
Redes neurais de maneira fácil (Parte 36): Modelos relacionais de aprendizado por reforço

Introdução
Neste artigo, continuamos nosso estudo sobre métodos de aprendizado por reforço. Em textos anteriores, exploramos vários algoritmos. No entanto, sempre utilizamos modelos convolucionais. E isso não é uma surpresa. Na concepção e teste de todos os algoritmos analisados anteriormente, utilizamos variados jogos de computador. E, na sua maioria, a entrada para os modelos era a imagem dos níveis de diversos jogos de computador. As tarefas de reconhecimento de imagens e detecção de diferentes objetos são facilmente solucionáveis por modelos convolucionais.
A imagem das cenas de jogos de computador é livre de ruídos e distorções de objetos. Isso simplifica seu reconhecimento. No entanto, na situação real, estamos desprovidos dessas condições "assépticas". Nossos dados estão repletos de todo tipo de ruído. E frequentemente, as imagens estudadas estão distantes das expectativas ideais. Elas podem estar movimentadas pela cena (tarefa facilmente resolvida pelas redes convolucionais). Também podem estar submetidas a distorções: estendidas ou compactadas, sob um ângulo diferente. Com esse tipo de desafio, os modelos convolucionais tradicionais têm maior dificuldade.
Existem cenários nos quais, para uma resolução bem-sucedida do problema, é crucial não apenas a presença de dois ou mais objetos, mas também a sua disposição relativa. E tais problemas se tornam complexos de resolver com a utilização exclusiva de modelos convolucionais. Porém, eles são eficientemente resolvidos por modelos relacionais.
1. Aprendizado por reforço relacional
A principal vantagem dos modelos relacionais é a capacidade de estabelecer relações entre objetos, possibilitando a estruturação de dados brutos. O modelo relacional pode ser mais claramente ilustrado na forma de gráficos. Os objetos e eventos são representados como nós. E as conexões evidenciam as dependências entre os objetos e eventos pertinentes.

O uso de gráficos nos possibilita estabelecer de forma clara a estrutura das dependências entre os objetos. Por exemplo, se desejamos descrever um padrão de ruptura de canal, construiremos um gráfico cujo topo seja a formação do canal. A descrição da formação do canal também pode ser apresentada na forma de um gráfico. Em seguida, criaremos 2 nós de ruptura do canal (limite superior e inferior). Ambos os nós terão as mesmas conexões com o nó de formação do canal anterior, mas não estão conectados entre si. Para prevenir a entrada na posição durante uma falsa ruptura, podemos aguardar um retrocesso até a borda do canal. Estes serão mais dois nós de retrocesso para os limites superior e inferior do canal, que terão conexões para os nós que rompem o limite do canal correspondente. Mas, novamente, eles não terão conexões entre si.
A estrutura descrita se ajusta bem ao gráfico e proporciona uma organização clara dos dados e da sequência de eventos. Analisamos algo semelhante ao elaborar as regras de associação. Mas isso é difícil de harmonizar com as redes convolucionais que usávamos anteriormente.
As redes convolucionais parecem ser utilizadas para identificar objetos nos dados. Podemos treinar o modelo para destacar pontos de reversão de movimento ou tendências menores. Contudo, na prática, o processo de formação do canal pode se estender ao longo do tempo com intensidades variáveis de tendências dentro do canal. E os modelos convolucionais nem sempre lidam bem com essas distorções. Além disso, nem as camadas neurais convolucionais nem as totalmente conectadas conseguem diferenciar dois padrões distintos que consistem nos mesmos objetos numa sequência diferente.
É importante salientar que as redes neurais convolucionais só conseguem detectar objetos. No entanto, não conseguem estabelecer dependências entre eles. Portanto, precisamos encontrar um outro algoritmo capaz de aprender essas dependências. E é aqui que precisamos nos lembrar dos mecanismos de atenção. São eles que permitem focar em objetos individuais, destacando-os do conjunto geral de dados.
Em setembro de 2014, foi proposto o "mecanismo de atenção generalizada" para aprimorar a eficiência dos modelos de tradução automática que utilizam modelos recorrentes. A ideia consistia em adicionar uma camada de atenção adicional que capturava os estados ocultos do codificador durante o processamento da sequência de entrada. Isso solucionou o problema da memória de longo prazo. Além disso, a análise das dependências entre os elementos da sequência contribuiu para melhorar a qualidade da tradução automática.
O algoritmo para esse mecanismo incluía as seguintes iterações:
1. Criar os estados ocultos do codificador e acumulá-los em um bloco de atenção.
2. Avaliar as dependências em pares entre os estados ocultos de cada elemento do codificador e o último estado oculto do decodificador.
3. As estimativas resultantes são combinadas em um único vetor e normalizadas usando a função Softmax.
4. Calcular o vetor de contexto multiplicando todos os estados ocultos do codificador pelas pontuações de alinhamento correspondentes.
5. Decodificar o vetor de contexto e combinar o valor resultante com o estado anterior do decodificador.
Todas as iterações são realizadas até que o sinal de fim de frase seja recebido.
A figura abaixo apresenta a solução proposta.

No entanto, o treinamento de modelos recorrentes é um processo bastante complexo e, em junho de 2017, no artigo "Attention Is All You Need", foi proposta uma nova arquitetura de rede neural chamada Transformer. Nessa arquitetura, abandonou-se o uso de blocos recorrentes e introduziu-se um novo algoritmo de atenção chamado Self-Attention. Ao contrário do algoritmo descrito anteriormente, o Self-Attention analisa as dependências em pares dentro de uma única sequência. Em artigos anteriores, já desenvolvemos 3 tipos de camadas neurais utilizando o algoritmo de Self-Attention. Neste artigo, utilizaremos uma dessas camadas. Antes de começarmos a implementar o EA, vamos entender como o algoritmo Self-Attention pode aprender a estrutura do gráfico.

Na entrada do algoritmo Self-Attention, esperamos um tensor de dados brutos, No qual cada elemento da sequência é descrito por um número de atributos. O número desses atributos é pré-definido e fixo para todos os elementos da sequência. Assim, o tensor de dados de entrada se apresenta como uma tabela. Cada linha desta tabela representa a descrição de um elemento da sequência, e cada coluna corresponde a um atributo distinto.
Os atributos usados podem ter distribuições completamente diferentes. As características de distribuição de um atributo podem ser muito diferentes das de outro atributo. E também os efeitos no resultado final dos valores absolutos das características e suas alterações podem ser totalmente opostos. Para tornar os dados comparáveis, por analogia com o estado latente da camada recorrente, usamos uma matriz de pesos. A multiplicação de cada linha do tensor de dados brutos pela matriz de peso converte a descrição do elemento da sequência em um espaço de incorporação interno de dimensão d. E a seleção dos parâmetros dessa matriz no processo de aprendizado nos permite escolher os valores que tornam os elementos da sequência o máximo possível separáveis entre si e agrupados por similaridade. É importante dizer que o algoritmo Self-Attention permite a criação e o treinamento de três dessas matrizes, que permitem formar três incorporações diferentes dos dados de entrada: Query, Key e Value. As dimensões dos vetores Query e Key são definidas durante a criação do modelo. As dimensões do vetor Value corresponde ao número de atributos nos dados de entrada (o tamanho do vetor que descreve um elemento da sequência).
Cada uma das incorporações geradas tem uma finalidade funcional diferente. Query e Key são usadas para determinar as interdependências entre os elementos de uma sequência. Já Value determina quais informações de cada elemento da sequência devem ser passadas posteriormente.
Para determinar as taxas de dependência entre os elementos da sequência, precisamos multiplicar par a par a incorporação de cada elemento da sequência do tensor Query pela incorporação de todos os elementos do tensor Key (incluindo a incorporação do elemento correspondente). Ao usar operações matriciais, só precisamos multiplicar a matriz Query pela matriz Key transposta.
![]()
Os valores obtidos serão divididos pela raiz quadrada da dimensionalidade da incorporação key. E serão normalizados pela função Softmax, considerando os elementos da sequência de incorporação Query. Como resultado dessa operação, obteremos uma matriz quadrada que representa as dependências entre os elementos da sequência de dados de entrada.
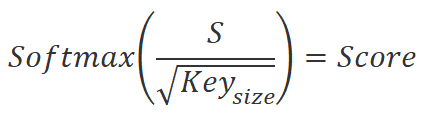
Existem dois aspectos relevantes a serem considerados aqui:
- Por meio da função Softmax, obtivemos índices de dependência normalizados que variam de 0 a 1. A soma linear dos coeficientes resulta em 1.
- Utilizamos diferentes matrizes para criar as incorporações Query e Keys. Dessa forma, obtemos diferentes incorporações para o mesmo elemento da sequência de dados de entrada. Essa abordagem nos permite ter uma matriz de coeficientes de dependência não diagonal. Nessa matriz, o coeficiente de dependência do elemento A em relação ao elemento B e o coeficiente de dependência inversa do elemento B em relação ao elemento A são diferentes.
Neste ponto, vale a pena relembrar o objetivo dessa ação. Conforme mencionado acima, desejamos ter um modelo capaz de criar gráficos de dependências entre diferentes objetos e eventos. Descrevemos cada objeto ou evento usando vetores de atributos no tensor de dados de entrada. A matriz de coeficientes de dependência que obtemos é a representação tabular do gráfico que procuramos. Os valores zero dos coeficientes indicam a ausência de conexões entre os nós correspondentes nos dados de entrada, enquanto os valores diferentes de zero determinam o efeito ponderado de um nó sobre o valor de outro.
No caso do algoritmo Self-Attention, multiplicamos os coeficientes de dependência obtidos pelas incorporações correspondentes no tensor Value. Os valores de incorporação "ponderados" resultantes são somados, e o vetor resultante é a saída do bloco Self-Attention para o elemento de sequência analisado. Para manusear operações matriciais, utilizamos a multiplicação de matrizes. Multiplicar a matriz de dependência ao quadrado pelo tensor Value nos dará o tensor de resultados do bloco Self-Attention desejado.
![]()
O algoritmo Self-Attention descrito acima é no caso simples de uma única cabeça de atenção. No entanto, na prática, a variante de atenção com várias cabeças é mais comumente usada. Nessa implementação, é adicionada uma matriz adicional de redução de dimensionalidade, que reduz a dimensionalidade do tensor concatenado de todas as cabeças de atenção para a dimensionalidade dos dados de entrada.
Na etapa final do algoritmo Self-Attention, o tensor de dados de entrada é somado ao resultado do bloco de atenção e, em seguida, os valores resultantes são normalizados.
É importante observar que, tanto na entrada quanto na saída do bloco Self-Attention, temos tensores de tamanho igual. Apenas na saída, obtemos um tensor de valores normalizados, em que os atributos que têm um impacto significativo no resultado são maximizados. Os valores dos atributos que não têm influência no resultado e os fenômenos de ruído são minimizados. Normalmente, os modelos usam várias unidades de atenção de acompanhamento para reforçar esse efeito.
No entanto, o bloco de atenção por si só é capaz apenas de nos ajudar a destacar os atributos essenciais. Ele não nos fornece uma solução para o problema proposto. Portanto, após o bloco de atenção, é elaborado um bloco de tomada de decisão. Pode ser um perceptron totalmente conectado ou qualquer outra solução a nível de arquitetura estudada anteriormente.
2. Implementação usando MQL5
Ao iniciar a implementação, é preciso dizer que não repetiremos o modelo do artigo original "Deep reinforcement learning with relational inductive biases". Apenas usaremos o trabalho proposto e adicionaremos um módulo relacional ao nosso modelo usando o módulo de curiosidade interna, que criamos no artigo anterior. Criaremos uma cópia do EA do artigo anterior e nomearemos o arquivo como "RLL-Learning.mq5".
Como a alteração da arquitetura interna do modelo ensinado sem alterar a camada de dados de entrada e a camada de saída não exige nenhuma alteração no algoritmo do EA, poderíamos simplesmente criar novos arquivos de modelo e não fazer alterações diretamente no código do EA. Mas, nos últimos artigos, tenho recebido muitas perguntas nos comentários sobre erros no carregamento de modelos criados usando a ferramenta NetCreator. Por isso, decidi voltar a redigir descrições da arquitetura do modelo no código do EA neste artigo.
É claro que você ainda pode usar a ferramenta NetCreator para criar os modelos necessários. Mas, nesse caso, preste atenção aos aspectos descritos a seguir.
No código do EA, o nome do arquivo do modelo é especificado por meio de uma macro substituição. Portanto, o modelo que você criar deve ter o formato especificado.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
O nome do arquivo é composto por:
- O nome do instrumento, no gráfico em que o Expert Advisor está sendo executado. O nome completo do instrumento em seu terminal, incluindo prefixos e sufixos.
- O período de tempo especificado nos parâmetros do EA.
- O nome do arquivo do Expert Advisor sem uma extensão.
Todos os componentes mencionados acima são separados por um sublinhado.
Ao nome do arquivo é adicionada uma extensão:
- "nnw" - para o modelo a ser treinado,
- "fwd" - para o modelo avançado (forward model),
- "inv" - para o modelo inverso (inverse model).
Os arquivos de todos os modelos criados devem ser colocados no diretório "Files" do seu terminal ou em "Common/Files". O diretório com os arquivos deve corresponder ao sinalizador common que você especificou no código do programa. Quando o valor do sinalizador common é true, ele corresponde ao diretório "Common/Files".
bool CNet::Load(string file_name, float &error, float &undefine, float &forecast, datetime &time, bool common = true)
Mas vamos voltar ao código do nosso EA. Na função OnInit, primeiro inicializamos as classes para trabalhar com indicadores.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
Em seguida, tentamos carregar os modelos previamente preparados. Observe que eu tento fazer isso a partir da pasta "Common/Files". Essa abordagem me permite usar o Expert Advisor inalterado no testador de estratégia e em tempo real. A questão é que, quando o EA é executado no testador de estratégias, ele não acessa o diretório Files do terminal. Por motivos de segurança, o testador de estratégias cria "sua própria área restrita" para cada agente de teste. Além disso, cada agente tem acesso ao diretório "Common/Files".
//--- if(!StudyNet.Load(FileName + ".icm", true)) if(!StudyNet.Load(FileName + ".nnw", FileName + ".fwd", FileName + ".inv", 6, true)) {
No caso de carregamento malsucedido de modelos previamente preparados, criamos uma descrição da arquitetura dos modelos usados. Coloquei esse subprocesso em um método CreateDescriptions separado. Aqui, apenas o chamamos e verificamos o resultado. Se falharmos, removeremos os objetos desnecessários e sairemos da função de inicialização do EA com o resultado INIT_FAILED.
CArrayObj *model = new CArrayObj(); CArrayObj *forward = new CArrayObj(); CArrayObj *inverse = new CArrayObj(); if(!CreateDescriptions(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; }
Assim que todos os três modelos necessários tiverem sido criados com sucesso, chamamos o método de criação do modelo. E verificamos o resultado das operações do método.
if(!StudyNet.Create(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; } StudyNet.SetStateEmbedingLayer(6); delete model; delete forward; delete inverse; }
Em seguida, especificamos a camada neural do modelo treinado com os resultados do codificador e excluímos os objetos de descrição de arquitetura dos modelos criados que não são mais necessários.
A próxima etapa é colocar o modelo no modo de treinamento e especificar o tamanho do buffer de experiência.
if(!StudyNet.TrainMode(true)) return INIT_FAILED; StudyNet.SetBufferSize(Batch, 10 * Batch);
Definimos o tamanho dos buffers de indicador.
//--- CBufferFloat* temp; if(!StudyNet.GetLayerOutput(0, temp)) return INIT_FAILED; HistoryBars = (temp.Total() - 9) / 12; delete temp; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
E especificamos o tipo de execução da operação de negociação.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
Desse modo, concluímos o método de inicialização do Expert Advisor. E agora vamos trabalhar com o método de criação de descrição de arquitetura de modelos CreateDescriptions.
bool CreateDescriptions(CArrayObj *Description, CArrayObj *Forward, CArrayObj *Inverse)
{
Nos parâmetros desse método, obtemos ponteiros para três arrays dinâmicos que armazenarão as arquiteturas dos três modelos criados:
- Description — modelo a ser treinado,
- Modelo avançado,
- Modelo inverso.
No corpo do método, verificamos logo os ponteiros obtidos. E, se necessário, criamos novas instâncias dos objetos.
//--- if(!Description) { Description = new CArrayObj(); if(!Description) return false; } //--- if(!Forward) { Forward = new CArrayObj(); if(!Forward) return false; } //--- if(!Inverse) { Inverse = new CArrayObj(); if(!Inverse) return false; }
Simultaneamente, controlamos o fluxo de operações. E, em caso de falha, encerramos o método com o resultado False.
Uma vez que os objetos necessários tenham sido criados com sucesso, passamos ao subprocesso de descrever diretamente a arquitetura dos modelos que estão sendo criados. Primeiro, descreveremos a arquitetura do modelo a ser treinado. Limpamos o array dinâmico para escrever a descrição da arquitetura do modelo e preparamos uma variável para escrever um ponteiro para o objeto de descrição de camada neural CLayerDescription.
//--- Model
Description.Clear();
CLayerDescription *descr;
Como de costume, primeiro criamos uma camada neural de dados de entrada. Como uma camada de dados de entrada, usaremos uma camada neural totalmente conectada sem uma função de ativação. O tamanho da camada neural que especificamos é igual ao número de valores que são transferidos para o modelo. É importante lembrar que, para cada vela nos dados históricos, passaremos 12 valores, entre eles estão a descrição da própria vela e a descrição do modelo. Além disso, passaremos o saldo da conta e o volume das posições abertas, adicionando, assim, mais 9 valores.
O algoritmo para descrever a camada neural será repetido para cada camada neural e consiste em três etapas. Primeiro, criamos uma nova instância do objeto de descrição de camada neural. E não nos esquecemos de verificar o resultado da operação. Porque se cometermos um erro ao criar um novo objeto, corremos o risco de cometer o erro crítico de acessar um objeto inexistente.
Em seguida, definimos a descrição da camada neural. O número de parâmetros que especificamos aqui varia de acordo com o tipo de camada neural criada. Para a camada de dados de entrada, especificamos o tipo de camada neural, o número de elementos na camada neural, o tipo de parâmetros de otimização e a função de ativação.
Depois de inserir todos os parâmetros necessários da camada neural, adicionamos um ponteiro para o objeto de descrição de camada neural no array dinâmico de descrição de arquitetura do modelo.
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = HistoryBars * 12 * 9; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
A experiência com o treinamento de redes neurais sugere que o processo de treinamento é mais estável quando os dados de entrada são normalizados. Para a normalização dos dados no treinamento e na prototipagem, usaremos a camada de normalização em lote. Nós a criaremos logo após a camada de dados de entrada.
Aqui, como antes, primeiro criamos uma nova instância do objeto de descrição de camada neural e verificamos o resultado da operação. Em seguida, especificamos o tipo de camada neural criada defNeuronBatchNormOCL. O número de elementos corresponde ao tamanho da camada de neurônios anterior. E o tamanho do pacote de normalização. Depois disso, adicionamos um ponteiro para o objeto de descrição de camada neural ao array dinâmico de descrição de arquitetura de modelo.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Após a normalização dos dados, criamos um bloco de pré-processamento. Neste caso, usaremos camadas neurais convolucionais para procurar padrões nos dados de entrada.
Como antes, criamos uma nova instância do objeto de descrição de camada neural CLayerDescription. Especificamos o tipo de camada neural defNeuronConvOCL. Especificamos a janela de dados de 3 elementos. O passo da janela de dados é definido como 1. Com esses parâmetros, o número de elementos em um filtro será 2 a menos do que o tamanho da camada anterior. Para maximizar o potencial, criei 16 filtros nessa camada neural. Esse número de filtros parece excessivo. Mas eu queria tornar o modelo o mais flexível possível. Usei o LeakReLU como função de ativação. Já para a otimização dos parâmetros, usarei o Adam.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count - 2; descr.window = 3; descr.step = 1; descr.window_out = 16; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
A próxima etapa é bem diferente do convencional. Após a camada de convolução, estamos acostumados a usar uma camada de subamostra para redução de dimensionalidade. Mas, neste caso, estamos lidando com séries temporais. E, além dos valores em si, precisamos rastrear a dinâmica da mudança nos atributos. E, para isso, decidi fazer um experimento e colocar um bloco LSTM após a camada convolucional. Logicamente, seu tamanho será menor do que a saída da camada convolucional. Porém, graças à arquitetura de bloco recorrente, esperamos obter uma redução da dimensionalidade com uma visão retrospectiva cautelosa dos estados anteriores do sistema.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 300; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Para revelar estruturas mais complexas, repetiremos o bloco de camadas neurais convolucionais e recorrentes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 100; descr.window = 3; descr.step = 3; descr.window_out = 10; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 100; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Em seguida, chegamos ao bloco relacional do nosso modelo de treinamento. Aqui, usaremos o bloco proveniente do Self-Attention multicamada e multicabeça. Para isso, especificaremos o tipo de camada neural defNeuronMLMHAttentionOCL. Especificaremos o número de elementos da sequência de dados de entrada igual ao número de velas a serem analisadas. Nesse caso, o número de atributos da descrição de uma vela será igual a 5.
Não confunda o número de atributos da descrição de uma vela na entrada do modelo e na entrada do bloco relacional. Lembre que, antes do bloco relacional, foi feito o processamento inicial dos dados por camadas neurais convolucionais e recorrentes.
O tamanho do vetor Keys é definido como 16. E vamos definir o número de cabeças de atenção como 64. Assim como nos filtros da rede neural convolucional, especifiquei um número superestimado de cabeças de atenção para analisar minuciosamente a situação atual do mercado.
Criaremos 4 dessas camadas. Mas não salvaremos a descrição dada da camada neural 4 vezes. Em vez disso, especificaremos o parâmetro layers como 4.
Como em todos os casos anteriores, usaremos o Adam como método de otimização de parâmetros. É importante ressaltar que a função de ativação não é especificada aqui, pois todas as funções de ativação são determinadas pelo algoritmo para a construção da camada neural.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = 20; descr.window = 5; descr.step = 64; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Para concluir a descrição da arquitetura de modelo treinado, resta-nos especificar a camada de função quantil totalmente parametrizada. Na descrição dessa camada neural, especificamos apenas o tipo de camada neural defNeuronFQF, o espaço de ação, o número de quantis e o método de otimização de parâmetros.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Com isso, concluímos o subprocesso de descrição de arquitetura de modelo treinado. Mas ainda precisamos dos modelos Forward e Inverse. Sua arquitetura foi totalmente retirada do artigo anterior. Mas precisamos adicionar sua descrição ao nosso método para que ele funcione corretamente. O subprocesso de descrição é exatamente igual ao descrito acima.
Primeiro, limpamos o array dinâmico que descreve a arquitetura do modelo Forward. E adicionamos uma camada neural de dados de entrada. Para o modelo Forward, o tamanho da camada de dados de entrada é igual ao vetor concatenado do tamanho da saída do codificador do modelo principal e do espaço de possíveis ações do agente.
//--- Forward Forward.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 104; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Em seguida, temos uma camada neural totalmente conectada de 500 elementos com a função de ativação LReLU e o método de otimização de Adam.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Na saída do bloco Forward, esperamos obter o próximo estado na saída do codificador do modelo. Dessa forma, finalizamos esse modelo com uma camada neural totalmente conectada com o número de neurônios igual ao tamanho do vetor na saída do codificador do modelo. Não usamos a função de ativação. E, como antes, usamos Adam como método de otimização de parâmetros.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 100; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
A mesma abordagem é usada para criar o modelo inverso. Só que na entrada alimentamos esse bloco com o vetor concatenado de dois estados sucessivos. Assim, o tamanho da camada de dados de entrada é 2 vezes o tamanho da saída do codificador do modelo.
//--- Inverse Inverse.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 200; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
A segunda camada neural é semelhante à camada do modelo Forward.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
Na saída do modelo inverso, esperamos obter uma ação. Por isso, o tamanho da próxima camada neural é igual ao espaço de ações aceitáveis do agente. Só que essa camada não usa a função de ativação. Em vez disso, usaremos a camada Softmax subsequente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 4; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 4; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- return true; }
O restante do código do Expert Advisor foi transferido do artigo anterior sem nenhuma alteração. O código completo do Expert Advisor e todas as bibliotecas usadas podem ser encontrados no anexo.
3. Teste
O modelo desenvolvido foi treinado e posto à prova no testador de estratégias usando dados históricos do EURUSD no período de tempo H1. Os parâmetros do indicador foram usados por padrão.

Como resultado do treinamento do modelo, conseguimos obter um aumento no saldo que é visto no testador de estratégia. Apesar do fato de que, em média, há 2 negociações perdedoras para cada 2 lucrativas, e a participação das negociações lucrativas foi de 53,7%. Em geral, podemos observar um crescimento bastante uniforme do gráfico de saldo e patrimônio líquido, já que a média das negociações com lucro é 12,5% maior do que a média das negociações com prejuízo. O fator de lucro foi de 1,31 e o fator de recuperação chegou a 2,85.


Considerações finais
Neste documento, apresentamos o uso de enfoques relacionais no aprendizado por reforço. Adicionamos um bloco relacional ao modelo e o treinamos usando o módulo de curiosidade interno. Os resultados dos testes demonstraram a capacidade dessa abordagem para o treinamento de modelos e a criação de EAs lucrativos com base neles.
Gostaria de salientar que o Expert Advisor apresentado no artigo é capaz de realizar operações de negociação. No entanto, não está pronto para ser usado em negociações reais. O Expert Advisor é apresentado apenas para fins de demonstração da tecnologia. Antes de utilizar o Expert Advisor em contas reais, é necessário um aprimoramento significativo e testes rigorosos em diversas condições.
Referências
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Attention Is All You Need
- Deep reinforcement learning with relational inductive biases
- Redes neurais de maneira fácil (Parte 8): mecanismos de atenção
- Redes neurais de maneira fácil (Parte 10): atenção multi-cabeça
- Redes neurais de maneira fácil (Parte 11): uma visão sobre GPT
- Redes neurais de maneira fácil (Parte 35): módulo de curiosidade intrínseca
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | RRL-learning.mq5 | EA | EA para treinamento do modelo. |
| 2 | ICM.mqh | Biblioteca de classe | Biblioteca da classe de elaboração de modelo |
| 3 | NeuroNet.mqh | Biblioteca de classe | Biblioteca das classes para a criação de uma rede neural |
| 4 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/11876
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Oi Dmitry Gizlyk,
Obrigado por seus artigos maravilhosos.
Por favor, me ajude! Quando tento treinar no Strategy Tester usando o Ryzen 9 6900hx (APU), recebo esse erro e o EA não tem nenhuma transação.
Como corrigir esse problema, irmão?
Olá, Dmitry,
Obrigado pelo excelente trabalho! Este é o melhor tutorial até agora na Internet sobre ML na plataforma MQL5
Os detalhes estão bem explicados e podem ser compreendidos por novos alunos.
Seguindo seu tutorial, executei o Strategy Tester e, aparentemente, apenas um dos meus processadores foi usado, apesar de haver 12 disponíveis, conforme mostrado na imagem abaixo
Existe alguma maneira de ativar todos os núcleos em vez de apenas um?
SISTEMA OPERACIONAL Windows 11 build 22H2
Suporte a OpenCL 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrado)
RAM 16gb
O OpenCL já está ativado nas configurações do Metatrader.
Obrigado pelo tutorial detalhado!
Olá, Dmitry,
Obrigado pelo excelente trabalho! Este é o melhor tutorial até agora na rede sobre ML na plataforma MQL5
Os detalhes estão bem explicados e podem ser compreendidos por novos alunos.
Seguindo seu tutorial, executei o Strategy Tester e, aparentemente, apenas um dos meus processadores foi usado, apesar de haver 12 disponíveis, conforme mostrado na imagem abaixo
Existe alguma maneira de ativar todos os núcleos em vez de apenas um?
SISTEMA OPERACIONAL Windows 11 build 22H2
Suporte ao OpenCL 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrado)
RAM 16gb
O OpenCL já está ativado nas configurações do Metatrader.
Obrigado pelo tutorial detalhado!
Olá, no testador do Strategy você pode ver o uso de apenas um núcleo. Ele é usado pelo programa mql, não pelo OpenCL. O OpenCL usa núcleos de GPU ou CPU no sistema fora do monitor do testador de estratégia. Há várias maneiras de ver o consumo de recursos de um programa OpenCL no Windows:
1. use um software de monitoramento de desempenho, como o MSI Afterburner ou o GPU-Z, que exibe o uso da GPU e outros componentes do sistema. Eles também podem mostrar a parte dos recursos que cada programa OpenCL está usando.
2) Use profilers como o AMD CodeXL ou o NVIDIA Nsight Visual Studio Edition. Eles permitem que você analise um programa OpenCL e mostre quais partes do código consomem mais tempo e recursos.
3. use a API do OpenCL para coletar estatísticas. Isso permite que você obtenha informações de forma programática sobre o uso de recursos OpenCL, como uso de memória ou desempenho do núcleo. Você pode usar a biblioteca Performance Counters for OpenCL (PCPerfCL) para coletar essas informações no Windows.
4. use ferramentas de criação de perfil, como o Intel VTune Amplifier, que podem ajudá-lo a ver como um programa usa o processador e outros recursos de componentes do sistema.
Boa tarde, Dimitri!
Por favor, ajude-me a executar o Expert Advisor deste artigo. Tentei de tudo para fazê-lo funcionar, mas, infelizmente, ele não funciona corretamente.
O problema é o seguinte: o Expert Advisor é iniciado no testador e começa o teste no testador normalmente, com contagem regressiva dos segundos, barra verde, sem erros no registro, vê normalmente a placa de vídeo e a seleciona. Mas há 0% de carga na placa de vídeo. É como se não estivesse contando nada para ela. Em Common\Files, há dois arquivos com extensões icm e nnw com tamanho de 1 kb. Quando tento reiniciar o teste no testador novamente, ele avisa que não pode inicializar e o teste não começa. Se você reiniciar o MT5 e excluir os arquivos criados por esse EA em Common\Files, ele será iniciado normalmente, mas também não usará a placa de vídeo e criará novamente esses arquivos de 1 kb. e assim por diante.
Tentei pegar os arquivos NeuroNet.mqh do próximo artigo (que você postou nos comentários) e substituir o do artigo por ele - isso não ajudou. Tentei selecionar um pequeno período de tempo no testador (1 mês, 1 semana, 2 meses, etc.), mas também não adiantou.
Como iniciar? Os Expert Advisors dos artigos anteriores funcionam normalmente e usam a placa de vídeo corretamente.
Também há um problema com o Expert Advisor do próximo artigo 37, 38. Por outro lado, não há progresso no testador, mas a placa de vídeo é usada ao máximo e, portanto, por pelo menos 5 horas, até mesmo 10 horas.
O Expert Advisor do artigo 39 funcionou bem. Lá, escolhi o histórico de mais de 1 mês e ele não criou o banco de dados, mas escolhi 1 mês e ele criou o banco de dados normalmente. O restante de suas partes funcionou normalmente.
Esta é uma verdadeira joia, Dmitriy!
Sou um cientista de dados com experiência prática no desenvolvimento de vários algoritmos de aprendizado de máquina em dados de séries temporais e, ainda assim, considero sua série informativa e bem escrita. Essa é uma base valiosa a ser desenvolvida.
Obrigado por compartilhar seu trabalho.
Bijan