
Doğrusal Regresyon Örneğiyle 3 Gösterge Hızlandırma Yöntemi
Hesaplama Hızı
Göstergelerin hızlı hesaplanması hayati derecede önemli bir iştir. Hesaplamalar farklı yöntemlerle hızlandırılabilir. Bu konuyla ilgili birçok makale vardır.
Ve şimdi hesaplamaları hızlandırmak ve hatta bazen bir kodun kendisini basitleştirmek için 3 yöntem daha inceleyeceğiz. Açıklanan tüm yöntemler algoritmik yöntemlerdir, yani geçmiş derinliğini azaltmayacağız veya işlemci biriminin ek çekirdeklerini etkinleştirmeyeceğiz. Hesaplama algoritmalarını doğrudan optimize edeceğiz.
Temel Gösterge
3 yöntemin de görüntülenmesi için kullanılacak gösterge, doğrusal regresyon göstergesidir. Her çubukta (son çubukların tanımlı sayısına göre) regresyon işlevi oluşturur ve bu çubukta hangi değere sahip olması gerektiğini gösterir. Sonuç olarak, sağlam bir çizgimiz var:
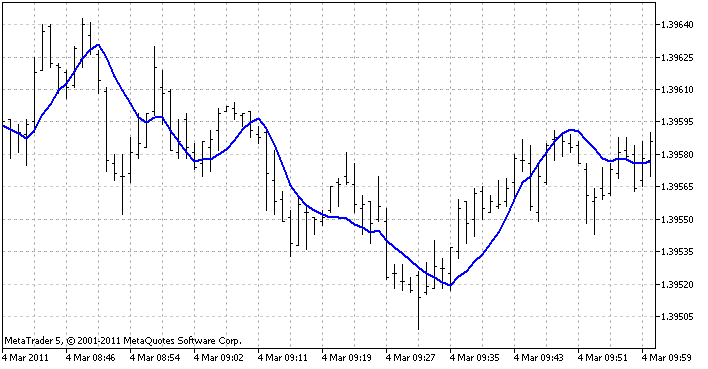
Gösterge terminalde böyle görünüyor
Doğrusal regresyon denklemi aşağıdaki gibi görünür:
![]()
Bizim durumumuzda x barlar bir dizi ve y fiyatları vardır.
Bahsedilen denklemin oranları aşağıdaki gibi hesaplanır:
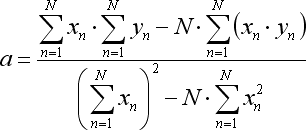
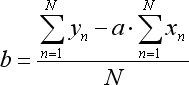
burada N, regresyon çizgisini oluşturmak için kullanılan çubukların bir numarasıdır.
Bu denklemler MQL5'te (tüm tarih çubukları döngüsünün içinde) böyle görünür:
// Finding intermediate values-sums Sx = 0; Sy = 0; Sxx = 0; Sxy = 0; for (int x = 1; x <= LRPeriod; x++) { double y = price[bar-LRPeriod+x]; Sx += x; Sy += y; Sxx += x*x; Sxy += x*y; } // Regression ratios double a = (LRPeriod * Sxy - Sx * Sy) / (LRPeriod * Sxx - Sx * Sx); double b = (Sy - a * Sx) / LRPeriod; lrvalue = a*LRPeriod + b;
Göstergenin tam kodu makaleye eklenir. Ayrıca, mevcut makalede açıklanan tüm yöntemleri içerir. Bu nedenle, gösterge ayarlarında "Standart" hesaplama yöntemi seçilmelidir:

Grafikte ayarlandığında gösterge giriş parametreleri ayar penceresi
İlk İyileştirme Yöntemi. Toplamları Taşıma
Her birinde bazı çubuklar dizisi değerlerinin toplam rakamının hesap olduğu çok sayıda gösterge vardır. Ve bu dizi her barda sürekli değişir. En iyi bilinen örnek HareketliOrtalamadır (MA). N son çubuklarının toplamını hesaplar ve sonra bu değer sayılarına bölünür.
Bence, oldukça az sayıda insan, bu tür hareketli toplamların hesaplanmasını önemli ölçüde hızlandırmanın zarif bir yolu olduğunu biliyor. Bu yöntemi göstergelerimde zaten oldukça uzun zamandır kullanıyorum, t'nin MetaTrader 4 ve 5 normal MA göstergelerinde de kullanıldığını öğrendiğimde. (MetaTrader göstergelerinin geliştiriciler tarafından düzgün bir şekilde optimize edileceğini bulduğumda zaten ilk durum değil. Uzun zaman önce hızlı ZigZag göstergeleri arıyordum ve düzenli bir gösterge dış göstergelerin çoğundan daha etkili olduğunu kanıtladı. Bu arada, bahsedilen forum konusu, birinin ihtiyaç duyması durumunda ZigZag optimizasyon yöntemlerini de içerir).
Ve şimdi toplamları taşımaya geri döneceğiz. İki bitişik çubuk için hesaplanan toplamları karşılaştıralım. Aşağıdaki şekil, bu toplamların önemli ölçüde ortak bir parçaya sahip olduğunu göstermektedir (yeşil renkle gösterilmiştir). 0 çubuğu için hesaplanan toplam, yalnızca toplamın bir eski çubuk (soldaki kırmızı) içermemesi, ancak bir yeni çubuk (sağda mavi olan) içermesi nedeniyle çubuk 1'in toplamından farklıdır:

Bir çubuk kaydırma sırasında toplam değerleri hariç tuttu ve dahil etti
Bu nedenle, çubuk 0 için bir toplam hesaplarken gerekli tüm çubukları yeniden özetlemeye gerek yoktur. Çubuk 1'den sadece bir miktar alabilir, bir değer düşebilir ve ona yeni bir değer ekleyebiliriz. Yalnızca iki aritmetik işlem gereklidir. Böyle bir yöntem kullanarak gösterge hesaplamayı önemli ölçüde hızlandırabiliriz.
Hareketli Ortalama'da bu tür bir yöntem, gösterge tüm ortalama değerleri tek arabelleği içinde tuttuğundan rutin olarak kullanılır. Ve bu, toplamların N'ye bölünmesinden, yani toplamdaki çubuk sayısından başka bir şey değildir. Ara bellekten gelen bir değeri N ile çarparak, herhangi bir çubuk için kolayca bir toplam alabilir ve yukarıda açıklanan yöntemi uygulayabiliriz.
Şimdi size bu yöntemin daha karmaşık göstergede nasıl uygulanacağını göstereceğim - doğrusal regresyon. Regresyon fonksiyon oranlarının hesaplanması için denklemlerin dört toplam içerdiğini zaten gördünüz: x, y, x*x, x*y. Bu toplamların hesaplanması arabelleğe alınmalıdır. Bunu başarmak için göstergedeki her toplam için arabellekler atanmalıdır:
double ExtBufSx[], ExtBufSy[], ExtBufSxx[], ExtBufSxy[]; Arabellek mutlaka bir grafikte görülmeyebilir. MetaTrader 5, ara hesaplamalar için özel bir arabellek türünesahiptir. OnInit'te arabellek numaraları atamak için kullanacağız:
SetIndexBuffer(1, ExtBufSx, INDICATOR_CALCULATIONS); SetIndexBuffer(2, ExtBufSy, INDICATOR_CALCULATIONS); SetIndexBuffer(3, ExtBufSxx, INDICATOR_CALCULATIONS); SetIndexBuffer(4, ExtBufSxy, INDICATOR_CALCULATIONS);
Standart doğrusal regresyon hesaplama kodu şimdi aşağıdakiler için değişecektir:
// (The very first bar was calculated using the standard method) // Previous bar int prevbar = bar-1; //--- Calculating new values of intermediate totals // from the previous bar values Sx = ExtBufSx [prevbar]; // An old price comes out, a new one comes in Sy = ExtBufSy [prevbar] - price[bar-LRPeriod] + price[bar]; Sxx = ExtBufSxx[prevbar]; // All the old prices come out once, a new one comes in with an appropriate weight Sxy = ExtBufSxy[prevbar] - ExtBufSy[prevbar] + price[bar]*LRPeriod; //--- // Regression ratios (calculated the same way as in the standard method) double a = (LRPeriod * Sxy - Sx * Sy) / (LRPeriod * Sxx - Sx * Sx); double b = (Sy - a * Sx) / LRPeriod; lrvalue = a*LRPeriod + b;
Göstergenin tam kodu makaleye eklenir. Gösterge ayarlarında "Hareketli Toplamlar" hesaplama yöntemi ayarlanmalıdır.
İkinci Yöntem. Basitleştirme
Bu yöntem Matematik hayranları tarafından takdir edilecektir. Karmaşık denklemlerde, bilinen diğer bazı denklemlerin doğru parçaları gibi görünen parçalar genellikle bulunabilir. Bu, bu parçaları sol parçalarıyla (genellikle yalnızca bir değişkenden oluşan) değiştirmek için olasılık verir. Başka bir deyişle, karmaşık bir denklemi basitleştirebiliriz. Ve bu basitleştirilmiş denklemin bazı unsurları zaten gösterge olarak gerçekleşiyor gibi görünebilir. Bu durumda, bu denklemi içeren göstergenin kodu, sırayla önemli ölçüde basitleştirilmiş olabilir.
Sonuç olarak, en azından daha fazla alan etkili ve basit koda sahibiz. Ve bazı durumlarda, kodda uygulanan göstergelerin iyi hız için optimize edilmesi durumunda daha hızlı da olabilir.
Doğrusal regresyon denkleminin de basitleştirilebileceği ve hesaplamasının birkaç MetaTrader 5 standart göstergesinin başlatılmasıyla değiştirilebileceği görülmektedir. Öğelerinin çoğu, farklı hesaplama modlarında Hareketli Ortalama göstergesinde hesaplanır:
- toplam y Basit Hareketli Ortalama'da bulunur:
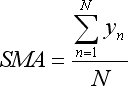
- x*y toplamı Doğrusal Ağırlıklı Hareketli Ortalama'da bulunur:
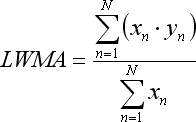
LWMA denkleminin yalnızca 1'den N'ye gerilemede yer alan çubukları geçmişten geleceğe artan bir şekilde numaralandırmamız durumunda doğru olduğunu unutmayın:

LWMA göstergesini kullanmak için regresyon çubuklarını geleneksel olarak numaralandırmanın yolu
Bu nedenle, aynı numaralandırma diğer tüm denklemlerde kullanılmalıdır.
Yönteme devam edelim:
- x toplam, aşağıdaki denklemle değiştirilebilen (1 + 2 + ... + N) sayı serisi toplamından başka bir şey değildir:
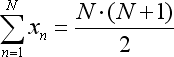
- x*x toplam başka bir denkleme göre basitleştirilmiştir:
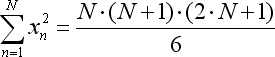
- bir gösterge grafiği oluşturmak için regresyon işlevinin anlamını yalnızca x'in N.I.'a eşit olduğu son çubuğu için hesaplamamız gerekir, regresyon işlevi denklemi özel durumuyla değiştirilebilir:
![]()
Bu nedenle, son beş denklem, a ve b oran hesaplama denklemlerindeki ve regresyon denkleminin kendisinde tüm değişkenler için değiştirmeler almamızı sağlar. Tüm bu değiştirmeleri tamamladıktan sonra, regresyon değerinin hesaplanması için yepyeni bir denklem elde edeceğiz. Sadece Hareketli Ortalama gösterge değerleri ve N rakamından oluşacaktır. Elemanlarının tüm azalmalarından sonra zarif bir denklem elde edeceğiz:
![]()
Bu denklem, doğrusal regresyon temel göstergesinde yürütülen tüm hesaplamaların yerini alır. Bu denkleme sahip gösterge kodunun çok daha fazla uzay etkili olacağı oldukça açıktır. "Hız Karşılaştırması" bölümünde, kodun daha hızlı çalışıp çalışmadığını da öğreneceğiz.
Göstergenin belirtilen bölümü:
double SMA [1]; double LWMA[1]; CopyBuffer(h_SMA, 0, rates_total-bar, 1, SMA); CopyBuffer(h_LWMA, 0, rates_total-bar, 1, LWMA); lrvalue = 3*LWMA[0] - 2*SMA[0];
LWMA ve SMA göstergeleri OnInit'te önceden oluşturulur:
h_SMA = iMA(NULL, 0, LRPeriod, 0, MODE_SMA, PRICE_CLOSE); h_LWMA = iMA(NULL, 0, LRPeriod, 0, MODE_LWMA, PRICE_CLOSE);
Tüm kaynak kodları, makaleye eklenmiştir. Gösterge ayarlarında "Basitleştirme" hesaplama yöntemi ayarlanmalıdır.
Bu yöntemde terminalde yerleşik göstergeleri kullandığımızı unutmayın, yani iCustomyerine uygun yumuşatma yöntemlerinin seçimi ile iMA işlevi kullanılmıştır. Bu önemli bir şeydir, çünkü teoride yerleşik göstergeler çok hızlı çalışmalıdır. Diğer bazı standart göstergeler terminalde yerleşiktir (bunlar iMA gibi "i" önekine sahip işlevler tarafından oluşturulur). Basitleştirme yöntemini kullanırken, bu göstergelere denklemleri basitleştirmek çok daha iyidir.
Üçüncü Yöntem. Yaklaşık
Bu yöntemin fikri, bir uzmanda kullanılan "ağır" göstergelerin, ihtiyaç duyulan değerleri yaklaşık olarak hesaplayan çok daha hızlı göstergelerle değiştirilebilmesidir. Bu yöntemi kullanarak stratejinizi daha hızlı test edebilirsiniz. Sonuçta, tahmin doğruluğu hata ayıklama aşamasında çok önemli değildir.
Ayrıca, bu yöntem parametreleri kabaca optimize etmek için bir çalışma stratejisi ile kullanılabilir. Bu, parametrelerin etkili değer alanlarını hızlı bir şekilde bulmanızı sağlar. Ve daha sonra ince ayarlama için "ağır" göstergeler tarafından işlenebilirler.
Ayrıca, bir stratejinin düzgün çalışmasına izin vermek için yaklaşık hesaplamanın yeterli olacağı görülebilir. Bu durumda, gerçek ticarette "hafifletilmiş" bir gösterge de kullanılabilir.
Regresyona benzer etkiye sahip doğrusal regresyon için hızlı bir denklem geliştirilebilir. Örneğin, regresyon çubuklarını iki gruba ayırabilir, her biri için ortalama değeri hesaplayabilir, bu iki ortalama nokta boyunca bir çizgi çizebilir ve satırın değerini son çubukta tanımlayabiliriz:

Noktalar iki gruba ayrıldı - sol ve sağ olanlar - ve hesaplamalar yapıldı
Böyle bir hesaplama, regresyon durumundan daha az aritmetik işlem içerir. Hesaplamaları hızlandırmanın yolu bu.
// The interval midpoint int HalfPeriod = (int) MathRound(LRPeriod/2); // Average price of the first half double s1 = 0; for (int i = 0; i < HalfPeriod; i++) s1 += price[bar-i]; s1 /= HalfPeriod; // Average price of the second half double s2 = 0; for (int i = HalfPeriod; i < LRPeriod; i++) s2 += price[bar-i]; s2 /= (LRPeriod-HalfPeriod); // Price excess by one bar double k = (s1-s2)/(LRPeriod/2); // Extrapolated price at the last bar lrvalue = s1 + k * (HalfPeriod-1)/2;
Göstergenin tam kodu makaleye eklenir. Gösterge ayarlarında "Yaklaşık" hesaplama yöntemi ayarlanmalıdır.
Şimdi, bunun orijinaline ne kadar yakın olduğunu analiz edelim. Bunu başarmak için göstergeleri bir grafikte standart ve yaklaşık hesaplama yöntemleriyle ayarlamalıyız. Ayrıca, gerilemeye bilerek zayıf bir şekilde benzeyen başka bir gösterge de eklemeliyiz. Bununla birlikte, geçmiş çubukları kullanarak bazı eğilimleri de hesaplamalıdır. Hareketli Ortalama bunun için sadece iyi olacaktır (SMA değil LWMA kullandım - regresyon grafiğine çok daha benzer). Yanında iyi bir yaklaşıma sahip olup olmadığımızı değerlendirebiliriz. Bence bu iyi bir şey.

Kırmızı çizgi mavi olana yeşil çizgiden daha yakın. Yaklaşık algoritmanın iyi olduğu anlamına gelir.
Hız Karşılaştırması
Günlük ekranı gösterge parametrelerinde açılabilir:

Yürütme hızının değerlendirilmesi için göstergeyi ayarlama
Bu durumda gösterge, uzman ileti günlüğünde hız değerlendirmesi için gerekli tüm verileri görüntüler: OnCalculate() öğesinin başlangıç ve bitişi olan OnInit() olay işleme zamanı. Hızın neden bu iki değerle değerlendirilmesi gerektiğini açıklayacağım. OnInit() aracısı herhangi bir yöntem olması durumunda neredeyse anında yürütülür ve OnCalculate() hemen herhangi bir yöntem durumunda OnInit() hemen sonra başlar. Tek özel durum, OnInit() içinde SMA ve LWMA göstergelerinin oluşturulduğu basitleştirme yöntemidir. OnInit() bitirme ve OnCalculate() arasında, belirtilen yöntemin durumunda (ve yalnızca bu durumda!) başlayan bir gecikme vardır:

Terminalin uzmanlar günlüğünde gösterge tarafından görüntülenen yürütme günlüğü
Bu gecikmenin, o sırada bazı hesaplamalar yapan yeni oluşturulan SMA ve LWMA'dan kaynaklandığı anlamına gelir. Bu hesaplamaların süresi de göz önünde bulundurulmalıdır, bu nedenle, gerileme göstergesinin başlatılmasından hesaplamalarının sonuna kadar her zamanı "kesintisiz" olarak değerlendireceğiz.
Farklı yöntemlerin hızları arasındaki farkı daha doğru bir şekilde not etmek için tüm değerlendirmeler, maksimum erişilebilir geçmiş derinliğine sahip büyük bir veri dizisi - M1 zaman dilimi kullanılarak gerçekleştirilir. Bu 4 milyondan fazla bar. Her yöntem iki kez değerlendirilecektir: 20 ve 2000 çubuk gerilemede.
Sonuçlar aşağıdaki gibidir:


Gördüğünüz gibi, her üç optimizasyon yöntemi de standart regresyon hesaplama yöntemine kıyasla en az iki kez hız artışı gösterdi. Gerilemedeki çubuk sayısının artmasından sonra, hareketli toplamlar ve basitleştirme yöntemleri fantastik hız gösterdi. Standart olandan yüzlerce kat daha hızlı çalıştılar!
Bu iki yöntemle hesaplama için gereken sürenin pratik olarak değişmediğini not etmeliyim. Bu gerçek kolayca açıklanabilir: Bir regresyon oluşturmak için kaç çubuk kullanılmış olursa olsun, hareketli toplamlar yönteminde sadece 2 eylem yürütülür, eski bir çubuk söner ve yenisi gelir. Regresyon uzunluğuna bağlı herhangi bir döngü yoktur. Bu nedenle, regresyon 20000 veya 200000 çubuk içerse bile, yöntemin yürütme süresi 20 çubukla karşılaştırıldığında önemsiz bir şekilde artacaktır.
Basitleştirme yöntemi, denkleminde farklı modlarda Hareketli Ortalama kullanır. Daha önce de belirttiğim gibi, bu gösterge hareketli toplamlar yöntemi ile kolayca optimize edilebilir ve terminal geliştiricileri tarafından kullanılır. Regresyon uzunluğunun artması durumunda basitleştirme yönteminin yürütme süresinin de değişmemesine şaşmamalı.
Hareketli toplamlar yöntemi, deneyimizdeki en hızlı hesaplama yöntemi olduğunu kanıtladı.
Sonuç
Bazı tüccarlar sadece hareketsiz oturuyorlar ve testçilerinde ticaret sistemlerinin parametrelerinin optimizasyonu başka bir prosedürün sonunu bekliyorlar. Ancak, o anda zaten ticaret yapan ve para kazanan bazı satıcılar da vardır. Açıklanan yöntemlerle elde edilen hesaplama hızları, bu tüccar grupları arasında neden böyle bir fark olduğunu açıkça açıklar. Ve ticaret algoritmalarının kalitesine dikkat etmenin neden bu kadar önemli olduğunu.
Terminal programlarını kendiniz için yazmanız veya üçüncü taraf programcılara sipariş etmeniz önemli değildir (örneğin, "İşler" bölümünün yardımıyla). Her durumda, sadece çalışma göstergeleri ve stratejileri değil, aynı zamanda hızlı çalışan göstergeler de alabilirsiniz, bazı çabalar sarf etmeye veya biraz para harcamaya hazırsanız.
Herhangi bir algoritma hızlandırma yöntemi kullanırsanız, standart algoritmalara kıyasla onlarca ila yüzlerce kez hız avantajı elde edersiniz. Bu, örneğin, ticaret stratejilerinizin parametrelerini bir test cihazında yüz kat daha hızlı optimize edebileceğiniz anlamına gelir. Ve daha dikkatli ve sık yapın. Söylemeye gerek yok, bu işlem gelirlerinizin artmasına neden olur.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/270
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.
 MQL5'te İstatistiksel Olasılık Dağılımları
MQL5'te İstatistiksel Olasılık Dağılımları
 Fiyat Korelasyonunun İstatistiksel Verilerine Dayalı Sinyalleri Filtreleme
Fiyat Korelasyonunun İstatistiksel Verilerine Dayalı Sinyalleri Filtreleme
 Kaynak Kodun İzlenmesi, Hata Ayıklanması ve Yapısal Analizi
Kaynak Kodun İzlenmesi, Hata Ayıklanması ve Yapısal Analizi
 Satıcı Çalışmasında İstatistiksel Dağılımların Rolü
Satıcı Çalışmasında İstatistiksel Dağılımların Rolü
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
İşte kanıtı. Yani, Urain 'in linki vermesinden biraz daha önce.
Öncelik iddiasında değilim :). Genel olarak konuşursak, neredeyse önemsiz bir gerçek.
Not: Eğer her şeyi unutmadıysam, hızların karşılaştırılmasının sonucu hala klasik hesaplama lehineydi - ama önemli ölçüde optimize edilmişti (fark büyük değil, ama yine de; Candid' a'nın gönderilerine bakın). Bununla birlikte, daha yüksek dereceli regresyonlara (ikinci dereceden, kübik vb.) uygulanan benzer bir teknik, "konvolüsyon" yönteminin klasik olana göre avantajını gösterebilecek gibi görünüyor.
Çok iyi ve faydalı bir makale ama bir sorum var.
Hareketli Toplamlar yöntemini kullanırsak, göstergenin çok fazla hız kazandığı doğrudur, ancak bu, bellek tüketimini artıracak 4 yardımcı tampon eklemek anlamına gelir.
Yani soru şu ki, hangi yöntem daha az bellek kullanan Standart yöntem mi yoksa daha fazla bellek kullanan ancak daha hızlı olan Hareketli Toplamlar yöntemi mi daha iyidir?
Uygulamada bir sorun var:
LRMethod == LR_M_Sum olduğunda
Sx ve Sxx'in sabit olduğu ortaya çıkar:
Sxx = ExtBufSxx[prevbar];
ExtBufSxx [bar] = Sxx;
Eğer durum buysa, neden tamponlar?
Belki de hareketli toplam yöntemini kullanarak SMA ve LWMA'yı sayarsanız ve sonucu bir konvolüsyon olarak sayarsanız daha da hızlı olacaktır.
Ayrıca, SMA ve LWMA aracılığıyla da hesaplanabilen regresyonun eğimini bilmek iyi olurdu.
Bunu 4 üzerinde uyguladım: https://www.mql5.com/tr/code/10642
Merhaba,
,,Her barda (son barların tanımlanan sayısına göre) regresyon fonksiyonu oluşturur ve o barda hangi değere sahip olması gerektiğini gösterir''
Ancak en son regresyon çizgisinin eğimini nasıl hesaplayabilirim (sadece eğriyi oluşturan son noktayı biliyorum)...
Yardımınız için teşekkürler
Petr
Merhaba
Bu makale için teşekkürler. Ancak lütfen bana yöntemlerinizi MQL5 kodumun içinde nasıl çağıracağımı söyleyebilir misiniz? Nasıl yapılacağını anlamıyorum, yöntemlerinizin içindeki parametrelerin listesini anlamıyorum. sizinkini entegre ettikten sonra kodumun içinde belirli bir anda doğrusal regresyon tarafından döndürülen değeri nasıl alabilirim?