Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 1258
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Возможно, я до либ еще не дошел. Деревья это только частный случай огромной темы Байесовской, например здесь куча примеров книги и видео
Бейесовскую оптимизацию гиперпараметров НС по статьям Владимира использовал. Работает хорошо.Например, что деревья.. есть байесовские нейросети
Неожиданно!
НС работают с мат операциями + и * и могут внутри себя любой индикатор смастерить от МА до цифровых фильтров.
А деревья через разделение на правую и левую часть , простым if(x<v){левая ветка}else{правая ветка}.
или байсовские НС это тоже if(x<v){левая ветка}else{правая ветка}?
Но если много переменных оптимизировать, то оооочень долго.
Неожиданно!
НС работают с мат операциями + и * и могут внутри себя любой индикатор смастерить от МА до цифровых фильтров.
А деревья через разделение на правую и левую часть , простым if(x<v){левая ветка}else{правая ветка}.
или байсовские НС это тоже if(x<v){левая ветка}else{правая ветка}?
это да, медленно, поэтому выдираю оттуда полезные знания пока что, дает понимание некоторых вещей
не, в байесовских НС просто веса оптимизируются сэмплированием весов из распределений, и на выходе тоже получается распределение, содержащее кучу вариантов, но имеющее среднее, дисперсию и т.п. Другими словами, она как бы захватывает много вариантов, которых по факту нет в обучающем датасете, но они, априори, предполагаются. Чем больше сэмплов подается в такую НС тем она ближе сходится к обычной, т.е. байесовские подходы изначально для не оч. больших датасетов. Это пока то что знаю.
Т.е. таким НС сильно большие датасеты не нужны, результаты сойдутся с обычными. Зато на выходе после обучения будет не точечная оценка, а вероятностное распределение, для каждого сэмпла
это да, медленно, поэтому выдираю оттуда полезные знания пока что, дает понимание некоторых вещей
не, в байесовских НС просто веса оптимизируются сэмплированием весов из распределений, и на выходе тоже получается распределение, содержащее кучу вариантов, но имеющее среднее, дисперсию и т.п. Другими словами, она как бы захватывает много вариантов, которых по факту нет в обучающем датасете, но они, априори, предполагаются. Чем больше сэмплов подается в такую НС тем она ближе сходится к обычной, т.е. байесовские подходы изначально для не оч. больших датасетов. Это пока то что знаю.
Т.е. таким НС сильно большие датасеты не нужны, результаты сойдутся с обычными. Зато на выходе после обучения будет не точечная оценка, а вероятностное распределение, для каждого сэмпла
Мечетесь вы как под спидами, то одно, то другое, то третье... а толку ноль.
По ходу времени у вас свободного выше крыши, как у барина какого то, работать нужно, вкалывать, добиваться карьерного роста, а не от нейросетей к баесам метаться.
Уж поверьте в нормальных канторах никто бабки под наукообразное словоблудие и статьи не даст, только эквити подтвержденных мировыми праймброкерами.не мечусь, а последовательно изучаю от простого к сложному
на барина сами работайте, если работы нет могу предложить, например переписать кое-что на mql
Я на барина и работаю как и все, странно что вы не работаете, видать сами барин, наследник, золотой мальчик, нормальный мужик если теряет работу через 3 месяца на улице, через пол года труп.
если по теме МО в трейдинге вообще ничего нет - то гуляйте тогда, а то бедолаги одни нищие собрались, можно подумать )
да я показывал всё по МО, честно без детских тайн, как всякие оторванные здесь шифруются, ошибка на тесте 10-15%, но рынок постоянно меняется, торговля не идёт, болтанка возле нуля
короче гуляй, Вася, мне нытье не интересно
вы только и делаете что ноете, результатов нет, роете вилами воду и всё, но признаться что в пустую теряете время нет смелости
вас бы в армию отправить или хотя бы на стройку поработать с мужиками физически, выправили бы характерэто да, медленно, поэтому выдираю оттуда полезные знания пока что, дает понимание некоторых вещей
не, в байесовских НС просто веса оптимизируются сэмплированием весов из распределений, и на выходе тоже получается распределение, содержащее кучу вариантов, но имеющее среднее, дисперсию и т.п. Другими словами, она как бы захватывает много вариантов, которых по факту нет в обучающем датасете, но они, априори, предполагаются. Чем больше сэмплов подается в такую НС тем она ближе сходится к обычной, т.е. байесовские подходы изначально для не оч. больших датасетов. Это пока то что знаю.
Т.е. таким НС сильно большие датасеты не нужны, результаты сойдутся с обычными
Вот из комментариев https://www.mql5.com/ru/forum/226219 к статье Владимира о Байесовской оптимизации, как она выстраивает кривую по нескольким точкам. Но тогда ним и лес/нс не нужны - можно просто искать ответ прямо на этой кривой.
Другая проблема, - если оптимизатор недообучится т тогда он будет учить НС непонятной фигне.
 образец которому учили
образец которому учили 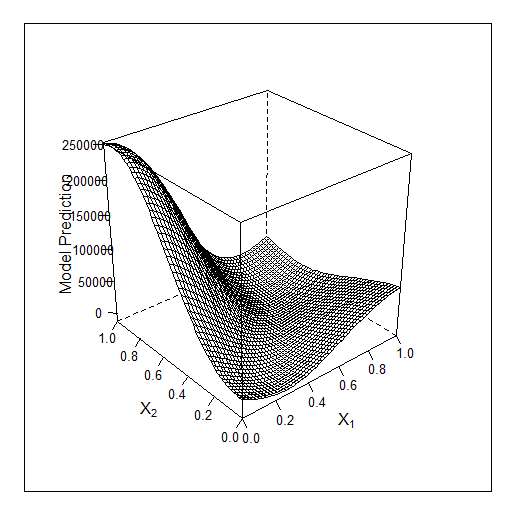
Вот для 3 признаков работа Байеса
Вот из-за придурковатых в теме вообще не интересно становится общаться
ноют че-то себе под нос
Так о чем общаться с вами? Вы просто ссылки коллекционируете и разное наукообразие собираете чтобы впечатлить новичков, СанСаныч всё уже написал в своей статье, добавить можно мало чего, теперь подтянулись всякие продавцы и статейщики размазали своими вилами всё в стыд и срам аж противно. "математиков" из себя строят, "квантов"....
Хотите математике попробуйте это почитать http://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf
А не поймете никакой вы не математик, а пшикне совсем, здесь понятнее должно быть
https://habr.com/ru/post/276355/
спектр применения большой, как конкретно будет применяться - тот еще вопрос
вечером почитаю