Aprendizado de máquina no trading: teoria, prática, negociação e não só - página 3009
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Mas o mais importante é que deve haver uma prova teórica de que o poder preditivo dos recursos disponíveis não muda, ou muda pouco, no futuro. Em todo o rolo compressor, esse é o aspecto mais importante.
Infelizmente, ninguém descobriu isso, caso contrário, ele não estaria aqui, mas em ilhas tropicais))))
Sim. Até mesmo uma árvore ou regressão pode encontrar um padrão se ele estiver lá e não mudar.
1. Alguém mais tem um par professor-traço com menos de 20% de erro de classificação?
É fácil. Posso gerar dezenas de conjuntos de dados. Só agora estou investigando TP=50 e SL=500. Há uma média de 10% de erro na marcação do professor. Se for de 20%, será um modelo de ameixa.
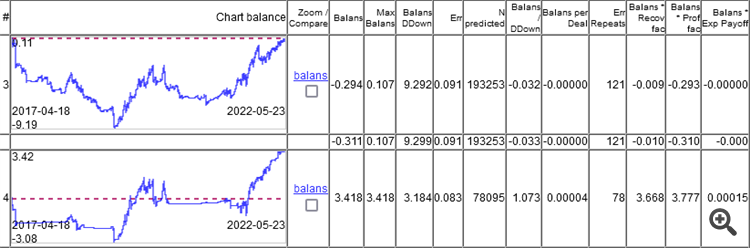
Portanto, o ponto não está no erro de classificação, mas no resultado da soma de todos os lucros e perdas.
Como você pode ver, o modelo superior tem um erro de 9,1%, e você pode ganhar algo com um erro de 8,3%.
Os gráficos mostram apenas o OOS, obtido pelo Walking Forward com retreinamento uma vez por semana, um total de 264 retreinamentos em 5 anos.
É interessante que o modelo funcionou em 0 com um erro de classificação de 9,1% e 50/500 = 0,1, ou seja, deveria ser 10%. Acontece que 1% comeu o spread (mínimo por barra, o real será maior).
Primeiro, você precisa perceber que o modelo está cheio de lixo em seu interior...
Se você decompor um modelo de madeira treinado nas regras internas e nas estatísticas sobre essas regras.
como :
e analisar a dependência do erro da regra err com relação à frequência de sua ocorrência na amostra.
teremos
Então, estamos interessados nessa área
Onde as regras funcionam muito bem, mas são tão raras que faz sentido duvidar da autenticidade das estatísticas sobre elas, porque 10-30 observações não são estatísticas
Primeiro, você precisa perceber que o modelo está cheio de lixo por dentro...
Se você decompor um modelo de madeira treinado nas regras internas e nas estatísticas sobre essas regras.
como:
e analisar a dependência do erro da regra err em relação à frequência freq de sua ocorrência na amostra
obtemos
Apenas um raio de sol na escuridão das postagens recentes
Haverá um artigo sobre isso, se houver.
haverá um artigo sobre isso, se houver.
Norm, meu último artigo foi sobre a mesma coisa. Mas se sua maneira for mais rápida, isso é uma vantagem.
O que você quer dizer com mais rápido?
O que você quer dizer com mais rápido?
Em termos de velocidade.
cerca de 5 a 15 segundos em uma amostra de 5 km
cerca de 5 a 15 segundos em uma amostra de 5k.
Refiro-me a todo o processo, desde o início até a obtenção do TC.
Tenho dois modelos sendo retreinados várias vezes, portanto, não é muito rápido, mas é aceitável.
E, no final, não sei exatamente o que foi selecionado.
Quero dizer, todo o processo, desde o início até a obtenção do TC.
Tenho dois modelos sendo retreinados várias vezes, portanto, não é muito rápido, mas é aceitável
e, no final, não sei exatamente o que eles selecionaram.
Treinar 5 mil.
Validar 60 mil.
Treinamento do modelo - 1-3 segundos
extração de regras - 5 a 10 segundos
verificação da validade de cada regra (20-30k regras) 60k - 1-2 minutos
é claro que tudo é aproximado e depende do número de recursos e dados