Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 3009
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Vor allem aber muss theoretisch nachgewiesen werden, dass sich die Vorhersagekraft der verfügbaren Merkmale in Zukunft nicht oder nur geringfügig ändert. In der ganzen Dampfwalze ist dies der wichtigste Punkt.
Leider hat das niemand gefunden, sonst wäre er nicht hier, sondern auf tropischen Inseln))))
Ja. Selbst ein Baum oder eine Regression kann ein Muster finden, wenn es vorhanden ist und sich nicht ändert.
1. Hat noch jemand ein Lehrer-Eigenschafts-Paar mit weniger als 20% Klassifikationsfehler?
Ganz einfach. Ich kann Dutzende von Datensätzen ungeneriert erzeugen. Ich bin gerade dabei, TP=50 und SL=500 zu untersuchen. Der durchschnittliche Fehler bei der Bewertung des Lehrers liegt bei 10%. Wenn er 20% beträgt, ist es ein Pflaumenmodell.
Der springende Punkt ist also nicht der Klassifikationsfehler, sondern das Ergebnis der Addition aller Gewinne und Verluste.
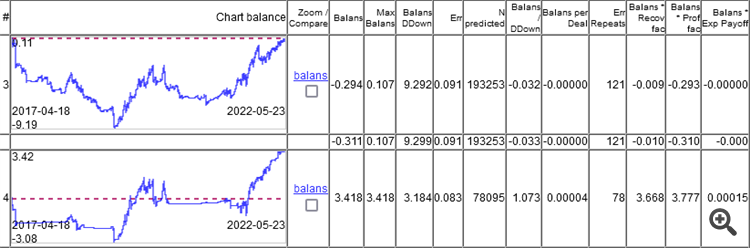
Wie Sie sehen, hat das beste Modell einen Fehler von 9,1 %, und Sie können mit einem Fehler von 8,3 % etwas verdienen.
Die Diagramme zeigen nur die OOS, die durch Walking Forward mit wöchentlicher Umschulung erzielt wurden, insgesamt 264 Umschulungen über 5 Jahre.
Es ist interessant, dass das Modell bei 0 mit einem Klassifizierungsfehler von 9,1 % arbeitete, und 50/500 = 0,1, d. h. 10 % sein sollte. Es stellt sich heraus, dass 1% die Streuung gefressen hat (Minimum pro Balken, der reale Wert wird größer sein).
Zuerst muss man erkennen, dass das Modell im Inneren voller Müll ist...
Wenn man ein trainiertes Holzmodell in die darin enthaltenen Regeln und die Statistiken über diese Regeln zerlegt.
zum Beispiel:
und analysiert die Abhängigkeit des Fehlers der Regel err von der Häufigkeit ihres Auftretens in der Stichprobe.
erhalten wir
Dann sind wir an diesem Bereich interessiert
Wo die Regeln sehr gut funktionieren, aber so selten sind, dass es Sinn macht, die Echtheit der Statistik über sie anzuzweifeln, denn 10-30 Beobachtungen sind keine Statistik
Zuerst muss man feststellen, dass das Modell innen voller Müll ist...
Wenn man ein trainiertes Holzmodell in die darin enthaltenen Regeln und die Statistiken über diese Regeln zerlegt.
zum Beispiel:
und analysieren Sie die Abhängigkeit des Fehlers der Regel err von der Häufigkeit ihres Auftretens in der Stichprobe
erhalten wir
Nur ein Lichtblick in der Dunkelheit der letzten Beiträge
Es wird einen Artikel darüber geben, wenn es einen gibt.
wird es einen Artikel darüber geben, wenn es einen gibt.
Norm, in meinem letzten Artikel ging es um die gleiche Sache. Aber wenn Ihr Weg schneller ist, ist das ein Pluspunkt.
Was meinen Sie mit "schneller"?
Was meinen Sie mit "schneller"?
In Bezug auf die Geschwindigkeit.
etwa 5-15 Sekunden bei einer 5k-Probe
etwa 5-15 Sekunden bei einer 5k-Probe.
Ich meine den gesamten Prozess von Anfang an bis zum Erhalt des TC.
Ich habe 2 Modelle, die mehrmals neu trainiert werden, also ist es nicht sehr schnell, aber es ist akzeptabel.
Und am Ende weiß ich nicht, was genau sie herausgefiltert haben.
Ich meine den gesamten Prozess von Anfang an bis zur Erteilung der Genehmigung.
Ich habe 2 Modelle, die mehrmals neu trainiert werden, also nicht sehr schnell, aber akzeptabel
und am Ende weiß ich nicht, was genau sie aussortiert haben.
Trainieren 5k.
Gültig 60k.
Modelltraining - 1-3 Sekunden
Regelextraktion - 5-10 Sekunden
Überprüfung jeder Regel (20-30k Regeln) auf Gültigkeit 60k 1-2 Minuten
Natürlich ist alles nur ein Näherungswert und hängt von der Anzahl der Merkmale und Daten ab.