(PF-1)*SdDay - ограничения сверху для того, чтоб этот коэффициент не захватил основной объем показателя Vigoda. - 1. Указывает на явное использование неверной зависимости от Профит Фактора. Чем больше сделок, тем сложнее добиться большой прибыльности. - 2. Cформулируем по-другому, тем сложнее добится случайного результата с большой прибыльностью.
(PF-1) - делается для того, чтоб при отрицательном показателе баланса, множитель PF тоже был отрицательным. - 3. Отрицательный баланс имеет минус, а профит фактор < 1 - это имеет смысл и методически оправдано. Смысл перегружать одно другим? Это идет как первый показатель, по этому следующие должны также влиять на объем общего, и не иметь какой-то свой перевес. -
((PipBar+Ust)/10) - при открытии позиции время не в нашу пользу, т.к. рынок может поменяться в любую минуту, и показатель PipBar (теперь я его переделал на PipMin, пункт/мин.) как раз и показывает качество используемого времени, т.е. максимальное кол-во пунктов за минимальное время. - 4. Обратная зависимость критерия от длины тестируемого периода проще и понятнее. Ust - устойчивость также не мало важна, чем выше показатель, тем значит плавнее рост баланса. - 5. Прибыль деленая на максимальную просадку никак не вяжется с плавностью роста баланса. Я бы так не называл это. Деление на 10 выравнивает влияние на общую сумму. - 6. Эта 10-ка результат каких-то статистических формульных вычислений или среднепотолочная эмпирика по типу "подогнать примерно"?
(ProcDay*10)/(MD+(SrD*4)) - соотношение скорости роста баланса к использованным рискам во время этого. 4. Обратная зависимость критерия от длины тестируемого периода проще и понятнее. Умножения на 10 и 4, также для выравнивания влияния на общий показатель. - 6. Эти 10-ка и 4-ка результат каких-то статистических формульных вычислений или среднепотолочная эмпирика по типу "подогнать примерно"?
Если использовать вместо сложения умножение, то сложнее отбалансировать влияние каждого показателя, от этого итог иногда неоправданно скачет.Поверьте уже все проверено, если один параметр слегка завышен, то при умножении он часто вытягивает общий итог не на ту верхушку. - 1. Указывает на явное использование неверной зависимости от Профит Фактора, Профита, Максимальной просадки, Длины тестируемого периода.
Я продолжаю корректировать формулу и позже выложу обновления и сравнения...
MD - один из самых важных показателей. И наша задача выявить честность этого показателя. Что это значит? Объясняю на примере: предположим у нас два похожих друг на друга прохода, у обоих одинаковая просадка, и все остальное так же где-то рядом, изначально нет принципиальной разницы. На самом деле в одном из проходов просадка подогнана в притирку от опасных сделок (которые не открылись, и мы их не видим) - прошу пояснить, что такое опасная сделка, которая не открылась и котрую мы не видим, и как её на чистую воду выводит SrD? - а в другом наоборот просадка в основном маленькая, и только в одной случайной сделке она дошла до такого же уровня - уровня опасной сделки, так ведь?. В итоге мы получаем в корне разные два прохода. Если представить что просадка каждой сделки это штриховка, то SrD как раз и определяет плотность и радиус этой штриховки, и наглядно показывает что максимальная просадка к примеру 15% случайно совпала еле вытягиваясь из статистических 25-30% (которые не открылись в миллиметре от сигнала, и мы их не видим) или наоборот случайно проскользнувшая из 5-10% (максимально открытых всех позиций). - Я приводил примеры просадок 1-11-1-11-... против 6-6-6-6-... Я полагаю, что для них SrD одинаковое, но вот первый пример как раз именно тот, который дергает эти ваши опасные сделки, или не так?
PF - также один из самых важных показателей. И оптимизация его может получить запросто, также обходя опасные сделки в миллиметре. По мне так лучше открывать все сделки и получить PF 1.8. Но чтоб видеть все опасные и безопасные сделки, - у вас есть определение опасных и безопасных сделок и когда они открываются? Выше вы их связываете с просадкой. Сложно понять, что это. а уж на деле (после оптимизации), немного сузить сигнал и получить PF 2-3. В оптимизации жизнь для ТС должна быть жесткой, а на деле можно и облегчить труд. Тем более что убыточные сделки здесь уже не нужны... "Тяжело в учении - легко в бою" как говориться, вот так должно быть... - Интуитивно, я понимаю, чего вы желаете добиться. Сомневаюсь, что для оптимизации вы ставите параметр PF=1.8 и он вам делает прогон с PF=1.8, а для работы вы устанавливаете PF=2-3. Нет, конечно, оптимизационные и рабочие варианты отличаются другими параметрами. И вам кажется, что при оптимизационном режиме вы собираете "опасные и безопасные" сделки, убеждаетесь, что все тип-топ, а потом как бы выключаете "опасные" сделки и в уме держите - класс, я осведомлен об "опасных" сделках, я их контролирую, ведь, я их выключил в рабочем варианте, и если они даже возникнут, то они мне не угроза. Это иллюзия. Мне она напоминает анекдот про "Что делаю? Отгоняю крокодилов - Так их отродясь тут не было - Так это потому, что я их так хорошо отгоняю. А по-научному, любое высказывание о любом элементе пустого множества верно. Все что вы не придумаете о сделках, которых не было, которые не открылись в рабочем варианте и в любом другом, - все будет верно. Ваше "лучше открывать все сделки" показывает вам реальность при одном наборе оптимизируемых параметров. "Немного сузить сигнал" - другую реальность, в которой нет сделок из первой. Эти несуществующие сделки, которые не открылись при узком сигнале, существуют только в вашем воображении. И естественно, вы осведомлены о них, что они "существуют", что все под контролем - вы их отпугнули "сузив сигнал". Попробуйте понять, что в условиях "узкого сигнала" неоткрывшихся сделок нет, их свойств мы не знаем, но воображать о них мы можем что угодно. Интуитивно хочется приоткрыть дверь и вглянуть на эти неоткрывшиеся опасные сделки, но приоткрывая дверь - расширяя сигнал, мы меняем реальность. Я бы не тратил время на попытку взвешивания фантомов. Исходите из фактов. Для каждого прогона они свои.
PipBar - объясняю важность на примере. Опять же два похожих друг на друга прохода, да же кол-во сделок одинаково. Только в одном проходе сделки в среднем открываются, пол дня межуются, потом закрываются хорошо. В другом открываются, через 5-10минут происходит скачок, и закрываются также в плюсе. Получается одна и та же прибыль, но при кардинально разном использовании времени. Хотя период тестирования у них одинаковый (год к примеру). PipBar - прозрачно показывает качество использованного времени, т.е. ТС занимает деньги у баланса для совершения сделки на минимальный срок с максимальной отдачей! - Желание понятно, но методологический подход неверен. Расчитайте стоимость денег, которую вы одолжили у депозита на сделку(и) и сравните её с чем-то такой же природы, т.е. снова стоимостью чего вам покажется правильным. Или умножьте обратную величину стоимости на критерий - чем больше стоимость, тем хуже. Так ведь? А вы её к устойчивости прибавляете. То, что вы делаете, это попытка вымучать калибровкой коэффициентов критерий по вот такому типу: максимальная скорость/стоимость авто + количество подушек безопасности / расход топлива на 100 км + мощность /% по кредиту
(PF-1)*SdDay - 从上面的限制,所以这个系数没有抓住维高达指标的大部分。交易越多,就越难实现高利润率。
(PF-1) - 它用于在出现负余额的情况下使PF乘数为负数。它作为第一个指标,基于这个原因,下面的指标也应该影响总量,而不是有一些普遍性。
((PipBar+Ust)/10) - 开仓时 时间对我们不利,因为市场可能随时变化,而PipBar指标(现在改为PipMin,点/分钟)显示了所使用时间的质量,即在最短的时间内获得最大的点数。Ust也很重要,数值越高,平衡的增长就越平稳。除以10可以平衡对整体平衡的影响。
(ProcDay*10)/(MD+(SrD*4))- 平衡增长的速度与期间使用的风险的比率。乘以10和4,也是为了均衡对总数的影响。
如果你用乘法而不是加法,就更难平衡每个指标的影响,这有时会导致总数不必要的跳跃。相信我,这已经被测试过了,如果一个参数被稍微高估了,当乘以这个参数时,往往会把总数拉到错误的顶部。
我不断调整公式,以后会发布更新和比较......
(PF-1)*SdDay - ограничения сверху для того, чтоб этот коэффициент не захватил основной объем показателя Vigoda. - 1. Указывает на явное использование неверной зависимости от Профит Фактора. Чем больше сделок, тем сложнее добиться большой прибыльности. - 2. Cформулируем по-другому, тем сложнее добится случайного результата с большой прибыльностью.
(PF-1) - делается для того, чтоб при отрицательном показателе баланса, множитель PF тоже был отрицательным. - 3. Отрицательный баланс имеет минус, а профит фактор < 1 - это имеет смысл и методически оправдано. Смысл перегружать одно другим? Это идет как первый показатель, по этому следующие должны также влиять на объем общего, и не иметь какой-то свой перевес. -
((PipBar+Ust)/10) - при открытии позиции время не в нашу пользу, т.к. рынок может поменяться в любую минуту, и показатель PipBar (теперь я его переделал на PipMin, пункт/мин.) как раз и показывает качество используемого времени, т.е. максимальное кол-во пунктов за минимальное время. - 4. Обратная зависимость критерия от длины тестируемого периода проще и понятнее. Ust - устойчивость также не мало важна, чем выше показатель, тем значит плавнее рост баланса. - 5. Прибыль деленая на максимальную просадку никак не вяжется с плавностью роста баланса. Я бы так не называл это. Деление на 10 выравнивает влияние на общую сумму. - 6. Эта 10-ка результат каких-то статистических формульных вычислений или среднепотолочная эмпирика по типу "подогнать примерно"?
(ProcDay*10)/(MD+(SrD*4)) - соотношение скорости роста баланса к использованным рискам во время этого. 4. Обратная зависимость критерия от длины тестируемого периода проще и понятнее. Умножения на 10 и 4, также для выравнивания влияния на общий показатель. - 6. Эти 10-ка и 4-ка результат каких-то статистических формульных вычислений или среднепотолочная эмпирика по типу "подогнать примерно"?
Если использовать вместо сложения умножение, то сложнее отбалансировать влияние каждого показателя, от этого итог иногда неоправданно скачет.Поверьте уже все проверено, если один параметр слегка завышен, то при умножении он часто вытягивает общий итог не на ту верхушку. - 1. Указывает на явное использование неверной зависимости от Профит Фактора, Профита, Максимальной просадки, Длины тестируемого периода.
Я продолжаю корректировать формулу и позже выложу обновления и сравнения...
让我用一个简单的例子告诉你,你会意识到你的方法是不正确的。
资产负债表上的数字对我们很有价值,因为我们把它与我们的 "更多的钱 "的梦想相比较。平衡和 "更多的钱 "是同一性质的,平衡越大,越接近 "更多的钱"。
最大缩水指标对我们很有价值,因为我们把它与我们的噩梦--"损失的存款 "进行比较。最大跌幅和 "损失的存款 "同样具有相同的性质,跌幅越低,我们离 "损失的存款 "就越远。
利润因素对我们很有价值,因为我们在其中比较了所有利润的总和与所有损失的总和。令人惊讶的是,所有利润的总和和所有损失的总和又是相同性质的指标,我们的利润越多,损失越少,这个指标对我们就越有价值。
我认为,你已经理解了比较(加、除、乘)同质指标、相同性质的指标的重要性。否则将是一片混乱。
现在让我们回到你的SrD。用他的例子,我想向你指出,仅仅因为我们知道如何计算所有交易的平均缩减量而引入一个指标,就像病人的平均体温一样贴切。你能解释一下SrD为估值增加了什么吗?在我看来--绝对没有。缩减1,11,1,11,1,11,...。将相当于为你的SrD提供6,6,6,6,6,6,6,...的缩减。我不认为你会发现这里有任何支持者会同意这一估计。特别是如果存款的死亡是以10的缩减量出现的。你了解最大缩水的价值吗?它表明你的存款离死亡有多远,以及它在完成时是活着还是死了。SrD本身并不能说明什么,因为你没有把它与相同性质的指标进行比较,而只是把它挂在空中,没有进行估计,所以它没有价值。如果你真的想输入这样的东西,试着计算SrProfit并与SrD进行比较,但不是与MD进行比较,当然也不是与余额增长率进行比较。
一旦你有了这些指标,它们就应该被乘以。如果一个指标对你来说比另一个更重要,那么你应该为它使用一个更 "强大 "的功能。例如,将较重的指标平方,或从较轻的指标中取对数,取平方根,等等。使用函数对一个指标施加权重是一个品味和偏好的问题。这样的乘法背后没有统计学,它只是一个有意义的粗略近似--标准与对你很重要的指标的比例关系。但你所做的--将利润除以条数,再加上增长率除以不同的缩水,试图用10和4的眼睛来规范化--如果你的计算背后有一个严格的数学公式,这将是真的。到目前为止,你的公式甚至不是一个粗略的近似值,因为它没有指标。
Vita писал(а) >>
现在回到你的SrD。用他的例子,我想向你指出,仅仅因为我们知道如何计算所有交易的平均缩减量而引入一个指标,就像病人的平均体温一样贴切。你能解释一下SrD给估值增加了什么吗?在我看来--绝对没有。缩减1,11,1,11,1,11,...。将相当于为你的SrD提供6,6,6,6,6,6,6,...的缩减。我不认为你会发现这里的支持者会同意这一估计。特别是如果存款的死亡是以10的缩减量出现的。你了解最大缩水的价值吗?它表明你的存款离死亡有多远,以及它在完成时是活着还是死了。SrD本身并不能说明什么,因为你没有把它与相同性质的指标进行比较,而只是把它挂在空中,没有进行估计,所以它没有价值。如果你真的想输入这样的东西,试着计算SrProfit并与SrD进行比较,但不要与MD进行比较,当然也不要与余额增长率进行比较。
MD是最重要的指标之一。而我们的任务就是要揭示这个指标的诚实性。它是什么意思?让我举例说明:假设我们有两张类似的通行证,都有相同的缩水,其他一切都很接近,最初没有根本的区别。事实上,在其中一个通道中,缩水是针对危险的交易进行调整的(这些交易还没有开盘,我们没有看到),而在另一个通道中,缩水大部分是小的,只有在一个随机交易中达到了相同的水平。因此,我们得到了截然不同的两个通道。如果我们把每笔交易的缩减想象成一个孵化器,SrD只是定义了这个孵化器的密度和半径,它明显地显示出,例如15%的最大缩减几乎没有从统计学上的25-30%(在距离信号几毫米的地方没有开仓,我们看不到它)中抽出,或者反过来说,意外地从5-10%(所有仓位都已最大限度地开仓)中滑落。
PF也是最重要的指标之一。而且它的优化可以很容易地进行,把危险的交易排除在一毫米以内。在我看来,最好是打开所有的交易,获得PF1.8。但最好是看到所有危险和安全的交易,事实上(经过优化)将信号缩小一些,获得PF2-3。在优化中,TS的生活一定是艰难的,而事实上是可以促进工作的。更重要的是,这里不再需要亏损的交易了......俗话说:"学习难,战斗易",应该是这样的......。
PipBar - 我正在用一个例子解释其重要性。同样,这两张通行证彼此相似,交易的数量也相同。只有在一个通道中,交易平均打开,等待半天,然后顺利关闭。在另一个地方,他们打开,在5-10分钟内发生了反弹,他们在加上关闭。获得同样的利润,但使用的时间却完全不同。虽然他们的测试期是一样的(比如说一年)。PipBar透明地显示了所使用的时间质量,即TS从余额中拿钱的时间最短,而回报最大!这就是PipBar。
我将在以后写下其余的内容......
MD - один из самых важных показателей. И наша задача выявить честность этого показателя. Что это значит? Объясняю на примере: предположим у нас два похожих друг на друга прохода, у обоих одинаковая просадка, и все остальное так же где-то рядом, изначально нет принципиальной разницы. На самом деле в одном из проходов просадка подогнана в притирку от опасных сделок (которые не открылись, и мы их не видим) - прошу пояснить, что такое опасная сделка, которая не открылась и котрую мы не видим, и как её на чистую воду выводит SrD? - а в другом наоборот просадка в основном маленькая, и только в одной случайной сделке она дошла до такого же уровня - уровня опасной сделки, так ведь?. В итоге мы получаем в корне разные два прохода. Если представить что просадка каждой сделки это штриховка, то SrD как раз и определяет плотность и радиус этой штриховки, и наглядно показывает что максимальная просадка к примеру 15% случайно совпала еле вытягиваясь из статистических 25-30% (которые не открылись в миллиметре от сигнала, и мы их не видим) или наоборот случайно проскользнувшая из 5-10% (максимально открытых всех позиций). - Я приводил примеры просадок 1-11-1-11-... против 6-6-6-6-... Я полагаю, что для них SrD одинаковое, но вот первый пример как раз именно тот, который дергает эти ваши опасные сделки, или не так?
PF - также один из самых важных показателей. И оптимизация его может получить запросто, также обходя опасные сделки в миллиметре. По мне так лучше открывать все сделки и получить PF 1.8. Но чтоб видеть все опасные и безопасные сделки, - у вас есть определение опасных и безопасных сделок и когда они открываются? Выше вы их связываете с просадкой. Сложно понять, что это. а уж на деле (после оптимизации), немного сузить сигнал и получить PF 2-3. В оптимизации жизнь для ТС должна быть жесткой, а на деле можно и облегчить труд. Тем более что убыточные сделки здесь уже не нужны... "Тяжело в учении - легко в бою" как говориться, вот так должно быть... - Интуитивно, я понимаю, чего вы желаете добиться. Сомневаюсь, что для оптимизации вы ставите параметр PF=1.8 и он вам делает прогон с PF=1.8, а для работы вы устанавливаете PF=2-3. Нет, конечно, оптимизационные и рабочие варианты отличаются другими параметрами. И вам кажется, что при оптимизационном режиме вы собираете "опасные и безопасные" сделки, убеждаетесь, что все тип-топ, а потом как бы выключаете "опасные" сделки и в уме держите - класс, я осведомлен об "опасных" сделках, я их контролирую, ведь, я их выключил в рабочем варианте, и если они даже возникнут, то они мне не угроза. Это иллюзия. Мне она напоминает анекдот про "Что делаю? Отгоняю крокодилов - Так их отродясь тут не было - Так это потому, что я их так хорошо отгоняю. А по-научному, любое высказывание о любом элементе пустого множества верно. Все что вы не придумаете о сделках, которых не было, которые не открылись в рабочем варианте и в любом другом, - все будет верно. Ваше "лучше открывать все сделки" показывает вам реальность при одном наборе оптимизируемых параметров. "Немного сузить сигнал" - другую реальность, в которой нет сделок из первой. Эти несуществующие сделки, которые не открылись при узком сигнале, существуют только в вашем воображении. И естественно, вы осведомлены о них, что они "существуют", что все под контролем - вы их отпугнули "сузив сигнал". Попробуйте понять, что в условиях "узкого сигнала" неоткрывшихся сделок нет, их свойств мы не знаем, но воображать о них мы можем что угодно. Интуитивно хочется приоткрыть дверь и вглянуть на эти неоткрывшиеся опасные сделки, но приоткрывая дверь - расширяя сигнал, мы меняем реальность. Я бы не тратил время на попытку взвешивания фантомов. Исходите из фактов. Для каждого прогона они свои.
PipBar - объясняю важность на примере. Опять же два похожих друг на друга прохода, да же кол-во сделок одинаково. Только в одном проходе сделки в среднем открываются, пол дня межуются, потом закрываются хорошо. В другом открываются, через 5-10минут происходит скачок, и закрываются также в плюсе. Получается одна и та же прибыль, но при кардинально разном использовании времени. Хотя период тестирования у них одинаковый (год к примеру). PipBar - прозрачно показывает качество использованного времени, т.е. ТС занимает деньги у баланса для совершения сделки на минимальный срок с максимальной отдачей! - Желание понятно, но методологический подход неверен. Расчитайте стоимость денег, которую вы одолжили у депозита на сделку(и) и сравните её с чем-то такой же природы, т.е. снова стоимостью чего вам покажется правильным. Или умножьте обратную величину стоимости на критерий - чем больше стоимость, тем хуже. Так ведь? А вы её к устойчивости прибавляете. То, что вы делаете, это попытка вымучать калибровкой коэффициентов критерий по вот такому типу: максимальная скорость/стоимость авто + количество подушек безопасности / расход топлива на 100 км + мощность /% по кредиту
Об остальном позже напишу...
在用恒定手数进行优化时,我们想回答的第一个问题是,我们应该从TS中期待什么样的缩减水平。假设提款水平为初始存款的30%。如何在实践中实现这一标准,以便我们在优化过程中消除不必要的变体?例如,像这样。
经过优化,我们得到一个变体样本,并将其转移到Excel中。按标准排序--恢复系数(利润/最大缩水)。
第二个问题是,在实际交易中使用哪种变体?假设最好的变体给出了10%的缩水。我们允许3倍的提款,也就是说,交易量可以增加3倍。但是......。所选变体的进一步参数会恶化。通常情况下,这种情况会发生。
然后,我们可以同时使用一组体积等于一手(0.01、0.1、1等)的变体,而不是一个变体。同时,我们对在同一时间开立的交易数量进行了限制。例如,我们设置了20个专家顾问进行交易,只能开3个单量的头寸。我们在开仓前设置了一个检查。
因此,我们通过20个专家顾问而不是一个专家顾问来重新分配获得初始存款的30%的潜在缩水的概率。
现在的问题是如何选择这20个专家顾问?简单地采取20个最佳选择并不是一个好的解决方案。毕竟许多变体在优化期间有相同的交易量,即它们同步运作。因此,我们按交易数量和恢复系数进行排序。在每组中,我们选择最好的变体。
对我来说,"自动选择优化结果的标准。" 是时间,也就是说,系统必须在所有时间间隔内保持稳定。
市场是动态的,所以我们不得不得出结论,优化输出是动态的,不能用于自动选择。
如果APS检测到市场的高波动性并进入日内模式,那么自动选择怎么办?
假设2008年下半年(01.08.2008-01.01.2009)的优化没有意义,ATS的一个MA将是盈利的。
趋势和非趋势时间段的采样是一个选项(我更喜欢固定的两周优化)。
如何实现稳定?
我的选择标准是 稳定性。尝试改变我的方法,我是这样做的:
半年时间,12个独立的优化,在M5上已经足够了。
通常情况下,剩下的参数变体不会超过50个,然而,这将给我们带来大约2-3个 "相同 "的设置包。
通过pf或cc选择优化结果与ATC算法的编写方法直接相关。
一个人需要时间来学习如何走路,一个拳击手首先需要一个以上的比赛来获得资格......
有一篇文章 将帮助对数据进行分类,并在任何时间间隔内运行选定的 参数变体。
>> 向大家问好!
该主题和其他关于优化结果使用的问题对任何交易者来说当然是极其重要的。
我的问题不仅是针对下面引用的作者,....
收到的分析报告可能只是手写的,正如这里有人说的。"最完美的神经网络是脑袋"。
但我认为,无论是心理上还是事实上的结果,都是值得的。
没有虚假的谦虚),我要指出,我在手工选择结果 优化方面取得了一些 。然而,没有办法使这个过程自动化。也许这只是可怜的形式化的经验。
现在只是一个测试版本,但我已经对结果很满意了......
你去那里,求我的超级简单但超级有效的标准;)
为什么主题陷入沉默。空中的问题,于是就挂了。在我尝试了很多 "哑巴"(一次通过)的有利可图的EA,然后在演示中失去了它们,如果不是在转发上,就是在实际交易中,我意识到,在我自己决定这个问题之前--我不会进一步....。无处可去 :)
..............
如果我看到什么是值得的,我就会分组--2个,三个人的力量,最后优化跨区......,选择最好的,然后演示....。没有保证,还没有统计数据 :)
...............................................
从帖子来看,大家对自己的标准和最终参数集(FSP)的选择结果或多或少都很满意。
.............................
所以问题就在这里。
假设我们有一个在3周历史上被优化的TS,然后我们根据优化结果选择一个TPF,然后有一周是真实的(或OOS),在这一周里,TPF没有变化,在周末我们固定结果。
我们重复52个周期(周),向前移动一个星期,即1年。
如果一周的交易(测试)结果是正数或等于零,我们认为是成功的。
问题:使用你选择最后一组参数的标准和方法,获得的成功数量是多少?
我问这个问题是因为我正在寻找根据优化结果选择TPF的方法。
我将在后面描述我在这个话题上的经验。
向大家问好!
好吧,在你们都躲起来的时候,我有时间讲述我的故事。
.............
我意识到,a)市场是不稳定的,b)不可能创建一个专家顾问,长期以恒定的参数盈利,c) ...其他重要的见解。
任务设定为:学习在专家顾问的优化结果中选择这样一个最终参数集(FPS),使用该参数集在统计学上可靠地给出了正的预期回报。
一切似乎都很清楚,但为了以防万一,我将通过上一篇文章的一个例子来解释。
因此,我们重复52个周期(周),提前一周,即1年。
如果每周交易(测试)的结果为正数或等于零,则视为成功。
也就是说,如果在52周中,有40周的结果是成功的,而12周不成功的平均损失是,例如,1126c.u,
而平均盈利周的结果是等于-1777c.u.,那么我们认为问题得到了完美的解决。
(我们理解,最好是有520周或5200周的样本结果。但我们有理由相信,在这种规模的样本中,我们的结果的比例不会改变)。
.........
承认这项任务是一项严肃的任务。这比找到圣杯要好,因为理论上任何MTS都可以按照给定的方法来使用。课题发起人也写到了这一点。
技术部分的解决情况如下。
- 我们将各种标准的计算附在专家顾问身上。MT报告中的标准数据,如最大利润、达到最大利润的时间占测试时间的百分比、扩展的Z-score、买入和卖出的平均交易时间、处于买入和卖出的时间占测试时间的百分比,等等,等等。简而言之,越多越好。没有多余的信息。(我指的是关于我的交易信息;-)))
- IsBackTestingTime.mqh Copyright © 2008, Nikolay Kositsin.在我的版本中,它被重新制作,但想法是相似的。我将使用之前的例子:让我们假设一个专家顾问有两个优化参数,每个参数有10个值,另一个参数有3个值。在设定了所需的优化期和测试期的持续时间以及这些时期的转变后,对于一个完整的(没有GA)优化,我们将得到31200=300*52+300*52次,即52次优化期的300次和测试期的300次(相对于之前的次数)。科西津的文章和图片在那里
我将离开一段时间,然后继续....。
在此期间,请出来躲避,不要再躲避了....。))
- 我们把专家顾问的所有外部参数和我们需要的标准写进一个csv文件中,在一个演练中(从deinit)。
- 优化完成后,我将其加载到Excel中,在一分钟内,我们就有了一个格式化的、可随时使用的xls文件,其中包含所有的通行证。
一个问题出现了:我应该如何处理所有这些 "东西"?
我决定根据本节和其他章节中已经描述过的模型,将选择FPP的过程自动化。比如说。
让我们采取1-st子组优化的方式,从1-st到300-th进行优化
1.小于50的交易 - 筛选出(220左)
2.利润因子小于2--过滤掉(剩下78个)。
3.利润低于30%或高于70%(我们取中间值)--过滤掉(还有33个)。
....总共可以处理6个标准,并通过绝对值、相对值(%)和位置号定义过滤器。有两种类型的过滤器--带状(内、外)和边界(多、少)。
7.我们直接选择FPN。例如,它将是具有负责平衡曲线直线度的标准的最大值的集合。
现在,让我们在这组测试的三百个通行证中找到相应的通行证(就像它是OoS一样),并通过一个通行证的可用数量来固定利润。
因此,对于每一个分组来说。
结果我们得到了带有平衡图和每周(在这种情况下)"交易 "指数的报告。一切都显得很有魅力。但是...
结果。
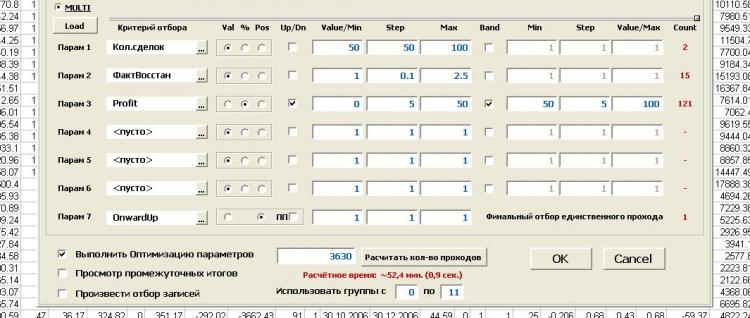
我在选择方法上没有发现一致的模式。一切似乎都很好,但有些事情是不对的。我不相信!!!。(正如伟大的人所说...)。
同时,我相信这种方法有潜力,而且是巨大的。
我处理这个问题的时间并不长,只测试了一个策略(我在努力回忆开发这个主题后的去处和原因....)。
问题。
1.你怎么看:不是每个TS都适合这样的处理吗?也就是说,在时间上更稳定,以及如何为这种稳定性引入一个标准,以立即确定--我们的TS/不是我们的TS。
2.这里有什么做错了吗?有人可以看到其他的方法吗?
3.我想听听你的结果。这个问题已经在我在这一页的第一篇帖子中问过了
提议。
集体选择一个现成的策略(已经由MTS调试过或来自可靠的作者,建议),再次集体尝试解决问题(或至少接近解决)。
使用由我描述的功能(但我不坚持,另一个类似的功能是可能的 - 建议)。
测试结果将在这里公布或不在这里公布,我们可以一起决定。
我们可以像你说的那样,开一个新的主题。
只有在取得了成果,并且 该主题没有褪色和演变的情况下,才可以。
一个补充。
1.该工具相当灵活。它允许你将任何选择优化结果的方法正规化。当然,我认为是这样。
2.根本没说有优化寻找最终参数集的方法的功能,也就是像优化优化参数。我们为每个标准选择范围和步骤,以及边界类型和过滤器操作模式,并运行优化。 看一次总比......好。
这就是它的全部内容。
PS。 "真是一团糟,想想看......。没有什么好笑的事... "(c) UmaTurman