Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 3336
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Скорость тестирования экспортированной в наивный код модели (катбуст)
И экспортированной в ONNX
внутрянка почти аналогичная у двух версий бота, результаты тоже
Хотите, чтобы я вам перекопал код катбуста и дал точный ответ? Я копаю только то, что мне интересно. Катбустом не пользуюсь.
Допустил, что Вы знаете, а так - нет - я не думал Вас обременять.
Про коэффициенты листьям впервые слышу - что это?
Значения в листьях, которые суммируются, образуя координату Y функции.
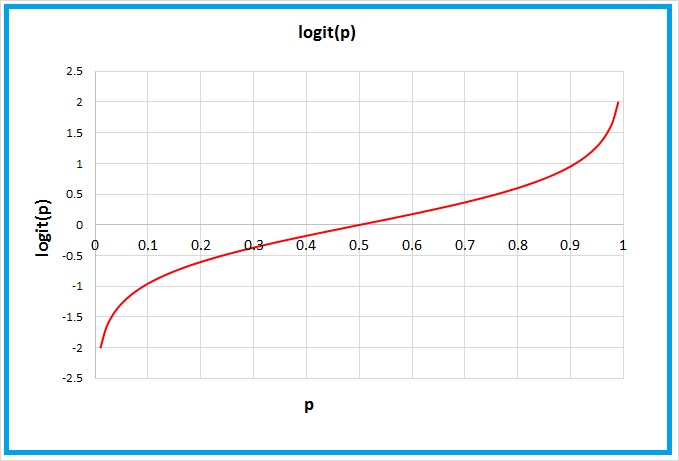
Больше или равно 0,5 по X означает, что класс "1" по умолчанию в CatBoost.А вы не задумывались почему так происходит?
По факту ошибочная закономерность в листе. Почему она такая - может быть ряд причин.
Или у Вас есть конкретный однозначный ответ?
Скорость тестирования экспортированной в наивный код модели (катбуст)
И экспортированной в ONNX
внутрянка почти аналогичная у двух версий бота, результаты тоже
Плата за универсальность.
Жаль, что у CatBoost существенные ограничения по конвертации модели.
Плата за универсальность.
Жаль, что у CatBoost существенные ограничения по конвертации модели.
Начал втыкать еще в object importance, там предложена целая статья. Посмотрю что это может дать.
Рад, что всё же смог заинтересовать. Пишите о достижениях в исследовании полезности данного подхода.
Думаю, что попробую воссоздать оценку листьев с учётом поэтапной коррекции ошибки, сделав переразметку после каждого листа (дерева).
Но, всё же, кажется, что при классификации это работает не так... плохо понимаю формулы.
Как я понял, что на первой итерации строится приближенная функция аппроксимации логлосс по меткам целевой, к которой с помощью деревьев надо приблизится, и дельта между идеальной функцией и получившейся с помощью деревьев как раз и записывается в лист после умножения на коэффициент скорости обучения.
Просто если размечать на ошибку, буквально воспринимая подход, то что-же, надо ошибку в двух разных классах помечать одним, допустим "1"?
Или, как?
Рад, что всё же смог заинтересовать. Пишите о достижениях в исследовании полезности данного подхода.
Я давно в этой теме. Есть другие способы/пакеты. Эту фичу как-то пропустил, может недавно добавили
Можно видео посмотреть на эту тему
Значения в листьях, которые суммируются, образуя координату Y функции.
Для меня это ответ или прогноз листа. Подумал что вы его еще корректировать каким-то коэффициентом хотите.
Просто если размечать на ошибку, буквально воспринимая подход, то что-же, надо ошибку в двух разных классах помечать одним, допустим "1"?
Или, как?
В учебном примере из статьи - только регрессия. За классификацию точно не скажу.