L'apprentissage automatique dans la négociation : théorie, modèles, pratique et algo-trading - page 3009
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Mais surtout, il doit y avoir une preuve théorique que le pouvoir prédictif des caractéristiques disponibles ne change pas, ou change faiblement dans le futur. Dans tout ce rouleau compresseur, c'est la chose la plus importante.
Malheureusement, personne n'a trouvé cela, sinon il ne serait pas ici mais sur les îles tropicales))))
Oui, même un arbre ou une régression peut trouver un modèle s'il est présent et ne change pas.
1. Quelqu'un d'autre a-t-il une paire enseignant-trait avec moins de 20% d'erreur de classification ?
C'est facile. Je peux dégénérer des dizaines d'ensembles de données. Je suis en train d'étudier TP=50 et SL=500. Il y a en moyenne 10 % d'erreur dans la notation de l'enseignant. Si elle est de 20 %, il s'agira d'un modèle de mauvaise qualité.
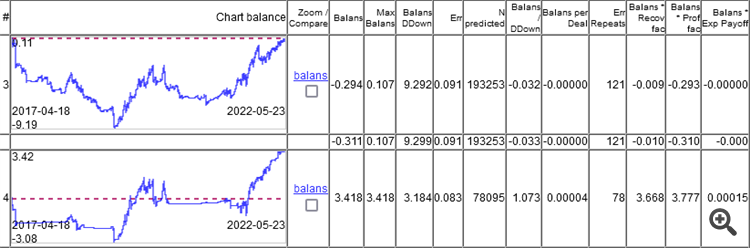
L'important n'est donc pas l'erreur de classification, mais le résultat de l'addition de tous les profits et de toutes les pertes.
Comme vous pouvez le voir, le meilleur modèle a une erreur de 9,1 %, et vous pouvez gagner quelque chose avec une erreur de 8,3 %.
Les graphiques ne montrent que les OOS, obtenus par Walking Forward avec un recyclage une fois par semaine, soit un total de 264 recyclages sur 5 ans.
Il est intéressant que le modèle ait fonctionné à 0 avec une erreur de classification de 9,1 %, et 50/500 = 0,1, c'est-à-dire que 10 % devraient être. Il s'avère que 1% a mangé l'écart (minimum par barre, l'écart réel sera plus grand).
Il faut d'abord se rendre compte que le modèle est plein de déchets à l'intérieur...
Si vous décomposez un modèle en bois formé en règles internes et en statistiques sur ces règles.
comme :
et que l'on analyse la dépendance de l'erreur de la règle err par rapport à la fréquence de son apparition dans l'échantillon.
nous obtenons
Nous nous intéressons donc à ce domaine
Lorsque les règles fonctionnent très bien, mais qu'elles sont si rares qu'il est logique de douter de l'authenticité des statistiques les concernant, car 10-30 observations ne sont pas des statistiques.
Il faut d'abord se rendre compte que le modèle est plein de déchets à l'intérieur...
Si vous décomposez un modèle en bois formé en règles à l'intérieur et en statistiques sur ces règles.
comme.. :
et analyser la dépendance de l'erreur de la règle err sur la fréquence freq de son occurrence dans l'échantillon.
nous obtenons
Juste un rayon de soleil dans l'obscurité des messages récents
Il y aura un article à ce sujet, s'il y en a un.
Il y aura un article à ce sujet, s'il y en a un.
Norm, mon dernier article traitait de la même chose. Mais si votre méthode est plus rapide, c'est un plus.
Que voulez-vous dire par "plus rapide" ?
Que voulez-vous dire par "plus rapide" ?
En termes de vitesse.
environ 5 à 15 secondes sur un échantillon de 5 km
environ 5 à 15 secondes sur un échantillon de 5 km.
Je parle de l'ensemble du processus, depuis le début jusqu'à l'obtention du CT.
J'ai deux modèles qui sont entraînés plusieurs fois, donc ce n'est pas très rapide, mais c'est acceptable.
Et à la fin, je ne sais pas exactement ce qu'ils ont éliminé.
Je veux dire, tout le processus depuis le début jusqu'à l'obtention du CT.
J'ai 2 modèles qui sont entraînés plusieurs fois, donc ce n'est pas très rapide, mais c'est acceptable.
et à la fin, je ne sais pas exactement ce qu'ils ont éliminé.
Entraînement 5k.
Valider 60k.
formation du modèle - 1-3 secondes
extraction des règles - 5-10 secondes
vérification de la validité de chaque règle (20-30k règles) 60k 1-2 minutes
Bien entendu, tout est approximatif et dépend du nombre de caractéristiques et de données.