
神经网络变得轻松(第三十六部分):关系强化学习

概述
我们将继续探索强化学习方法。 在前面的文章中,我们已经讨论过几种算法。 但我们始终使用卷积模型。 原因很简单。 在设计和测试所有先前研究的算法时,我们参考了各种电脑游戏。 因此,我们主要将各种电脑游戏的关卡图像输入模型。 卷积模型可以轻松解决相关的任务,譬如图像识别和检测这些图像上的对象。
电脑游戏中的图像没有噪点或物体失真。 这简化了识别任务。 然而,现实中没有这样的“理想”条件。 数据充满了各种噪音。 很多时候,所研究图像距理想预期甚远。 它们可以围绕场景移动(卷积网络可以轻松处理这一点),且会受到各种失真的影响。 它们也可以拉伸、压缩、或以不同的角度呈现。 对于通常的卷积模型,此任务更难处理。
在某些情况下,不仅存在两个或多个物体,那么它们的相对位置对于成功解决问题就尤为重要。 使用卷积模型很难解决这些问题。 但是它们可以通过关系模型得以很好地解决。
1. 关系强化学习
关系模型的主要优点是能够在对象之间构建依赖关系。 这样就可以构建源数据。 关系模型可以用示图的形式表示,其中对象和事件表示为节点,而关系代表对象和事件之间的依赖关系。

通过使用示图,我们可以直观地构建对象之间的依赖关系结构。 例如,如果我们想描述通道突破模式,我们可以绘制一个有顶部的通道形成的示图。 通道形成描述也可以表示为示图。 接下来,我们将创建两个通道突破节点(上边界和下边界)。 两个节点均拥有与前一个通道形成节点的相同链接,但它们彼此间没有相互连接。 为了避免在出现假突破时入场建仓,我们可以等待价格回滚到通道边界。 这就是另外两个节点,即回滚到通道上边界和下边界。 它们将与相应通道边界突破的节点建立连接。 但同样,它们彼此之间不会有连接。
所描述的结构适合示图,从而提供了数据和事件序列的清晰结构。 在构建关联规则时,我们研究过类似的东西。 但这与我们之前所用的卷积网络难以相关。
卷积网络用于识别数据中的对象。 我们可以训练模型来检测一些走势逆转点或小型趋势。 但在实践中,通道形成过程可以随着通道内趋势的不同强度而扩展。 然而,卷积模型也许无法很好地应对这种扭曲。 此外,卷积和完全连接的神经层都不能分离由不同序列的相同对象组成的两种不同形态。
还应该注意的是,卷积神经网络只能检测对象,但不能在它们之间建立依赖关系。 因此,我们需要寻找一些其它算法来学习这种依赖关系。 现在,我们回到关注度模型。 关注度模型可以将注意力集中在独立对象上,从常规数据数组中将它们挑捡出来。
“广义关注度机制”于 2014 年 9 月首次提出,旨在提高使用递归i模型的机器翻译模型的效率。 这个思路是创建一个附加的关注度层,其在处理原始数据集时收集编码器的隐藏状态。 这解决了长期记忆的问题。 序列元素之间依赖关系的分析有助于提高机器翻译的质量。
该机制操作算法包括以下迭代:
1. 创建编码器隐藏状态,并将其累积在关注度模块之中。
2. 评估每个编码器元素的隐藏状态与解码器的最后一个隐藏状态之间的成对依赖关系。
3. 将结果分数组合成单个向量,并调用 Softmax 函数对其进行归一化。
4. 通过将编码器的所有隐藏状态乘以其相应的对齐得分来计算上下文向量
5. 解码上下文向量,并将结果值与解码器的先前状态相结合。
迭代重复所有操作,直至收到句子结束信号为止。
下图展示了此解决方案的可视化效果:

不过,训练递归模型是一个相当耗时的过程。 故此,在 2017 年 3 月,在文章“关注度是您所需的一切”中提出了另一种变体。 这是 Transformer 神经网络的新架构,它不使用递归模块,而是使用新的自关注算法。 与前面讲述的算法不同,自关注分析一个序列中的配对依赖关系。 在之前的文章中,我们曾用自关注算法创建了 3 种类型的神经层。 我们将在本文中使用其中之一。 但在继续实现智能系统之前,我们研究一下自关注算法如何学习示图结构。

在自关注算法的输入中,我们期望源数据的张量,其中序列的每个元素都由一定数量的要素描述。 此类要素的数量是预先确定的,并且对于序列的所有元素都是固定的。 因此,初始数据张量以表格形式表示。 此表格的每一行都是序列中一个元素的描述。 每列对应一个要素。
所用的要素可以具有完全不同的分布。 一个要素的分布特征可能与另一个要素大不相同。 要素的绝对值及其变化对最终结果的影响也可能完全相反。 为了令数据具有可比较的形式,类似于递归层的隐藏状态,我们使用权重矩阵。 将初始数据张量的每一行乘以权重矩阵,将序列元素的描述转换为某种 d-维内部嵌入空间。 在学习过程中为指定的矩阵选择参数,允许为序列元素选择数值,将最大程度地分离,并按相似性分组。 请注意,自关注算法允许创建和训练三个这样的矩阵。 矩阵允许我们形成三种不同的源数据嵌入:Query、Key 和 Value。 Query 和 Key 向量维度是在模型创建期间设置的。 Value 向量维度对应于源数据中的要素数(对应于一个元素描述向量的大小)。
每个生成的嵌入都有自己的功能用途。 Query 和 Key 用于定义序列元素之间的相互依赖关系。 Value 定义应传递每个元素的哪些信息。
为了找到序列元素之间的依赖系数,我们需要将 Query 张量中每个序列元素的嵌入成对乘以 Key 张量中所有元素的嵌入(包括相应元素的嵌入)。 使用矩阵运算时,我们可以简单地将 Query 矩阵乘以转置的 Key 矩阵。
![]()
我们将获得的值除以 Key 嵌入维度的平方根,并在 Query 嵌入序列元素的上下文中调用 Softmax 函数进行规范化。 作为此操作的结果,我们得到了初始数据序列元素之间的依赖关系方阵。
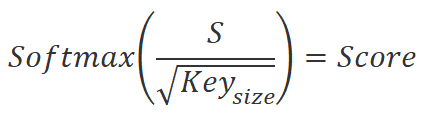
注意以下两点:
- 通过调用 Softmax 函数,我们得到了归一化在 0 到 1 范围内的依赖系数。 在这种情况下,系数的逐行总和等于 1。
- 我们使用不同的矩阵来创建 Query 和 Key。 这意味着我们为源数据序列的同一元素获得了不同的嵌入。 通过这种方法,我们最终获得了依赖系数的非对角矩阵。 在此矩阵中,A 元素对 B 元素的依赖系数和 B 元素对 A 元素的反依赖系数将不同。
我们记住这个行动的目的。 如上所述,我们希望获得一个模型,该模型可以构建各种对象和事件之间的依赖关系图。 我们使用初始数据张量中的要素向量描述每个对象或事件。 生成的依赖系数矩阵则按所需图形的表格表示。 在此矩阵中,系数的零值表示源数据的相应节点之间没有链接。 非零值确定一个节点对另一个节点值的加权影响。
但回到自关注算法。 我们将获得的依赖系数乘以 Value 张量中的相应嵌入。 我们对“加权”嵌入的结果值求和,结果向量是序列中分析元素的自关注模块的输出。 使用矩阵运算时,我们只需使用矩阵乘法函数。 通过将依赖系数的方阵乘以 Value 张量,我们得到了自关注模块结果的所需张量。
![]()
上面描述了一个简单的单目击者案例的自关注算法。 然而,在实践中,我们主要使用多目击者关注度选项。 在这样的实现中,又增加了一个降维矩阵。 它将级联张量的维度从所有目击者减少到源数据的维度。
在自关注算法结束时,我们将源数据张量与关注度模块相加,然后规范化结果值。
如您所见,自关注模块输入和输出处的张量大小相同。 但是输出张量包含归一化值,因此对结果有重大影响的要素被最大化。 与之对比,不影响结果和噪声现象的要素值将被最小化。 通常,在模型中后随若干个关注度模块来增强这种效果。
不过,关注度模块只能帮助我们找到明显的要素。 它不能提供问题的解决方案。 因此,关注度模块之后是决策模块。 该模块可以是完全连接感知器,或任何以前研究过的体系架构解决方案。
2. 利用 MQL5 实现
现在我们移步到实现,应该注意的是,我们不会重复来自原始文章“具有关系归纳偏差的深度强化学习”中的模型。 我们将使用建议的开发,并向我们的模型添加一个关系模块,即内部好奇心模块。 我们在上一篇文章中已创建了此模型的副本。 我们依据上一篇文章创建智能系统的副本,并将其保存为 RLL-Learning.mq5。
在不修改源数据层的情况下,更改我们正在训练的模型的内部架构,结果层不需要更改 EA 算法,因此我们可以简单地创建新的模型文件,而无需直接修改 EA 代码。 不过,在以前发表文章的评论中,我经常收到消息,其内容有关加载由 NetCreator 工具创建的模型时出错。 因此,在本文中,我决定回到 EA 代码中编译模型架构的讲述。
当然,您仍然可以使用 NetCreator 来创建必要的模型。 但在这种情况下,您应该注意以下几点。
在 EA 代码中,模型名称由宏替换指定。 因此,模型应与指定的格式相对应。
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
文件名由以下部分组成:
- 运行 EA 的图表的品种。 它是终端中显示品种的全名,包括前缀和后缀。
- 在 EA 参数中指定的时间帧。
- 不带扩展名的 EA 文件名。
上述所有组件都由下划线分隔。
以下扩展名之一将添加到文件名中:
- "nnw" 表示正在训练的模型
- "fwd" 代表前向模型,
- "inv" 表示逆模型。
将创建模型的所有文件保存在终端的 “Files” 目录或 “Common/Files” 中。 在这种情况下,包含文件的目录必须与程序代码中指定的 common 标志匹配。 common 标志的 true 值对应于 “common” 目录。
bool CNet::Load(string file_name, float &error, float &undefine, float &forecast, datetime &time, bool common = true)
现在我们回到智能系统的代码。 在 OnInit 函数中,我们首先初始化处理指标的类。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
然后我们尝试加载先前准备好的模型。 请注意,我正在从 “Common/Files” 目录加载模型。 这种方式允许我能在策略测试器和实时使用 EA 时无需更改。 这是因为当 EA 在策略测试器中启动时,它不会访问终端的 “Files” 目录。 出于安全原因,策略测试器为每个测试代理者创建“自己的沙箱”。 不过,每个代理者都可以访问共享文件资源,即 “Common/Files” 目录。
//--- if(!StudyNet.Load(FileName + ".icm", true)) if(!StudyNet.Load(FileName + ".nnw", FileName + ".fwd", FileName + ".inv", 6, true)) {
如果无法加载预先训练的模型,我们会为所用模型架构创建描述。 我把这个子过程在一个单独的 CreateDescriptions 方法中实现。 在此,我们调用它,并检查操作的结果。 如果失败,我们将删除不必要的对象,并以 INIT_FAILED 结果退出 EA 初始化函数。
CArrayObj *model = new CArrayObj(); CArrayObj *forward = new CArrayObj(); CArrayObj *inverse = new CArrayObj(); if(!CreateDescriptions(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; }
成功创建所有三个所需模型的描述后,我们调用模型创建方法。 确定检查操作执行结果。
if(!StudyNet.Create(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; } StudyNet.SetStateEmbedingLayer(6); delete model; delete forward; delete inverse; }
接下来,我们依据编码器结果指定我们正在训练模型的神经层,并把不再需要的已创建模型架构描述对象删除。
在下一步中,我们将模型切换到训练模式,并指定体验回放缓冲区的大小。
if(!StudyNet.TrainMode(true)) return INIT_FAILED; StudyNet.SetBufferSize(Batch, 10 * Batch);
我们设置指标缓冲区的大小。
//--- CBufferFloat* temp; if(!StudyNet.GetLayerOutput(0, temp)) return INIT_FAILED; HistoryBars = (temp.Total() - 9) / 12; delete temp; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
指定交易操作执行类型。
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
这样就完成了 EA 初始化方法。 现在我们转到 CreateDescriptions 方法,该方法创建模型体系结构的描述。
bool CreateDescriptions(CArrayObj *Description, CArrayObj *Forward, CArrayObj *Inverse)
{
在参数中,该方法接收指向三个动态数组的指针,以便写入三个模型的体系结构:
- Description — 正在训练的模型,
- Forward model,
- Inverse model.
在方法主体中,我们立即检查收到的指针。 如有必要,我们会创建新的对象实例。
//--- if(!Description) { Description = new CArrayObj(); if(!Description) return false; } //--- if(!Forward) { Forward = new CArrayObj(); if(!Forward) return false; } //--- if(!Inverse) { Inverse = new CArrayObj(); if(!Inverse) return false; }
我们再次控制操作执行过程。 如果失败的话,我们在完成该方法时返回 False 结果。
成功创建必要的对象后,我们移入下一个子过程,在其中我们描述正在创建的模型的体系结构。 我们从训练模型架构开始。 我们清除动态数组以便写入模型架构的描述,并准备一个变量来写入指向一个神经层描述对象 ClayerDescription 的指针。
//--- Model
Description.Clear();
CLayerDescription *descr;
像往常一样,我们首先创建源数据的神经层。 作为输入数据层,我们将使用没有激活函数的全连接神经层。 我们指定神经层的大小等于传输到模型的值的数量。 请注意,为了描述每个历史数据烛条,我们传输 12 个值。 这些是烛台的描述和所分析指标的值。 此外,我们还传递账户状态和持仓量。 这又增加了 9 个值。
神经层描述算法将针对每个神经层重复。 它由三个步骤组成。 首先,我们创建神经层描述对象的新实例。 不要忘记检查操作结果,因为如果在创建新对象时出错,我们可能会在访问不存在的对象时遇到严重错误。
接下来,我们设置神经层的描述。 在此,指定参数的数量因神经层的类型而异。 对于输入数据层,我们指定神经层类型、神经层中的元素数量、参数优化类型和激活函数。
在指定了神经层的所有必要参数后,我们把指向神经层描述对象的指针添加到模型架构描述的动态数组之中。
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = HistoryBars * 12 * 9; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
根据我在训练神经网络方面的经验,使用归一化的初始数据时,学习过程更加稳定。 为了在训练和使用期间规范化数据,我们将使用批量规范化层。 我们将在源数据层之后立即创建它。
此处,我们再次创建神经层描述对象的新实例,并检查操作的结果。 接下来,指定要创建的神经层的类型 - defNeuronBatchNormOCL,即前一个神经层大小级别的元素数, 和规范化批量大小。 之后,我们将指向神经层描述对象的指针添加到模型架构描述的动态数组之中。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
规范化数据后,我们将创建一个预处理模块。 在此,我们将采用卷积神经层来查找源数据中形态。
和以前一样,我们创建一个新的 ClayerDescription 神经层描述对象实例,指定 defNeuronConvOCL 神经层类型,指定分析数据的窗口等于 3 个元素,并将数据窗口步长设置为 1。 采用这些参数,一个过滤器中的元素数量将比前一层的尺寸少 2 个。 为了最大限度地发挥潜力,我在这个神经层中创建了 16 个过滤器。 似乎过滤器太多,但我想令模型尽可能灵活。 我采用 LeakReLU 作为激活函数。 为了优化参数,我们将使用 Adam。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count - 2; descr.window = 3; descr.step = 1; descr.window_out = 16; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
下一步不是标准的。 在卷积层之后,我们通常使用子采样层进行降维。 但这次我们操控时间序列。 除了值之外,我们还需要跟踪要素变化动态。 为此,我决定进行一个实验,并在卷积层之后使用 LSTM 模块。 当然,它的尺寸会小于卷积层的输出。 但是由于递归模块的架构,我们希望得到降维,就要考虑到系统的先前状态。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 300; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
为了揭示更复杂的结构,我们将重复卷积和递归神经层模块。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 100; descr.window = 3; descr.step = 3; descr.window_out = 10; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 100; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
接下来,我们移步讨论训练模型的关系模块。 在此,我们将使用来自多层多目击者自关注模块。 为此,我们指定了 defNeuronMLMHAttentionOCL 神经层类型。 初始数据序列的元素数量将等于分析蜡烛的数量。 在这种情况下,一个烛台描述要素的数量将为 5。
不要把模型输入输入处描述一根烛条的符号数量,与关系模块混淆。 由于关系模块之前是由卷积和递归神经层执行的数据预处理。
Keys 矢量大小将等于 16。 目击者数量将等于 64。 与卷积神经网络的过滤器类似,我指示更多的目击者,以便全面分析当前的市场情况。
我们将创建四个这样的层。 但是我们不会将这个神经层描述保存四次。 取而代之,我们将 layers 参数设置为等于 4。
与之前的所有情况一样,我们将使用 Adam 方法来优化参数。 在这种情况下,我们不指定激活函数,因为所有激活函数都由神经层构造算法指示。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = 20; descr.window = 5; descr.step = 64; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
为了完成模型架构的描述,我们需要指出完全参数化的分位数函数的层。 在该神经层的描述中,我们仅指出神经层类型 defNeuronFQF、动作空间、分位数和参数优化方法。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
与描述训练模型的体系结构相关的子过程至此结束。 现在我们需要正向和逆向模型。 我们将采用上一篇文章中的架构。 为了令智能系统正常工作,我们需要将它们的描述添加到我们的方法之中。 描述子过程与上述过程相同。
首先,我们清除前向模型架构描述的动态数组。 然后我们添加源数据神经层。 对于前向模型,输入数据层的大小等于主模型编码器输出的级联向量大小,以及可能的代理者操作空间。
//--- Forward Forward.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 104; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
接下来是具有 LReLU 激活函数和 Adam 优化方法的 500 个元素的完全连接的神经层。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
在 Forward 模块的输出端,我们期望在模型编码器输出端获得下一个状态。 因此,该模型由一个完全连接的神经层完成,其中神经元的数量等于模型编码器输出处的向量大小。 不使用激活函数。 同样,我们利用 Adam 作为参数优化方法。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 100; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
逆模型构造方法与此类似。 唯一的区别是我们将两个后续状态的级联向量馈送到这个模块当中。 因此,源数据层的大小是模型编码器输出大小的两倍。
//--- Inverse Inverse.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 200; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
第二个神经层与前向模型的神经层相同。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
我们期望在逆模型的输出端采取动作。 因此,下一个神经层的大小等于可能的代理者动作的空间。 此层不使用激活功能。 我们用下一个 Softmax 层替代。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 4; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 4; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- return true; }
其余的 EA 代码与我们在上一篇文章中研究的相同。 附件中提供了完整的 EA 代码,以及所有用到的函数库。
3. 测试
该模型在策略测试器中采用 EURUSD 历史数据进行训练和测试,时间帧为 H1。 指标采用默认参数。

模型训练显示策略测试器中的余额增长。 虽然平均每 2 笔盈利交易就有 2 笔亏损交易,但盈利交易的份额为 53.7%。 总的来说,我们看到余额和净值图表的增长相当均匀,因为平均盈利交易比平均亏损交易高 12.5%。 盈利因子为 1.31,恢复因子为 2.85。


结束语
在本文中,我们熟悉了强化学习领域的关系方式。 我们在模型中添加了一个关系模块,并使用内在好奇心模块对其进行了训练。 试验结果验证了该方法在模型训练中的可行性。 这些模型可以用于创建可盈利 EA 的基础。
尽管所呈现的 EA 可以执行交易操作,但它尚未准备好在真实交易中运用。 该 EA 仅用于评估目的。 在实盘运用之前,需要在所有可能的条件下进行细致改进和全面测试。
参考文献列表
- 通过共同学习对齐和翻译的神经机器翻译
- 基于关注神经机器翻译的有效方法
- 关注就是您所需要的全部
- 具有关系归纳偏差的深度强化学习
- 神经网络变得轻松(第八部分):关注机制
- 神经网络变得轻松(第十部分):多目击者关注
- 神经网络变得轻松(第十一部分):自 GPT 获取
- 神经网络变得轻松(第三十五部分):内在好奇心模块
本文中用到的程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | RRL-learning.mq5 | 智能交易系统 | 模型训练 EA |
| 2 | ICM.mqh | 类库 | 模型规划类库 |
| 3 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 4 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/11876