Оценка статистических параметров последовательности очень важна, так как большинство математических моделей и методов строятся исходя из различного рода предположений, например, о нормальности закона распределения, или требуют знания значения дисперсии или других параметров. В статье кратко рассматриваются простейшие статистические параметры случайной последовательности и некоторые методы ее визуального анализа. Предлагается реализация этих методов на MQL5 и способ визуализации результатов расчета при помощи программы Gnuplot.
# load data
fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv'
, sep= ','
, header = T
, na.strings = 'NULL')
fx_dat <- subset(fx_data, Volume > 0)
# create open price returns
dat_return <- diff(x = fx_dat[, 2], lag = 1)
# check summary for the returns
summary(dat_return)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
# generate random normal numbers with parameters of original data
norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return))
#check summary for generated data
summary(norm_generated)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03
# test normality of original data
shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)])
Shapiro-Wilk normality test
data: dat_return[sample(length(dat_return), 4999, replace = F)]
W = 0.86826, p-value < 2.2e-16
# test normality of generated normal data
shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)])
Shapiro-Wilk normality test
data: norm_generated[sample(length(norm_generated), 4999, replace = F)]
W = 0.99967, p-value = 0.6189
####### quantiles
hour1_quantiles <- data.frame()
counter <- 1for (i in seq(from = 0.05, to = 0.95, by = 0.05)){
hour1_quantiles[counter, 1] <- i
hour1_quantiles[counter, 2] <- quantile(dat_return, probs = i)
counter <- counter + 1
}
colnames(hour1_quantiles) <- c(
'probability'
, 'value'
)
plot(hour1_quantiles$value, type = 's')
#View
hour1_quantiles
probability value10.05 -0.002537520.10 -0.001660030.15 -0.001210040.20 -0.000900050.25 -0.000680060.30 -0.000505070.35 -0.000360080.40 -0.000230090.45 -0.0001100100.500.0000000110.550.0001100120.600.0002400130.650.0003700140.700.0005100150.750.0006900160.800.0009100170.850.0012100180.900.0016600190.950.0025300
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')
## what is absolute statistics of hourly returns?
summary(abs(dat_return))
Min. 1 st Qu. Median Mean 3 rd Qu. Max.
0.0000000.0003000.0006900.0010970.0014200.068490
而我的灵魂一直想挖掘所谓的正态分布增量报价的话题。
如果有人赞成,我将提出论据,说明这个过程不可能是正常的。而这些论点将是每个人都能理解的,同时与CPT相一致。而这些争论是如此微不足道,不应该有任何疑问。
而概率将表达什么,是对下一个柱子的预测,还是对下一个柱子的运动矢量?
概率将表示对下一个刻度(增量)的预测。我只是想。
- 计算未来的Ybayes点的值,对于这些值,贝叶斯公式的概率将是最大的。
- 将Ybayes与实际进来的Yreal ticks进行比较。收集和处理统计数据。
如果数值的差异在合理范围内,那么我将公布代码并询问下一步该怎么做。退步?矢量?剥皮?
概率将表达对下一个tick(增量)的预测。我只是想。
为什么要降到虱子?你可以在5分钟内学会预测刻度方向,准确率为70%,但提前100个刻度,你知道准确率会下降。
试着提前半小时或一小时递增。这对我来说也很有趣,也许我可以在某些方面提供帮助。
概率将表达对下一个tick(增量)的预测。我只是想。
- 计算未来的Ybayes点的值,对于这些值,贝叶斯公式的概率将是最大的。
- 将Ybayes与实际的Yreal ticks进行比较。收集和处理统计数据。
如果数值的差异在合理的范围内,我会公布代码并询问下一步该怎么做。退步?矢量? 曲线?剥皮?
ARIMA有什么问题?在软件包中,差异的数量(增量的增量)是根据输入流自动计算的。很多与静止性有关的微妙之处隐藏在包装内。
如果你真的想那么深入,一些ARCH?
我试过一次。问题是这样的。增量可以很容易地计算出来。但如果我们把这个增量的置信区间 加到增量本身,它将是买入或卖出,因为之前的价格值落在置信区间内。
是的,正如SanSanych所写的,经典的方法是数据分析、数据要求和系统错误。
但这个主题是关于贝叶斯的,我正试图用贝叶斯的术语来思考,就像战壕里的士兵计算后验(经验后)的概率。我在上面举了一个士兵的例子。
其中一个主要问题是把什么作为先验概率。换句话说,我们应该把谁放在未来的幕布后面,放在零条的右边?高斯?拉普拉斯?维纳?专业数学家在这里写什么(对我来说是一片黑暗的 "森林")?
我选择高斯是因为我对正态分布有一个概念,我相信它。如果它不会 "开枪",那么就有可能采取其他规律,用高斯代替贝叶斯公式,或与高斯一起作为两个概率的乘积。如果我理解正确的话,试着做一个贝叶斯网络。
自然,我不能单独做这件事。我想用高斯来解决这个问题,这是我在花束下制定的。 如果有人愿意在自愿的基础上加入我,请这样做。这里有一个实际问题。
给出:МТ4的随机数发生器。
需要:将MQL4代码写成函数FP(),将标准RNG形成的MT4[]数组转换为正态分布的ND[]数组。
瓦西里(我不知道我的父名)-索科洛夫在https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/, 向我展示了转化公式。
利他主义和仁慈将是结果的图形表示,尽管我可以在MT4窗口中直接放大计算数组的图表。 我在我的项目中正在这样做。
我明白,这里的许多人可能通过点击几下数学包就能解决这个问题,但我想用MQL4的语言说话,这是交易者、程序员、经济学家和哲学家共同理解的。
是的,正如SanSanych所写的,经典的方法是数据分析、数据要求和系统错误。
但这个主题是关于贝叶斯的,我正试图用贝叶斯的术语来思考,就像战壕里的士兵计算后验(经验后)的概率。我在上面举了一个士兵的例子。
其中一个主要问题是把什么作为先验概率。换句话说,我们应该把谁放在未来的幕布后面,放在零条的右边?高斯?拉普拉斯?维纳?专业数学家在这里写什么(对我来说是一片黑暗的 "森林")?
我选择高斯是因为我对正态分布有一个概念,我相信它。如果它不会 "开枪",那么就有可能采取其他规律,用高斯代替贝叶斯公式,或与高斯一起作为两个概率的乘积。如果我理解正确的话,试着做一个贝叶斯网络。
自然,我不能单独做这件事。我想用高斯来解决这个问题,这是我在花束下制定的。 如果有人愿意在自愿的基础上加入我,请这样做。这里有一个实际问题。
给出:МТ4的随机数发生器。
需要:将MQL4代码写成函数FP(),将标准RNG形成的MT4[]数组转换为正态分布的ND[]数组。
瓦西里(我不知道我的父名)-索科洛夫在https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/, 向我展示了转化公式。
然而,我可以,而且我可以直接在MT4窗口中重新调整计算数组的图表。 我在我的项目中也是这样做的。
我明白,许多交易者可能会使用数学软件包在几次点击中解决这个问题,但我想使用MQL4语言,这对交易者、程序员、经济学家和哲学家来说是普遍可以使用的。
这里是一个具有不同分布的发生器,包括正态分布。
https://www.mql5.com/ru/articles/273
在R中进行简要的分布分析。
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189我们从现有的时钟柱开盘价增量中估计出正态分布的参数,并绘制出比较原始系列和具有相同分布的正态系列的频率和密度。你甚至可以用眼睛看到,原来一系列的小时条的增量远远不是正常的。
顺便说一句,我们不是在上帝的殿堂里。相信是没有必要的,甚至是有害的。
下面是上面的帖子中的一句奇怪的话,它与我上面写的内容一致
-2.515e-02-6.800e-04 0.000e+00 -3.400e-076.900e-04 6.849e-02
据我所知,在象限中,50%的时钟上的所有增量都小于7点!而更像样的增量是在粗大的尾巴上,即在善与恶的另一边。
那么,TS会是什么样子呢?这就是问题所在,而不是贝叶斯和其他,其他,其他....。
还是应该以其他方式来理解?
下面是上面的帖子中的一句奇怪的话,它与我上面写的内容一致
-2.515e-02-6.800e-04 0.000e+00 -3.400e-076.900e-04 6.849e-02
据我所知,在象限中,每小时有50%的增量低于7个点!这就是为什么我们要把这些增量作为我们的目标。而更像样的增量是在粗大的尾巴上,即在善与恶的另一边。
那么,TS会是什么样子呢?这就是问题所在,而不是贝叶斯和其他,其他,其他....。
还是应该以其他方式来理解?
SanSanych,是的!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')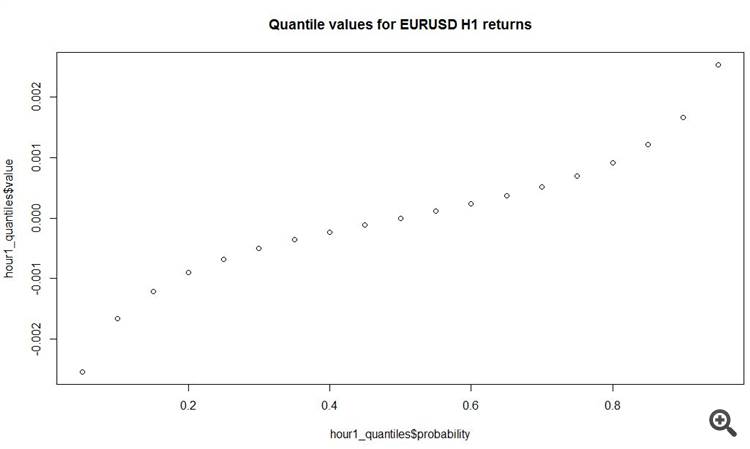
而另一个有趣的事情是,每小时的平均绝对增量是11个点!共计。
你必须做很长时间,因为你需要重新改造和...而Box-Cox并不真正喜欢它))))只是遗憾的是,如果你没有
只是遗憾的是,如果你没有任何正常的预测因素,对最终结果不会有太大影响......