"New Neural" est un projet de moteur de réseau neuronal Open Source pour la plateforme MetaTrader 5. - page 56
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Oui, c'est exactement ce que je voulais savoir.
A mql5
SZ, la plus grande préoccupation pour le moment est de savoir si les données devront être copiées dans des tableaux spéciaux du CPU ou si le passage d'un tableau comme paramètre dans une fonction normale sera pris en charge. Cette question peut changer fondamentalement l'ensemble du projet.
ZZY Pouvez-vous nous dire si vous prévoyez de fournir uniquement l'API OpenCL ou si vous prévoyez de l'intégrer dans vos propres wrappers ?
2) Il y aura un wrapper, seuls les GPU HW seront supportés (avec le support d'OpenCL 1.1).
La sélection de plusieurs GPU, le cas échéant, ne sera possible que par le biais des paramètres du terminal.
OpenCL sera utilisé de manière synchrone.
Oui, c'est exactement ce que je voulais savoir.
A mql5
SZ La principale préoccupation pour le moment est de savoir si les données devront être copiées dans des tableaux spéciaux du CPU ou si le passage d'un tableau comme paramètre dans une fonction normale sera pris en charge. Cette question peut changer fondamentalement l'ensemble du projet.
ZZZY pouvez-vous nous dire si vous envisagez de fournir uniquement l'API OpenCL ou si vous prévoyez de l'intégrer dans vos propres wrappers ?
Jugement par :
mql5:
Vous pourrez en effet utiliser directement les fonctions de la bibliothèque OpenCL.dll sans avoir à brancher des DLL tierces.
Les fonctions OpenCL.dll seront disponibles comme s'il s'agissait de fonctions natives de MQL5 tandis que le compilateur redirigera lui-même les appels.
On peut en conclure que les fonctions d'OpenCL.dll peuvent déjà être mises en place dès maintenant (appels fictifs).
Renat et mql5, ai-je bien compris "l'environnement" ?
Jugement par :
Les fonctions OpenCL.dll peuvent être utilisées comme s'il s'agissait de fonctions natives de MQL5 et le compilateur lui-même redirigera les appels.
On peut en conclure que les fonctions d'OpenCL.dll peuvent déjà être mises en place dès maintenant (appels fictifs).
Renat et mql5, ai-je bien compris la "situation" ?
Jusqu'à présent, c'est le schéma du projet :
Les objets sont des rectangles, les méthodes des ellipses.Les méthodes de traitement sont divisées en 4 catégories :
Ces quatre méthodes décrivent l'ensemble du traitement dans toutes les couches. Les méthodes sont importées dans le traitement par le biais d'objets méthodes, qui sont hérités de la classe de base et surchargés si nécessaire en fonction du type de neurone.
Nikolaï, vous connaissez la phrase d'accroche : l'optimisation prématurée est la racine de tous les maux.
Oubliez OpenCL pour le moment. Vous devrez faire quelque chose de décent sans lui. Vous aurez toujours le temps de le transposer, surtout s'il n'est pas encore disponible.
Nikolay, vous connaissez cette phrase populaire - l'optimisation prématurée est la racine de tous les maux.
Oubliez OpenCL pour l'instant ; vous auriez pu écrire quelque chose de décent sans lui. Vous pouvez toujours l'échanger. D'ailleurs, il n'y a pas encore de fonction interne.
Oui, c'est une phrase populaire et j'ai presque été d'accord avec elle la dernière fois, mais après l'avoir analysée, j'ai réalisé que je ne pouvais pas simplement la planifier puis la redessiner pour le GPU, elle a des besoins très spécifiques.
Si nous planifions sans GPU, il serait logique de créer un objet Neuron, qui serait responsable à la fois des opérations à l'intérieur d'un neurone, et de l'allocation des données de calcul dans les cellules de mémoire requises, en héritant d'une classe d'un ancêtre commun, nous pourrions facilement connecter le type de neurone requis et ainsi de suite,
Mais ayant fait travailler un peu mon cerveau, j'ai immédiatement compris que cette approche détruira complètement les calculs de GPU, l'enfant à naître est condamné à ramper.
Par "méthode de calcul parallèle", j'entends l'opération très spécifique qui consiste à multiplier les entrées avec les poids dans*wg, par méthode de calcul successif, j'entends somme+=a[i] et ainsi de suite.
Juste pour une meilleure compatibilité future avec les GPU, je propose de dériver les opérations des neurones et de les combiner en un seul mouvement dans un objet de couche, et les neurones ne fourniraient que des informations d'où prendre où mettre.
Lecture 1 ici https://www.mql5.com/ru/forum/4956/page23
Lecture 2 ici https://www.mql5.com/ru/forum/4956/page34
Lecture 3 ici https://www.mql5.com/ru/forum/4956/page36
Lecture 4 ici https://www.mql5.com/ru/forum/4956/page46
Conférence 5 (dernière). Codage épars
Ce sujet est le plus intéressant. Je vais rédiger ce cours progressivement. N'oubliez donc pas de consulter cet article de temps en temps.
En général, notre tâche est de présenter la cotation des prix (vecteur x) sur les N dernières barres comme une décomposition linéaire en fonctions de base (séries de la matrice A) :
où s sont les coefficients de notre transformation linéaire que nous voulons trouver et utiliser comme entrées de la couche suivante du réseau neuronal (par exemple, SVM). Dans la plupart des cas, on connaît les fonctions de base A , c'est-à-dire qu'on les choisit à l'avance. Il peut s'agir de sinus et de cosinus de différentes fréquences (on obtient la transformée de Fourier), de fonctions de Gabor, de Hammotons, d'ondelettes, de courbures, de polynômes ou de toute autre fonction. Si ces fonctions nous sont connues à l'avance, alors le codage clairsemé se réduit à trouver un vecteur de coefficients s de telle sorte que la plupart de ces coefficients soient nuls (vecteur clairsemé). L'idée est que la plupart des signaux d'information ont une structure qui est décrite par un nombre de fonctions de base inférieur au nombre d'échantillons du signal. Ces fonctions de base incluses dans la description éparse du signal sont ses caractéristiques nécessaires qui peuvent être utilisées pour la classification du signal.
Le problème consistant à trouver la transformation linéaire déchargée de l'information originale est appelé "Compressed Sensing" (http://ru.wikipedia.org/wiki/Compressive_sensing). En général, le problème est formulé comme suit :
minimiser la norme L0 de s, sous réserve que As = x
où la norme L0 est égale au nombre de valeurs non nulles du vecteur s. La méthode la plus courante pour résoudre ce problème consiste à remplacer la norme L0 par la norme L1, ce qui constitue la base de la méthode de poursuite de base(https://en.wikipedia.org/wiki/Basis_pursuit):
minimiser la norme L1 de s, sous réserve que As = x
où la norme L1 est calculée comme suit : |s_1|+|s_2|+...+|s_L|. Ce problème se réduit à une optimisation linéaire
Une autre méthode populaire pour trouver le vecteur clairsemé s est la recherche de correspondance(https://en.wikipedia.org/wiki/Matching_pursuit). L'essence de cette méthode est de trouver la première fonction de base a_i d'une matrice A donnée telle qu'elle s'adapte au vecteur d'entrée x avec le plus grand coefficient s_i par rapport aux autres fonctions de base.Après avoir soustrait a_i*s_i du vecteur d'entrée, nous ajoutons la fonction de base suivante au résidu résultant, et ainsi de suite, jusqu'à ce que nous atteignions l'erreur donnée. Un exemple de la méthode de poursuite de la correspondance est l'indicateur suivant, qui inscrit un sinus après l'autre dans le vecteur d'entrée avec le plus petit résidu : https://www.mql5.com/ru/code/130.
Si les fonctions de baseA(dictionnaire) ne nous sont pas connues à l'avance, nous devons les trouver à partir des données d'entréex en utilisant des méthodes collectivement appelées apprentissage du dictionnaire. C'est la partie la plus difficile (et pour moi la plus intéressante) de la méthode de codage clairsemé. Dans mon précédent cours, j'ai montré comment ces fonctions peuvent, par exemple, être trouvées par la règle d'Ogi, qui fait de ces fonctions des vecteurs principaux de citations d'entrée. Malheureusement, ce type de fonctions de base ne conduit pas à une description disjointe des données d'entrée (c'est-à-dire que le vecteur s n'est pas clair).
Les méthodes existantes d'apprentissage de dictionnaires conduisant à des transformations linéaires disjointes sont divisées en deux catégories
Lesméthodes probabilistes de recherche des fonctions de base se réduisent à la maximisation de la vraisemblance maximale :
maximiser P(x|A) sur A.
Habituellement, on suppose que l'erreur d'approximation a une distribution gaussienne, ce qui nous amène à résoudre le problème d'optimisation suivant :
(1)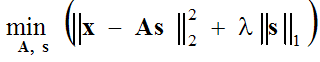 ,
,
qui est résolu en deux étapes : (1) étape de codage épars) avec la fonction de base A fixée, l'expression entre parenthèses est minimisée par rapport au vecteur s, et (2) étape de mise à jour du dictionnaire) le vecteur trouvés est fixé et l'expression entre parenthèses est minimisée par rapport à la fonction de base A en utilisant la méthode de descente du gradient :
(2)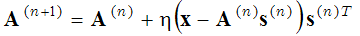
où (n+1) et (n) en exposant désignent les numéros d'itération. Ces deux étapes (étape de codage clairsemé et étape d'apprentissage du dictionnaire) sont répétées jusqu'à ce qu'un minimum local soit atteint. Cette méthode probabiliste de recherche de fonctions de base est utilisée, par exemple, dans les domaines suivants
Olshausen, B. A., & Field, D. J. (1996). Emergence des propriétés des champs réceptifs des cellules simples par l'apprentissage d'un code clairsemé pour les images naturelles. Nature, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999). Apprentissage de représentations surcomplètes. Neural Comput., 12(2), 337-365.
La méthode des directions optimales (MOD) utilise les deux mêmes étapes d'optimisation (étape de codage clairsemé et étape d'apprentissage du dictionnaire), mais dans la deuxième étape d'optimisation (étape de mise à jour du dictionnaire), les fonctions de base sont calculées en égalisant la dérivée de l'expression entre parenthèses (1) par rapport à A à zéro :
où nous obtenons
(3)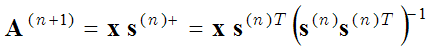 ,
,
où s+ est une matrice pseudo-inverse. Il s'agit d'un calcul plus précis de la matrice de base que la méthode de descente de gradient (2). La méthode MOD est décrite plus en détail ici :
K. Engan, S. O. Aase, et J.H. Hakon-Husoy. Méthode des directions optimales pour la conception des cadres. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 5, pp. 2443-2446, 1999.
Le calcul des matrices pseudo-inverse est fastidieux. La méthode k-SVD évite de le faire. Je n'ai pas encore trouvé la solution. Vous pouvez le lire ici :
M. Aharon, M. Elad, A. Bruckstein. K-SVD : un algorithme pour concevoir des dictionnaires surcomplets pour la représentation éparse. IEEE Trans. Signal Processing, 54(11), novembre 2006.
Je n'ai pas encore compris les méthodes de regroupement et de recherche en ligne du dictionnaire, non plus. Les lecteurs intéressés peuvent se référer à l'enquête suivante :
R. Rubinstein, A. M. Bruckstein et M. Elad, " Dictionaries for sparse representation modeling ", Proc. of IEEE , 98(6), pp. 1045-1057, juin 2010.
Voici quelques conférences vidéo intéressantes sur ce sujet :
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
C'est tout pour le moment. Je développerai ce sujet dans de futurs billets, à mesure que je le pourrai et que les visiteurs de ce forum s'y intéresseront.
Nikolaï, vous connaissez la phrase populaire - l'optimisation prématurée est la racine de tous les maux.
C'est une expression tellement courante pour les développeurs afin de dissimuler leur inutilité, que vous pouvez vous faire taper sur les doigts chaque fois que vous l'utilisez.
Cette phrase est fondamentalement nuisible et absolument fausse, si nous parlons du développement de logiciels de qualité avec un long cycle de vie et une orientation directe sur la vitesse et les charges élevées.
Je l'ai vérifié à de nombreuses reprises au cours de mes nombreuses années de pratique de la gestion de projet.
C'est une expression tellement courante pour couvrir les erreurs des développeurs que vous pouvez vous faire taper sur les doigts à chaque fois que vous l'utilisez.
Vous devez donc prendre en compte certaines fonctionnalités qui apparaîtront on ne sait quand avec on ne sait quelle interface à l'avance parce qu'elles vous donnent un gain de performance ?
J'ai testé cela de nombreuses fois au cours de mes années de pratique de la gestion de projet.