O "New Neural" é um projecto de motor de rede neural Open Source para a plataforma MetaTrader 5. - página 56
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Sim, era exactamente isso que eu queria saber.
Para mql5
SZ A principal preocupação no momento é se os dados precisarão ser copiados para matrizes de CPU especiais ou se a passagem de um array como um parâmetro em uma função normal será suportada. Esta questão pode alterar fundamentalmente todo o projecto.
ZZY você pode responder em seus planos de apenas dar OpenCL API, ou você está planejando embrulhá-lo em seus próprios invólucros?
2) Haverá um wrapper, apenas GPUs HW serão suportados (com suporte a OpenCL 1.1).
Seleções múltiplas de GPU, se houver, só serão possíveis através das configurações do terminal.
O OpenCL será usado de forma síncrona.
Sim, era exactamente isso que eu queria saber.
Para mql5
SZ A principal preocupação no momento é se os dados precisarão ser copiados para matrizes de CPU especiais ou se a passagem de um array como um parâmetro em uma função normal será suportada. Esta questão pode alterar fundamentalmente todo o projecto.
ZZZY pode responder em planos para apenas dar OpenCL API ou está a planear embrulhá-lo nos seus próprios invólucros?
A julgar por:
mql5:
Você será de fato capaz de usar as funções da biblioteca OpenCL.dll diretamente sem ter que conectar DLLs de terceiros.
As funções OpenCL.dll estarão disponíveis como se fossem funções MQL5 nativas enquanto o compilador irá redirecionar as chamadas em si.
A partir daí, pode-se concluir que as funções da OpenCL.dll já podem ser estabelecidas agora (chamadas fictícias).
Renat e mql5, será que eu entendi o "ambiente" corretamente?
A julgar por:
As funções OpenCL.dll podem ser usadas como se fossem funções MQL5 nativas e o próprio compilador irá redirecionar as chamadas.
A partir daí, pode-se concluir que as funções da OpenCL.dll já podem ser estabelecidas agora (chamadas fictícias).
Renat e mql5, eu tenho a "situação" certa?
Até agora, este é o esquema do projecto:
Os objectos são rectângulos, os métodos são elipses.Os métodos de processamento estão divididos em 4 categorias:
Esses quatro métodos descrevem todo o processamento em todas as camadas, os métodos são importados para o processamento através de objetos do método, que são herdados da classe base e sobrecarregados conforme necessário, dependendo do tipo de neurônio.
Nikolai, tu sabes a frase - a optimização prematura é a raiz de todo o mal.
Esquece o OpenCL por agora. Terás de fazer algo decente sem ele. Você sempre terá tempo para transpô-lo, especialmente se ainda não estiver disponível.
Nikolay, você conhece uma frase tão popular - a otimização prematura é a raiz de todos os males.
Esqueça o OpenCL por enquanto; você poderia ter escrito algo decente sem ele. Podes sempre trocá-lo. Além disso, ainda não há nenhum recurso interno.
Sim, é uma frase popular e quase concordei com ela da última vez, mas depois de analisá-la percebi que não podia apenas planejá-la e depois reprojetá-la para a GPU, ela tem necessidades muito específicas.
Se planejamos sem GPU, então seria lógico fazer um objeto Neuron, que seria responsável tanto pelas operações dentro de um neurônio, quanto pela alocação de dados de cálculo em células de memória necessárias, herdando uma classe de um ancestral comum poderíamos facilmente conectar o tipo de neurônio necessário e assim por diante,
Mas tendo trabalhado um pouco com o meu cérebro, compreendi imediatamente que esta abordagem irá destruir completamente os cálculos da GPU, a criança por nascer está condenada a engatinhar.
Mas suspeito que o meu post acima o deixou confuso. Por "método de computação paralela" quero dizer operação bastante específica de multiplicação de entradas com pesos em*wg, por método de computação sucessiva quero dizer soma+=a[i] e assim por diante.
Apenas para uma melhor compatibilidade futura com GPU, proponho derivar operações de neurônios e combiná-las em um único movimento em um objeto de camada, e os neurônios só forneceriam informações de onde levar para onde colocar.
Palestra 1 aqui https://www.mql5.com/ru/forum/4956/page23
Palestra 2 aqui https://www.mql5.com/ru/forum/4956/page34
Palestra 3 aqui https://www.mql5.com/ru/forum/4956/page36
Palestra 4 aqui https://www.mql5.com/ru/forum/4956/page46
Palestra 5 (última). Codificação Esparsa
Este tópico é o mais interessante. Vou escrever esta palestra gradualmente. Então, não se esqueça de verificar este posto de vez em quando.
Em geral nossa tarefa é apresentar a cotação de preços (vetor x) nas últimas N barras como uma decomposição linear em funções de base (série de matriz A):
onde s são os coeficientes da nossa transformação linear que queremos encontrar e usar como inputs para a próxima camada da rede neural (por exemplo, SVM). Na maioria dos casos, conhecemos as funções básicas A , ou seja, escolhemo-las com antecedência. Podem ser sinos e cossenos de diferentes frequências (obtemos a transformação de Fourier), funções Gabor, Hammotons, wavelets, curlets, polinómios ou qualquer outra função. Se estas funções nos são conhecidas de antemão, então a codificação esparsa reduz-se a encontrar um vector de coeficientes s de tal forma, que a maioria destes coeficientes são zero (vector esparso). A idéia é que a maioria dos sinais de informação tem uma estrutura que é descrita por um número menor de funções de base do que o número de amostras de sinais. Estas funções básicas incluídas na descrição esparsa do sinal são as suas características necessárias que podem ser utilizadas para a classificação do sinal.
O problema de encontrar a transformação linear descarregada da informação original chama-se Sensoriamento Comprimido (http://ru.wikipedia.org/wiki/Compressive_sensing). Em geral, o problema é formulado da seguinte forma:
minimizar norma L0 de s, sujeito a As = x
onde a norma L0 é igual ao número de valores não nulos do vector s. O método mais comum para resolver este problema é a substituição da norma L0 pela norma L1, que constitui a base do método de busca da base(https://en.wikipedia.org/wiki/Basis_pursuit):
minimizar norma L1 de s, sujeito a As = x
onde a norma L1 é calculada como |s_1|+|s_2|+...+|s_L|. Este problema reduz-se à optimização linear
Outro método popular para encontrar o vector s esparso é a busca de correspondência(https://en.wikipedia.org/wiki/Matching_pursuit). A essência deste método é encontrar a primeira função base a_i de uma dada matriz A, de modo que ela se encaixe no vector de entrada x com o maior coeficiente s_i em comparação com outras funções base.Depois de subtrair a_i*s_i do vector de entrada, adicionamos a função de base seguinte ao resíduo resultante, e assim por diante, até alcançarmos o erro dado. Um exemplo do método de busca de correspondência é o seguinte indicador, que inscreve um seno após o outro no vetor de entrada com o menor resíduo: https://www.mql5.com/ru/code/130.
Se as funções básicasA(dicionário) não são conhecidas por nós de antemão, precisamos encontrá-las a partir dos dados de entradax usando métodos chamados colectivamente de aprendizagem de dicionário. Esta é a parte mais difícil (e para mim a mais interessante) do método de codificação esparsa. Na minha palestra anterior mostrei como essas funções podem, por exemplo, ser encontradas pela regra de Ogi, o que faz dessas funções os principais vetores das citações de entrada. Infelizmente, este tipo de funções de base não leva a uma descrição desarticulada dos dados de entrada (ou seja, o vector s é não espesso).
Os métodos existentes de aprendizagem de dicionário que levam à desarticulação das transformações lineares dividem-se em
Osmétodos probabilísticos de encontrar funções de base são reduzidos para maximizar a máxima probabilidade:
maximizar P(x|A) sobre A.
Normalmente assume-se que o erro de aproximação tenha uma distribuição gaussiana, o que nos leva a resolver o seguinte problema de optimização:
(1)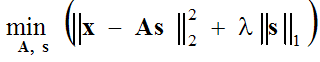 ,
,
que é resolvido em dois passos: (passo de codificação 1-espaço) com funções de base A fixa, a expressão entre parênteses é minimizada com respeito aos vetores s, e (passo de atualização de 2 dicionários) o vetors encontrado é fixo e a expressão entre parênteses é minimizada com respeito às funções de base A usando o método de descida de gradiente:
(2)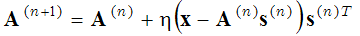
onde (n+1) e (n) no sobrescrito denotam números de iteração. Estas duas etapas (etapa de codificação e etapa de aprendizagem do dicionário) são repetidas até que um mínimo local seja alcançado. Este método probabilístico de encontrar funções de base é utilizado, por exemplo, em
Olshausen, B. A., & Field, D. J. (1996). Emergência de propriedades de campo receptivas a células simples através da aprendizagem de um código esparso para imagens naturais. Natureza, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999). Aprender representações demasiado completas. Neural Comput., 12(2), 337-365.
O Método de Direções Ótimas (MOD) utiliza as mesmas duas etapas de otimização (etapa de codificação e etapa de aprendizagem do dicionário), mas na segunda etapa de otimização (etapa de atualização do dicionário) as funções básicas são calculadas equalizando a derivada da expressão entre parênteses (1) em relação a A a zero:
onde nós chegamos
(3)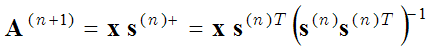 ,
,
onde o s+ é uma matriz pseudo-inversa. Este é um cálculo mais preciso da matriz de base do que o método de descida por gradiente (2). O método MOD é descrito com mais detalhes aqui:
K. Engan, S. O. Aase, e J.H. Hakon-Husoy. Método de direcções óptimas para a concepção de estruturas. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 5, pp. 2443-2446, 1999.
Calcular matrizes pseudo-inversas é incómodo. O método k-SVD evita fazê-lo. Ainda não o descobri. Podes ler sobre isso aqui:
M. Aharon, M. Elad, A. Bruckstein. K-SVD: Um Algoritmo para Desenho de Dicionários Super Completos para Representação Escassa. IEEE Trans. Signal Processing, 54(11), Novembro de 2006.
Eu também ainda não descobri os métodos de agrupamento e on-line para encontrar o dicionário. Os leitores interessados podem consultar a próxima pesquisa:
R. Rubinstein, A. M. Bruckstein, e M. Elad, "Dictionaries for sparse representation modeling", Proc. of IEEE , 98(6), pp. 1045-1057, junho de 2010.
Aqui estão algumas palestras interessantes em vídeo sobre este tema:
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
É tudo por agora. Irei expandir este tópico em futuras mensagens, conforme for possível e conforme os visitantes deste fórum estiverem interessados.
Nikolai, você conhece a frase popular - otimização prematura é a raiz de todos os males.
É uma frase tão comum para os desenvolvedores encobrirem sua inutilidade, que você pode ser esbofeteado no pulso por cada vez que você a usa.
A frase é fundamentalmente prejudicial e absolutamente errada, se estamos a falar de desenvolvimento de software de qualidade com longo ciclo de vida e orientação directa em alta velocidade e cargas elevadas.
Já verifiquei isso muitas vezes nos meus muitos anos de prática de gerenciamento de projetos.
É uma frase tão comum para encobrir as fodas dos desenvolvedores que você pode receber um tapa no pulso por cada vez que a usar.
Então você tem que levar em conta algumas características que vão aparecer quem sabe quando com quem sabe com que interface de antemão, porque isso lhe dá um aumento de desempenho?
Já testei isto muitas vezes nos meus anos de prática de gestão de projectos.