автоэнкодера и изменения архитектуры самого агента. То есть обучение обоих агентов осуществлялось полностью в сопоставимых условиях. И только пересмотр подходов к формированию вознаграждения позволил повысить результативность модели. Что лишний раз подтверждает важность правильного выбора функции вознаграждения, которая играет ключевую роль в методах обучения с подкреплением.

Заключение
В данной статье мы познакомились с ещё одним методом обучения навыков Explore, Discover and Learn (EDL). Представленный алгоритм позволяет агенту исследовать окружающую среду и открывать новые навыки без предварительных знаний о состояниях или необходимых навыках. Это становится возможным благодаря использованию вариационного автоэнкодера для поиска зависимостей между состояниями окружающей среды и необходимыми навыками.
На первом этапе метода осуществляется исследование окружающей среды. Формируется обучающая выборка состояний с максимальным охватом различных состояний, соответствующих различным поведениям. Затем, средствами вариационного автоэнкодера осуществляется поиск зависимостей между состояниями и навыками. Латентное состояние автоэнкодера служит сжатым представлением состояний и своеобразным идентификатором необходимого навыка. Декодер и энкодер модели формируют функции зависимости между состояниями и навыками.
Обучение агента в рамках осуществляется путем стремления получить состояние, спрогнозированное автоэнкодером. Прогнозные состояния, предоставляемые автоэнкодером, лишены стохастичности, присущей реальной окружающей среде, что повышает стабильность и скорость обучения агента. В то же время это является узким местом подхода. Так как результативность модели сильно зависит от качества прогнозирования состояний автоэнкодером. Что и было продемонстрировано в процессе тестирования.
На сегодняшний день финансовые рынки являются довольно сложными и стохастическими средами, сложными к прогнозированию. И инвестирование в них остается высокорискованным. Достижение положительных результатов в торговле возможно лишь благодаря строгому соблюдению взвешенной и сбалансированной стратегии.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | StudyModel.mq5 | Советник | Советник обучения модели автоэнкодера |
| 3 | StudyActor.mq5 | Советник | Советник обучения агента |
| 4 | StudyActor2.mq5 | Советник | Альтернативный советник обучения агента (изменена функция вознаграждения) |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | FQF.mqh | Библиотека класса | Библиотека класса организации работы полностью параметризированной модели |
| 8 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 9 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 10 | VAE.mqh | Библиотека класса | Библиотека класса латентного слоя вариационного автоэнкодера |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Есть сообщения в журнале агентов тестирования? На некоторых этапах прерывания инициализации советник выводит сообщени.
Очистил все журналы тестера и запустил оптимизацию Research за первые 4 месяца 2023 года на EURUSD H1.
Запускал на реальных тиках:
Результат: всего 4 выборки, 2 в плюсе и 2 в минусе:
Может я что-то не так делаю, не те параметры оптимизирую или что-то не то с терминалом у меня? Непонятно... Пытаюсь повторить ваши результаты как в статье...
Ошибки начинаются в самом начале.
Сет и результат оптимизации, а также журналы агентов и тестера прилагаю в архиве Research.zip
Очистил все журналы тестера и запустил оптимизацию Research за первые 4 месяца 2023 года на EURUSD H1.
Запускал на реальных тиках:
Результат: всего 4 выборки, 2 в плюсе и 2 в минусе:
Может я что-то не так делаю, не те параметры оптимизирую или что-то не то с терминалом у меня? Непонятно... Пытаюсь повторить ваши результаты как в статье...
Ошибки начинаются в самом начале.
Сет и результат оптимизации, а также журналы агентов и тестера прилагаю в архиве Research.zip
1. Я ставил полную оптимизацию, а не быструю. Это позволяет осуществить полный перебор заданных параметров. И, соответственно, проходов будет больше.
2. То, что при запуске Research есть прибыльные и убыточные проходы - нормально. При первом запуске нейронная сеть инициализируется случайными параметрами. Настройка модели осуществляется в процессе обучения.
Проблема в том, что вы запускаете "tester.ex5". Он проверяет качество обученных моделей, а у Вас их ещё нет. Сначала нужно запустить Research.mq5 для создания базы примеров. Затем StudyModel.mq5, который обучит автоэнкодер. Актер обучается в советнике StudyActor.mq5 или StudyActor2.mq5 (отличаются функцией вознаграждения. И только потом будет работать tester.ex5. Обратите, в параметрах последнего нужно указать модель актера Act или Act2. Зависимости от советника, используемого для обучения Актера.
Дмитрий добрый день!
Подскажите а как понять что прогресс обучения вообще идеёт? Проценты ошибки в обучении с подкреплением имеют значение или здесь смотреться по фактическому результату торговли сети?
Сколько Вы учили циклов (StudyModel.mq5 -> StudyActor2.mq5 ) пока получился адекватный результат?
Вы в статье указали что изначально собрали базу из 50 проходов. Производили ли Вы дополнительные сборы в процессе тренировки? Вы дополняли базу начальную или удаляли и пересоздавали в процессе обучения?
Вы всегда в каждом проходе используете 100 000 итераций или меняете число от прохода к проходу? От чего это зависит?
Я проучил сеть 3 дня, Сделал циклов наверное 40-50. Результат как на скриншёте. Иногда она просто выдаёт прямую линию (не открывает и не закрывает сделки). Ещё бывает она открывает много сделок и не закрывает их. Меняется только эквити. Базу примеров пробовал разную. Пробовал создать 50 примеров и потом делать циклы. Пробовал создать 96 примеров и добавлял через каждых 10 циклов ещё по 96 примеров, и так до 500. Результат одинаков. Кук её учить? Что я делаю не так?
Дмитрий добрый день!
Подскажите а как понять что прогресс обучения вообще идеёт? Проценты ошибки в обучении с подкреплением имеют значение или здесь смотреться по фактическому результату торговли сети?
Сколько Вы учили циклов (StudyModel.mq5 -> StudyActor2.mq5 ) пока получился адекватный результат?
Вы в статье указали что изначально собрали базу из 50 проходов. Производили ли Вы дополнительные сборы в процессе тренировки? Вы дополняли базу начальную или удаляли и пересоздавали в процессе обучения?
Вы всегда в каждом проходе используете 100 000 итераций или меняете число от прохода к проходу? От чего это зависит?
Я проучил сеть 3 дня, Сделал циклов наверное 40-50. Результат как на скриншёте. Иногда она просто выдаёт прямую линию (не открывает и не закрывает сделки). Ещё бывает она открывает много сделок и не закрывает их. Меняется только эквити. Базу примеров пробовал разную. Пробовал создать 50 примеров и потом делать циклы. Пробовал создать 96 примеров и добавлял через каждых 10 циклов ещё по 96 примеров, и так до 500. Результат одинаков. Кук её учить? Что я делаю не так?
Та же фигня...
Потратил несколько дней, но результат такой же.
Как ее учить непонятно...
Получить результат как в статье, так и не удалось...