Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 1489
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Si alguien entiende HMM entonces por favor ayúdeme a resolver el problema, si el problema es solucionable entonces compartiré el grial)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Si alguien entiende HMM entonces por favor ayúdeme a resolver el problema, si el problema es solucionable entonces compartiré el grial)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
bien, el estado es markoviano, pero ¿cuál es el modelo? método tabular o qué
significa que necesitas más puntos para la ventana cuadrada, al menos
y si se alimenta una serie aleatoria, ¿de qué tipo de predicción que no sea 50\50 podemos hablar?significa que necesitas más puntos para la ventana cuadrada, como mínimo
Te lo dije, incluso tomé varios miles de puntos
y si se introduce una serie aleatoria, ¿de qué tipo de predicción, además del 50/50, podemos hablar?
Qué diferencia hay, los datos son los mismos, el modelo es el mismo
Predigo nuevos datos utilizando toda la función del paquete (como en todos los ejemplos en la red ...) los resultados son grandes
Utilizo el mismo modelo para predecir los mismos datos pero con ventana deslizante y el resultado es inaceptable.
Esa es la cuestión: ¿cuál es el problema?Te dije que incluso tomé varios miles de puntos
qué diferencia hay, los datos son los mismos, el modelo es el mismo
Predigo nuevos datos utilizando toda la función en el paquete (como en todos los ejemplos en la web ...) los resultados son grandes
predigo los mismos datos con el mismo modelo pero con una ventana deslizante y el resultado es diferente, inaceptable.
Esa es la verdadera pregunta: ¿cuál es el problema?No sé qué tipo de modelo y de dónde sacas los estados. sin paquetes, ¿qué sentido tiene?
Tal vez hay un gcf que no da ningún estado aleatorio, por eso se predice en el 1er caso. Intenta cambiar la semilla tanto para el tren como para la prueba para ver que en el 1er caso es imposible predecir nada, de lo contrario no se como ayudar la idea no es clara
Las divisiones se realizan en función de la probabilidad de clasificación. Más concretamente, no por probabilidad, sino por error de clasificación. Porque todo se sabe en el simulacro de entrenamiento, y no tenemos probabilidad, sino una estimación exacta.
Aunque existen diferentes fi rmas de separación, es decir, medidas de impureza (muestreo izquierdo o derecho).
Me refería a la distribución de la precisión de la clasificación sobre la muestra, no al total como se hace ahora.
no está claro cuál es el modelo y de dónde se obtienen los estados. Sin paquetes, conceptualmente, ¿qué sentido tiene?
Tal vez hay un gcp que no da ninguna aleatoriedad, por eso se predice en el 1er caso. Intenta cambiar la semilla tanto para el tren como para la prueba para ver si es imposible predecir en el primer caso también, de lo contrario no sé cómo ayudar a la idea.
Aquí está el archivo, hay precios y dos columnas con predictores "data1" y "data2".
Entrenas el HMM con sólo dos estados(en una pista de datos sin maestro) para estas dos columnas ("datos1" y "datos2") en Python o lo que quieras. No tocas el precio para nada, sólo lo haces para visualizarlo
Entonces se toma el algoritmo de Viterbi y se hace una (prueba de datos).
obtenemos dos estados, debería ser así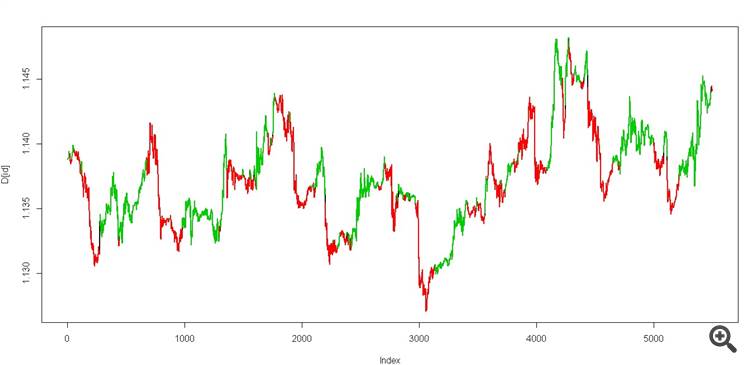
es un verdadero grial))
Y luego tratar de calcular el mismo Viterbi en la ventana deslizante utilizando los mismos datos
Aquí hay un archivo con precios y dos columnas con predictores "data1" y "data2".
Entrenas el HMM con sólo dos estados(en una pista de datos) usando estas dos columnas ("data1" y "data2") en Python o lo que quieras. No tocas el precio en absoluto, sólo lo usas para la visualización.
Entonces se toma el algoritmo de Viterbi y (prueba de datos)
obtenemos dos estados, debería ser así
Es un verdadero grial).
Y a continuación, intente el mismo cálculo de Viterbi en la ventana deslizante sobre los mismos datos
Senk, lo miraré más tarde, ya te avisaré, porque estoy trabajando con un markoviano.
senk, lo comprobaré más tarde y te informaré, ya que yo mismo estoy trabajando con Markov.
¿ha habido suerte?
¿ha habido suerte?
No estoy buscando todavía, día libre ) Te lo haré saber cuando tenga tiempo, más tarde en la semana quiero decir
mirando los paquetes hasta ahora. Creo que se ajusta ahttps://hmmlearn.readthedocs.io/en/latest/tutorial.html