
Нейросети — это просто (Часть 43): Освоение навыков без функции вознаграждения

Введение
Обучение с подкреплением (Reinforcement Learning) является мощным подходом в области машинного обучения, который позволяет агенту самостоятельно обучаться, взаимодействуя с окружающей средой и получая обратную связь в виде функции вознаграждения. Однако, одной из ключевых проблем в обучении с подкреплением является необходимость определения функции вознаграждения, которая формализует желаемое поведение агента.
Определение функции вознаграждения может быть сложным искусством, особенно в задачах, где требуется достижение множества целей или существуют неоднозначные ситуации. Кроме того, некоторые задачи могут не иметь явной функции вознаграждения, что затрудняет применение традиционных методов обучения с подкреплением.
В этой статье мы предлагаем познакомиться с концепцией "Diversity is All You Need" (Разнообразие — всё, что вам нужно), которая позволяет обучать модель навыкам без явной функции вознаграждения. Разнообразие действий, исследование окружения и максимизация изменчивости взаимодействий с окружением являются ключевыми факторами для обучения агента эффективному поведению.
Этот подход предлагает новую перспективу на обучение без функции вознаграждения и может быть полезным в решении сложных задач, где определение явной функции вознаграждения затруднено или невозможно.
1. Концепция "Diversity is All You Need"
В реальной жизни, чтобы исполнитель мог выполнять определенные функции, необходимы определенные знания и навыки. Аналогично, при обучении модели мы стремимся развить навыки, необходимые для решения поставленной задачи.
В обучении с подкреплением главным инструментом для стимулирования модели является функция вознаграждения. Она позволяет агенту понимать, насколько успешными были его действия. Однако часто вознаграждение поступает редко, и для поиска оптимальных решений требуются дополнительные подходы. Мы уже рассмотрели некоторые методы стимулирования модели к исследованию окружающей среды, но они не всегда эффективны.
Модели, обученные традиционным способом, обладают узкой специализацией и способны решать только конкретные задачи. При небольших изменениях в постановке задачи, требуется полное переобучение модели, даже если уже имеющиеся навыки могут быть полезны. То же самое происходит при изменении окружающей среды.
Один из возможных ответов на эту проблему — использование иерархических моделей, состоящих из нескольких блоков. В таких моделях мы создаем отдельные модели для различных навыков и планировщик, который управляет использованием этих навыков. Обучение планировщика позволяет решать новые задачи с использованием ранее обученных навыков. Однако здесь возникают вопросы о достаточности и качестве предварительно обученных навыков, так как для решения новых задач могут потребоваться дополнительные навыки.
Концепция "Diversity is All You Need" предлагает использовать иерархические модели с отдельными навыками и планировщиком. Он подчеркивает максимальное разнообразие действий и изучение окружающей среды, что позволяет агенту эффективно учиться и адаптироваться. Благодаря обучению разнообразным и различимым навыкам модель становится более гибкой и адаптивной, способной использовать разные стратегии в различных ситуациях. Этот подход полезен, когда определение явных вознаграждений является сложной задачей, позволяя модели автономно исследовать и находить новые решения.
Центральной идеей этой концепции является использование разнообразия как инструмента для обучения. Разнообразие в действиях и поведении модели позволяет ей исследовать пространство состояний и обнаруживать новые возможности. При этом разнообразие не ограничивается случайными или неэффективными действиями, а нацелено на обнаружение различных полезных стратегий, которые могут быть применены в разных ситуациях.
Принцип "Diversity is All You Need" подразумевает, что разнообразие является ключевым компонентом успешного обучения без явной функции вознаграждения. Модель, обученная на разнообразных навыках, становится более гибкой и адаптивной, способной применять различные стратегии в зависимости от контекста и требований задачи.
Этот подход имеет потенциал применения в решении сложных задач, где определение явной функции вознаграждения затруднено или недоступно. Он позволяет модели самостоятельно исследовать окружающую среду, обучаясь различным навыкам и стратегиям, что может привести к открытию новых путей и решений.
Еще одним постулатом, лежащим в основе концепции "Diversity is All You Need", является предположение о том, что текущее состояние модели зависит не только от конкретного выбранного действия, а также от используемого навыка. То есть, вместо простого связывания действия и состояния, модель учится ассоциировать определенные состояния с определенными навыками.
Алгоритм концепции состоит из двух этапов. Сначала происходит неуправляемое обучение разнообразным навыкам без связи с конкретной задачей, что позволяет основательно изучить окружающую среду и расширить поведенческий репертуар агента. Затем следует этап контролируемого обучения с подкреплением, нацеленный на достижение максимальной эффективности модели в решении поставленной цели.
На первом этапе мы проводим обучение модели навыков. Входные данные модели состоят из текущего состояния окружающей среды и конкретного выбранного навыка для применения. Модель генерирует соответствующее действие, которое затем выполняется. Результатом этого действия является переход в новое состояние среды. На данном этапе нас интересует только это новое состояние, а внешнее вознаграждение не используется.
Вместо этого мы применяем модель дискриминатора, которая по новому состоянию старается определить, какой навык был использован на предыдущем шаге. Кросс-энтропия между результатами дискриминатора и one-hot вектором, соответствующим применяемому навыку, служит в качестве вознаграждения для нашей модели навыков.
Обучение модели навыков осуществляется при помощи методов обучения с подкреплением, таких как Актер-Критик. Модель дискриминатора, с другой стороны, обучается с использованием классических методов обучения с учителем.
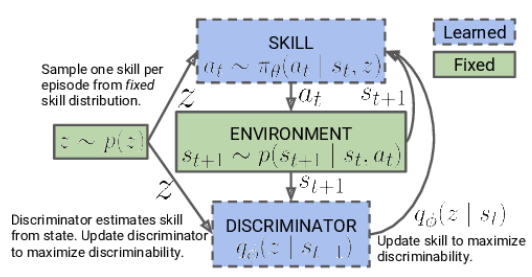
В начале обучения модели навыков мы работаем с фиксированной базой навыков, которая не зависит от текущего состояния. Это связано с тем, что мы ещё не обладаем информацией о навыках и их полезности в различных состояниях. Наша задача состоит в изучении этих навыков. При разработке архитектуры модели мы определяем количество навыков, которые будут обучаться.
В процессе обучения модели навыков агент активно исследует и заполняет каждый навык на основе информации, полученной из окружающей среды. Мы подаем идентификаторы навыков в модель случайным образом, чтобы она могла изучать и заполнять каждый навык независимо от других.
Модель использует полученные идентификаторы навыков и текущее состояние среды для определения соответствующего действия, которое следует выполнить. Она учится ассоциировать определенные навыки с конкретными состояниями и выбирать действия для каждого навыка.
Важно отметить, что в начале обучения модель не обладает предварительными знаниями о навыках или их полезности в конкретных состояниях. Она самостоятельно изучает и определяет связи между навыками и состояниями в процессе обучения. При этом используется функция вознаграждения, которая способствует максимальному разнообразию поведения агента в зависимости от применяемого навыка.
После завершения этапа обучения модели навыков мы переходим к следующему этапу, который представляет собой контролируемое обучение с подкреплением. На этом этапе мы обучаем модель планировщика с целью максимизации заданной цели или получения максимальной награды в рамках конкретной задачи. В этом процессе мы можем использовать фиксированную модель навыков, что позволяет ускорить процесс обучения модели планировщика.
Таким образом, двухэтапный подход обучения модели навыков, начиная с неконтролируемого заполнения навыков и завершая контролируемым обучением с подкреплением, позволяет модели самостоятельно изучать и использовать навыки в рамках различных задач.
Заметьте, что в нашем подходе мы изменили иерархический процесс принятия решений по сравнению с ранее рассмотренной иерархической моделью. Ранее мы использовали несколько агентов, каждый из которых обладал своими собственными навыками. Агенты предлагали варианты действий, и затем планировщик оценивал эти варианты и принимал окончательное решение.
В текущем подходе мы изменили эту последовательность. Теперь сначала планировщик анализирует текущую ситуацию и принимает решение о выборе подходящего навыка. Затем агент, основываясь на выбранном навыке, принимает решение о соответствующем действии.
Таким образом, мы инвертировали иерархический процесс: теперь планировщик принимает решение об используемом навыке, а затем агент выполняет действие, соответствующее выбранному навыку. Это изменение позволяет нам эффективно управлять и использовать навыки в зависимости от текущей ситуации.
2. Реализация средствами MQL5
После теоретического обзора мы переходим к практической реализации нашей работы. Как и в предыдущей статье, мы начинаем с создания базы примеров, которую будем использовать для обучения модели. Сбор данных осуществляется советником "DIAYN\Research.mq5", который является модифицированной версией советника из предыдущей статьи. Однако, в текущем алгоритме есть некоторые отличия.
Первое изменение, которое мы внесли, связано с архитектурой моделей. Мы внесли модификации в архитектуру, чтобы она отвечала новым требованиям и идеям, вытекающим из концепции "Diversity is All You Need".
В процессе обучения мы используем три модели:
- Модель агента (навыков). Она отвечает за обучение и осуществление различных навыков в соответствии с текущим состоянием среды.
- Планировщик, который принимает решения на основе оценки ситуации и выбирает подходящий навык для выполнения задачи. Планировщик работает в сотрудничестве с моделью навыков и управляет принятием решений на более высоком уровне.
- Дискриминатор, который используется только в процессе обучения модели навыков и не применяется в реальном времени. Он используется для предоставления обратной связи и служит для вычисления вознаграждения во время обучения.
Важно отметить, что модель навыков и планировщик являются основными моделями, которые используются в процессе промышленной эксплуатации и решении задач. Дискриминатор же используется только для улучшения обучения модели навыков и не применяется в фактической работе системы.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler, CArrayObj *discriminator) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- if(!discriminator) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Согласно алгоритму "Diversity is All You Need", модели агента (модели навыков) подается вход буфер данных, содержащий описания текущего состояния и идентификатора используемого навыка. В контексте нашей работы мы передаем следующую информацию:
- Исторические данные ценового движения и индикаторов: Эти данные предоставляют информацию о прошлых изменениях цен на рынке и значениях различных индикаторов. Они служат важным контекстом для принятия решений моделью агента.
- Информация о текущем состоянии счета и открытых позициях: Эти данные включают информацию о текущем балансе счета, открытых позициях, размере позиций и других финансовых показателях. Они помогают модели агента учитывать текущее положение и ограничения при принятии решений.
- One-hot вектор идентификации навыка: Этот вектор представляет собой бинарное представление идентификатора используемого навыка. Он указывает на конкретный навык, который модель агента должна применить в данном состоянии.
Для обработки такого входа необходим слой исходных данных достаточного размера, который позволит модели агента получить всю необходимую информацию о состоянии рынка, финансовых данных и выбранном навыке для принятия оптимальных решений.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
После получения исходных данных мы создаем слой нормализации данных, который играет важную роль в обработке входных данных перед их передачей модели агента. Слой нормализации данных позволяет привести разные исходные признаки к одному масштабу. Что позволит обеспечить стабильность и согласованность данных. Это важно для эффективной работы модели агента и получения качественных результатов.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Подготовленные исходные данные могут обрабатываться с использованием блока сверточных слоев.
Сверточные слои — это ключевой компонент в архитектуре моделей глубокого обучения, особенно в задачах обработки изображений и последовательностей. Они позволяют извлекать пространственные и локальные зависимости из исходных данных.
В случае нашего алгоритма "Diversity is All You Need", сверточные слои могут быть применены к историческим данным ценового движения и индикаторам, чтобы извлечь важные паттерны и тренды. Это помогает агенту уловить взаимосвязи между различными временными шагами и принять решение на основе обнаруженных закономерностей.
Каждый сверточный слой состоит из 4 фильтров, которые сканируют входные данные с определенным окном. В результате применения сверточных операций получается набор карт признаков, которые выделяют важные характеристики данных. Подобные преобразование позволяют модели агента обнаруживать и учитывать важные особенности данных в контексте задачи обучения с подкреплением.
Сверточные слои обеспечивают модели агента способность "увидеть" и сфокусироваться на значимых аспектах данных, что является важным шагом в процессе принятия решений и выполнения соответствующих действий в рамках концепции "Diversity is All You Need".
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
После прохождения через блок сверточных слоев, данные подвергаются обработке в блоке принятия решений, который состоит из трех полносвязных слоев. В процессе пропуска данных через полносвязные слои, модель агента способна изучать сложные зависимости и обнаруживать взаимосвязи между различными аспектами данных.
На выходе блока принятия решений используется FQF (Fully Parameterized Quantile Function). Эта модель используется для оценки квантилей распределения будущих вознаграждений или целевых переменных. Она позволяет модели агента получать оценки не только средних значений, но и прогнозировать различные квантили, что полезно для моделирования неопределенности и принятия решений в условиях стохастичности.
Использование полностью параметризированной модели FQF на выходе блока принятия решений позволяет модели агента получать более гибкие и точные предсказания, которые могут быть использованы для оптимального выбора действий в рамках концепции "Diversity is All You Need".
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель планировщика выполняет классификацию текущего состояния окружающей среды для определения используемого навыка. В отличие от модели агента, планировщик имеет упрощенную архитектуру без использования сверточных слоев для предварительной обработки данных, что позволяет сэкономить ресурсы.
Входные данные для планировщика аналогичны данным агента за исключением вектора идентификации навыка. Планировщик получает описание текущего состояния окружающей среды, включая исторические данные ценового движения, индикаторы, а также информацию о текущем состоянии счета и открытых позициях.
Классификация состояния среды и определение используемого навыка выполняется путем передачи данных через полносвязные слои и блок FQF. Результаты нормализуются с помощью функции SoftMax. Что приводит к получению вектора вероятностей, отражающего вероятность принадлежности состояния к каждому возможному навыку.
Таким образом, модель планировщика позволяет определить, какой навык следует использовать на основе текущего состояния окружающей среды. Это дальше помогает модели агента принять соответствующее решение и выбрать оптимальное действие в соответствии с концепцией "Diversity is All You Need".
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Для диверсификации навыков мы используем третью модель — Дискриминатор. Ее задача заключается в вознаграждении наиболее неожиданных действий, что способствует разнообразию поведения Агента. Точность данной модели не требуется на высоком уровне, поэтому мы принимаем решение еще больше упростить ее архитектуру и исключить блок FQF.
В архитектуре Дискриминатора мы используем только слой нормализации и полносвязные слои. Это позволяет сократить вычислительные ресурсы, при этом сохраняя способность модели классифицировать. На выходе модели мы применяем функцию SoftMax для получения вероятностей принадлежности действий к различным навыкам.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- return true; }
После описания архитектуры моделей мы можем перейти к организации процесса сбора данных для обучения. На первом этапе сбора данных мы будем использовать только модель Агента, поскольку у нас нет никакой первичной информации об окружающей среде. Вместо этого мы можем эффективно использовать случайно сгенерированный вектор идентификации навыка, который будет давать сравнимые результаты с использованием необученной модели. Это также позволит нам значительно сократить использование вычислительных ресурсов.
В методе OnTick организован непосредственный процесс сбора данных. В начале метода мы проверяем, произошло ли событие открытия нового бара, и, если это так, мы загружаем исторические данные.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Аналогично предыдущей статье, мы загружаем информацию о текущем состоянии в два массива: массив исторических данных state и массив информации о состоянии счета account структуры sState.
MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Полученную структуру мы сохраняем в базу примеров для последующего обучения моделей. Для передачи исходных данных в модель Агента необходимо создать буфер данных. В данном случае мы начинаем с загрузки исторических данных в этот буфер.
State1.AssignArray(sState.state);
Для обеспечения более устойчивой и одинаково эффективной работы модели с разными размерами счетов было принято решение привести информацию о состоянии счета к относительным единицам. Для этого мы внесем некоторые изменения в показатели состояния счета.
Вместо абсолютного значения баланса мы будем использовать коэффициент изменения баланса. Это позволит учесть относительное изменение баланса во времени.
Также мы заменим показатель эквити на отношение эквити к балансу. Это поможет учесть относительную долю эквити относительно баланса и сделать показатель более сопоставимым между разными счетами.
Кроме того, мы добавим отношение изменения эквити к балансу, что позволит учесть изменение относительного эквити во времени.
Наконец, введем отношение накопленной прибыли/убытков к балансу, чтобы учесть относительную величину накопленных результатов торговли относительно баланса счета.
Эти изменения позволят создать более универсальную модель, способную эффективно работать с различными размерами счетов и учитывать их относительное состояние.
State1.Add((sState.account[0] - prev_balance) / prev_balance); State1.Add(sState.account[1] / prev_balance); State1.Add((sState.account[1] - prev_equity) / prev_equity); State1.Add(sState.account[3] / 100.0f); State1.Add(sState.account[4] / prev_balance); State1.Add(sState.account[5]); State1.Add(sState.account[6]); State1.Add(sState.account[7] / prev_balance); State1.Add(sState.account[8] / prev_balance);
В завершении подготовки данных для модели мы создадим случайный one-hot вектор, который будет служить идентификатором навыка. One-hot вектор представляет собой бинарный вектор, в котором только один элемент равен 1, а остальные элементы равны 0. Это позволяет модели различать и идентифицировать разные навыки на основе значения элемента, соответствующего конкретному навыку.
Создание случайного one-hot вектора гарантирует разнообразие и различие идентификаторов навыков в каждом примере данных, что соответствует нашей концепции "Diversity is All You Need".
vector<float> one_hot = vector<float>::Zeros(NSkills); int skill=(int)MathRound(MathRand()/32767.0*(NSkills-1)); one_hot[skill] = 1; State1.AddArray(one_hot);
На этом этапе мы передаем подготовленные исходные данные в модель Актера и выполняем прямой проход (forward pass) через модель. Прямой проход представляет собой процесс передачи входных данных через слои модели и получения соответствующих выходных значений.
После выполнения прямого прохода мы получаем результаты модели, которые представляют вероятности для каждого действия, определенные моделью Актера. Для выбора действия к выполнению мы семплируем (выбираем случайным образом с учетом вероятностей) одно из возможных действий на основе полученных вероятностей.
Семплирование действий позволяет Актеру максимально исследовать окружающую среду с учетом каждого навыка. Это способствует повышению разнообразия действий, которые модель может предпринять, и помогает избежать слишком частого выбора одних и тех же действий. Такой подход обеспечивает модели большую гибкость и способность адаптироваться к различным ситуациям в окружающей среде.
if(!Actor.feedForward(GetPointer(State1), 1, false)) return; int act = Actor.getSample();
Дальнейший код метода был взят из предыдущей версии советниника без каких-либо изменений. Полный код советника, включая все его методы, можно найти в приложенном файле.
В предыдущих статьях уже был подробно описан процесс сбора базы примеров, поэтому мы не будем повторяться и сразу перейдем к разработке советника "DIAYN\Study.mq5" для обучения моделей. В основном, мы использовали ранее разработанный код, однако внесли значительные изменения в метод обучения под названием Train.
Важно отметить, что мы немного отклонились от оригинального алгоритма, предложенного авторами метода. В нашем советнике мы параллельно обучаем модель навыков и планировщика. Конечно же, вместе с ними обучается и дискриминатор, согласно концепции "Diversity is All You Need".
Таким образом, мы стремимся достичь разнообразия в навыках и поведении моделей, чтобы получить более устойчивые и эффективные результаты.
Как и ранее, обучение моделей происходит внутри цикла. Количество итераций этого цикла определяется во внешних параметрах советника.
На каждой итерации цикла обучения мы случайным образом выбираем проход и состояние из базы примеров. После выбора состояния мы загружаем исторические данные о ценовых движениях и индикаторах в буфер данных аналогично тому, как это делается в советнике для сбора данных.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State1.AssignArray(Buffer[tr].States[i].state);
Также мы добавляем данные о состоянии счета и открытых позициях в тот же буфер данных. Как было упомянуто ранее, мы переводим эти данные в относительные единицы, чтобы обеспечить более устойчивую работу моделей с разными размерами счетов. Это позволяет нам унифицировать представление состояния счета и открытых позиций в модели и обеспечить их сопоставимость для обучения.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State1.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State1.Add(Buffer[tr].States[i].account[1] / PrevBalance); State1.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State1.Add(Buffer[tr].States[i].account[3] / 100.0f); State1.Add(Buffer[tr].States[i].account[4] / PrevBalance); State1.Add(Buffer[tr].States[i].account[5]); State1.Add(Buffer[tr].States[i].account[6]); State1.Add(Buffer[tr].States[i].account[7] / PrevBalance); State1.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Подготовленных данных достаточно для модели планировщика, и мы можем выполнить прямой проход через модель для определения используемого навыка.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Scheduler.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После выполнения прямого прохода моделью планировщика и получения вектора вероятностей, мы формируем one-hot вектор идентификации навыка. Здесь у нас есть два варианта выбора навыка: "жадный" метод выбора, который выбирает навык с наибольшей вероятностью, и семплирование, при котором мы выбираем навык случайным образом с учетом вероятностей.
В стадии обучения рекомендуется использовать семплирование для максимального исследования окружающей среды. Это позволяет модели исследовать различные навыки и обнаружить скрытые возможности и оптимальные стратегии. В процессе обучения семплирование помогает избежать преждевременной сходимости к определенному навыку и обеспечивает более разнообразные исследовательские действия, способствуя обучению более гибкой и адаптивной модели.
int skill = Scheduler.getSample(); SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; State1.AddArray(SchedulerResult);
Получившийся вектор идентификации навыка добавляется в буфер исходных данных, который передается на вход модели Агента. После этого выполняется прямой проход модели Агента для генерации действия. Вероятностное распределение, полученное из модели, используется для семплирования действия.
Семплирование действия из вероятностного распределения позволяет модели Агента принимать разнообразные решения, основываясь на вероятностях каждого действия. Это способствует исследованию различных стратегий и поведенческих вариантов, а также помогает модели избегать преждевременной фиксации на определенном действии.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } int action = Actor.getSample();
После выполнения прямого прохода модели Агента мы переходим к формированию буфера данных для прямого прохода модели Дискриминатора, где будет описано следующее состояние системы. Подобно предыдущему шагу, мы начинаем с загрузки исторических данных в буфер. В данном случае мы просто копируем исторические данные из базы примеров в буфер данных без каких-либо проблем, поскольку эти показатели не зависят от модели и используемых навыков.
State1.AssignArray(Buffer[tr].States[i + 1].state);
С описанием состояния счета у нас возникают некоторые сложности. Мы не можем просто взять данные из базы примеров, так как они редко будут соответствовать выбранному действию. Аналогично, мы не можем просто подставить действие из базы примеров, так как дискриминатор будет анализировать состояние, полученное на вход, и сопоставлять его с используемым навыком. Здесь возникает разрыв.
Однако, важно отметить, что результат работы дискриминатора используется только в качестве функции вознаграждения. Нам не требуется высокая точность в описании нового состояния баланса счета. Вместо этого, нам необходима сопоставимость данных при выполнении различных действий. Поэтому мы можем приближенно оценить значения показателей состояния счета на основе предыдущего состояния с учетом размер последней свечи и выбранного действия. Все необходимые данные для расчета у нас уже есть.
На первом этапе мы копируем данные счета из предыдущего состояния и рассчитываем прибыль для длинной позиции при движении цены на величину последней свечи. Здесь мы не учитываем конкретный объем позиции и ее направление, это будет учтено позже.
vector<float> account; account.Assign(Buffer[tr].States[i].account); int bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT);
Затем мы вносим корректировки в данные о состоянии счета в зависимости от выбранного действия. Простейший случай - закрытие позиций. Мы просто добавляем накопленную прибыль или убыток к текущему состоянию счета. Полученное значение затем переносится в элементы эквити и свободной маржи, а остальные показатели обнуляются.
При выполнении торговой операции нам необходимо увеличить соответствующую позицию. Учитывая, что все сделки совершаются с минимальным лотом, мы увеличиваем размер соответствующей позиции на минимальный лот.
Для расчета накопленной прибыли или убытка по каждому направлению мы умножаем ранее рассчитанную прибыль для одного лота на размер соответствующей позиции. Поскольку ранее была рассчитана прибыль для длинной позиции, мы добавляем это значение к предыдущей накопленной прибыли для длинных позиций и вычитаем для коротких позиций. Суммарная прибыль по счету получается путем сложения прибылей по разным направлениям.
Эквити рассчитывается как сумма баланса и накопленной прибыли.
Показатели маржи остаются без изменений, поскольку изменение на минимальный лот будет незначительным.
В случае удержания позиции подход аналогичен, за исключением изменения объема позиции.
switch(action) { case 0: account[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 1: account[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 2: account[0] += account[4]; account[1] = account[0]; account[2] = account[0]; for(bar = 3; bar < AccountDescr; bar++) account[bar] = 0; break; case 3: account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; }
После корректировки данных о состоянии баланса и открытых позиций мы добавляем их в буфер данных. При этом, как и ранее, мы переводим их значения в относительные единицы и проводим прямой проход модели дискриминатора.
PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; State1.Add((account[0] - PrevBalance) / PrevBalance); State1.Add(account[1] / PrevBalance); State1.Add((account[1] - PrevEquity) / PrevEquity); State1.Add(account[3] / 100.0f); State1.Add(account[4] / PrevBalance); State1.Add(account[5]); State1.Add(account[6]); State1.Add(account[7] / PrevBalance); State1.Add(account[8] / PrevBalance); //--- if(!Discriminator.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После прямого прохода дискриминатора мы сравниваем его результаты с one-hot вектором, который содержит идентификацию навыка, используемого при прямом проходе агента.
Discriminator.getResults(DiscriminatorResult);
Actor.getResults(ActorResult);
ActorResult[action] = DiscriminatorResult.Loss(SchedulerResult, LOSS_CCE);
Значение кросс-энтропии, полученное при сравнении двух векторов, используется в качестве вознаграждения для выбранного действия. Это вознаграждение позволяет нам провести обратный проход модели агента и обновить ее веса с целью улучшения выбора действий в будущем.
Result.AssignArray(ActorResult); State1.AddArray(SchedulerResult); if(!Actor.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
One-hot вектор идентификации, который представляет используемый навык, является целевым значением при обучении модели дискриминатора. Мы используем этот вектор в качестве цели, чтобы обучить дискриминатор правильно классифицировать состояния системы в соответствии с выбранным навыком.
Result.AssignArray(SchedulerResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
В качестве вознаграждения для планировщика мы используем только изменение баланса счета. Мы рассчитываем эту величину точно и передаем ее в виде относительных значений. Однако, в отличие от агента, которому передается вознаграждение только по выбранному действию, мы распределяем вознаграждение планировщика по всем навыкам, исходя из вероятностей выбора каждого навыка. Таким образом, вознаграждение планировщика разделяется между навыками в соответствии с их вероятностями выбора.
Result.AssignArray(SchedulerResult * ((account[0] - PrevBalance) / PrevBalance)); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
По завершении каждой итерации цикла обучения, мы генерируем информационное сообщение, содержащее данные о процессе обучения. Это сообщение выводится на график для визуализации процесса. Затем мы переходим к следующей итерации, продолжая процесс обучения.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
По достижении завершения процесса обучения, мы выполняем очистку сообщений на графике, удаляя предыдущие информационные данные. Затем инициируется завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Discriminator", Discriminator.getRecentAverageError()); ExpertRemove(); //--- }
Во вложении представлен полный код всех методов и функций, используемых в советнике. Вы можете ознакомиться с ним для получения подробной информации.
3. Тестирование
Модель была обучена на исторических данных инструмента EURUSD с таймфреймом H1 в течение первых четырех месяцев 2023 года. В процессе обучения была обнаружена непоказательная ошибка работы модели агента, связанная с политикой вознаграждения, которая может приводить к неограниченному росту вознаграждения. Тем не менее, процесс обучения все еще контролируется показателями моделей планировщика и дискриминатора.
Второй особенностью процесса является отсутствие прямой зависимости между выбором планировщика и совершаемым действием. Выбор планировщика в большей степени влияет на выбор стратегии, чем на конкретное действие. Это означает, что планировщик определяет общий подход к принятию решений, в то время как конкретное действие выбирается моделью агента на основе текущего состояния и выбранного навыка.
Для проверки работоспособности обученной модели мы использовали данные первых двух недель мая 2023 года, которые не были включены в обучающую выборку, но тесно следуют за периодом обучения. Этот подход позволяет оценить работу модели на новых данных, при этом данные остаются сопоставимыми, поскольку между обучающей и тестовой выборками нет временного разрыва.
Для тестирования мы использовали модифицированный советник "DIAYN\Test.mq5". Внесенные изменения затронули только алгоритмы подготовки данных в соответствии с архитектурой моделей и процесс подготовки исходных данных. Также была изменена последовательность вызова прямых проходов моделей. Процесс построен аналогично описанным ранее советникам для сбора базы примеров и обучения моделей. Подробный код советника доступен во вложении.


В результате тестирования обученной модели была достигнута небольшая прибыль, с профит-фактором 1.61 и фактором восстановления 3.21. За 240 баров тестового периода модель совершила 119 сделок, при этом почти 55% из них были закрыты с прибылью.
Значительную роль в достижении этих результатов сыграл планировщик, который равномерно распределял использование всех навыков. Важно отметить, что для выбора действий и навыков использовалась жадная стратегия. Модель выбирала наиболее прибыльное действие на основе текущего состояния.

Заключение
Данная статья представила подход к обучению торговой модели на основе DIAYN (Diversity Is All You Need) метода, который позволяет обучать модель разнообразным навыкам без привязки к конкретной задаче.
Модель была обучена на исторических данных по инструменту EURUSD с использованием таймфрейма H1 в течение первых 4 месяцев 2023 года.
В процессе обучения модели было выявлено отсутствие прямой зависимости между выбором планировщика и совершаемым действием. Тем не менее, процесс обучения оставался контролируемым и показал некоторую способность модели к прибыльной торговле.
После завершения обучения модель была протестирована на новых данных, которые не входили в обучающую выборку. Результаты тестирования показали небольшую прибыль, профит-фактор 1.61 и фактор восстановления 3.21. Однако, для достижения более стабильных и высоких результатов требуется дальнейшая оптимизация и улучшение стратегии модели.
Важным аспектом работы модели был планировщик, который равномерно распределял использование всех навыков. Это подчеркивает важность разработки эффективных стратегий принятия решений для достижения успешных результатов в торговле.
В целом, представленный подход к обучению торговой модели на основе DIAYN метода предоставляет интересные перспективы для развития автоматизированной торговли. Дальнейшие исследования и улучшения данного подхода могут привести к созданию более эффективных и прибыльных торговых моделей.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mql5 | Советник | Советник обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | FQF.mqh | Библиотека класса | Библиотека класса организации работы полностью параметризированной модели |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте, спасибо за проделанную работу. Можно ли сразу задать нейросети задачу делить стратегию по торговым сессиям?
Добрый вечер,
Если хотите настроить четко по времени, можно добавить one-hot вектор идентификации сессии и конкатенировать его вектором исходных данных.
Второй вариант, добавить к исходным данным тайм-эмбединг. Его можно настроить с желаемой периодичностью. Для торговых сессий подойдет период в сутки. Для сезонности, можно настроить на год.