
От начального до среднего уровня: Массив (I)

Введение
Представленные здесь материалы предназначены только для обучения. Ни в коем случае нельзя рассматривать это приложение как окончательное, цели которого будут иные, кроме изучения представленных концепций.
В предыдущей статье "От начального до среднего уровня: Массивы и строки (III)", мы объяснили и показали с помощью кода, соответствующего достигнутому на данный момент уровню знаний, как стандартная библиотека может переводить двоичные значения в десятичные, восьмеричные и шестнадцатеричные. Кроме того, мы создали двоичное представление в формате строки, что позволило нам легко визуализировать результат.
В дополнение к этой базовой концепции было продемонстрировано, как можно определить ширину пароля на основе секретной фразы. И, по счастливому совпадению, полученный пароль оказался с повторяющейся последовательностью символов. Это великолепно, так как это не было изначальной целью. На самом деле это просто удачное совпадение, но оно дает нам прекрасную возможность объяснить другие концепции и моменты, связанные с массивами и строками.
Кто-то может подумать, что мы расскажем о том, как работает каждая функция или процедура в стандартной библиотеке, но это не совсем наша цель. Наша настоящая цель - показать концепции, лежащие в основе каждого решения. Можно принимать решения в зависимости от типа проблемы, которую нужно решить. Хотя мы всё еще находимся на достаточно базовом уровне, у нас уже есть некоторые реальные возможности в плане программирования, что позволяет нам начать применять некоторые более продвинутые концепции.
Это не только облегчит нашу задачу, но и позволит вам прочитать немного более сложный код. Но не стоит беспокоиться о том, что мы увидим здесь. Мы будем вводить изменения постепенно, чтобы мы могли привыкнуть к ним и читать код без проблем, поскольку я склонен сворачивать или уплотнять выражения таким образом, что это может сбить с толку тех, кто только начинает работать.
В любом случае, давайте начнем данную статью с рассказа о том, что было в предыдущей. То есть мы узнаем один из многочисленных способов избежать именно того, что было получено путем факторизации пароля от секретной фразы.
Одно из множества решений
Хорошо. Сегодня мы начнем с того, что сделаем код более «красивым». Оригинальный код показан ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Код 01
На мой взгляд, код немного «неприятен». И это происходит так, потому что переменные, объявленные в строках 16 и 17, используются только в цикле в строке 21. Но если нам нужна переменная с таким же именем или другого типа, придется выполнить дополнительную работу, чтобы просто подправить код. Однако, как уже было показано в предыдущих статьях, мы можем объявлять переменные внутри цикла FOR.
А теперь обратите внимание. Если объявлено несколько переменных для использования только в цикле FOR, все они должны быть одного типа. НЕВОЗМОЖНО объявить и инициализировать переменные разных типов, как это происходит в первом выражении оператора FOR. Поэтому нам придется сделать небольшой выбор. Поскольку у переменных pos и i, объявленных в строках 16 и 17, тип uchar, а у переменной c, объявленной в операторе FOR, тип int, то мы можем изменить первые две на тип int или изменить переменную c на тип uchar. Однако, на мой взгляд, фраза длиннее 255 символов не имеет смысла. Поэтому мы можем найти золотую середину и установить все три переменные как ushort, поскольку они используются только в качестве индексов доступа. В соответствии с этим объяснением код 01 заменяется на код 02, как видно ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+
Код 02
Несмотря на кажущуюся путаницу, которую может вызвать код 02, он делает то же самое, что и код 01. Но я хотел бы обратить ваше внимание на строку 20. Прошу заметить, что теперь в первом выражении объявлены все переменные, которые будут использоваться в цикле, и только в этом цикле. Посмотрите как построено третье выражение оператора FOR. Обратите внимание, в данном случае невозможно произвести подобную настройку переменной i без использования тернарного оператора. Но важно отметить, что данная настройка решает только проблему сохранения индекса внутри массива, так как инкремент выполняется в строке 23.
Несмотря на это изменение, результат остался прежним, т.е. при запуске кода мы увидим в терминале нечто похожее на следующее изображение.
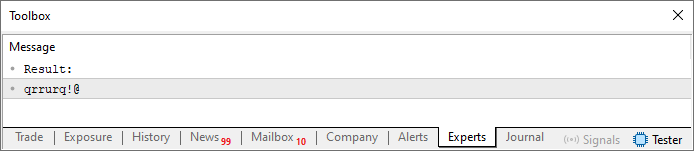
Рисунок 01
Теперь давайте немного подумаем. Мы видим повторение символов в выходной строке, потому что именно в строке 27 мы указываем на одно и то же место в строке szCodePhrase. Таким образом, при уменьшении значения в пределах строки, которая была задана в строке 13, мы всегда указываем на одну и ту же точку. Однако (и вот тут-то и возникает важный момент), если мы добавим текущую позицию к предыдущей, то получим новый и совершенно отличающийся индекс. Поскольку в строке 13 нет повторяющихся символов, выходная строка, которая будет нашим паролем, не содержит повторяющихся символов.
Здесь важно кое-что отметить: такой подход не всегда эффективен. Это связано с тем, что количество символов, присутствующих в строке 13, может быть недостаточным. В ином случае значения могут образовать идеальный цикл. Это происходит так, потому что фактически у нас есть цикл символов, объявленный в строке 13, где первый символ, являющийся закрывающей скобкой, соединяется с последним, который является числом девять. Это похоже на змею, кусающую свой собственный хвост.
Многие из тех, кто не является программистом не понимают это. Но такая ситуация всегда возникает в той или иной форме, когда мы работаем с программированием.
Хорошо, мы уже объяснили то, что собираемся делать, давайте теперь взглянем на код. Данный код приведен ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 0) + psw[c]) % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+s
Код 03
Такой подход очень интересен. Обратите внимание, что я практически не изменил код. Была изменена только строка 27, что очень похоже на то, что было сделано в третьем выражении цикла FOR, которое можно увидеть в строке 20. Но прежде чем говорить об этом, стоит посмотреть на результат, который можно проанализировать ниже.
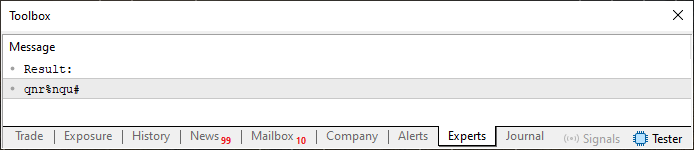
Рисунок 02
Прощу заметить, что теперь у нас больше нет повторений, как раньше. Однако всё можно сделать еще лучше, изменив всего одну вещь в коде 03. Теперь, как уже объяснялось в предыдущих статьях, этот тернарный оператор в строке 27 работает как оператор IF. По этой причине первое вычисляемое значение не исправляется. Однако все последующие значения будут исправляться в зависимости от значения, использованного в предыдущем индексе массива. Обратите внимание: значение массива, которое будет использоваться в данном исправлении, НЕ является значением, вычисленным в цикле в строке 20. Это то значение, которое получено из строки, определенной в строке 13. Поэтому, чтобы узнать точное значение, необходимо обратиться к таблице ASCII и добавить его к значению, вычисленному в цикле строки 20. Звучит немного запутанно, но всё очень просто, если остановиться и подумать.
Однако я хотел бы обратить ваше внимание на нулевое значение, используемое в тернарном операторе. Первый индекс остается неизменным именно благодаря данному значению. Что произойдет, если вместо него использовать другое значение? Предположим, что изменим строку 27, как показано ниже.
psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 5) + psw[c]) % StringLen(szCodePhrase)]);
Результат будет совсем другим, как можно видеть на следующем изображении.
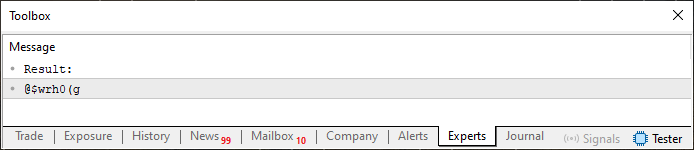
Рисунок 03
Это интересно. Таким образом, с помощью простого изменения мы смогли сгенерировать нечто, что многие сочтут надежным паролем. Для этого мы используем простые расчеты и два легко запоминающихся предложения. И, прошу заметить, мы добились всего этого, имея, как я считаю, базовый уровень знаний в области программирования. Неплохо для новичка. Итак, дорогие читатели, изучение и эксперименты с новыми возможностями могут оказаться очень интересными, ведь здесь показано нечто очень базовое, это то, что более опытный программист сделает за считанные минуты.
Отлично, это была самая простая часть демонстрации по использованию массивов. Но мы еще не закончили. Прежде чем мы сделаем дальнейшие шаги к чему-то более сложному, нам нужно поговорить о других деталях, связанных с массивами. Для этого мы обратимся к новой теме.
Типы данных и их связь с массивами
Одна из самых сложных, запутанных и трудных тем для освоения в программировании - именно сегодняшняя. Скорее всего, вы еще не совсем представляете, насколько сложным является этот вопрос. Некоторые люди считают себя хорошими программистами, но не имеют ни малейшего представления о том, как всё взаимосвязано. Поэтому они утверждают, что некоторые вещи невозможны или сложнее, чем они есть на самом деле.
Разобравшись с этим, вы начнете понимать ряд других вопросов, которые, казалось бы, не имеют ничего общего друг с другом, но по своей сути являются частью одного и того же.
Для начала давайте вспомним о памяти компьютера. Неважно, сколько бит в процессоре (8, 16, 32 или 64) или любое другое экзотическое значение, например 48 бит, это определенно не имеет значения. Также не имеет значения, работаем ли мы с двоичной, восьмеричной, шестнадцатеричной или любой другой системой счисления. Это тоже не играет существенную роль. На самом деле важно то, как настроены или построены структуры данных. Например, кто сказал, что в байте должно быть восемь бит, и почему именно восемь? Разве не может быть десять или двенадцать бит?
Возможно, сейчас вы не совсем понимаете меня. Дело в том, что на самом деле очень сложно сжать десятилетия опыта в нечто, что было бы понятно каждому, особенно если ориентироваться на начинающих программистов. Однако, если не усвоить определенные понятия заранее, разговор о некоторых вещах может оказаться довольно сложным. Но, учитывая то, что уже показали в предыдущих статьях, мы можем провести небольшой эксперимент. Для этого мы будем работать с массивом любого типа и переменной любого другого типа. Однако есть одно небольшое правило: тип данных, используемый в массиве, НЕ МОЖЕТ БЫТЬ ОДИНАКОВЫМ с переменной. Но даже в этом случае мы можем сделать так, чтобы они взаимодействовали друг с другом и имели одинаковую ценность, если следовать нескольким простым правилам.
Да, кажется сложным и требующим больше знаний по программированию, но так ли это на самом деле? Давайте проверим. Чтобы было еще интереснее, воспользуемся функцией, которую мы уже видели в предыдущей статье, где мы могли преобразовывать двоичные значения в другой тип представления.
Это хорошая идея. А чтобы сделать пример более обширным (поскольку мы будем часто использовать подобную реализацию для объяснения различных моментов), мы поместим данную функцию в заголовочный файл. В результате получается то, что показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Код 04
Теперь еще один важный момент: поскольку код 04 является заголовочным файлом, который будет присутствовать здесь, и я хочу, чтобы он был доступен только для обучающих скриптов, мы его поместим в папку внутри папки scripts. Как мы уже объясняли, это означает, что для всего, что создано здесь, мы не будем возвращаться к этому вопросу, чтобы двигаться дальше. Отлично. Теперь обратите внимание на следующее: все значения, которые мы будем преобразовывать, должны рассматриваться как беззнаковые, пока мы не исправим эту маленькую деталь в функции, которая появляется в коде 04.
Как только это будет сделано, мы сможем проверить, всё ли работает правильно. Для этого мы используем очень простой код:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation via standard library.\n" + 11. "Decimal: %I64u\n" + 12. "Octal : %I64o\n" + 13. "Hex : %I64X", 14. value, value, value 15. ); 16. PrintFormat("Translation personal.\n" + 17. "Decimal: %s\n" + 18. "Octal : %s\n" + 19. "Hex : %s\n" + 20. "Binary : %s", 21. ValueToString(value, 0), 22. ValueToString(value, 1), 23. ValueToString(value, 2), 24. ValueToString(value, 3) 25. ); 26. } 27. //+------------------------------------------------------------------+
Код 05
Когда этот код выполнится, результат будет таким, как показано на следующем изображении:
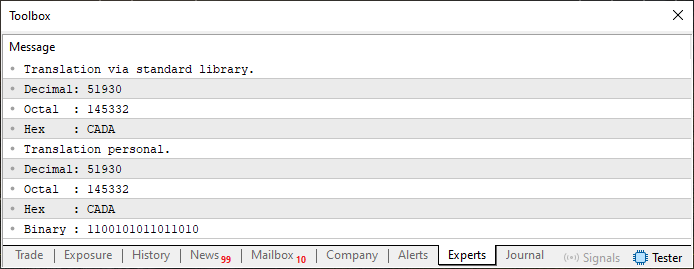
Рисунок 04
Очевидно, что это работает. Поэтому теперь мы можем начать экспериментировать с массивами и переменными разных типов. Это позволит вам начать понимать кое-что очень интересное, что происходит только в определенных языках программирования. Для этого мы начнем с изменения кода 05, который теперь станет тем, что я буду называть "ZERO FRAME". Это показано ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA}; 09. ushort value = 0; 10. 11. value = (array[0] << 8) | (array[1]); 12. 13. PrintFormat("Translation personal.\n" + 14. "Decimal: %s\n" + 15. "Octal : %s\n" + 16. "Hex : %s\n" + 17. "Binary : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2), 21. ValueToString(value, 3) 22. ); 23. } 24. //+------------------------------------------------------------------+
Код 06
А теперь я хочу попросить у вас кое-что. Нужно убрать все отвлекающие факторы, которые могут отвлечь вас. Я хочу, чтобы вы полностью сосредоточились на том, что мы будем рассматривать, начиная с этого момента. То, что я собираюсь объяснить сейчас, весьма сложно для многих начинающих программистов. Однако это не просто программисты, а именно те, кто использует определенные языки программирования, в том числе MQL5.
Сначала давайте посмотрим на результат выполнения кода 06. Это можно увидеть ниже.
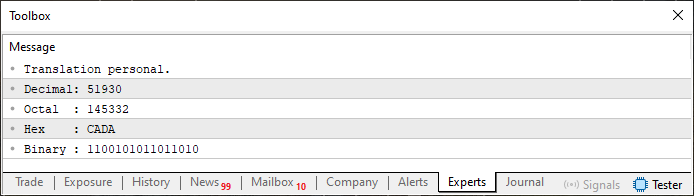
Рисунок 05
То, что показано здесь, в коде 06, является основой для множества концепций. Если можно понять это во время изучения данного кода, то без проблем можно будет понять и многие другие вещи, которые появятся позже. Это связано с тем, что многие из этих вещей в той или иной мере вытекают из того, что делает код 06.
С первого взгляда вы, возможно, не поймете, насколько сложным является этот простой код или то, что его можно сделать просто потому что код 06 возможно реализовать. Так что давайте не будем нервничать. Тем из вас, кто уже знает об этом, мы не объясним ничего нового. А для тех, кто не знает, может оказаться очень запутанным то, что будет рассказано здесь.
Возможно, я слишком поторопился. Давайте теперь вернемся немного назад и посмотрим на следующее: какая часть кода 06 вам непонятна, если основываться лишь на том, что было объяснено до настоящего момента? Вероятно, это строки 8 и 11. На самом деле, эти строки не имеют особого смысла для тех, кто только начинает свой путь. Хотя в предыдущих кодах этой же статьи мы видели нечто очень похожее, что можно видеть в коде 03 в строках 15, 20, 23 и 27.
Однако в коде 06 всё работает немного по-другому, хотя и не совсем по-другому. Возможно я допустил ошибку, использовав массивы до того, как объяснил должным образом их работу. Поэтому я хочу извиниться. Теперь вы можете быть немного озадачены, увидев, что при выполнении кода 06 всё происходит так, как показано на изображении 05.
Поэтому давайте начнем с самого простого и правильного способа: со строки 11 кода 06. То, что у нас получилось, эквивалентно тому, что можно увидеть в строке кода ниже.
value = (0xCA << 8) | (0xDA);
Это может показаться немного сложным, хотя мы уже объяснили, как работает оператор сдвига. Давайте снова обратимся к визуальной поддержке. Это значительно упростит понимание.
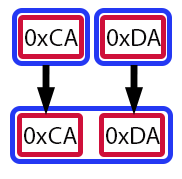
Рисунок 06
Каждый красный прямоугольник представляет собой байт, или значение типа uchar, в то время как каждый синий прямоугольник представляет собой переменную. Стрелки указывают на движения, совершаемые в процессе, то есть на этом изображении показано, как было создано значение переменной value в строке 11. У вас может появиться вопрос: несмотря на то, что value является типом ushort, мы можем поместить внутрь него значения типа uchar и таким образом создать новое значение? Именно так, мой дорогой читатель. Однако это еще не всё. Давайте продвигаться медленно, чтобы концепция была понятна.
Как вы, возможно, уже знаете, область памяти, которую мы создаем в строке 8, является константной областью, но это еще не всё. При инициализации значений в данной области памяти она напоминает картридж ROM, похожий на старые картриджи, используемые в видеоиграх.

Рисунок 07
Хотя это может показаться странным, эта строка 08 на самом деле создает ROM внутри RAM.
Но подождите минутку, какой размер памяти ROM, созданного в этой строке 08? Это зависит от ситуации, дорогой читатель. И я даю этот ответ не для того, чтобы поиздеваться над вами, я говорю это со всей искренностью. Однако в стандартной библиотеке есть функция, которая сообщает нам размер выделенного блока. Помните, что массив - это строка символов, но строка - это специальный массив, как объяснялось выше. В отличие от массивов, которые были показаны в предыдущих кодах, где мы создавали генератор паролей из простых фраз, массив, построенный в коде 06, на самом деле является чистым массивом. То есть это не строка, а массив, предназначенный для представления любых значений. Но, поскольку мы объявляем его как массив типа uchar, мы ограничиваем диапазон значений, которые мы можем в него поместить. Однако, здесь всё усложняется: мы можем использовать другой, более крупный тип, чтобы определить, какое значение присутствует в массиве.
Для этого мы должны использовать тип данных, который может содержать столько же битов, сколько и массивов. Именно это и пытается передать рисунок 06, поскольку синяя область представляет собой набор всех битов в массиве. Чтобы прояснить ситуацию, добавим немного больше информации в строку 08 и посмотрим, что получится. Но, чтобы не усложнять ситуацию, нам нужно изменить код, как показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+
Код 07
Да, я знаю. То, что делается в коде 07, кажется совершенно безумным. Но посмотрите на результат, который будет получен при выполнении этого кода. Можно увидеть его ниже.
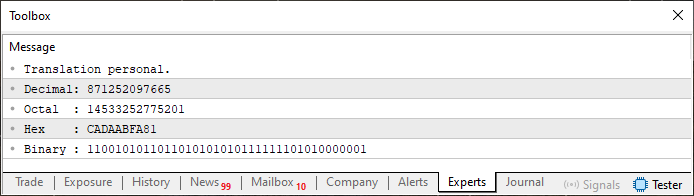
Рисунок 08
Вот это действительно безумие, но, как видите, это работает. То есть мы смешиваем в массиве двоичные, шестнадцатеричные и десятичные значения. В итоге нам удалось собрать небольшой блок памяти ROM, содержащий какую-то информацию. Но самое удивительное - это не то, что мы здесь видим, это лишь верхушка айсберга, за которым скрывается нечто гораздо большее.
Прежде чем копать глубже, давайте разберемся, что произошло и какие ограничения и меры предосторожности нужно соблюдать при работе с подобными элементами.
Вы, наверное, заметили, что в восьмой строке мы добавили только новые данные. Хорошо, но сколько данных мы можем туда поместить? Ответ: БЕСКОНЕЧНЫЕ ДАННЫЕ, или то количество, которое позволяет ваше оборудование. На практике объем информации, которую мы можем объединить, зависит от объема памяти вашего компьютера для обработки данных. Однако, в отличие от восьмой строки, это не относится к переменной value. В последнем случае у нас есть максимальный предел количества битов, которые можно хранить. Поскольку я хотел, чтобы мы испытали это более гибко, я установил максимальный предел, который в настоящее время можно обработать в MQL5, то есть 64 бита или восемь байт. Означает ли это, что мы можем поместить только восемь байт в переменную value? Нет, в действительности это означает, что после завершения 64 бит новая информация заменит старую. Это поведение создает модель потока данных, которую мы рассмотрим ниже.
Важно отметить, что у нас есть возможность поместить в одну переменную максимум 64 бита. Однако это не означает, что мы можем поместить восемь различных значений. И вот здесь всё становится сложнее для тех, кто начал непосредственно с этой статьи, не прочитав предыдущие и не практикуясь в том, что там изложено.
Прежде чем мы поговорим о цикле, который находится в строке 11, и о том, что происходит в строке 12, давайте внесем небольшое изменение в данный код 07. Это поможет прояснить понятие количества информации в массиве. Ниже показана деталь, которую необходимо изменить.
const ushort array[] = {0xCADA, B'1010101111111010', 0x81}; Как видно из приведенной выше строки, наш массив теперь состоит не из пяти, а из трех элементов. Важно отметить, что несмотря на такое изменение количества элементов, мы по-прежнему используем практически тот же объем памяти, но теперь у нас есть 8 бит, потраченных впустую в памяти. Это происходит потому, что, в отличие от кода 07, где каждый байт используется полностью, в новой структуре последнее значение массива использует только 8 из 16 доступных бит. Это может показаться "приемлемым" расточительством, но об этом мы поговорим в другой раз. Сейчас я просто хочу, чтобы вы поняли, что тип используемых данных влияет на расход памяти, а также на производительность нашего кода.
Однако всё станет еще хуже, если вы используете что-то вроде следующей строки.
const int array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; Я знаю, что многие люди не беспокоятся об использовании неподходящего типа в некоторых переменных. Хотя кажется, что проблемы нет (и в данном конкретном случае ее нет), используя эту строку в коде 07, мы тратим не только 8 бит памяти, но и 16 бит на каждый элемент массива. При 5 элементах перерасход составит 80 бит или 10 байт, что больше, чем длина пароля, который мы использовали в начале статьи.
Данный объем нерационально расходуемой памяти может показаться незначительным, учитывая, что сегодня у нас есть компьютеры с более чем 32 гигабайтами памяти. И хотя в этом случае может произойти сбой, в нашем случае это не повлияет на поведение кода, как мы увидим в строках 11 и 12, так что давайте посмотрим, что там произойдет.
Здесь мы сообщаем коду, что для каждого элемента, присутствующего в массиве, мы хотим, чтобы значение переменной value сдвинулось на 8 бит влево, тем самым освобождая место для нового элемента. То же самое происходит в строке 12, но данная строка ориентирована на использование конкретного элемента массива, на который указывает переменная c. А как узнать, сколько элементов находится в массиве? В строке 11 второе выражение, управляющее завершением цикла, дает нам эту информацию. Здесь мы обращаемся к стандартной библиотеке MQL5.
Этот вызов, расположенный в строке 11, эквивалентен использованию функции ArraySize. То есть, таким образом мы можем узнать, сколько элементов в массиве, независимо от того, сколько битов на самом деле использует каждый элемент.
Чтобы поэкспериментировать с данной концепцией, просто изменим код, чтобы он выглядел так, как показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. Print("Number of elements in the array: ", ArraySize(array)); 25. } 26. //+------------------------------------------------------------------+
Код 08
Благодаря этому при запуске кода 08 мы сможем увидеть количество элементов, присутствующих в массиве, как показано на рисунке ниже в выделенной области.
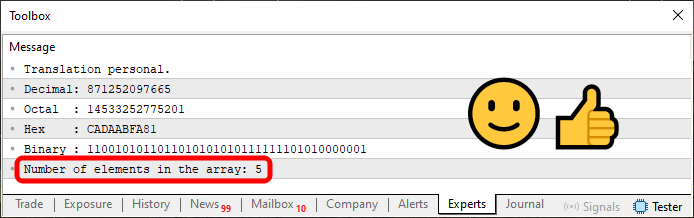
Рисунок 09
Заключительные идеи
Что ж, эта статья уже содержит много материала для изучения и усвоения. Поэтому я дам вам немного времени, чтобы изучить и применить на практике то, что здесь показано. Попробуйте понять эти первые понятия, связанные с использованием массивов. Хотя в данной статье используются массивы ROM, которые не позволяют изменять их содержимое, очень важно, чтобы вы постарались понять как можно больше из того, что здесь объясняется. Я знаю, что материал трудно усвоить сразу, но приложите все усилия, чтобы понять то, что показывается в этих статьях, особенно в данной статье.
Понимание материала, изложенного в других статьях, значительно поможет вам стать хорошим программистом. По мере того как материал будет становиться всё более сложным, будут возрастать и проблемы. Не отчаивайтесь из-за трудностей. Практикуйтесь и используйте приложения, чтобы понять моменты, которые не объясняются здесь полностью, но упоминаются в статье, например, указанные модификации, результаты которых не показали. Важно понимать, как данные изменения влияют на память. Так что смело изучайте файлы из приложения.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15462
 MQL5-советник, интегрированный в Telegram (Часть 4): Модуляризация функций кода для улучшенного повторного использования
MQL5-советник, интегрированный в Telegram (Часть 4): Модуляризация функций кода для улучшенного повторного использования
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования