
Нейросети в трейдинге: Агент с многоуровневой памятью (Окончание)

Введение
В предыдущей статье мы рассмотрели теоретические основы фреймворка FinMem — инновационного агента на основе больших языковых моделей (LLM). Данный фреймворк использует уникальную систему многоуровневой памяти, которая позволяет эффективно обрабатывать данные разной природы и временной значимости.
Модуль памяти FinMem разделён на две основные части:
- Рабочая память — предназначения для обработки краткосрочных данных, таких как ежедневные новости и рыночные колебания.
- Долговременная память — хранит информации с долгосрочной ценностью, включая аналитические отчёты и исследования.
Стратифицированная структура памяти позволяет агенту приоритизировать данные, концентрируясь на наиболее релевантных для текущих рыночных условий. Например, краткосрочные события анализируются одномоментно, в то время как информация с глубоким влиянием сохраняется для дальнейшего использования.
Модуль профилирования FinMem адаптирует работу агента под конкретные профессиональные контексты и рыночные условия. Учитывая индивидуальные предпочтения и риск-профиль пользователя, агент способен оптимизировать свою стратегию, обеспечивая максимальную эффективность торговых операций.
Модуль принятия решений объединяет текущие данные и сохранённые воспоминания, генерируя стратегии, которые учитывают как краткосрочные тренды, так и долгосрочные закономерности. Такой когнитивно-инспирированный подход позволяет агенту запоминать ключевые рыночные события и адаптироваться к новым сигналам, что существенно повышает точность и результативность инвестиционных решений.
Результаты экспериментов, проведенных авторами фреймворка, показывают, что FinMem превосходит другие модели автономной торговли. Даже при ограниченных исходных данных агент демонстрирует выдающуюся эффективность в обработке информации и формировании стратегий. Его способность управлять когнитивной нагрузкой позволяет одновременно анализировать десятки рыночных сигналов и выделять ключевые из них. Агент структурирует сигналы по важности и принимает обоснованные решения даже в условиях ограниченного времени.
Кроме того, FinMem обладает уникальной способностью к обучению в реальном времени, что делает его гибким к изменяющимся рыночным условиям. Это позволяет агенту не только успешно справляться с текущими задачами, но и постоянно совершенствовать свои подходы, адаптируясь к новым данным. FinMem объединяет когнитивные принципы и передовые технологии, предлагая современное решение для работы в условиях сложных динамичных финансовых рынков.
Авторская визуализация информационного потока фреймворка FinMem представлена ниже.
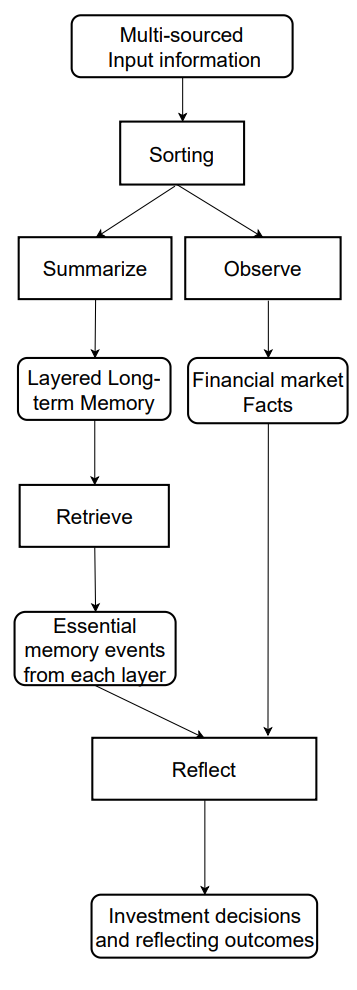
В предыдущей статье мы начали реализацию предложенных авторами фреймворка подходов средствами MQL5. И предложили собственное видение модуля многоуровневой памяти CNeuronMemory, которое значительно отличается от авторской версии. Ведь в своей реализации фреймворка FinMem мы исключили большую языковую модель, являющуюся ключевым компонентом оригинальной концепции. Что наложило свой отпечаток на все компоненты модели.
Несмотря на это, мы приложили максимум усилий, чтобы воспроизвести основные информационные потоки фреймворка. В частности, объект CNeuronFinMem был разработан таким образом, чтобы сохранить стратифицированный подход к обработке данных. Этот объект успешно интегрирует методы обработки краткосрочной информации и долгосрочных стратегий, обеспечивая стабильную и предсказуемую работу в условиях динамичных рынков.
Построение фреймворка FinMem
Напомню, что мы остановились на построении комплексного алгоритма предложенного фреймворка в рамках объекта CNeuronFinMem, структура которого представлена ниже.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Ранее мы рассмотрели, как осуществляется инициализация объекта, и теперь перейдём к построению метода прямого прохода feedForward, который принимает два основных параметра.
Первый — это тензор, представляющий собой многомерный массив данных, характеризующий состояние окружающей среды. Он содержит различные рыночные данные, такие как текущие котировки и показатели анализируемых технических индикаторов. Такой подход позволяет учитывать широкий спектр переменных, обеспечивая алгоритму возможность принимать решения на основе комплексного анализа.
Второй параметр — это вектор, содержащий информацию о состоянии торгового счёта. Он включает текущий баланс, данные о прибыли и убытках, а также временную метку. Этот компонент обеспечивает доступность актуальной информации и поддерживает точность расчётов в режиме реального времени.
bool CNeuronFinMem::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cTransposeState.FeedForward(NeuronOCL)) return false;
Выполнения всестороннего анализа состояния окружающей среды мы начинаем с обработки исходных данных, представленных в виде тензора многомерного массива. Процедура транспонирования позволяет преобразовать полученный массив, обеспечивая удобство работы с различными проекциями для более детальное выделения ключевых характеристик.
Далее две проекции исходных данных направляются в специализированные модули памяти для углублённого анализа. Первый модуль предназначен для изучения временной динамики рыночных параметров, организованных в виде баров, что позволяет зафиксировать и интерпретировать комплексное поведение анализируемого финансового инструмента. Второй модуль сосредоточен на анализе унитарных последовательностей мультимодального временного ряда, что даёт возможность выявлять скрытые зависимости между различными индикаторами и фиксировать их корреляционные связи. Это создаёт интегрированное представление о текущем состоянии рынка.
Подобная структура анализа обеспечивает высокий уровень точности и способствует гибкой адаптации модели к изменениям рыночной динамики, что критически важно для достижения надёжных и своевременных решений в финансовой среде.
if(!cMemory[0].FeedForward(NeuronOCL) || !cMemory[1].FeedForward(cTransposeState.AsObject())) return false;
Объединения результатов анализа двух модулей памяти осуществляется с помощью блока кросс-внимания, который позволяет обогащать мультимодальные временные ряды результатами анализа унитарных последовательностей. Это способствует повышению точности и полноты полученной информации, делая её более пригодной для принятия взвешенных решений.
if(!cCrossMemory.FeedForward(cMemory[0].AsObject(), cMemory[1].getOutput())) return false;
Далее исследуется влияние рыночных изменений на состояние баланса. Для этого результаты многоуровневого анализа рыночной ситуации сопоставляются с вектором текущего состояния счёта средствами модуля кросс-внимания. Такой методологический подход позволяет точнее оценить влияние рыночных событий на финансовые показатели. Анализ даёт возможность учитывать сложные зависимости между событиями на рынке и финансовыми результатами. Это особенно важно для прогнозирования и управления рисками.
if(!cMemoryToAccount.FeedForward(cCrossMemory.AsObject(), SecondInput)) return false;
Следующим шагом является работа с блоком оперативного принятия решений. Данная работа начинается с сопоставления последних действий Агента с текущими прибылями и убытками, что позволяет определить их взаимозависимости. На данном этапе мы определяем эффективность используемой политики и необходимость её корректировки. Это позволяет избегать шаблонных действий и повышать гибкость торговой стратегии, что особенно ценно в условиях высокой волатильности.
Кроме того, на данном шаге модель может оценить риск, допустимый для следующей торговой операции.
Важно отметить, что тензор последних действий Агента является третьим источником данных. В то же время, мы помним об ограничении метода, допускающего обработку только двух информационных потоков исходных данных. Но воспользуемся тем фактом, что тензор действий Агента формируется на выходе данного объекта и сохраняется в буфере его результатов до завершения операций очередного метода прямого прохода. Это обеспечивает возможность вызова прямого прохода внутреннего блока кросс-внимания с использованием указателя на текущий объект, аналогично рекуррентным модулям.
if(!cActionToAccount.FeedForward(this.AsObject(), SecondInput)) return false;
На данном этапе необходимо обеспечить сохранение тензора последних действий Агента до его заполнения новыми данными, чтобы гарантировать корректное выполнение операций обратного прохода. Для этого производится замена указателей на соответствующие буферы данных, что минимизирует риск потери информации.
if(!SwapBuffers(Output, PrevOutput)) return false;
После этого вызывается метод родительского класса, задачей которого является формирование нового тензора действий Агента. Этот процесс основывается на результатах аналитических операций, проведённых ранее в рамках текущего метода. Таким образом, создаётся непрерывная цепочка взаимодействия между различными модулями, позволяющая поддерживать высокий уровень согласованности и актуальности данных.
if(!CNeuronRelativeCrossAttention::feedForward(cActionToAccount.AsObject(), cMemoryToAccount.getOutput())) return false; //--- return true; }
И завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Алгоритм прямого прохода, построенный нами, имеет нелинейную природу, что существенно влияет на обработку данных в методах обратного прохода. Это особенно заметно в алгоритме распределения градиентов ошибки, реализованном в методе calcInputGradients. Чтобы корректно выполнить данный процесс, информация должна обрабатываться строго в соответствии с логикой прямого прохода, но в обратном порядке. Это требует учёта всех уникальных характеристик архитектуры модели для обеспечения точности и согласованности вычислений.
В параметрах метода calcInputGradients получаем указатели на объекты двух потоков исходных данных, в которые нам предстоит передать градиенты ошибки в соответствии с влиянием исходных данных на конечный результат работы модели.
bool CNeuronFinMem::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondInput || !SecondGradient) return false;
И в теле метода мы сразу проверяем актуальность полученных указателей. Ведь в противном случае все дальнейшие операции не имеют смысла ввиду невозможности передачи дальше их результатов.
Напомню, операции прямого прохода завершились вызовом метода родительского класса, который отвечает за итоговую обработку. Соответственно, распределение градиента ошибки стартует с одноименного метода родительского класса. Его задача — направить градиент ошибки на два внутренних блока кросс-внимания параллельных магистралей обработки данных.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionToAccount.AsObject(), cMemoryToAccount.getOutput(), cMemoryToAccount.getGradient(), (ENUM_ACTIVATION)cMemoryToAccount.Activation())) return false;
Здесь следует обратить внимание, что по одной из информационных магистралей мы рекуррентно использовали результаты предшествующего прямого прохода нашего объекта в качестве исходных данных. Это приводит к созданию непрерывного цикла в процессе обратного прохода, который нам предстоит разорвать.
Для корректного выполнения операций распределения градиента ошибки нам необходимо сначала вернуть в буфер результаты значения предпоследнего прямого прохода, которые мы использовали в качестве исходных данных для модуля кросс-внимания сопоставления их с полученным финансовым результатом. Это достигается путем подмены указателей на буферы данных, что позволяет вернуть данные без потери информации и с минимальными затратами.
if(!SwapBuffers(Output, PrevOutput)) return false;
Кроме того, нам необходимо подменить указатель на буфер градиентов ошибки нашего объекта, чтобы не потерять данные, полученные ранее от последующего слоя. Для этого мы воспользуемся любым свободным на данный момент буфером достаточного размера. Очевидно, что размер тензора описания состояния окружающей среды значительно больше вектора действий Агента. Это позволяет нам взять один из буферов указанной магистрали.
CBufferFloat *temp = Gradient; if(!SetGradient(cMemoryToAccount.getPrevOutput(), false)) return false;
И теперь, когда мы обезопасили все необходимые данные, вызываем метод распределения градиентов ошибки через блок кросс-внимания анализа влияния предшествующих действий агента на полученный финансовый результат.
if(!calcHiddenGradients(cActionToAccount.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
После чего возвращаем указатели на буферы данных в исходное состояние.
if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
На данном этапе мы распределили градиент ошибки по магистрали оценки последних действий Агента. При этом передали соответствующие градиенты ошибки на магистраль памяти и буфер вектора описания счета. Однако следует обратить внимание, что данные буфера описания состояния счета участвуют в двух информационных потоках: памяти и действий Агента. По-последнему мы уже передали градиент ошибки. Теперь определим влияние данных о состоянии счета на итоговый результат работы модели по магистрали памяти и суммируем значения, полученные от двух информационных потоков.
if(!cCrossMemory.calcHiddenGradients(cMemoryToAccount.AsObject(), SecondInput, cMemoryToAccount.getPrevOutput(), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, cMemoryToAccount.getPrevOutput(), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
Далее нам предстоит распределить градиент ошибки по магистрали памяти до уровня исходных данных основной магистрали в соответствии с их влиянием на итоговый результат работы модели. И здесь у нас снова 2 информационных потока анализа исходных данных в разных проекциях. Сначала мы распределяем градиент ошибки по указанным информационным потокам.
if(!cMemory[0].calcHiddenGradients(cCrossMemory.AsObject(), cMemory[1].getOutput(), cMemory[1].getGradient(), (ENUM_ACTIVATION)cMemory[1].Activation())) return false;
И спускаем его до уровня объекта транспонирования исходных данных.
if(!cTransposeState.calcHiddenGradients(cMemory[1].AsObject())) return false;
На данном этапе нам остается передать градиент ошибки в объект исходных данных от двух параллельных магистралей памяти. Сначала мы спускаем погрешности по одной магистрали.
if(!NeuronOCL.calcHiddenGradients(cMemory[0].AsObject())) return false;
А затем осуществляем подмену буферов данных и проводим градиент ошибки по второй магистрали.
temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cTransposeState.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cTransposeState.AsObject()) || !NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cTransposeState.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Остается суммировать данные двух информационных потоков и вернуть указатели на буферы данных в исходное состояние. После чего возвращаем логический результат вызывающей программе и завершаем работу метода.
На этом мы завершаем рассмотрение алгоритмов построения методов объекта CNeuronFinMem. С полным кодом данного класса и всех его методов Вы можете самостоятельно ознакомиться во вложении.
Архитектура модели
Мы завершили реализацию подходов фреймворка FinMem средствами MQL5 в рамках объекта CNeuronFinMem. Эта реализация обеспечивает базовую функциональность и основу для дальнейшей работы с обучающими алгоритмами. Следующим шагом осуществим интеграцию созданного объекта в обучаемую модель Агента, которая служит ядром для принятия решений в финансовых системах. Архитектура обучаемой модели представлена в методе CreateDescriptions.
Следует отметить, что фреймворк FinMem не ограничивается исключительно архитектурными решениями. Он также включает уникальные алгоритмы обучения, которые позволяют модели адаптироваться к изменениям и эффективно обрабатывать данные в условиях сложной финансовой среды. Но к процессу обучения мы вернемся чуть позже. Сейчас же для нас важно, что обучать мы будем только одну модель — Агента.
В параметрах метода CreateDescriptions мы получаем указатель на динамический массив для записи архитектуры создаваемой модели.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
В теле метода мы сразу проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр динамического массива.
Далее мы, как обычно, создаем блок предварительной обработки исходных данных. Этот блок включает полносвязный слой, принимающий исходные данные, и слой пакетной нормализации, который снижает чувствительность модели к изменениям масштабов данных и улучшает стабильность обучения. Такой подход обеспечивает эффективное функционирование последующих компонентов модели.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее идет разработанный нами блок фреймворка FinMem, который служит основой для реализации ключевых аспектов обработки данных и формирования решений.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinMem; //--- Windows { int temp[] = {BarDescr, AccountDescr, 2*NActions}; //Window, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
В массиве windows мы указываем 3 основных размерности тензоров исходных данных: описания одного бара, состояния счета и действий агента. Последний одновременно является и размерностью вектора результатов работы блока.
Обратите внимание, что в данном случае мы указали размерность тензора действий Агента в 2 раза больше соответствующей константы. Такой подход позволяет нам внедрить подходы стохастической головы Агента. Как обычно в таких случаях, первая часть указывает на средние значения распределений, а вторая — на соответствующие дисперсии. И в связи с этим хочется напомнить, что при инициализации объектов кросс-внимания, работающих с тензором действий агента, мы делили основной поток исходных данных на 2 равных вектора. Это позволит нам получить на выходе блока согласованные значения средних и соответствующих дисперсий.
Генерация значений в рамках заданных распределений осуществляется средствами слоя латентного состояния вариационного автоэнкодера.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А завершает архитектуру модели сверточный слой, который спроецирует полученные значения в нужный нам диапазон действий Агента.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
После чего нам остается лишь вернуть логический результат выполнения операций вызывающей программе и заверить работу метода.
Программа обучения
Мы выполнили большую работу на пути реализации подходов, предложенных авторами фреймворка FinMem. И на данном этапе у нас уже сформирована архитектура модели, позволяющая эффективно обрабатывать финансовые данные и адаптироваться к сложным рыночным условиям. Особенностью созданной модели является использование многоуровневой памяти, имитирующей когнитивные процессы человека.
Но, как было сказано выше, авторы данного фреймворка помимо архитектурных решений предложили и алгоритм обучения модели, который основан на многоуровневом подходе к обработке данных. Это позволяет учитывать не только линейные зависимости, но и сложные нелинейные взаимосвязи между параметрами. На этапе обучения модель получает доступ к обширному спектру информации из нескольких источников, что способствует созданию комплексного представления о финансовой среде. Это обеспечивает адаптацию к изменяющимся рыночным условиям и повышает точность прогнозов.
В процессе обучения при получении запроса с анализируемыми данными модель активирует два ключевых процесса: наблюдение и обобщение. Система наблюдает за рыночными метками, которые включают ежедневные изменения цен анализируемого финансового инструмента. Эти метки служат индикаторами действий "Купить" или "Продать". Данная информация позволяет модели определить и приоритизировать наиболее релевантные воспоминания, ранжируя их на основе оценок извлечения из каждого слоя долговременной памяти.
В свою очередь, долговременная память FinMem позволяет сохранять критически важные данные для будущего использования события и воспоминания. Они обрабатываются на более глубоких уровнях памяти, что обеспечивает их долговременное хранение. Повторяющиеся торговые операции и реакции рынка укрепляют релевантность сохранённой информации, что способствует постоянному улучшению качества принимаемых решений.
Принятое нами ранее решение об отказе от использования большой языковой модели накладывает свой отпечаток и на процесс обучения. Тем не менее мы постараемся сохранить предложенные подходы обучения модели. В частности, в процессе обучения позволим заглядывать модели "в будущее", как это мы делали при обучении различных моделей прогнозирования ценового движения. Но есть один нюанс. В данном случае мы не можем просто модели передать информацию о предстоящем ценовом движении. На выходе нашей модели формируются параметры торговой операции. И в процессе обучения нам необходимо передавать в качестве обратной связи (обучающих меток) аналогичные данные. Поэтому, в процессе обучения моделей на основании имеющейся информации о предстоящем ценовом движении мы постараемся сгенерировать почти идеальное торговое решение.
Предлагаю посмотреть на реализацию предложенного подхода в коде. В рамках статьи мы рассмотрим лишь метод непосредственного обучения модели Train. А с полным кодом программы обучения "...\Experts\FinMem\Study.mq5" Вы можете ознакомиться во вложении.
Начало метода обучения моделей вполне традиционное: мы генерируем вектор вероятностей выбора траекторий из буфера воспроизведения опыта на основании доходности сохраненных проходов и объявляем необходимые локальные переменные.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false;
После чего организовываем цикл обучения моделей. Однако в данном случае мы используем рекуррентные модели, которые чувствительны к последовательности подачи исходных данных. Что приводит нас к необходимости использования системы вложенных циклов. В рамках внешнего цикла мы сэмплируем одну траекторию из буфера воспроизведения опыта и начальное состояние на ней. А во внутреннем цикле будем последовательно перебирать состояния на выбранной траектории. Количество итераций обучения и размер одного пакета указываются во внешних параметрах программы обучения.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
Здесь следует обратить внимание, что перед началом обучения на каждой новой траектории нам необходимо очистить память модели. Ведь сохраненные в ней данные должны иметь отношение к анализируемому состоянию окружающей среды.
В теле вложенного цикла мы сначала извлекаем описание анализируемого состояние окружающей среды из буфера воспроизведения опыта и формируем вектор описания состояния счета.
Здесь следует обратить внимание, что мы именно формируем вектор описания состояния счета. Ранее мы просто переносили в данный вектор информацию из буфера воспроизведения опыта, немного изменив формат представления данных. В данном же случае нам следует учесть тот факт, что модель учится анализировать влияние последних действий агента на полученный финансовый результат. А значит, вектор состояния счета должен зависеть от них, чего нельзя добиться простым переносом информации из буфера воспроизведения опыта.
Сначала мы формируем гармоники временной метки анализируемого состояния окружающей среды.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
И получим вектор последних действий Агента, сохраненных в буфере модели.
//--- Previous Action
Actor.getResults(result);
Тут же мы вычислим доходность данного действия по изменению цены в рамках последнего бара анализируемого состояния окружающей среды. Должен признать, что для упрощения алгоритма используется базовый анализ. Мы не учитываем такие аспекты, как срабатывание уровней стоп-лосса, тейк-профита, а также возможные комиссии за совершение торговых операций. Кроме того, предполагается, что перед выполнением последней операции агента все ранее открытые позиции были закрыты. Этот подход оправдан для поверхностной оценки эффективности модели, но перед её использованием в реальной торговле необходимо будет детально учесть все особенности рынка и связанные с ним параметры.
Для вычисления доходности последней операции мы просто умножаем изменение цены на разность объемов сделок покупки и продажи из вектора последних действий агента.
float profit = float(bState[0] / (_Point * 10) * (result[0] - result[3]));
Напомню, что в качестве изменения цены мы рассматриваем разницу между ценами закрытия и открытия. А значит получаем положительное значение для растущей свечи и отрицательное в противном случае. Разница объемов торговых операций нам так же дает положительное число для операций покупки и отрицательное — для продажи. Следовательно, произведение двух указанных значений дает корректный знак торговой операции.
Далее мы берем из буфера воспроизведения опыта данные баланса и эквити предшествующего состояния, когда предполагалось совершение торговой операции, предложенной агентом на предыдущем шаге.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
Как было сказано ранее, мы предполагаем закрытие всех ранее открытых позиций перед совершением торговых операций. Это предполагает изменение баланса до уровня эквити.
bAccount.Clear(); bAccount.Add((PrevEquity - PrevBalance) / PrevBalance);
Изменение эквити за последний торговый бар равно посчитанному выше финансовому результату последней торговой операции.
bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity);
Торговую операцию мы осуществляем только на разницу объемом, что и отражается в показателях открытых позиций.
bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0));
Соответственно, финансовый результат мы указываем только для открытой позиции.
bAccount.Add((bAccount[3]>0 ? profit / PrevBalance : 0)); bAccount.Add((bAccount[4]>0 ? profit / PrevBalance : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
И после подготовки исходных данных мы осуществляем прямой проход нашей модели, в ходе выполнения операций которого будет сформирован новый вектор действий Агента.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Теперь, для осуществления операций обратного прохода нам необходимо подготовить целевые значения "идеальной" торговой операции на основании данных о предстоящем ценовом движении. Для этого мы извлекаем из буфера воспроизведения опыта данные на заданный горизонт планирования.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break;
Переформатируем их в матрицу.
if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
А затем изменим порядок строк матрицы таким образом, чтобы данные соответствовали хронологической последовательности.
for(int i = 0; i < NForecast / 2; i++) { if(!fstate.SwapRows(i, NForecast - i - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
В первой колонке нашей прогнозной матрицы содержатся данные об изменении цены за каждый бар. Мы возьмем накопительную сумму этих значений, что позволит нам получить общее изменение цены на каждом шаге прогнозного периода.
target = fstate.Col(0).CumSum();
Здесь следует обратить внимание, что такой подход не учитывает возможные гепы. Ввиду относительно низкой вероятности подобных событий мы готовы пренебречь этим в ходе экспериментов. Но такой подход не применим при подготовке реальных торговых решений.
Дальнейшее формирование вектора целевых действий агента зависит от предыдущей операции. Если на предыдущем шаге была открыта позиция, то мы ищем точку выхода. Рассмотрим алгоритм на примере операции покупки. Вначале определим уровень установленного стоп-лосса и объявим необходимые локальные переменные.
if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0;
Далее мы организуем цикл перебора прогнозных значений ценового движения с поиском позиции срабатывания текущего стоп-лосса. В ходе перебора значений мы фиксируем максимальное и минимальное значение с целью установки новых уровней стоп-лосса и тейк-профита.
for(int i = 0; i < NForecast; i++) { tp = MathMax(tp, target[i] + fstate[i, 1] - fstate[i, 0]); pos = i; if(cur_sl >= target[i] + fstate[i, 2] - fstate[i, 0]) break; sl = MathMin(sl, target[i] + fstate[i, 2] - fstate[i, 0]); }
В случае нисходящего движения значение тейк-профита ожидаемо останется равным "0", что приведет к формированию нулевого вектора действий агента. А как следствие закрытие всех открытых позиций и ожиданию открытия нового бара.
Если же ожидается движение цены вверх, то формируется новый вектор действий агента с указанием скорректированных значений торговых уровней.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.01f); result[1] = tp; result[2] = sl; for(int i = 3; i < NActions; i++) result[i] = 0; bActions.AssignArray(result); } }
Аналогичным образом формируется вектор действий при поиске точки выхода из короткой сделки.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int i = 0; i < NForecast; i++) { tp = MathMin(tp, target[i] + fstate[i, 2] - fstate[i, 0]); pos = i; if(cur_sl <= target[i] + fstate[i, 1] - fstate[i, 0]) break; sl = MathMax(sl, target[i] + fstate[i, 1] - fstate[i, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.01f); result[4] = tp; result[5] = sl; for(int i = 0; i < 3; i++) result[i] = 0; bActions.AssignArray(result); } }
Немного иной подход в случае отсутствия открытой позиции. В этом случае мы сначала определяем ближайшую доминирующую тенденцию.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin])) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
И вектор действий формируется в рамках данной тенденции. А объем сделки мы указываем в размере минимального лота на каждые 100USD текущего баланса.
if(argmin == 0 || argmax < argmin) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong i = 0; i < argmax; i++) { tp = MathMax(tp, target[i] + fstate[i, 1] - fstate[i, 0]); pos = i; if(cur_sl >= target[i] + fstate[i, 2] - fstate[i, 0]) break; sl = MathMin(sl, target[i] + fstate[i, 2] - fstate[i, 0]); } if(tp > 0) { sl = (float)MathMin(MathAbs(sl) / (MaxSL * Point()), 1); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(Buffer[tr].States[i].account[0] / 100 * 0.01); result[1] = tp; result[2] = sl; for(int i = 3; i < NActions; i++) result[i] = 0; bActions.AssignArray(result); } } else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong i = 0; i < argmin; i++) { tp = MathMin(tp, target[i] + fstate[i, 2] - fstate[i, 0]); pos = i; if(cur_sl <= target[i] + fstate[i, 1] - fstate[i, 0]) break; sl = MathMax(sl, target[i] + fstate[i, 1] - fstate[i, 0]); } if(tp < 0) { sl = (float)MathMin(MathAbs(sl) / (MaxSL * Point()), 1); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(Buffer[tr].States[i].account[0] / 100 * 0.01); result[4] = tp; result[5] = sl; for(int i = 0; i < 3; i++) result[i] = 0; bActions.AssignArray(result); } } } } }
Сформировав вектор "почти идеальных" действий мы осуществляем обратный проход нашей модели, минимизируя отклонение прогнозных действий агента от наших целевых значений.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Теперь нам остается проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации нашей системы циклов.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
А после успешного выполнения всех итераций нашей системы циклов обучения модели мы очищаем поле комментариев на графике финансового инструмента, которое использовалось для информирования пользователя. Выводим в журнал результаты обучения и инициализируем процесс завершения работы программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение алгоритмов построения фреймворка FinMem средствами MQL5. А с полным кодом всех представленных объектов, их методов и программ, используемых при подготовке статьи, Вы можете самостоятельно ознакомиться во вложении.
Тестирование
Последние две статьи были посвящены фреймворку FinMem. В них мы реализовали свое видение подходов, предложенных авторами данного фреймворка, средствами MQL5. И теперь подошли к самому волнительному этапу — проверке эффективности реализованных решений на реальных исторических данных.
Следует подчеркнуть, что в процессе реализации мы внесли значительные модификации в алгоритмы фреймворка FinMem. Следовательно, оцениваем только реализованное решение, а не оригинальный фреймворк.
Обучение модели проводилось на исторических данных валютной пары EURUSD за 2023 год с использованием таймфрейма H1. Настройки индикаторов, анализируемых моделью, были оставлены на уровне значений по умолчанию.
Для начального этапа обучения использовалась выборка данных, сформированная в рамках предыдущих исследований. Реализованный алгоритм обучения с формированием "почти идеальных" целевых действий Агента позволяет обучать модель без обновления обучающей выборки. Однако с целью охвата более широкого спектра состояний счета я бы рекомендовал по возможности добавить регулярное обновление обучающей выборки.
После нескольких циклов обучения нам удалось получить модель, демонстрирующую устойчивую прибыльность как на обучающих, так и на тестовых данных. Финальное тестирование проводилось на исторических данных за январь 2024 года с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
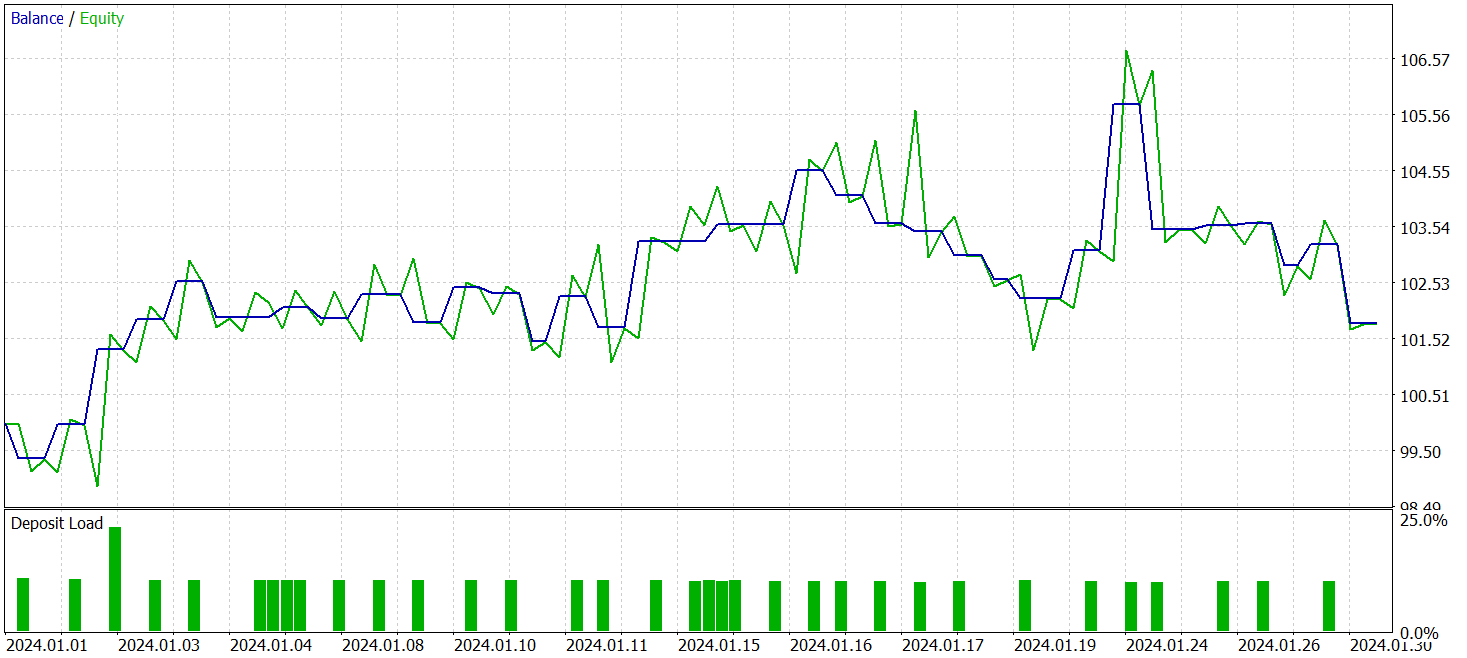
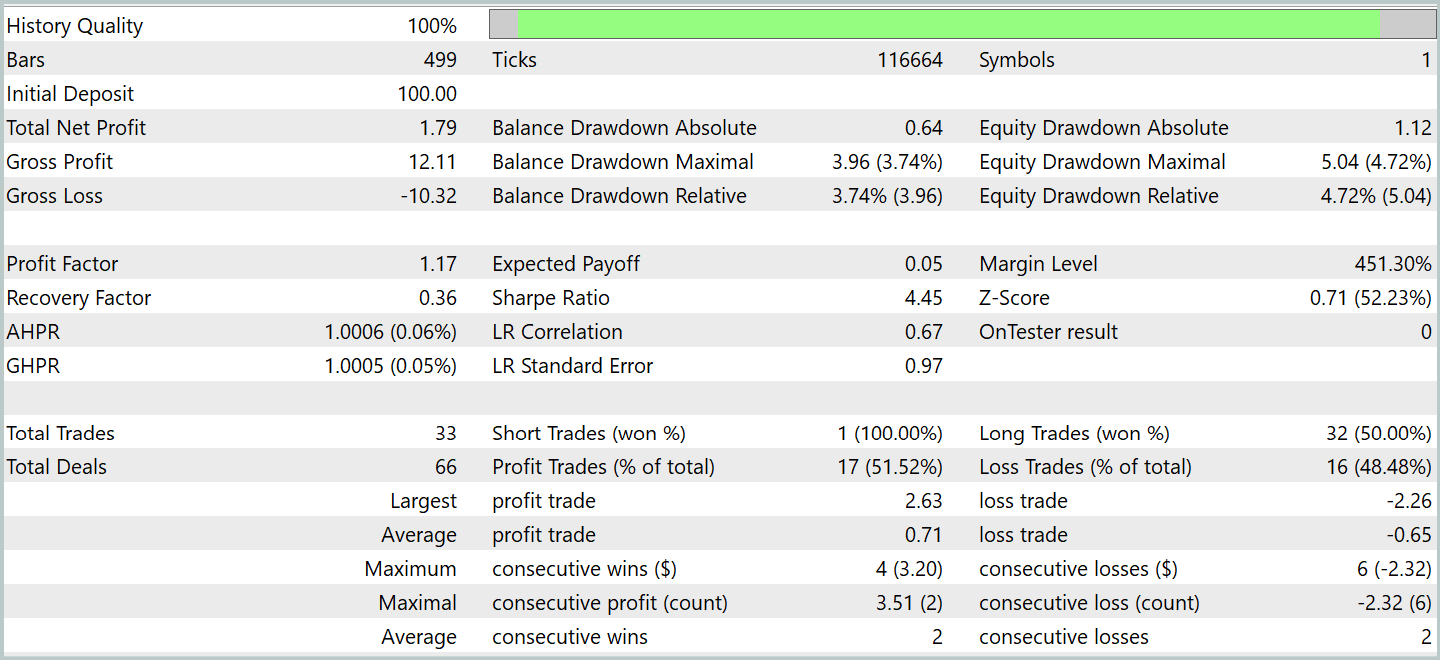
За период тестирования модель совершила 33 торговых операции и чуть более половины из них были закрыты с прибылью. При этом превышение средней и максимальной прибыльной позиции над аналогичными показателями убыточных сделок позволило модели продемонстрировать тенденцию к росту баланса. Что свидетельствует о потенциале предложенных подходов и возможности их использования в реальной торговле.
Заключение
Мы познакомились с фреймворк FinMem, который представляет собой новый этап в эволюции автономных торговых систем. Этот фреймворк сочетает когнитивные принципы и современные алгоритмы на основе больших языковых моделей. Многоуровневая память и способность к адаптации в реальном времени позволяют агенту принимать обоснованные и точные инвестиционные решения, даже в условиях нестабильности на рынках.
В практической части работы мы реализовали собственную интерпретацию предложенных подходов с использованием языка программирования MQL5, исключив при этом большую языковую модель. Результаты проведенных экспериментов подтверждают эффективность предложенных подходов и их применимость в реальной торговле. Однако для полноценного использования данной модели на реальных финансовых рынках необходимо провести дополнительную настройку модели и обучение на более репрезентативной обучающей выборке с тщательным всесторонним тестированием.
Ссылки
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования