Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 1258
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
un montón de fórmulas ((
Bueno ) hay un enlace al paquete R. Yo no uso R, entiendo las fórmulas.
si usas R, pruébalo )
Bueno ) hay un enlace al paquete R. Yo no uso R, entiendo las fórmulas.
Si usas R, pruébalo )
El artículo de esta mañana sigue abierto: https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
El hecho más decepcionante es que no he podido encontrar una implementación en Python de este algoritmo. Los autores crearon un paquete de R(BayesTrees) que tenía algunos problemas obvios -sobre todo la falta de una función de "predicción"- y se creó otra implementación más utilizada llamada bartMachine.
Si tienes experiencia en la aplicación de esta técnica o conoces una biblioteca de Python, ¡deja un enlace en los comentarios!
Así que el primer paquete es inútil porque no puede predecir.
El segundo enlace vuelve a tener fórmulas.
He aquí un árbol ordinario fácil de entender. Todo es sencillo y lógico. Y sin fórmulas.
Tal vez aún no he llegado a los liberales. Los árboles son sólo un caso especial de un enorme tema bayesiano, por ejemplo, hay muchos ejemplos de libros y vídeos aquí
Utilicé la optimización bayesiana de los hiperparámetros de NS según los artículos de Vladimir. Funciona bien.Como qué árboles... hay redes neuronales bayesianas
Inesperadamente.
NS trabaja con las operaciones matemáticas + y * y puede construir cualquier indicador dentro de sí mismo, desde MA hasta filtros digitales.
Pero los árboles se dividen en partes derecha e izquierda por medio de un simple if(x<v){rama izquierda}else{rama derecha}.
¿O es también if(x<v){rama izquierda}else{rama derecha}?
Pero si hay muchas variables que optimizar, es ooooootra vez.
Inesperadamente.
NS trabaja con las operaciones matemáticas + y * y puede construir cualquier indicador en su interior - desde MA hasta filtros digitales.
Los árboles se dividen en partes derecha e izquierda por medio de un simple if(x<v){rama izquierda}else{rama derecha}.
¿O el NS baisiano es también if(x<v){rama izquierda}else{rama derecha}?
es, sí, lento, por lo que sacar de ahí conocimientos útiles hasta ahora, da una comprensión de algunas cosas
No, en la NS bayesiana, los pesos se optimizan simplemente muestreando los pesos de las distribuciones, y la salida es también una distribución que contiene un montón de opciones, pero tiene una media, varianza, etc. En otras palabras, capta un montón de variantes que no están realmente en el conjunto de datos de entrenamiento, pero que se suponen a priori. Cuantas más muestras se introduzcan en este tipo de NS, más se acercará a una regular, es decir, los enfoques bayesianos son inicialmente para conjuntos de datos no muy grandes. Esto es lo que sé hasta ahora.
Es decir, estas NS no necesitan conjuntos de datos muy grandes, los resultados convergerán a los convencionales. Pero el resultado después del entrenamiento no será una estimación puntual, sino una distribución de probabilidad para cada muestra.
es, sí, lento, por lo que sacar de ahí conocimientos útiles hasta ahora, da una comprensión de algunas cosas
No, en la NS bayesiana, los pesos se optimizan simplemente muestreando los pesos de las distribuciones, y la salida es también una distribución que contiene un montón de opciones, pero tiene una media, varianza, etc. En otras palabras, capta un montón de variantes que no están realmente en el conjunto de datos de entrenamiento, pero que se suponen a priori. Cuantas más muestras se introduzcan en este tipo de NS, más se acercará a una regular, es decir, los enfoques bayesianos son inicialmente para conjuntos de datos no muy grandes. Esto es lo que sé hasta ahora.
Es decir, tales NS no necesitan conjuntos de datos muy grandes, los resultados convergerán a los convencionales. Pero el resultado después del entrenamiento no será una estimación puntual, sino una distribución de probabilidad para cada muestra.
Vas de un lado a otro como si fueras a toda velocidad, una cosa a la vez, otra cosa a la vez... y es inútil.
Parece que tienes mucho tiempo libre, como algún caballero, necesitas trabajar, trabajar duro y esforzarte por crecer en tu carrera, en lugar de apresurarte desde las redes neuronales hasta lo más básico.
Créanme, nadie en ninguna casa de bolsa normal les dará dinero por verborrea o artículos científicos, sólo la equidad confirmada por los principales corredores del mundo.No me apresuro, pero estudio de manera constante desde lo simple a lo complejo
Si no tienes trabajo, puedo ofrecerte, por ejemplo, reescribir algo en mql.
Yo trabajo para el casero como todo el mundo, es extraño que no trabajes, tú mismo eres un casero, un heredero, un chico de oro, un hombre normal si pierde su trabajo en 3 meses en la calle, está muerto en seis meses.
Si no hay nada de MO en el comercio, entonces date un paseo, creerás que eres el único mendigo aquí)
Les mostré todo en IR, honestamente, no hay secretos infantiles, no hay mierda, el error en la prueba es de 10-15%, pero el mercado está en constante cambio, el comercio no va, charla cerca de cero
En resumen, vete, Vasya, no me interesan los lloriqueos
Lo único que hacéis es lloriquear, sin resultados, claváis tenedores en el agua y ya está, pero no tenéis el valor de admitir que estáis perdiendo el tiempo
Deberías unirte al ejército o al menos trabajar en una obra con hombres físicamente, mejorarías tu carácter.es lento, por eso estoy sacando algunos conocimientos útiles hasta ahora, da una comprensión de algunas cosas
No, en la NS bayesiana, los pesos se optimizan simplemente muestreando los pesos de las distribuciones, y la salida es también una distribución que contiene un montón de opciones, pero tiene una media, varianza, etc. En otras palabras, capta un montón de variantes que no están realmente en el conjunto de datos de entrenamiento, pero que, a priori, se suponen. Cuantas más muestras se introduzcan en este tipo de NS, más se acercará a una regular, es decir, los enfoques bayesianos son inicialmente para conjuntos de datos no muy grandes. Esto es lo que sé hasta ahora.
Es decir, este tipo de NS no necesita conjuntos de datos muy grandes, los resultados convergerán a los convencionales.
Aquí está de https://www.mql5.com/ru/forum/226219 comentarios sobre el artículo de Vladimir sobre la optimización bayesiana, cómo traza la curva sobre múltiples puntos. Pero entonces tampoco necesitan NS/bosques: basta con buscar la respuesta justo en esta curva.
Otro problema: si un optimizador no aprende, le enseñará a NS alguna tontería incomprensible.
 muestra enseñado
muestra enseñado 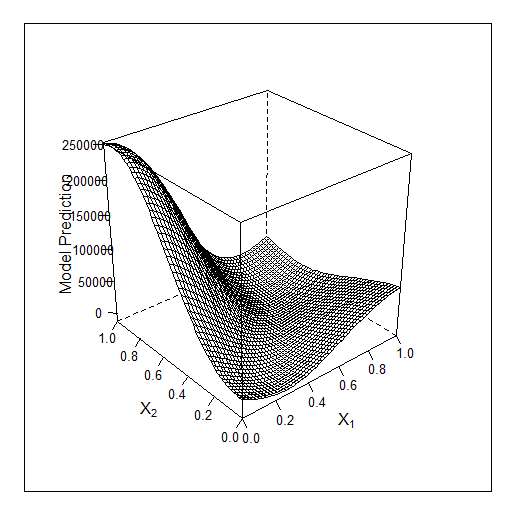
Aquí para 3 características Bayes trabajo
Son los imbéciles del hilo los que hacen que no sea nada divertido.
lloriqueando para sí mismos.
¿De qué hay que hablar? Solo coleccionas enlaces y diferentes resúmenes científicos para impresionar a los recién llegados, SanSanych lo ha escrito todo en su artículo, no hay mucho que añadir, ahora hay diferentes vendedores y articulistas que manchan todo con sus horcas de vergüenza y asco. Se llaman "matemáticos", se llaman "cuánticos" .....
Quieres matemáticas tratar de leer estehttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf
Y no entenderás que no eres un matemático sino un escamado.