Índice Hearst - página 20
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Há também a opção de dividir permanentemente o segmento ao meio.
Hm, e os pontos para os quais a diferença Close[i+1]-Close[i] = 0 e o desvio padrão 0, simplesmente não são considerados na construção de uma linha reta?
Há também uma opinião de que se deve usar o chamado RANSAC( http://en.wikipedia.org/wiki/RANSAC ) em vez do habitual ISC para calcular o coeficiente de Hurst porque os pontos "fora do número total", ou seja, os mais distantes da massa total, podem influenciar o coeficiente de inclinação da linha reta com o habitual ISC.
понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи.
Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей.
Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе.
Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(Close[i+1]-Close[i]) = 0 => log(d[i]/d[i-1]) = INF - Não entendo o que fazer com isto. RS = R/S - e como calcular quando S = 0, assumir que R = 0 também? então novamente log(R) = INF e novamente não entendo o que fazer. Ok. Aqui está um exemplo simples - qual é o coeficiente H
e se (Close[i+1]-Close[i]) = constante para todos i em um dado intervalo?
Não tenho idéia com base em qual modelo, pode-se decidir que alguns retornos devem ser descartados da amostra? -Se, por exemplo, houve um erro em vários valores no fluxo de dados do estoque (54,5 em vez de 14,4)
função RS toma como entrada uma matriz de Close[i]-Close[i-1] e o número de elementos da matriz
1. S[i-1] = Fechar[i]-Fechar[i-1] Para todos i de 0 a N
2. h[i] = log(S[i]/S[i-1])
3. hn = Soma de h[i] h_cp = arith. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Então eu estou m-n pontos com valor de log RS(i) e log i para i de n_min para alguns N e MNCs estão em linha reta
В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива
1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N
2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений.
3. Hn = Сумма h[i] h_cp = ср.ариф. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
Como entendo, não faz sentido calcular o coeficiente para 78 valores - ou seja, para uma barra de um dia? Eu também ainda não entendo o que fazer se alguns valores forem iguais a zero. Por exemplo, se eu inserir diferença de preço, é claro que a diferença em 5 minutos pode ser menor ou igual a 0, mas depois não é feito o log. Tenho uma idéia para tomar o módulo do valor caso seja negativo (ou seja, diferença absoluta) e no caso de 0, não insira este valor na série h.
O arquivo de teste em si. H~0.72
Seu indicador zHursttExponent.mq4 dá 0,1647 em seu arquivo de teste brown72.txt. Do que se trata?
Pelo que entendi, este indicador calcula o valor Hurst para cada tick para as últimas 2520 barras e imprime-o para fora. É assim?
O que significam então 4 caixas deste indicador e para que elas são necessárias em uma janela separada?
E mais uma pergunta.
for(int i=0; i<limit; i++)
{
}
//---- done
Qual é o significado desta peça no código do indicador?
Ваш индикатор zHursttExponent.mq4 на вашем же тестовом файле brown72.txt выдает 0.1647. К чему бы это ?
Насколько я понял, этот индикатор считает показатель Херста на каждом тике для последних 2520 баров и выдает значение на печать. Так ?
А что тогда означают 4 буфера этого индикатора и зачем они нужны в отдельном окне ?
И еще один вопрос.
for(int i=0; i<limit; i++)
{
}
//---- done
Какой смысл имеет этот кусок в коде индикатора ?
1. Não é possível repetir seu resultado = 0,1647. O meu é assim (=0,7241):
2) Sim, este indicador considera o índice Hurst em cada tick para as últimas 2520 barras e imprime o valor e desenha pontos r/s (linha branca), sobre os quais a linha reta de aproximação (linha vermelha) é desenhada, cuja inclinação é o índice procurado - para clareza, mas para mim - para uma estimativa visual qualitativa da correção do algoritmo. Tudo isso é verdade quando cRSGraphic = true, caso contrário o indicador considera o índice Hurst para as últimas 250 barras.
3. 4 buffers é uma aparente redundância, uma relíquia que sobrou da época da depuração e dos testes.
4. Loop vazio - o mesmo problema que no item 3.
Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин.
Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
Aqui está uma variante na qual o erro é contado. Infelizmente, não consigo encontrar onde roubei a fonte C desta maravilha, mas ela afirma contar por Feder E. Fractals. Para ele Teste H=0,6807 para o mesmo arquivo. Parece que não é ruim.
Para 78 valores, é o mais difícil. Muito trabalho é dedicado a como estimar Hurst em meia centena de observações. Mesmo sem entender os cálculos, você obtém resultados muito diferentes de um autor para outro. Não há nada de surpreendente nisso. Tantos algoritmos quanto os indicadores :). Ah, e outro problema - na versão anexa sobre 1000 observações com erro levado em conta que não podemos dizer nada sobre o preço - é consistente ou não no momento, porque 0,5 fica apenas entre os canais de erro (linhas vermelhas no cRSGraphic=falso).
O insumo deve ser ou a diferença de preço ou o logaritmo da relação de preço.
1. Não é possível repetir seu resultado = 0,1647. O meu é assim (=0,7241):
Você anexou o arquivo brown72.txt. No entanto, seus testes de indicador no arquivo brown72.csv. Por falta de outras instruções, acabei de renomeá-lo e colocá-lo na pasta de arquivos dos especialistas. Aqui está o resultado:
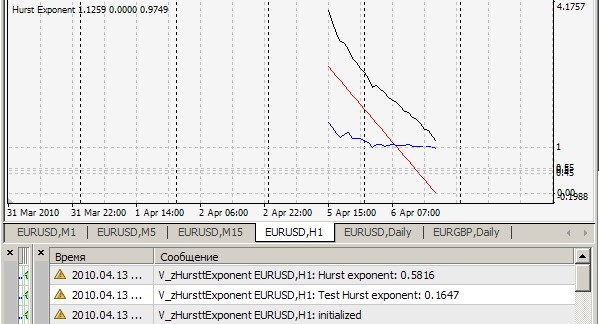
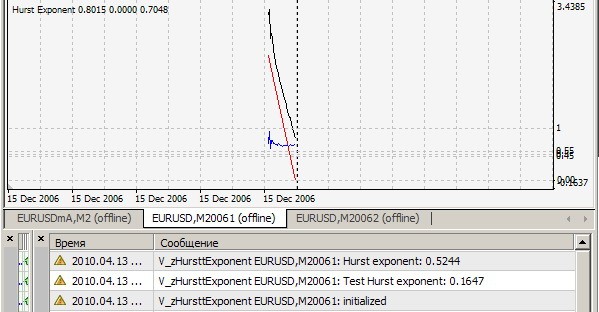
Em H1:
Em carrapatos:
Seu arquivo contém 1024 valores. Aqui estão os primeiros 4 deles:
45.47422
42.55601
46.5188
41.61502