トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 436 1...429430431432433434435436437438439440441442443...3399 新しいコメント 削除済み 2017.06.30 17:46 #4351 エリブラリウス 効いてます!ありがとうございます。その仕組みが面白い...。 最も類似した1つの選択肢を探すのか、それともいくつかの選択肢を平均化するのか?どうやら、最適な1枚を探し出してくれるようです。10種類、あるいは100種類のバリエーションを用意して、平均的な予測値を探せばいいと思います(正確な数はオプティマイザが決めるはずです)。 そうです、ここでは1番良いものを示しています、私は多くのバリエーションを気にしませんでした、あなたは私の文章を理解するならば、やり直してみることができます ) Женя 2017.06.30 21:20 #4352 ドクタートレーダー価格だけで利益を出すトレードのやり方は、今まで習ったことがありません。でも、パターンモデルがそうだったのですから、選択は当然です :)パターン」を見つけることと、それが統計的に優位に立つことは、まったく別のことです。IMHO なぜかとても疑問です。実際、平均化された歴史系列の全長に沿ったコンボリューション(積、差)によるパターンの探索 は、NSでONE NEURONを使って回帰するようなもので、それは極めて愚かな符号を持つ最も単純な線形モデルであり、そのまま価格の一片を表しているのです。 Aleksei Kuznetsov 2017.06.30 21:39 #4353 ジャンニパターン」を見つけることと、統計的な優位性を見つけることは別のことです。IMHO 非常に疑問です。実際、平均化された歴史的なシリーズの全長を畳み込んで(積、差)パターンを探すのは、NSでONE NEURONを使って回帰するようなもので、それは最も単純な線形モデルで、極めておぼつかない特徴、価格の一片をそのまま表しているのです。もしそれが単一のニューロンであれば、パターンの長さに等しい入力数で、(30バーのパターン=30 NSbの入力、500バーのパターン=500 NSの入力)。私の考えでは、NSの内部層の多くのニューロンはメモリに類似しており、10 - 50 - 100個の追加のニューロンは、それに応じて入力信号の10 - 50 - 100個の記憶された変種である。そして、履歴(1年間のM1)から37万5000のバリエーションと比較すると、最も頻繁に遭遇する10〜50〜100のバリエーションではなく、絶対的に正確で完全な記憶があるのです。そして、この記憶からパターンファインダーは最も類似したN個の結果を特定し、平均的な予測を得る。一方、ニューラルネットワークは類似したパターンがあるごとにニューロン間の接続の重みを増加させる。 また、なぜ畳み込みを使うのかが不明です。求められたパターンと履歴の各変種を畳み込み、その結果、3番目の一時的な配列が得られるという提案だと思いますが、パターンとチェックされる変種の類似性を判断するのに、どう役に立つのでしょうか。 Женя 2017.06.30 22:58 #4354 エリブラリウス1つのニューロンであれば、テンプレートの長さと同じ入力数で、(30本のバーのテンプレート=30個のNS入力、500本のバー=500個のNS入力)。 その通りです。elibrarius: もう一つはっきりしないのは、なぜ畳み込みを適用するのかということです。検索したパターンと履歴の各変種を畳み込み、その結果、3番目の時系列を得るという提案だと思いますが、パターンとチェックした変種の類似性を定義するのに、それがどのように役立つのでしょう? 極値が最も似ているパターンとシリーズを最小化する、そんな単純なことです。例えば、範囲 {0,0,0,1,2,3,1,1} があり、その中からパターン {1,2,3} を見つけたい場合、折りたたむと {0,0,0,3,8,14,11,8,6} (目で数えた)14個が最大でパターンの「頭」になります。もちろん,畳み込む前にベクトルを正規化(mo=0,length=1)することが望ましいが,そうしないと数値の大きな場所で極端な値が発生することになる Aleksei Kuznetsov 2017.06.30 22:59 #4355 マキシム・ドミトリエフスキー そうです、ここでは1が一番よくわかります、多くのバリエーションに悩まされることはありませんでした、私の文章が理解できたらやり直してみてください )を見ながら、何かがおかしい...。 以下はランダムな例です。青い予想線が非常に急な下降線を描き、似たような変形の弱い動きをしていますね...。 この変形をフォトショップで加工したところ、それほど急峻ではなく、アイデア次第でもっとロジカルになることがわかりました。 削除済み 2017.06.30 23:06 #4356 エリブラリウス写真を見ながら、何かがおかしい...。 以下はランダムな例です。青い予想線は非常に急な下降で、似たような変形の弱い動きをしていますね...。 この変形をフォトショップで加工したところ、それほど急峻ではなく、アイデア次第でもっとロジカルになることがわかりました。ある状況下では、なぜか角度が正しくカウントされません。シングルタイムフレームバージョンからマルチタイムフレームバージョンに書き直した後に始まり、どこに欠陥があるのかまだ分かっていませんちなみに、全然正しくカウントできていない可能性もありますが...Photoshopで確認しようとは思いませんでした。これまでのグラフと予測の角度が同じであること Aleksei Kuznetsov 2017.06.30 23:06 #4357 ジャンニ その通りです。 パターンと極端が一番似ていた列を崩すんですね、単純です。例えば、{0,0,0,1,2,3,1,1}という行があり、その中から{1,2,3}というパターンを探したいとすると、畳み込みによって{0,0,0,3,8,14,11,8, 6}(目算)最大14件、パターンの「頭」がどこにあるかがわかります。もちろん、畳み込む前にベクトルを正規化することが望ましい。そうしないと、数値の大きい場所で極端な値が発生するからである。なぜ、このように物事を複雑にするのでしょうか?1,2,3}の行で具体的に{0,0,0,1,2,3,1,1}を探せばいいのに、なぜ畳み込みで極値を探さなければならないのでしょう。複雑さと計算時間が増えることを除けば、何のメリットもないと思います。 Женя 2017.06.30 23:08 #4358 エリブラリウスなぜ、そんなふうに物事を複雑にするのか。具体的には系列{1,2,3}の中から{0,0,0,1,2,3,1,1}を探せばいいのに、なぜ畳み込み上の極値を探さなければならないのでしょう。複雑で計算時間がかかることを除けば、何のメリットもないと思います。うーん、「具体的に検索する」というのはどういうことでしょうか?コンボリューションより高速なアルゴリズムの例を教えてください。2つの操作を使用することができます:ベクトルの差分長とスカラー積、差分長は、私を信じて3〜10倍遅いです、成分の差、二乗、和、ルート抽出、および畳み込みは、乗算と加算することです。長さ3の行の各ピースをベクトルとして、我々の{1,2,3}と「類似性」を比較する必要があります。 Aleksei Kuznetsov 2017.06.30 23:21 #4359 ジャンニうーん、「具体的に検索する」というのはどういうことでしょうか?コンボリューションより高速なアルゴリズムの例を教えてください。最も簡単なのは、求める例の窓幅をシーケンス全体で段階的にずらし、その差分の abs 値の合計を求めることである。 0,0,0 と 1,2,3 の誤差 = (1-0)+(2-0)+(3-0)=6 となります。0,0,1 および 1,2,3 エラー = (1-0)+(2-0)+(3-1)=50,1,2 および 1,2,3 エラー = (1-0)+(2-1)+(3-2)=31,2,3 と 1,2,3 の誤差=(1-1)+(2-2)+(3-3)=0。2,3,1 と 1,2,3 の誤差 = (2-1)+(3-2)+Abs(1-3) =4となります。ここで、最小の誤差は最大の類似性である。 Aleksei Kuznetsov 2017.06.30 23:35 #4360 マキシム・ドミトリエフスキー特定の状況下で、なぜか角度を正しくカウントしないことに気づいた。ちなみに、全然カウントを間違えている可能性もありますが...Photoshopで確認することができなかったので。過去のチャートと予測の間で同じ角度を得る必要があるんだ。これだけ傾斜角が違うのに、グラフが似ていると考えるのが正しいのかどうか、まだよくわかりません。同じ例で言うとトレンドの上方または下方のポイントからの引き戻しを示すバリアントは、パターンチャートに転送することによって、反転ではなく、下落トレンドの継続を予測します - 基本的に逆信号です。何かおかしいぞ...。もしかしたら、このアフィン変換は必要ないのでは......?また、単純な相関関係(最小限の誤差)でよいのでしょうか? 1...429430431432433434435436437438439440441442443...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
効いてます!ありがとうございます。その仕組みが面白い...。
最も類似した1つの選択肢を探すのか、それともいくつかの選択肢を平均化するのか?どうやら、最適な1枚を探し出してくれるようです。10種類、あるいは100種類のバリエーションを用意して、平均的な予測値を探せばいいと思います(正確な数はオプティマイザが決めるはずです)。
そうです、ここでは1番良いものを示しています、私は多くのバリエーションを気にしませんでした、あなたは私の文章を理解するならば、やり直してみることができます )
価格だけで利益を出すトレードのやり方は、今まで習ったことがありません。でも、パターンモデルがそうだったのですから、選択は当然です :)
パターン」を見つけることと、それが統計的に優位に立つことは、まったく別のことです。IMHO なぜかとても疑問です。実際、平均化された歴史系列の全長に沿ったコンボリューション(積、差)によるパターンの探索 は、NSでONE NEURONを使って回帰するようなもので、それは極めて愚かな符号を持つ最も単純な線形モデルであり、そのまま価格の一片を表しているのです。
パターン」を見つけることと、統計的な優位性を見つけることは別のことです。IMHO 非常に疑問です。実際、平均化された歴史的なシリーズの全長を畳み込んで(積、差)パターンを探すのは、NSでONE NEURONを使って回帰するようなもので、それは最も単純な線形モデルで、極めておぼつかない特徴、価格の一片をそのまま表しているのです。
もしそれが単一のニューロンであれば、パターンの長さに等しい入力数で、(30バーのパターン=30 NSbの入力、500バーのパターン=500 NSの入力)。
私の考えでは、NSの内部層の多くのニューロンはメモリに類似しており、10 - 50 - 100個の追加のニューロンは、それに応じて入力信号の10 - 50 - 100個の記憶された変種である。そして、履歴(1年間のM1)から37万5000のバリエーションと比較すると、最も頻繁に遭遇する10〜50〜100のバリエーションではなく、絶対的に正確で完全な記憶があるのです。そして、この記憶からパターンファインダーは最も類似したN個の結果を特定し、平均的な予測を得る。一方、ニューラルネットワークは類似したパターンがあるごとにニューロン間の接続の重みを増加させる。
また、なぜ畳み込みを使うのかが不明です。求められたパターンと履歴の各変種を畳み込み、その結果、3番目の一時的な配列が得られるという提案だと思いますが、パターンとチェックされる変種の類似性を判断するのに、どう役に立つのでしょうか。1つのニューロンであれば、テンプレートの長さと同じ入力数で、(30本のバーのテンプレート=30個のNS入力、500本のバー=500個のNS入力)。
もう一つはっきりしないのは、なぜ畳み込みを適用するのかということです。検索したパターンと履歴の各変種を畳み込み、その結果、3番目の時系列を得るという提案だと思いますが、パターンとチェックした変種の類似性を定義するのに、それがどのように役立つのでしょう?
そうです、ここでは1が一番よくわかります、多くのバリエーションに悩まされることはありませんでした、私の文章が理解できたらやり直してみてください )
を見ながら、何かがおかしい...。
以下はランダムな例です。
青い予想線が非常に急な下降線を描き、似たような変形の弱い動きをしていますね...。
この変形をフォトショップで加工したところ、それほど急峻ではなく、アイデア次第でもっとロジカルになることがわかりました。
写真を見ながら、何かがおかしい...。
以下はランダムな例です。
青い予想線は非常に急な下降で、似たような変形の弱い動きをしていますね...。
この変形をフォトショップで加工したところ、それほど急峻ではなく、アイデア次第でもっとロジカルになることがわかりました。
ある状況下では、なぜか角度が正しくカウントされません。シングルタイムフレームバージョンからマルチタイムフレームバージョンに書き直した後に始まり、どこに欠陥があるのかまだ分かっていません
ちなみに、全然正しくカウントできていない可能性もありますが...Photoshopで確認しようとは思いませんでした。これまでのグラフと予測の角度が同じであること
その通りです。
パターンと極端が一番似ていた列を崩すんですね、単純です。例えば、{0,0,0,1,2,3,1,1}という行があり、その中から{1,2,3}というパターンを探したいとすると、畳み込みによって{0,0,0,3,8,14,11,8, 6}(目算)最大14件、パターンの「頭」がどこにあるかがわかります。もちろん、畳み込む前にベクトルを正規化することが望ましい。そうしないと、数値の大きい場所で極端な値が発生するからである。
なぜ、このように物事を複雑にするのでしょうか?1,2,3}の行で具体的に{0,0,0,1,2,3,1,1}を探せばいいのに、なぜ畳み込みで極値を探さなければならないのでしょう。複雑さと計算時間が増えることを除けば、何のメリットもないと思います。
なぜ、そんなふうに物事を複雑にするのか。具体的には系列{1,2,3}の中から{0,0,0,1,2,3,1,1}を探せばいいのに、なぜ畳み込み上の極値を探さなければならないのでしょう。複雑で計算時間がかかることを除けば、何のメリットもないと思います。
うーん、「具体的に検索する」というのはどういうことでしょうか?コンボリューションより高速なアルゴリズムの例を教えてください。
2つの操作を使用することができます:ベクトルの差分長とスカラー積、差分長は、私を信じて3〜10倍遅いです、成分の差、二乗、和、ルート抽出、および畳み込みは、乗算と加算することです。
長さ3の行の各ピースをベクトルとして、我々の{1,2,3}と「類似性」を比較する必要があります。
うーん、「具体的に検索する」というのはどういうことでしょうか?コンボリューションより高速なアルゴリズムの例を教えてください。
最も簡単なのは、求める例の窓幅をシーケンス全体で段階的にずらし、その差分の abs 値の合計を求めることである。
0,0,0 と 1,2,3 の誤差 = (1-0)+(2-0)+(3-0)=6 となります。
0,0,1 および 1,2,3 エラー = (1-0)+(2-0)+(3-1)=5
0,1,2 および 1,2,3 エラー = (1-0)+(2-1)+(3-2)=3
1,2,3 と 1,2,3 の誤差=(1-1)+(2-2)+(3-3)=0。
2,3,1 と 1,2,3 の誤差 = (2-1)+(3-2)+Abs(1-3) =4となります。
ここで、最小の誤差は最大の類似性である。
特定の状況下で、なぜか角度を正しくカウントしないことに気づいた。
ちなみに、全然カウントを間違えている可能性もありますが...Photoshopで確認することができなかったので。過去のチャートと予測の間で同じ角度を得る必要があるんだ。
これだけ傾斜角が違うのに、グラフが似ていると考えるのが正しいのかどうか、まだよくわかりません。同じ例で言うと
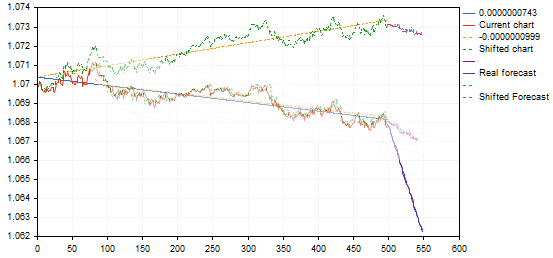
トレンドの上方または下方のポイントからの引き戻しを示すバリアントは、パターンチャートに転送することによって、反転ではなく、下落トレンドの継続を予測します - 基本的に逆信号です。何かおかしいぞ...。もしかしたら、このアフィン変換は必要ないのでは......?また、単純な相関関係(最小限の誤差)でよいのでしょうか?