Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 2476
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
es geht um die Verantwortung desselben Entwicklers - ich glaube nicht und sehe keinen Grund, irgendwelche Finanzmodelle aus Büchern/Blogs/Artikeln (und statistisch aufbereitete Verteilungen) in die Finanzanalyse einzubeziehen, wenn man Chaos approximiert/interpoliert... um die Ausgabe weiter zu extrapolieren
Ja, das ist die Grundlage, sehen Sie, die Sache ist die, dass die Menschen diese Formeln und Modelle geschaffen haben, ohne sich auf das Problem zu beziehen, sie haben versucht, etwas Allgemeingültiges zu schaffen, und dabei naiv gedacht, dass es für alles gilt. Aus irgendeinem Grund wirft jeder gerne mit Begriffen wie Laplace, Fourier, Taylor, Normalverteilung um sich und denkt, dass es aus irgendeinem Grund funktionieren muss, wenn man das alles in ein System einbaut. Ich war gut darin, ich habe die Ziolkowsky-Formel auf meinem Knie hergeleitet und niemand konnte verstehen, wie ich das gemacht habe... Ich hatte diese Erfahrung, ich war Ich habe versucht, die nächste Kerze in meinem Expert Advisor mit Hilfe von linearen Gleichungssystemen vorherzusagen und habe riesige Matrizen erstellt und die Determinanten und andere Dinge berechnet, und ich dachte, das wäre so cool, dass es niemand hat, aber als ich es getestet habe, stellte sich heraus, dass es kompletter Mist ist, Ich dachte, es wäre so cool und niemand sonst hätte es, aber als ich es getestet habe, stellte sich heraus, dass es kompletter Blödsinn war. Obwohl ich nach meiner Einschätzung im nächsten Moment zum Marktguru hätte werden sollen, war das wahrscheinlich vor 5 Jahren, ich hatte gerade die Universität beendet (übrigens kannte ich mich in Mathe und Physik sehr gut aus), ich meine, tolle Formeln und Theoreme zu kennen, macht uns nicht zu einem stärkeren Trader, und wenn wir über die praktische Seite sprechen, macht es uns am Ende schwächer... Der richtige Weg ist der umgekehrte: Man muss sich zuerst die Frage stellen, womit wir rechnen, sie mit einfachen menschlichen Begriffen beantworten und dann das Ganze in mathematische Kriterien umwandeln. Ich weiß, dass man dafür nicht über das ursprüngliche Modell nachdenken muss und darüber, wie man es aufbaut, sondern man muss vom Ende zum Anfang gehen. Wenn das Modell die richtigen Zahlen liefert, kann man danach versuchen, es zu verstehen, aber alles hängt von der KI ab, und je intelligenter das System ist, desto mehr wird es die Mathematik nerven, ich habe diese Barriere überwunden und versuche in meiner Arbeit, so viel wie möglich an die Maschine zu delegieren.
habe Ihre Antwort vorhin gefunden... Ich war vielleicht etwas voreilig mit meinem letzten Beitrag... Wahrscheinlich sollte man wirklich zumindest von einer Parabel als Funktion ausgehen, die eine Bewegung mit Geschwindigkeit und Beschleunigung beschreibt... (Ich habe diese Art von Diagrammen und Griechen (Delta und Gamma) von Optionen sogar schon irgendwo gesehen - ich kann mich nicht erinnern und ich kann sie nicht finden - und das ist auch nicht nötig - wir brauchen eine Zeitanalyse - horizontal, nicht vertikal)
Ich habe die Parabel lediglich als Beispiel dafür angeführt, wie eine unendliche Anzahl von Daten auf eine endliche Anzahl komprimiert werden kann, da es eine unendliche Anzahl von Punkten auf dem Diagramm gibt und sie auf eine Formel mit nur 3 Koeffizienten reduziert werden kann. Ich verstehe, was du denkst: Du kannst jede beliebige Funktion nehmen:
A[1]*X^0+A[2]*X^1+ ... + A [N]*X^N, handelt es sich im allgemeinen Fall um eine Taylor-Reihe (Funktionsreihe), mit der Ausnahme, dass A[i] > 0 für alle i = 1...N ist, ergibt sich im allgemeinen Fall ein konstantes Wachstum der ersten Ableitung, um es deutlich zu sagen:
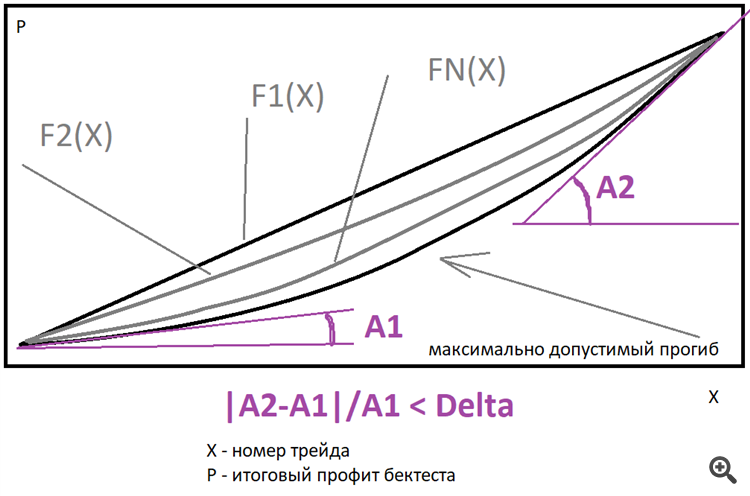
Idealerweise ist eine gerade Linie am besten, aber Sie können eine Familie von Potenzfunktionen genau der Art verwenden, die ich oben beschrieben habe, um Abweichungen zu schätzen. Sie müssen nur angeben, wie oft die endgültige Ableitung größer sein darf als die Anfangsableitung. Es ist möglich, den endgültigen Graphen in der Nähe einer solchen Familie zu approximieren, die beste Funktion zu finden und nach der Abweichung des realen Graphen von dieser Funktion zu suchen. Ich verwende nur die Gerade, aber vielleicht werde ich die Funktionalität später erweitern, sie wird einen Effizienzgewinn bringen und als Ergebnis den Bedarf an Rechenanlagen im Falle eines intelligenten Ansatzes verringern.
Evgeniy Ilin #:
mit dem richtigen Ansatz den Bedarf an Rechenleistung verringern.
Holen Sie sich einige Bibliothek auf numerische Methoden und es wird ein Schub in der Leistung, vielleicht sogar auf gpu
Holen Sie sich eine Bibliothek für numerische Methoden und es wird eine Erhöhung der Leistung, vielleicht sogar auf gpu sein
Die Idee ist nicht schlecht, aber soweit ich weiß, für vidyuha müssen Code in einer sehr seltsamen Art und Weise zu schreiben, wie alles funktioniert ein wenig anders, fertige Bibliothek ist unwahrscheinlich, zu arbeiten, höchstwahrscheinlich müssen Sie selbst zu schreiben. Übrigens, vielleicht bekomme ich es eines Tages in die Finger.
Wie immer läuft die Differenzierung also auf LOC hinaus... und die gesamte Vorhersage der Zukunft zur Zielfunktion, die aus dieser LOC abgeleitet werden soll... danke für die Bilder...
Ich werde erst einmal darüber nachdenken, wie ich Angebot und Nachfrage einschätzen kann (die tatsächliche Liquidität ist mir wichtiger als unentdeckte Regelmäßigkeiten, die ich noch nicht bereit bin, einer Maschine für statistische Wahrscheinlichkeiten zu überlassen)...
aber ich werde mich an die Verantwortung des Entwicklers erinnern, die Funktionen auszuwählen, die für ihn wichtig sind ... Und dann nach dem Muster: Eingaben normalisieren, Wahrscheinlichkeiten berechnen, wahrscheinlich clustern (wenn es viele Daten gibt), einen Gradienten bilden, alle Tiefpunkte finden (mit OLS), alle Tiefpunkte normalisieren und zu einer gemeinsamen Funktion zusammenfassen... wie ich schon sagte "bis zum Gehtnichtmehr"... aber maschinengestützt geht es schneller...
Im Idealfall ist eine gerade Linie am besten, aber Sie können auch eine Familie von Potenzfunktionen wie die oben beschriebene verwenden, um Ausreißer zu schätzen. Sie müssen nur angeben, wie oft die endgültige Ableitung größer als die Anfangsableitung sein kann.
Wird die Familie der Potenzfunktionen zu einer logarithmischen Normalverteilung oder spiegelt sie diese wider?... Entschuldigung, wenn die Frage dumm ist
Frage entfernt, lautet die Antwort wahrscheinlich nein .
In der Tat verstehe ich nicht viel davon. Sagen wir es mal so:
1) Was ist die Zielfunktion und warum brauchen Sie sie?
2) Warum brauchen Sie die Lognormalverteilung und warum glauben Sie, dass Sie sie überhaupt brauchen?
3) Ich verstehe nicht ganz, wie eine "Familie" von Funktionen zu einer einzigen prototypischen Funktion werden kann, selbst eine Lognormalverteilung.
4) Die Lognormalverteilung von was? Wie lautet die Zufallsvariable in Ihrer Verteilung?
5 ) Was ist MNC?
Versuchen Sie, die Frage in einfacher Sprache zu stellen und eine einfache Antwort zu erhalten ) Entschuldigung, wenn überhaupt )
In der Tat verstehe ich nicht viel davon. Sagen wir es mal so:
1) Was ist die Zielfunktion und warum brauchen Sie sie?
2) Warum brauchen Sie die Lognormalverteilung und warum glauben Sie, dass Sie sie überhaupt brauchen?
3) Ich verstehe nicht ganz, wie aus einer "Familie" von Funktionen eine einzige prototypische Funktion werden kann, selbst eine Lognormalverteilung.
4) Die Lognormalverteilung von was? Wie lautet die Zufallsvariable in Ihrer Verteilung?
5 ) Was ist MNC?
Versuchen Sie, eine Frage in einfacher Sprache zu stellen und eine einfache Antwort zu erhalten ) Entschuldigung, wenn überhaupt )
1) Die Ausgabe ist eine Funktion für die Vorhersage (in diesem Zusammenhang, nicht für die Ebenen des neuronalen Netzes)
2) weil es eine Asymmetrie gibt (eingeführt durch %Rate*Zeit und die Käufer/Verkäufer selbst)
3) ... weil sie vom gleichen Typ sind - warum sollte der Prototyp anders sein?...komm schon, ich sehe, dass die Leistungsverteilung ein Indikator für die umgekehrte Abhängigkeit ist
4) der Preis ist eine Zufallsvariable
5) Methode der kleinsten Quadrate
die Frage war ursprünglich (in meinem Kopf) "das kumulative Debit-Credit-Ungleichgewicht" (auch sorry für den Ausdruck) in Range (und auf dem Zeithorizont) zu bestimmen -- hier, ohne zu lernen, muss man erst mal rechnen... Aber danke für die Erinnerung an die Modellierung - ich bin kein Physiker, ich bin Ökologe - es ist einfacher für uns (ohne Funktionen und Modellierung, aber mit Verteilungen, Fakten und Wahrscheinlichkeiten; wir sagen das Ökosystem nicht voraus, obwohl es manchmal gut wäre, Risiken abzuschätzen; wir haben uns nicht tief in die Theorie eingegraben) - es war nur interessant, was wir mit diesen Wahrscheinlichkeiten später (mit Gewinn) machen könnten
In der Tat verstehe ich nicht viel davon. Sagen wir es mal so:
1) Was ist die Zielfunktion und warum brauchen Sie sie?
2) Warum brauchen Sie die Lognormalverteilung und warum glauben Sie, dass Sie sie überhaupt brauchen?
3) Ich verstehe nicht ganz, wie aus einer "Familie" von Funktionen eine einzige prototypische Funktion werden kann, selbst eine Lognormalverteilung.
4) Die Lognormalverteilung von was? Wie lautet die Zufallsvariable in Ihrer Verteilung?
5 ) Was ist MNC?
Versuchen Sie, die Frage in einfacher Sprache zu stellen, und Sie werden eine einfache Antwort erhalten (Entschuldigung, wenn überhaupt).
1) die Ziel- oder Fitnessfunktion ist ein quantitatives Maß für die Leistung Ihres Algorithmus
Wenn Sie z.B. eine Regression trainieren, ist die Zielfunktion eine Funktion/Formel, die zur Berechnung eines Fehlers für den Algorithmus verwendet wird, dasselbe gilt für den genetischen Algorithmus oder jeden anderen Algorithmus, der fast jeden MO-Algorithmus minimiert/maximiert.
https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BB%D0%B5%D0%B2%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F
5) Methode der kleinsten Quadrate
- Ich habe es - um jeden TS auf allen Indizes zu optimieren (durch Training über einen beliebigen Zeitraum nach Wahl des Entwicklers)... - um Bedingungen für die Eingabe mit minimalen Fehlern in Ihre eigene Induktion zu erhalten...
(obwohl dies andere Wahrscheinlichkeiten sind als die, an die ich als Ökologe bei der Bewertung der Umwelt und der Bedingungen gedacht habe)