OpenCL: внутренние тесты реализации в MQL5 - страница 29
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
...
--
Сделай 512 и посмотри чего получишь. Не боись кромсать программу, она только целее будет от этого. :) Сделаешь - сюда выложи.
ОК! При 512 пассах и 144000 баров:
Ну и если 60 оптимальный вариант, то вообще круто:
//---
То есть, на самом слабом ноутбуке из представленных в этой ветке, вот такой результат. Так что очень перспективно.
//---
К сожалению пока не могу на эту тему свободно общаться, так как ещё даже не изучил статью joo и в нейросетях совсем не ковырялся, а тут ещё OpenCL. Использовать тот или иной код не понимая каждую строчку в нём не могу. Хочу всё знать. ))) Пока работаю над движком торговой программы. Что-то так много всего нужно делать, что уже голова кругом. )))
Увеличил CountBars в 30 раз (до 4 320 000), решил проверить стойкость камня к нагрузке.
Пофигу всё: пашет, греется, но не сильно потеет. Температура потихоньку растет, но уже добралась до насыщения.
Красная линия - температура, зеленая - нагрузка ядер.
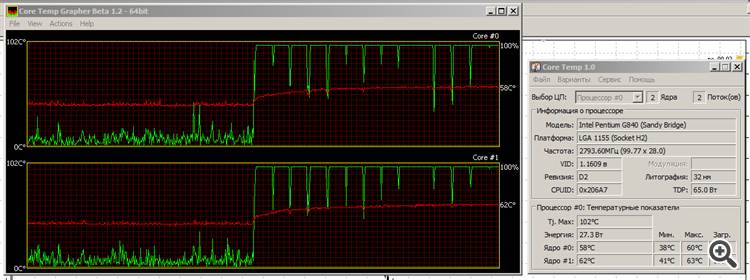
Вот за это я и люблю Intel образца Sandy Bridge: он "зеленый". Да, графика не ахти какая, но мы еще посмотрим, каким станет Ivy Bridge......
Вот за это я и люблю Intel образца Sandy Bridge: он "зеленый". Да, графика не ахти какая, но мы еще посмотрим, каким станет Ivy Bridge...Оу. Вот это реальный стресс-тест. :) Мой бы уже загнулся наверное.
Тогда уж каким будет Haswell и затем Rockwell ещё немного позднее... )))
Пример реализации папоротника Барнсли на OpenCL.
Расчет производится по алгоритму Chaos Game (пример), для создания уникальных траекторий используется генератор случайных чисел с базой генерации, зависящей от идентификатора нити, который возвращает get_global_id(0).
При масштабировании кол-во точек, требуемых для сохранения качества изображения, растет квадратично, поэтому в данной реализации предполагается, что каждый из экземпляров ядра отрисует фиксированное количество точек, попавших в видимую область.
Количество расчетных нитей задается в строке 191:
кол-во точек - в строке 233:
UPD
IFS-fern.mq5 - CPU-аналог
При scale=1000:
Сделал трёхслойку 16x7x3 нейронов. Собсно сделал ещё позавчера, сегодня отладил. До этого не сходились результаты при проверке на ЦПУ - причины описывать здесь не буду (хотя эпопея довольно любопытная и поучительная), по крайней мере не сейчас - спать очень хоцца. :)
Временные характеристики :
Завтра сделаю Optimizer для этой сетки. Потом займусь загрузкой реальных данных и доводкой тестера до реалистичных расчётов проверяемых на МТ5-тестере. Затем буду заниматься генератором MLP сеток+cl-кодов для их же оптимизации.
Исходник не выкладываю - жаба. Но для желающих потестить на своём железе в прицепе ex5.
У меня все стабильно, как при Путине:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
Кстати, обрати внимание: по времени исполнения на CPU разница между твоей системой и моей (на основе Pentium G840) уже не такая большая.
У тебя RAM быстрая? У меня 1333 MHz.
И еще: интересно, что при вычислениях на CPU у меня загружены оба ядра. Резкое снижение загрузки в конце - это уже после окончания вычислений. Что бы это значило?
У меня все стабильно, как при Путине:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1. Кстати, обрати внимание: по времени исполнения на CPU разница между твоей системой и моей (на основе Pentium G840) уже не такая большая.
2. У тебя RAM быстрая? У меня 1333 MHz.
1. Я тут на досуге свой разгон восстановил. У меня как-то машина круто зависла (как потом выяснилось шнур питания дисков вылетел из гнезда) так я в поисках чудес нажал кнопку "MemoryOK" на материнской плате. После чего всё равно не заработало, только все параметры CMOSa сбросились в состояние по умолчанию. А сейчас я опять догнал частоту процессора до 3840 МГц. Поэтому сейчас пошустрей работает.
2. До сих пор не могу понять. :) В биосе отображается 1866Mhz, но ни один тест не подтверждает. В частности тот бенчмарк, на который Ренат ссылку выкладывал показывает 1600MHz. А винда вообще показывает 1033MHz :))) При том, что сама память по номиналам двухгигагерцовая, а мать тянет (фицияльно) до 1866.
И еще: интересно, что при вычислениях на CPU у меня загружены оба ядра. Резкое снижение загрузки в конце - это уже после окончания вычислений. Что бы это значило?
Так может у тебя вообще не на ГПУ считает? Драйвер-то встал, но.. У меня единственно объяснение - расчёт происходит на ЦПУ-ОпенЦЛ, только, естественно, на всех доступных ядрах и с использованием векторных SSE-инструкций. :)
Второй вариант - считает одновременно и на ГПУ и на ЦПУ. Не знаю как эта (ЦПУ-ЖПУ) поддержка осуществляется драйвером, но в принципе не исключаю и такой вариант запуска процессинга опенЦЛ.
Это мои домыслы, если чё. Или как модно сейчас писать - "ИМХО". ;)
Сомневаюсь. Тем более что у меня всего-то 2 ядра. Откуда профит в 25 раз тогда берется?
Ну если в камень зашита вся Intel Math Kernel Library или Intel Performance Primitives (я их не качал), то это еще возможно... в некоторых случаях. Но это вряд ли, они ж сотни мегов весят.
Надо посмотреть, что гугл по этому поводу говорит.
Mathemat: И еще: интересно, что при вычислениях на CPU у меня загружены оба ядра.
Нет, я говорил о чистых вычислениях на CPU, без всяких OpenCL. Там-то загрузка как раз меньше 100%, причем на каждом ядре - сравнимые величины загрузки. А вот при выполнении кода OpenCL она вырастает до 100%, что вполне объяснимо именно работой на GPU.