
时间序列挖掘的数据标签(第4部分):使用标签数据的可解释性分解

概述
在本系列的前一篇文章中,我们提到了NHITS模型,其中我们只验证了单个变量输入的收盘价格预测。在这篇文章中,我们将讨论模型的可解释性,以及关于使用多个协变量来预测收盘价格。我们将使用不同的模型NBEATS进行演示,以提供更多的可能性。然而,需要注意的是,本文的重点应该放在模型的可解释性上,并将给出为什么也引入协变量主题的答案。这样你就可以随时使用不同的模型来验证你的想法。当然,这两个模型本质上是高质量的可解释模型,您也可以扩展到其他模型,用我文章中提到的库来验证您的想法。值得一提的是,本系列文章旨在为问题提供解决方案,在直接应用于您的真实交易之前,请仔细考虑,真实交易的实施可能需要更多的参数调整和优化方法,以提供可靠稳定的结果。前三篇文章的链接是:
- 时间序列挖掘的数据标签(第1部分):通过EA操作图制作具有趋势标记的数据集
- 时间序列挖掘的数据标签(第2部分):使用Python制作带有趋势标记的数据集
- 时间序列挖掘的数据标签(第3部分):使用标签数据的示例
目录:
关于 NBEATS
该模型已在各种期刊和网站上被广泛引用和解释。然而,为了避免您在不同的网站之间不断穿梭,我决定简单介绍一下这种模型。NBEATS可以处理任何长度的输入和输出序列,并且不依赖于时间序列的特定特征工程或输入缩放。它还可以使用多项式和傅立叶级数作为可解释配置的基函数来模拟趋势和季节分解。此外,该模型采用了对偶残差叠加拓扑,使得每个构建块都有两个残差分支,一个沿着反向预测,另一个沿着正向预测,大大提高了模型的可训练性和可解释性。哇,它看起来非常令人印象深刻!具体论文地址为:https://arxiv.org/pdf/1905.10437.pdf
1.模型架构
2.模型实施过程
输入的时间序列(dimension 是 length)被映射到低维向量(dimension 是 dim),第二部分将其映射回时间序列(length 是 length)。这一步骤也类似于AutoEncoder,它将时间序列映射到低维向量以保存核心信息,然后进行恢复。这个过程可以简单地表示为: 
该模块将生成两组展开系数,一组用于预测未来(预测),另一组用于预计过去(回溯)。这个过程可以用以下公式表示:

3.可解释性
具体来说,模型的分解是可解释的。NBEATS模型在每一层引入一些先验知识,迫使一些层学习某些类型的时间序列特征,并实现可解释的时间序列分解。实现方法是将展开系数约束到输出序列的函数形式。例如,如果希望某个层块主要预测时间序列的季节性,可以使用以下公式强制输出为季节性的:


4.协变量
在本文中,我们将引入协变量来帮助我们预测目标值。以下是协变量的定义:- static_categoricals:不随时间变化的类别变量列表。
- static_reals:不随时间变化的连续变量列表。
- time_varying_known_categoricals:随时间变化且在未来已知的分类变量列表,如假期信息。
- time_varying_known_reals:随时间变化且在未来已知的连续变量列表,如日期。
- time_varying_unknown_categoricals:随时间变化且未来未知的分类变量列表,如趋势。
- time_varying_unknown_reals:随时间变化且未来未知的连续变量列表,如上升或下降。
5.外部变量
NBEATS模型也可以引入外部变量,用外行的话来说,这些变量与我们的数据集无关,但模型会相应地发生变化。论文团队将其命名为NBEATSx,我们将不会在本文中讨论它。导入库
没什么好说的,做就行了!
import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import numpy as np import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.metrics import MQF2DistributionLoss from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json
重写 TimeSeriesDataSet 类
没什么好说的,做就行了! 至于为什么要这样做,请参阅本系列前面的文章。
class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs)
数据处理
我们在这里不再重复加载数据和数据预处理,具体解释请参考我之前三篇文章的相关内容,本文只解释了地方的相应变化。
1.数据采集
def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm
2.预处理
与之前不同的是,这里我们要讨论协变,为什么要这样做?事实上,这个模型还有其他变体,NBEATSx和GAGA。如果你对它们感兴趣,或者对我们正在使用的pytorch预测库中包含的其他模型感兴趣,了解协变量是很重要的。我们在这里简单地谈一谈。
针对我们的外汇数据柱,使用“open(开盘价)”、“high(最高价)”和“low(最低价)”数据列作为协变量。当然,您也可以自由扩展其他数据作为协变量,如MACD、ADX、RSI和其他相关指标,但请记住,它必须与我们的数据相关。您不能添加外部变量,如美联储会议记录、利率决策、非农数据等作为协变量输入,因为该模型没有解析这些数据的功能。也许有一天我会写一篇文章,重点讨论如何将外部变量添加到我们的模型中。
现在,让我们讨论如何在New_TmSrDt()类中添加协变。此类中提供了以下变量定义:
- static_categoricals (List[str])
- static_reals (List[str])
- timevaryingknown_categoricals (List[str])
- timevaryingknown_reals (List[str])
- timevaryingunknown_categoricals (List[str])
- timevaryingunknown_reals (List[str])
- timevaryingknown_categoricals
- timevaryingknown_reals
- timevaryingunknown_categoricals
- timevaryingunknown_reals
因为变量“open”、“high”和“low”根本不是类别,所以只剩下time_varying_known_reals和time_varyg_unknown_real可供选择。你可能会说,我们想预测“close”,那么每个柱的报价“open”、“high”、“low”都可以实时获得,为什么不能将其添加到time_varying_known_reals中?请仔细思考,如果你只预测一个柱的值,那么这个想法就成立了,你可以完全将它们归类为time_varying_known_reals,但如果我们想预测多个柱的数值呢?您可能只知道当前柱的数据,后面的值完全未知,因此它不适合我们文章中讨论的环境,因此我们应该将其添加到time_varying_unknown_reals中。但是,如果你只预测一个柱的“close”值,你肯定可以将其添加到time_varying_known_reals中,因此仔细考虑我们的用例是很重要的。time_varying_known_reals还有一个特殊情况。事实上,我们的每个柱都有一个固定的周期,比如M15、H1、H4、D1等,所以我们可以完全计算出要预测的柱所属的时间。所以你可以完全将时间添加为time_varying_known_reals,我们不讨论这篇文章,感兴趣的读者可以自己添加。如果要使用协变量,可以将“time_varying_unknown_reals=[”close“]”更改为“time_variaing_unknown_reals=]”close”,“high”,”open“,”low“]”。当然,我们的NBEATS版本不支持此功能!
因此,代码是:
def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, max_prediction_length=prediction_length, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training
获取学习率
没什么好说的,做就行了! 至于为什么要这样做,请参阅本系列前面的文章。
def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_
注意:此函数与Nbits之间的一些区别在于,NBeats.from_dataset()函数没有hidden_size参数。并且loss参数不能使用MQF2DistributionLoss()方法。
定义训练函数
没什么好说的,做就行了! 至于为什么要这样做,请参阅本系列前面的文章。
def train():
early_stop_callback = EarlyStopping(monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=True,
mode="min")
ck_callback=ModelCheckpoint(monitor='val_loss',
mode="min",
save_top_k=1,
filename='{epoch}-{val_loss:.2f}')
trainer = pl.Trainer(
max_epochs=ep,
accelerator="cpu",
enable_model_summary=True,
gradient_clip_val=1.0,
callbacks=[early_stop_callback,ck_callback],
limit_train_batches=30,
enable_checkpointing=True,
)
net = NBeats.from_dataset(
training,
learning_rate=lr,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
backcast_loss_ratio=0.0,
optimizer="AdamW",
stack_types = ["trend", "seasonality"],
)
trainer.fit(
net,
train_dataloaders=t_loader,
val_dataloaders=v_loader,
# ckpt_path='best'
)
return trainer 注意:此函数中的NBeats.from_dataset()要求我们添加一个可解释的分解类型变量stack_types。因此,我们使用默认值。除了这两个默认值之外,还有一个“通用”选项。
模型训练和测试
现在我们正在实现模型的训练和预测逻辑,这在上一篇文章中已经解释过了,并且没有任何变化,所以我不会过多讨论。
if __name__=='__main__': ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NHiTS.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) plt.show()
注意:运行它之前,请确保安装了 TensorBoard!这很重要,否则会发生一些莫名其妙的错误。
训练结果(运行代码时将出现10个图像,以下是一个随机图像作为示例):

Test result:

解释模型
有很多方法可以解释数据,但NBEATS模型在将预测分解为季节性和趋势方面是独特的(当然,因为本文选择了这两种预测,所以结果只能分解为这两种,但也可以有许多其他组合)。
如果您正在完成训练并希望分解预测,则可以添加以下代码:
for idx in range(10): # plot 10 examples best_model.plot_interpretation(x, raw_predictions, idx=idx)
如果要在运行预测时分解预测,可以添加以下代码:
best_model.plot_interpretation(predictions.x,predictions.output,idx=0) 结果是这样的:
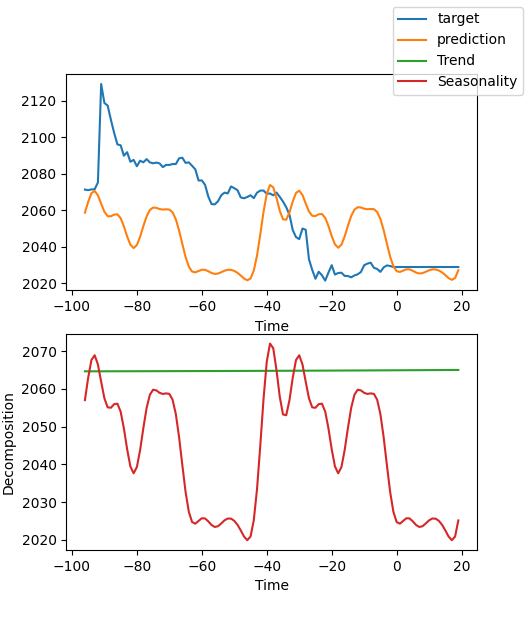
从图中可以看出,我们的结果似乎不够好,因为我们只展示了一个粗略的例子,而且我们没有仔细优化我们的模型,我们的数据关键指标仍然没有科学地指定。此外,大多数模型参数仅在默认情况下使用,没有进行调整,因此我们有很大的优化空间。
结论
在这篇文章中,我们讨论了如何使用我们的标记数据来使用NBEATS模型预测未来价格。同时,我们还证明了NBEATS模型的特殊可解释性分解函数。尽管我们的代码更改并不显著,但请注意我们在文本中对协变量的讨论。如果你真的了解不同协变量的用法,你可以将这个模型扩展到其他不同的应用场景!我相信这将大大帮助你提高EA的准确性,准确地完成你需要完成的任务。当然,本文只是一个例子。如果你想把它应用到实际交易中,它仍然有点粗糙。有很多地方需要进一步优化,所以不要在交易中直接使用它!同时,我们也提到了一些关于外部变量的信息。我不知道是否有人对这个方向感兴趣。如果我能获得足够的信息,我可能会在未来的这一系列文章中讨论如何实现它。
所以,本文到此结束,希望大家有所收获!
所有代码:
# Copyright 2021, MetaQuotes Ltd. # https://www.mql5.com import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json from torch.utils.data import DataLoader from torch.utils.data.sampler import Sampler,SequentialSampler class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs) def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, # min_encoder_length=max_encoder_length//2, max_prediction_length=prediction_length, # min_prediction_length=1, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.1, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_ def train(): early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=True, mode="min") ck_callback=ModelCheckpoint(monitor='val_loss', mode="min", save_top_k=1, filename='{epoch}-{val_loss:.2f}') trainer = pl.Trainer( max_epochs=ep, accelerator="cpu", enable_model_summary=True, gradient_clip_val=1.0, callbacks=[early_stop_callback,ck_callback], limit_train_batches=30, enable_checkpointing=True, ) net = NBeats.from_dataset( training, learning_rate=lr, log_interval=10, log_val_interval=1, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", stack_types=["trend", "seasonality"], ) trainer.fit( net, train_dataloaders=t_loader, val_dataloaders=v_loader, # ckpt_path='best' ) return trainer if __name__=='__main__': ep=200 __train=False mt_data_len=80000 max_encoder_length = 96 max_prediction_length = 20 # context_length = max_encoder_length # prediction_length = max_prediction_length batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() # lr=3e-3 trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NBeats.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NBeats.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) # best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) best_model.plot_interpretation(predictions.x,predictions.output,idx=0) plt.show()
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/13218
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。