예, SanSanych가 쓴 것처럼 고전적인 접근 방식은 데이터 분석, 데이터 요구 사항 및 시스템 오류에 대한 기억입니다.
하지만 이 스레드는 Bayes에 관한 것이며 저는 베이지안을 생각하려고 합니다. 마치 참호의 병사가 사후(경험 후) 확률을 계산하는 것과 같습니다. 위에서 군인에 대한 예를 들었습니다.
주요 질문 중 하나는 선험적 확률을 위해 무엇을 취해야 하는지입니다. 즉, 누가 미래의 장막 뒤에 놓을 것인가, 제로 바의 오른쪽에. 가우스? 라플라스? 위너? 전문 수학자들은 여기에 무엇을 씁니다(저를 위한 어두운 "숲")?
저는 가우스를 선택했습니다. 첫째로 정규 분포에 대한 아이디어가 있고 두 번째로 정규 분포를 믿기 때문입니다. "슛"하지 않으면 다른 법칙을 사용하여 가우스 대신 베이즈 공식으로 대체하거나 가우스와 함께 두 확률의 곱으로 대체할 수 있습니다. 내가 올바르게 이해한다면 베이지안 네트워크를 만들어보십시오.
물론 나 혼자 할 수는 없다. 나는 꽃다발 아래에서 공식화한 작업에서 가우스에 대처할 것입니다. 자발적으로 참여하고 싶은 사람이 있다면 환영합니다. 다음은 현재 문제의 예입니다.
주어진: 일반 MT4 난수 생성기.
필수: 정규 RNG로 구성된 MT4[] 배열을 정규 분포의 ND[] 배열로 변환하기 위해 MQL4 코드를 FP() 함수 형식으로 작성합니다.
예, SanSanych가 쓴 것처럼 고전적인 접근 방식은 데이터 분석, 데이터 요구 사항 및 시스템 오류에 대한 기억입니다.
하지만 이 스레드는 Bayes에 관한 것이며 저는 베이지안을 생각하려고 합니다. 마치 참호의 병사가 사후(경험 후) 확률을 계산하는 것과 같습니다. 위에서 군인에 대한 예를 들었습니다.
주요 질문 중 하나는 선험적 확률을 위해 무엇을 취해야 하는지입니다. 즉, 누가 미래의 장막 뒤에 놓을 것인가, 제로 바의 오른쪽에. 가우스? 라플라스? 위너? 전문 수학자들은 여기에 무엇을 씁니다(저를 위한 어두운 "숲")?
저는 가우스를 선택했습니다. 첫째로 정규 분포에 대한 아이디어가 있고 두 번째로 정규 분포를 믿기 때문입니다. "슛"하지 않으면 다른 법칙을 사용하여 가우스 대신 베이즈 공식으로 대체하거나 가우스와 함께 두 확률의 곱으로 대체할 수 있습니다. 내가 올바르게 이해한다면 베이지안 네트워크를 만들어보십시오.
물론 나 혼자 할 수는 없다. 나는 꽃다발 아래에서 공식화한 작업에서 가우스에 대처할 것입니다. 자발적으로 참여하고 싶은 사람이 있다면 환영합니다. 다음은 현재 문제의 예입니다.
주어진: 일반 MT4 난수 생성기.
필수: 정규 RNG로 구성된 MT4[] 배열을 정규 분포의 ND[] 배열로 변환하기 위해 MQL4 코드를 FP() 함수 형식으로 작성합니다.
Оценка статистических параметров последовательности очень важна, так как большинство математических моделей и методов строятся исходя из различного рода предположений, например, о нормальности закона распределения, или требуют знания значения дисперсии или других параметров. В статье кратко рассматриваются простейшие статистические параметры случайной последовательности и некоторые методы ее визуального анализа. Предлагается реализация этих методов на MQL5 и способ визуализации результатов расчета при помощи программы Gnuplot.
# load data
fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv'
, sep= ','
, header = T
, na.strings = 'NULL')
fx_dat <- subset(fx_data, Volume > 0)
# create open price returns
dat_return <- diff(x = fx_dat[, 2], lag = 1)
# check summary for the returns
summary(dat_return)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
# generate random normal numbers with parameters of original data
norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return))
#check summary for generated data
summary(norm_generated)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03
# test normality of original data
shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)])
Shapiro-Wilk normality test
data: dat_return[sample(length(dat_return), 4999, replace = F)]
W = 0.86826, p-value < 2.2e-16
# test normality of generated normal data
shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)])
Shapiro-Wilk normality test
data: norm_generated[sample(length(norm_generated), 4999, replace = F)]
W = 0.99967, p-value = 0.6189
내가 사분면에서 이해하는 한, 모든 시간당 증가분의 50%는 7핍 미만입니다! 그리고 더 적절한 증분은 뚱뚱한 꼬리에 있습니다. 선과 악의 반대편에.
그리고 TS는 어떤 모습일까요? 그게 Bayes 등이 아니라 전체 문제입니다...
아니면 다른 방식으로 이해해야 합니까?
SanSanych, 네!
####### quantiles
hour1_quantiles <- data.frame()
counter <- 1for (i in seq( from = 0.05 , to = 0.95 , by = 0.05 )){
hour1_quantiles[counter, 1 ] <- i
hour1_quantiles[counter, 2 ] <- quantile(dat_return, probs = i)
counter <- counter + 1
}
colnames(hour1_quantiles) <- c(
'probability'
, 'value'
)
plot(hour1_quantiles$ value , type = 's' )
#View
hour1_quantiles
probability value10.05 - 0.002537520.10 - 0.001660030.15 - 0.001210040.20 - 0.000900050.25 - 0.000680060.30 - 0.000505070.35 - 0.000360080.40 - 0.000230090.45 - 0.0001100100.500.0000000110.550.0001100120.600.0002400130.650.0003700140.700.0005100150.750.0006900160.800.0009100170.850.0012100180.900.0016600190.950.0025300
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')
## what is absolute statistics of hourly returns?
summary(abs(dat_return))
Min. 1 st Qu. Median Mean 3 rd Qu. Max.
0.0000000.0003000.0006900.0010970.0014200.068490
그래서 천천히 변형이라는 매혹적인 주제에 접근했습니다.))) 정규 분포가 없으면 만들 수 있기 때문입니다. 변형과 ... 둘 다 필요하기 때문에 아프기까지 오랜 시간이 걸리겠지만 나는 Box-Cox를 별로 좋아하지 않습니다)))) 그렇지 않으면 유감입니다 정상적인 예측 변수, 이것은 최종 결과에 거의 영향을 미치지 않을 것입니다 ...
그리고 내 영혼은 여전히 따옴표의 정규 분포 증분에 대한 주제를 파고 싶어합니다.
누군가가 "~을 위해"라고 말하면 이 과정이 정상적이지 못한 이유를 설명하겠습니다. 또한, 이는 CLT와 함께 조정될 모든 사람이 이해할 수 있는 주장이 될 것입니다. 그리고 이러한 주장은 너무 진부하여 의심의 여지가 없습니다.
그리고 확률은 가장 가까운 막대에 대한 예측 또는 가장 가까운 막대의 이동 벡터를 무엇으로 나타낼까요?
확률은 다음 틱(증가)의 예측을 나타냅니다. 나는 단지 원한다:
- Bayes 공식에 의한 확률이 최대가 되는 미래 틱 Ybayes의 값을 계산합니다.
- Ybayes를 실제 들어오는 Yreal 틱과 비교합니다. 통계를 수집하고 처리합니다.
값의 차이가 이유 안에 있다면 코드를 게시하고 다음에 무엇을해야하는지 물어볼 것입니다. 회귀? 벡터? 크리불카? 스캘핑?
확률은 다음 틱(증가)의 예측을 나타냅니다. 나는 단지 원한다:
그리고 왜 진드기까지 내려갈까요? 5분 안에 70%의 정확도로 진드기의 방향을 예측하는 방법을 배울 수 있지만 100초 앞서면 정확도가 떨어집니다.
30분 또는 1시간 전에 증분을 시도하십시오. 이것은 나에게 흥미 롭습니다. 아마도 내가 뭔가를 도울 수 있습니다.
확률은 다음 틱(증가)의 예측을 나타냅니다. 나는 단지 원한다:
- Bayes 공식에 따른 확률이 최대가 되는 미래 Ybayes 틱 값을 계산합니다.
- Ybayes를 실제 들어오는 Yreal 틱과 비교합니다. 통계를 수집하고 처리합니다.
값의 차이가 이유 안에 있다면 코드를 게시하고 다음에 무엇을해야하는지 물어볼 것입니다. 회귀? 벡터? 크리불카? 스캘핑?
ARIMA에 무슨 문제가 있습니까? 배치에서 파생 수(증분 증분)는 입력 스트림에 따라 자동으로 계산됩니다. 고정성과 관련된 많은 미묘함이 패키지 내부에 숨겨져 있습니다.
정말로 더 깊이 들어가고 싶다면 ARCH?
일단 시도했습니다. 문제는 다음입니다. 증분을 쉽게 계산할 수 있습니다. 그러나 이 증분 의 신뢰 구간 을 증분 자체에 추가하면 이전 가격 값이 신뢰 구간 내에 있으므로 BUY 또는 SELL 중 하나입니다.
예, SanSanych가 쓴 것처럼 고전적인 접근 방식은 데이터 분석, 데이터 요구 사항 및 시스템 오류에 대한 기억입니다.
하지만 이 스레드는 Bayes에 관한 것이며 저는 베이지안을 생각하려고 합니다. 마치 참호의 병사가 사후(경험 후) 확률을 계산하는 것과 같습니다. 위에서 군인에 대한 예를 들었습니다.
주요 질문 중 하나는 선험적 확률을 위해 무엇을 취해야 하는지입니다. 즉, 누가 미래의 장막 뒤에 놓을 것인가, 제로 바의 오른쪽에. 가우스? 라플라스? 위너? 전문 수학자들은 여기에 무엇을 씁니다(저를 위한 어두운 "숲")?
저는 가우스를 선택했습니다. 첫째로 정규 분포에 대한 아이디어가 있고 두 번째로 정규 분포를 믿기 때문입니다. "슛"하지 않으면 다른 법칙을 사용하여 가우스 대신 베이즈 공식으로 대체하거나 가우스와 함께 두 확률의 곱으로 대체할 수 있습니다. 내가 올바르게 이해한다면 베이지안 네트워크를 만들어보십시오.
물론 나 혼자 할 수는 없다. 나는 꽃다발 아래에서 공식화한 작업에서 가우스에 대처할 것입니다. 자발적으로 참여하고 싶은 사람이 있다면 환영합니다. 다음은 현재 문제의 예입니다.
주어진: 일반 MT4 난수 생성기.
필수: 정규 RNG로 구성된 MT4[] 배열을 정규 분포의 ND[] 배열로 변환하기 위해 MQL4 코드를 FP() 함수 형식으로 작성합니다.
변환 공식은 https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/ Vasily (나는 애칭을 모릅니다) Sokolov에 의해 표시되었습니다.
계산된 배열에 대한 그래프가 MT4 창에서 직접 확장될 수 있고 내가 확장할 수 있지만, 예의와 이타주의의 높이는 결과를 그래픽으로 표시합니다. 나는 내 프로젝트에서 이것을했습니다.
여기 많은 사람들이 매트에서 두 번의 클릭으로 이 문제를 해결할 수 있다는 것을 이해합니다. 패키지이지만 일반적으로 거래자, 프로그래머, 경제학자 및 철학자가 액세스할 수 있는 MQL4 언어를 사용하고 싶습니다.
예, SanSanych가 쓴 것처럼 고전적인 접근 방식은 데이터 분석, 데이터 요구 사항 및 시스템 오류에 대한 기억입니다.
하지만 이 스레드는 Bayes에 관한 것이며 저는 베이지안을 생각하려고 합니다. 마치 참호의 병사가 사후(경험 후) 확률을 계산하는 것과 같습니다. 위에서 군인에 대한 예를 들었습니다.
주요 질문 중 하나는 선험적 확률을 위해 무엇을 취해야 하는지입니다. 즉, 누가 미래의 장막 뒤에 놓을 것인가, 제로 바의 오른쪽에. 가우스? 라플라스? 위너? 전문 수학자들은 여기에 무엇을 씁니다(저를 위한 어두운 "숲")?
저는 가우스를 선택했습니다. 첫째로 정규 분포에 대한 아이디어가 있고 두 번째로 정규 분포를 믿기 때문입니다. "슛"하지 않으면 다른 법칙을 사용하여 가우스 대신 베이즈 공식으로 대체하거나 가우스와 함께 두 확률의 곱으로 대체할 수 있습니다. 내가 올바르게 이해한다면 베이지안 네트워크를 만들어보십시오.
물론 나 혼자 할 수는 없다. 나는 꽃다발 아래에서 공식화한 작업에서 가우스에 대처할 것입니다. 자발적으로 참여하고 싶은 사람이 있다면 환영합니다. 다음은 현재 문제의 예입니다.
주어진: 일반 MT4 난수 생성기.
필수: 정규 RNG로 구성된 MT4[] 배열을 정규 분포의 ND[] 배열로 변환하기 위해 MQL4 코드를 FP() 함수 형식으로 작성합니다.
변환 공식은 https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/ Vasily (나는 애칭을 모릅니다) Sokolov에 의해 표시되었습니다.
계산된 배열에 대한 그래프가 MT4 창에서 직접 확장될 수 있고 내가 확장할 수 있지만, 예의와 이타주의의 높이는 결과를 그래픽으로 표시합니다. 나는 내 프로젝트에서 이것을했습니다.
여기 많은 사람들이 매트에서 두 번의 클릭으로 이 문제를 해결할 수 있다는 것을 이해합니다. 패키지이지만 일반적으로 거래자, 프로그래머, 경제학자 및 철학자가 액세스할 수 있는 MQL4 언어를 사용하고 싶습니다.
다음은 일반 분포를 포함하여 다양한 분포를 가진 생성기입니다.
https://www.mql5.com/ru/articles/273
R 언어의 분포에 대한 간략한 분석:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189시간당 막대의 시작 가격에서 사용 가능한 증분에 대한 정규 분포의 매개변수를 추정하고 동일한 분포의 원본 시리즈와 정규의 빈도와 밀도를 비교하기 위해 표시했습니다. 육안으로도 알 수 있듯이, 시간당 막대의 원래 일련의 증가는 정상과 거리가 멉니다.
그런데 우리는 하나님의 성전에 있지 않습니다. 믿는 것은 선택 사항이며 심지어 해롭습니다.
여기에 내가 위에 쓴 내용을 반영하는 위의 게시물에서 흥미로운 줄이 있습니다.
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
내가 사분면에서 이해하는 한, 모든 시간당 증가분의 50%는 7핍 미만입니다! 그리고 더 적절한 증분은 뚱뚱한 꼬리에 있습니다. 선과 악의 반대편에.
그리고 TS는 어떤 모습일까요? 그게 Bayes 등이 아니라 전체 문제입니다...
아니면 다른 방식으로 이해해야 합니까?
여기에 내가 위에 쓴 내용을 반영하는 위의 게시물에서 흥미로운 줄이 있습니다.
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
내가 사분면에서 이해하는 한, 모든 시간당 증가분의 50%는 7핍 미만입니다! 그리고 더 적절한 증분은 뚱뚱한 꼬리에 있습니다. 선과 악의 반대편에.
그리고 TS는 어떤 모습일까요? 그게 Bayes 등이 아니라 전체 문제입니다...
아니면 다른 방식으로 이해해야 합니까?
SanSanych, 네!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')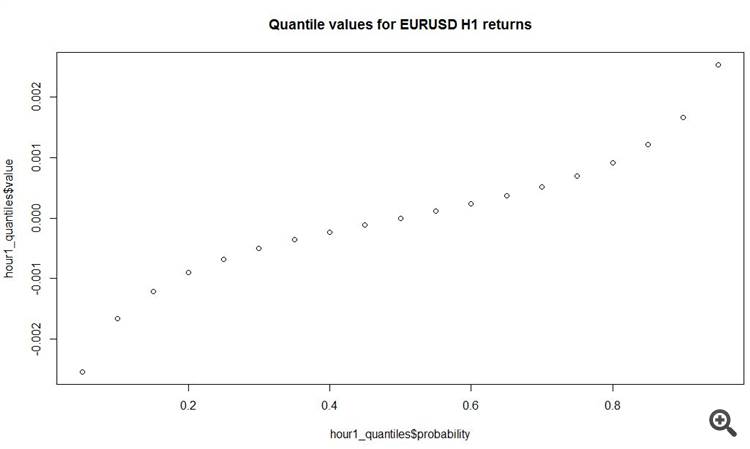
그리고 한 가지 더 흥미로운 점은 시간당 막대의 평균 절대 증분은 11포인트입니다! 총.
변형과 ... 둘 다 필요하기 때문에 아프기까지 오랜 시간이 걸리겠지만 나는 Box-Cox를 별로 좋아하지 않습니다)))) 그렇지 않으면 유감입니다
정상적인 예측 변수, 이것은 최종 결과에 거의 영향을 미치지 않을 것입니다 ...