
神经网络变得轻松(第五十三部分):奖励分解

概述
我们继续探索强化学习方法。如您所知,机器学习领域中用于训练模型的所有算法都基于最大化环境奖励的范式。奖励函数在模型训练过程中起着关键作用。其信号往往非常模棱两可。
为了激励代理者表现出所需的行为,我们在奖励函数中引入了额外的红利和惩罚。例如,我们常常把奖励函数搞得更加复杂,试图鼓励代理者去探索环境,并引入对不作为的惩罚。同时,模型的架构和奖励函数仍然是模型架构师主观考虑的结果。
在训练期间,即使采取精心设计的方式,模型也可能会遇到各种困难。出于众多不同的原因,代理者也许无法达成预期的结果。但是,我们如何理解代理者在奖励函数中正确地解释我们的信号呢?为尝试搞明白这个问题,人们希望将奖励分解成不同的分量。使用分解的奖励并分析各个分量的影响,对于找到优化模型训练的方法非常实用。这令我们能够更好地了解不同层面如何影响代理者行为,辨别导致问题的原因,并有效地调整模型架构、训练过程、或奖励函数。
1. 奖励分解的必要性
奖励函数值分解是一种简单且广泛适用的方法,可以应对各种挑战。在强化学习中,代理者会获得奖励,这往往是许多分量的总和。它们中的每一个都意图对代理者期望行为的某些层面进行编码。从这个复合奖励中,代理者学习单个复杂的重要性函数。使用数值分解,代理者学习每个奖励分量的重要性函数。从它们中获取的任何单个函数都很可能具有更简单的形式。
出于策略优化目的,通过对分量重要性函数进行加权合计来重建分量重要性函数。
奖励分解可包含于范围广泛的各种不同方法之中,包括此处研究的扮演者-评论者家族。
然而,奖励函数分解的额外诊断和训练能力是以更复杂的预测任务为代价的:应该训练多个函数,替代只训练单个重要性函数。该因素对打理着性能的影响在《强化学习代理者迭代设计的数值函数分解》一文中进行了分析。文章作者发现,在软性扮演者-评论者算法中加入奖励函数分解时,模型的训练结果不如原始算法。不过,作者有也提出了改进算法的选项。这令我们不仅能够与原始的软性扮演者-评论者算法相匹配,甚至反而有时能超过其性能。这些改进可以应用于奖励函数分解和扮演者-评论者家族中的其它算法。
广泛的强化学习算法可以根据以下形态进行适配,以便使用奖励函数的分解:
- 更改 Q-函数模型,如此我们即可在模型输出处为奖励函数的每个分量获得一个元素。
- 使用基本 Q-函数学习算法更新每个分量。
此形态适用于离散和连续动作空间模型学习算法。
该思路很简单。但如上所述,本文的作者发现,在软性扮演者-评论者算法的框架内使用奖励分解时,“迎头正对方案”效率低下。我要提醒您该算法中 Q-函数的优化方程。

在此,我们看到使用了来自评论者的两个目标模型的最小未来状态估值。如形态第 2 点的情况,我们使用基本算法来更新 Q-函数的每个分量的参数。但正如实践验证所示,使用分量最小值会导致模型的不平衡。选择一个总分最低的模型可以更有效地工作,如用其分量估值来训练模型。
通常,假设模型的奖励函数是其分量的线性函数。
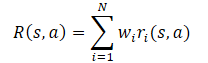
应用期望值的线性,我们发现 Q-函数继承了奖励函数的线性结构。
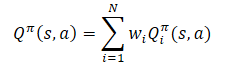
除非另有说明,否则我们假设所有 i 的 Wi=1。由于分量的权重取自 Q-函数,故可以在不改变目标分量预测的情况下更改它们。这允许您评估任意权重组合的策略。
值得关注的第二点是,优化分解的奖励函数就是根据许多准则对模型进行优化。它也有多准则优化的典型问题:梯度冲突、高曲率、和梯度值差异大。为了尽量令这一因素的负面影响最小化,该方法作者建议使用为多任务强化学习环境而设计的冲突防范梯度下降(CAGrad)算法。该方法靶标是缓解上述多目标优化问题。其基本思路是将多任务目标函数的梯度替换为每个单独任务的梯度加权和。这样做,就解决了以下优化问题:
![]()
其中 d 是更新向量,
g₀ — 梯度均值,
с — 收敛速度系数,在范围 [0, 1) 内。
解决这个优化问题令我们能够考虑每个分量对优化的影响,并专注于改进每个步骤的最坏估值。
2. 以 MQL5 实现
2.1创建新的模型类
我们基于 SAC+DICE 算法实现奖励函数分解版本。由于算法实现的特殊性,我们不会从上一篇文章中创建的 CNet_SAC_DICE 类继承。但我们仍会用到以前所做的开发。我们要创建的 CNet_SAC_D_DICE 类,与 CNet_SAC_DICE 相似。下面提供的是新类的结构。
class CNet_SAC_D_DICE : protected CNet { protected: CNet cActorExploer; CNet cCritic1; CNet cCritic2; CNet cTargetCritic1; CNet cTargetCritic2; CNet cZeta; CNet cNu; CNet cTargetNu; vector<float> fLambda; vector<float> fLambda_m; vector<float> fLambda_v; int iLatentLayer; float fCAGrad_C; int iCAGrad_Iters; int iUpdateDelay; int iUpdateDelayCount; //--- float fLoss1; float fLoss2; vector<float> fZeta; vector<float> fQWeights; //--- vector<float> GetLogProbability(CBufferFloat *Actions); vector<float> CAGrad(vector<float> &grad); public: //--- CNet_SAC_D_DICE(void); ~CNet_SAC_D_DICE(void) {} //--- bool Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1); //--- virtual bool Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &Rewards, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float discount, float tau); virtual void GetLoss(float &loss1, float &loss2) { loss1 = fLoss1; loss2 = fLoss2; } virtual bool TargetsUpdate(float tau); //--- virtual void SetQWeights(vector<float> &weights) { fQWeights=weights; } virtual void SetCAGradC(float c) { fCAGrad_C=c; } virtual void SetLambda(vector<float> &lambda) { fLambda=lambda; fLambda_m=vector<float>::Zeros(lambda.Size()); fLambda_v=fLambda_m; } virtual void TargetsUpdateDelay(int delay) { iUpdateDelay=delay; iUpdateDelayCount=delay; } //--- virtual bool Save(string file_name, bool common = true); bool Load(string file_name, bool common = true); };
我们在提供的类结构中可以看到借用的模型对象。但是,我们将用到的向量大小等于奖励函数分量数量,替代存储拉格朗日(Lagrange)系数及其平均值的变量。此处,我们添加 fQWeights 向量来存储每个分量的权重系数。我们选择 fCAGrad_C 变量来记录 CAGrad 方法的收敛率系数。
当然,这些修改反映在类构造函数当中。在初始阶段,我们初始化所有单位长度的向量。
CNet_SAC_D_DICE::CNet_SAC_D_DICE(void) : fLoss1(0), fLoss2(0), fCAGrad_C(0.5f), iCAGrad_Iters(15), iUpdateDelay(100), iUpdateDelayCount(100) { fLambda = vector<float>::Full(1, 1.0e-5f); fLambda_m = vector<float>::Zeros(1); fLambda_v = vector<float>::Zeros(1); fZeta = vector<float>::Zeros(1); fQWeights = vector<float>::Ones(1); }
类的初始化方法,以及创建嵌套模型的方法均取自上一篇文章,没有任何好研究的修改。仅对矢量大小进行了修改。
bool CNet_SAC_D_DICE::Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1) { ResetLastError(); //--- if(!cActorExploer.Create(actor) || !CNet::Create(actor)) { PrintFormat("Error of create Actor: %d", GetLastError()); return false; } //--- if(!opencl) { Print("Don't opened OpenCL context"); return false; } //--- if(!cCritic1.Create(critic) || !cCritic2.Create(critic)) { PrintFormat("Error of create Critic: %d", GetLastError()); return false; } //--- if(!cZeta.Create(zeta) || !cNu.Create(nu)) { PrintFormat("Error of create function nets: %d", GetLastError()); return false; } //--- if(!cTargetCritic1.Create(critic) || !cTargetCritic2.Create(critic) || !cTargetNu.Create(nu)) { PrintFormat("Error of create target models: %d", GetLastError()); return false; } //--- cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl); //--- if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), 1.0) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), 1.0) || !cTargetNu.WeightsUpdate(GetPointer(cNu), 1.0)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- cZeta.getResults(fZeta); ulong size = fZeta.Size(); fLambda = vector<float>::Full(size,1.0e-5f); fLambda_m = vector<float>::Zeros(size); fLambda_v = vector<float>::Zeros(size); fQWeights = vector<float>::Ones(size); iLatentLayer = latent_layer; //--- return true; }
请注意,于此我们采用单个值初始化权重 fQWeights 向量。如果您的奖励函数提供其它系数,那么您需调用 SetQWeights 方法。不过,应在使用 Create 方法完成类初始化之后再调用它,否则您的系数将被单一值覆盖。
我们将冲突防范梯度下降算法移至单独的 CAGrad 方法之中。在参数中,该方法接收梯度向量,并返回调整后的向量。
首先,我们必须在方法主体中进行一些准备工作:
- 判定梯度的平均值;
- 缩放梯度以便提高计算稳定性;
- 准备局部变量和向量。
vector<float> CNet_SAC_D_DICE::CAGrad(vector<float> &grad) { matrix<float> GG = grad.Outer(grad); GG.ReplaceNan(0); if(MathAbs(GG).Sum() == 0) return grad; float scale = MathSqrt(GG.Diag() + 1.0e-4f).Mean(); GG = GG / MathPow(scale,2); vector<float> Gg = GG.Mean(1); float gg = Gg.Mean(); vector<float> w = vector<float>::Zeros(grad.Size()); float c = MathSqrt(gg + 1.0e-4f) * fCAGrad_C; vector<float> w_best = w; float obj_best = FLT_MAX; vector<float> moment = vector<float>::Zeros(w.Size());
在完成准备工作后,我们为解决优化问题安排一个循环。在循环主体中,我们调用梯度下降方法迭代求解寻找优化更新向量的问题。
for(int i = 0; i < iCAGrad_Iters; i++) { vector<float> ww; w.Activation(ww,AF_SOFTMAX); float obj = ww.Dot(Gg) + c * MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f); if(MathAbs(obj) < obj_best) { obj_best = MathAbs(obj); w_best = w; } if(i < (iCAGrad_Iters - 1)) { float loss = -obj; vector<float> derev = Gg + GG.MatMul(ww) * c / (MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f) * 2) + ww.MatMul(GG) * c / (MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f) * 2); vector<float> delta = derev * loss; ulong size = delta.Size(); matrix<float> ident = matrix<float>::Identity(size, size); vector<float> ones = vector<float>::Ones(size); matrix<float> sm_der = ones.Outer(ww); sm_der = sm_der.Transpose() * (ident - sm_der); delta = sm_der.MatMul(delta); if(delta.Ptp() != 0) delta = delta / delta.Ptp(); moment = delta * 0.8f + moment * 0.5f; w += moment; if(w.Ptp() != 0) w = w / w.Ptp(); } }
循环迭代完成后,我们取最优权重调整误差梯度。结果将返回到调用程序。
w_best.Activation(w,AF_SOFTMAX); float gw_norm = MathSqrt(w.MatMul(GG).Dot(w) + 1.0e-4f); float lmbda = c / (gw_norm + 1.0e-4f); vector<float> result = ((w * lmbda + 1.0f / (float)grad.Size()) * grad) / (1 + MathPow(fCAGrad_C,2)); //--- return result; }
就像在 CNet_SAC_DICE 类中一样,整个训练都安排在 CNet_SAC_D_DICE::Study 方法之中。但尽管方式统一,且外部相似,但方法算法和结构仍存在许多差异。我们对方法参数进行了第一次修改。在此,我们将 “reward” 变量替换为分解奖励的 Rewards 向量。
此外,我们排除了 ActionsLogProbab 动作概率对数向量。如您所知,软性扮演者-评论者算法是为了在奖励函数中包含熵分量,从而鼓励代理者重复低概率动作。奖励函数的分解为每个分量分配一个单独的元素。因此,概率对数已经存在于奖励分解的 Rewards 向量当中,我们不需要在单独的向量中复制它们。
bool CNet_SAC_D_DICE::Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &Rewards, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float discount, float tau) { //--- if(!Actions) return false;
在方法主体中,我们检查指针与已完成操作的结果缓冲区的相关性。我们方法的控制模块至此完结。
转入下一阶段,必须说,在训练模型的过程中,注意到目标模型对后续状态的估值有相当大的不合理增加。这种估值极大超过了实际奖励,这导致训练模型及其目标副本在未考虑环境实际奖励的情况下相互适配。
为了把这种影响最小化,决定在初始阶段采用实际累积奖励来训练模型。完全拒绝使用目标模型也有负面影响。在经验回放缓冲区中,累积估值仅限于训练期间。对于类似的状态和动作,也能有很大不同,具体取决于至训练集尾端的距离。目标模型则把这种差异平滑了。此外,目标模型还有助于基于当前正策动作来估算状态。随着更新代理者参数的迭代次数增加,当前政策与经验回放缓冲区中的政策差异越来越大,不容忽视。但是我们需要一个具有足够估值的目标模型。因此,我们需要两种方法操作模式:使用和不使用目标模型。
在编排方法算法时,我们受以下参考引导:
- 如果需要使用目标模型,则用户会在参数中传递指向未来状态的指针。Rewards 向量仅包含当前状态下所执行动作的分解奖励。
- 拒绝使用目标模型后,用户不会传递指向未来状态的指针(参数变量包含 NULL)。Rewards 向量里包含分解奖励的累计。
因此,我们接下来检查指向未来状态的指针,并在必要时根据当前政策判定未来状态中的动作。此外,我们还要估算状态-动作对。
if(!!NextState) if(!CNet::feedForward(NextState, 1, false, NextSecondInput)) return false; if(!cTargetCritic1.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1) || !cTargetCritic2.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false; //--- if(!cTargetNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false;
接下来,我们依据当前状态进行保守政策直接验算。替换动作并运作一次贯穿 DICE 模块模型的直接验算。
if(!CNet::feedForward(State, 1, false, SecondInput)) return false; CBufferFloat *output = ((CNeuronBaseOCL*)((CLayer*)layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite(); if(!cNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false; if(!cZeta.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false;
接下来,判定分布校正估值模块模型的损失函数值。该步骤在上一篇文章中已有详述。我只是强调,在拒绝使用目标模型的情况下,估算未来状态的 next_nu向量会填充零值。
vector<float> nu, next_nu, zeta, ones; cNu.getResults(nu); cZeta.getResults(zeta); if(!!NextState) cTargetNu.getResults(next_nu); else next_nu = vector<float>::Zeros(nu.Size()); ones = vector<float>::Ones(zeta.Size()); vector<float> log_prob = GetLogProbability(output); int shift = (int)(Rewards.Size() - log_prob.Size()); if(shift < 0) return false; float policy_ratio = 0; for(ulong i = 0; i < log_prob.Size(); i++) policy_ratio += log_prob[i] - Rewards[shift + i] / LogProbMultiplier; policy_ratio = MathExp(policy_ratio / log_prob.Size()); vector<float> bellman_residuals = (next_nu * discount + Rewards) * policy_ratio - nu; vector<float> zeta_loss = MathPow(zeta, 2.0f) / 2.0f - zeta * (MathAbs(bellman_residuals) - fLambda) ; vector<float> nu_loss = zeta * MathAbs(bellman_residuals) + MathPow(nu, 2.0f) / 2.0f; vector<float> lambda_los = fLambda * (ones - zeta);
接下来,我们调用 Adam 优化方法更新拉格朗日系数向量。
请注意,我们调用上面讨论的 CAGrad 方法校正误差梯度向量。使用向量运算令我们能够像处理简单变量一样轻松地处理向量。
我们将调整后的数值保存在相应的向量之中。
vector<float> grad_lambda = CAGrad((ones - zeta) * (lambda_los * (-1.0f))); fLambda_m = fLambda_m * b1 + grad_lambda * (1 - b1); fLambda_v = fLambda_v * b2 + MathPow(grad_lambda, 2) * (1.0f - b2); fLambda += fLambda_m * lr / MathSqrt(fLambda_v + lr / 100.0f);
下一步是更新 v, ζ 模型参数。这些操作的算法保持不变。我们只是把向量替换了变量,并使用向量运算。
CBufferFloat temp; temp.BufferInit(MathMax(Actions.Total(), SecondInput.Total()), 0); temp.BufferCreate(opencl); //--- update nu int last_layer = cNu.layers.Total() - 1; CLayer *layer = cNu.layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; CBufferFloat *buffer = neuron.getGradient(); if(!buffer) return false; vector<float> nu_grad = CAGrad(nu_loss * (zeta * bellman_residuals / MathAbs(bellman_residuals) - nu)); if(!buffer.AssignArray(nu_grad) || !buffer.BufferWrite()) return false; if(!cNu.backPropGradient(output, GetPointer(temp))) return false;
我们必须调用 CNet_SAC_D_DICE::CAGrad 方法,按冲突防范梯度下降算法校正误差梯度向量。
//--- update zeta last_layer = cZeta.layers.Total() - 1; layer = cZeta.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; vector<float> zeta_grad = CAGrad(zeta_loss * (zeta - MathAbs(bellman_residuals) + fLambda) * (-1.0f)); if(!buffer.AssignArray(zeta_grad) || !buffer.BufferWrite()) return false; if(!cZeta.backPropGradient(output, GetPointer(temp))) return false;
在这个阶段,我们完成了对分布校正估算模块的操控,并转入训练我们的评论者模型。首先,我们执行它们的前向验算。我们之前已经运作了扮演者的前向验算。
//--- feed forward critics if(!cCritic1.feedForward(GetPointer(this), iLatentLayer, output) || !cCritic2.feedForward(GetPointer(this), iLatentLayer, output)) return false;
下一步是判定更新评论者参数的引用值向量。此处有两个细微差别。它们都与目标模型有关。首先,我们检查是否需要用它们来估算后续状态和动作。为此,我们检查指向系统后续状态的指针。
如果我们使用目标模型来估算后续的状态-动作对,那么我们需要选择累积分数最低的目标评论者。通过将奖励函数分量的加权系数向量乘以从目标模型的前向验算中获得的分解预测奖励向量,可以很容易地获得累积估值。接下来,我们所要做的就是选择最小估值,并保存所选模型的预测值向量。
如果拒绝估算后续状态,则预测值的向量将被填充零值。
vector<float> result; if(fZeta.CompareByDigits(vector<float>::Zeros(fZeta.Size()),8) == 0) fZeta = MathAbs(zeta); else fZeta = fZeta * 0.9f + MathAbs(zeta) * 0.1f; zeta = MathPow(MathAbs(zeta), 1.0f / 3.0f) / (MathPow(fZeta, 1.0f / 3.0f) * 10.0f); vector<float> target = vector<float>::Zeros(Rewards.Size()); if(!!NextState) { cTargetCritic1.getResults(target); cTargetCritic2.getResults(result); if(fQWeights.Dot(result) < fQWeights.Dot(target)) target = result; }
按折扣因子调整预测估值,并累加当前状态的奖励。
target = (target * discount + Rewards); ulong total = log_prob.Size(); for(ulong i = 0; i < total; i++) target[shift + i] = log_prob[i] * LogProbMultiplier;
在生成的向量中,我们将调整当前政策中的动作概率对数。存储在经验回放缓冲区中的动作概率对数已包含在奖励向量当中。我们用当前政策的对数替换它们的值,以便在考虑当前政策的情况下训练评论者进行估算。
判定目标值后,我们计算第一个平路在内核的预测误差,以及 Q-函数每个分量的误差梯度。生成的梯度要经由冲突防范梯度下降算法调整。
//--- update critic1 cCritic1.getResults(result); vector<float> loss = zeta * MathPow(result - target, 2.0f); if(fLoss1 == 0) fLoss1 = MathSqrt(fQWeights.Dot(loss) / fQWeights.Sum()); else fLoss1 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * fQWeights.Dot(loss) / fQWeights.Sum()); vector<float> grad = CAGrad(loss * zeta * (target - result) * 2.0f);
我们将校正后的误差梯度传输到相应的 Critic1 缓冲区,并执行逆向模型验算。
last_layer = cCritic1.layers.Total() - 1; layer = cCritic1.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.AssignArray(grad) || !buffer.BufferWrite()) return false; if(!cCritic1.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
在此,我们还执行扮演者的部分逆向验算,来调整源数据预处理模块。
针对第二个评论者重复这些操作。
//--- update critic2 cCritic2.getResults(result); loss = zeta * MathPow(result - target, 2.0f); if(fLoss2 == 0) fLoss2 = MathSqrt(fQWeights.Dot(loss) / fQWeights.Sum()); else fLoss2 = MathSqrt(0.999f * MathPow(fLoss2, 2.0f) + 0.001f * fQWeights.Dot(loss) / fQWeights.Sum()); grad = CAGrad(loss * zeta * (target - result) * 2.0f); last_layer = cCritic2.layers.Total() - 1; layer = cCritic2.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.AssignArray(grad) || !buffer.BufferWrite()) return false; if(!cCritic2.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
在方法的下一个模块中,我们将更新政策。我要提醒您,SAC+DICE 算法提供了两种扮演者政策的训练:保守和乐观。首先,我们将更新保守政策。我们已经针对这个模型进行了前向验算。
为了训练扮演者,我们将取最小平均误差评论者。我们定义这样一个模型,并将指向它的指针存储在局部变量之中。
vector<float> mean; CNet *critic = NULL; if(fLoss1 <= fLoss2) { cCritic1.getResults(result); cCritic2.getResults(mean); critic = GetPointer(cCritic1); } else { cCritic1.getResults(mean); cCritic2.getResults(result); critic = GetPointer(cCritic2); }
此处,我们将加载每位评论者的预测评级。然后,我们将使用方程判定模型逆向验算的参考值。
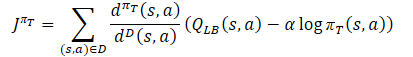
同时,我们使用冲突规避梯度下降方法确保校正误差梯度向量。
vector<float> var = MathAbs(mean - result) / 2.0f; mean += result; mean /= 2.0f; target = mean; for(ulong i = 0; i < log_prob.Size(); i++) target[shift + i] = discount * log_prob[i] * LogProbMultiplier; target = CAGrad(zeta * (target - var * 2.5f) - result) + result;
接下来,我们只需将接收到的数据传输到缓冲区,并执行评论者和扮演者的逆向验算。为防止模型彼此相互调整,在开始操作之前关闭评论者训练模式。在本例中,我们仅用它验算给扮演者的误差梯度。
CBufferFloat bTarget; bTarget.AssignArray(target); critic.TrainMode(false); if(!critic.backProp(GetPointer(bTarget), GetPointer(this)) || !backPropGradient(SecondInput, GetPointer(temp))) { critic.TrainMode(true); return false; }
我们尚未用到乐观情绪扮演者模型,与保守的模型对比。因此,在开始更新其参数之前,我们必须直接验算环境的当前状态。
//--- update exploration policy if(!cActorExploer.feedForward(State, 1, false, SecondInput)) { critic.TrainMode(true); return false; } output = ((CNeuronBaseOCL*)((CLayer*)cActorExploer.layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite();
与保守的扮演者情况一样,我们替换了动作向量,并获得概率对数,同时考虑到乐观情绪政策。
cActorExploer.GetLogProbs(log_prob);
根据乐观情绪政策方程判定模型逆向验算的参考值向量。
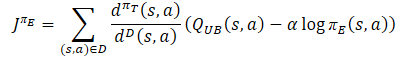
使用冲突规避梯度下降方法校正误差梯度向量。
target = mean; for(ulong i = 0; i < log_prob.Size(); i++) target[shift + i] = discount * log_prob[i] * LogProbMultiplier; target = CAGrad(zeta * (target + var * 2.0f) - result) + result;
然后,我们针对模型执行逆向验算,并把评论者返回到模型训练模式。
bTarget.AssignArray(target); if(!critic.backProp(GetPointer(bTarget), GetPointer(cActorExploer)) || !cActorExploer.backPropGradient(SecondInput, GetPointer(temp))) { critic.TrainMode(true); return false; } critic.TrainMode(true);
接下来,我们需要更新目标模型。在此,我做了进一步的补充,以防止对未来状态的估值失真,以及将评论者的模型适配到它们的目标副本的值。
仅当目标模型的参数不再用于估算后续状态时,才会在每次迭代时更新这些参数。如果在训练中用到目标模型,则其更新会延迟执行。
因此,我们首先检查是否需要更新模型,然后再进行操作。
if(!!NextState) { if(iUpdateDelayCount > 0) { iUpdateDelayCount--; return true; } iUpdateDelayCount = iUpdateDelay; } if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), tau) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), tau) || !cTargetNu.WeightsUpdate(GetPointer(cNu), tau)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- return true; }
该方法成功完成所有迭代之后,我们以 “true” 结果终止其工作。
奖励分解和向量的使用导致了其它方法的变化,包括操控文件的方法。但我们现在不会详述它们。您可以在附件 “MQL5\Experts\SAC-D&DICE\Net_SAC_D_DICE.mqh” 中找到它们,还有新类的所有方法的完整代码。
2.2调整数据存储结构
现在,我们把注意力集中在 “MQL5\Experts\SAC-D&DICE\Trajectory.mqh” 文件上。我们曾在此处修改过模型的架构。现在我们几乎没有改变。我们只需要修改评论者输出处的神经元数量。它们应该足够分解奖励函数。但在指定它们的数量之前,我们先定义分解奖励的结构。
我们将用索引 “0” 表示第一个元素中余额的相对变化。如您所知,我们的主要目标是在市场上实现盈利最大化。
索引为 “1” 的参数将包含净值变化的相对值。负值表示不希望的回撤。正数表示浮动盈利。
还分配了一个元素,是针对缺乏持仓的处罚。
接下来,添加动作概率的对数。如您所知,概率对数向量的长度与动作向量相等。
//+------------------------------------------------------------------+ //| Rewards structure | //| 0 - Delta Balance | //| 1 - Delta Equity ( "-" Drawdown / "+" Profit) | //| 2 - Penalty for no open positions | //| 3... - LogProbs vector | //+------------------------------------------------------------------+
因此,评论者结果的神经层大小比动作数大 3 个元素。
#define NActions 6 //Number of possible Actions #define NRewards 3+NActions //Number of rewards
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- Actor ........ ........ //--- Critic critic.Clear(); //--- Input layer ........ ........ //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
奖励分解也改变了经验回放缓冲区中数据存储的结构。现在,一个变量不足以让我们设置奖励。我们需要一个数据数组。同时,我们已经将熵分量引入到奖励数组之中,我们不需要单独的数组来重置这些值。因此,在状态描述结构中,我们将 'log_prob' 数组替换为 'rewards',并调整复制结构和处理文件的方法。
struct SState { float state[HistoryBars * BarDescr]; float account[AccountDescr - 4]; float action[NActions]; float rewards[NRewards]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(rewards, obj.rewards); } };
在 STrajectory 轨迹结构中,删除 Rewards 数组,因为我们现在将在 SState 状态结构中描述奖励。另外,我们对结构方法进行有针对性的修改。
struct STrajectory { SState States[Buffer_Size]; int Total; float DiscountFactor; bool CumCounted; //--- STrajectory(void); //--- bool Add(SState &state); void CumRevards(void); //--- bool Save(int file_handle); bool Load(int file_handle); };
附件中提供了上述结构及其方法的完整代码。
2.3创建模型训练 EA
是时候转入模型训练 EA 的工作了。在训练期间,我们如前用到三个 EA:
- Research — 收集示样本数据库
- Study — 模型训练
- Test — 检查获得的结果。
在 Research 和 Test EA 中,这些变化仅影响环境状态描述结构的准备,和 OnTick 方法结束时获得的奖励。虽然我们之前汇总了奖励和罚款,但现在我们将每个分量添加到其自己的数组元素当中。在这种情况下,遵循上述数据结构非常重要。数组的每个元素都必须填充。如果缺少分量值,则取 “0” 写入相应的数组元素。这种方法将令我们对所用数据的有效性充满信心。
void OnTick() { //--- ........ ........ //--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f-bAccount[1]; vector<float> log_prob; Actor.GetLogProbs(log_prob); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) { sState.action[i] = ActorResult[i]; sState.rewards[i + 3] = log_prob[i] * LogProbMultiplier; } if(!Base.Add(sState)) ExpertRemove(); }
EA 的完整代码可从附件中找到。
如常,模型训练在 Study EA 中运作。如上所述,我们将训练模型的过程分为两个阶段:
- 使用实际累积奖励进行训练(无目标模型),
- 使用目标模型进行训练。
第一阶段的持续时间由一个常数决定。
#define StartTargetIteration 20000
值得注意的是,只有在您首次启动 Study EA 时,且没有预训练模型时,才会在不使用目标模型的情况下进行训练。
如果在启动时,训练 EA 设法加载了预训练模型,则从第一次训练迭代开始就使用目标模型。
此控制是在 EA 的 OnInit 方法中实现的。
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models if(!Net.Load(FileName, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Net.Create(actor, critic, critic, critic, LatentLayer)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; StartTargetIter = StartTargetIteration; } else StartTargetIter = 0; //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
如您所见,StartTargetIter 变量在创建新模型时接收 StartTargetIteration 常量值。如果加载了预训练模型,则我们将 “0” 存储在延迟变量当中。
训练迭代安排在 Train 方法里。在方法开始时,我们像往常一样,判定经验回放缓冲区中保存的轨迹数,并使用 EA 外部参数中指定的迭代次数安排一个训练循环。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
在循环的主体中,我们随机抽取其中一个保存的轨迹中的状态。之后,我们将所选状态的有关信息传递至数据缓冲区和向量。
//--- bState.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- bActions.AssignArray(Buffer[tr].States[i].action); vector<float> rewards; rewards.Assign(Buffer[tr].States[i].rewards);
请注意,在当前阶段,我们仅为所选状态准备有关信息。为免执行不必要的工作,我们只会在必要时生成有关后续状态的信息。
我们通过比较当前训练迭代和 StartTargetIter 变量的值,来测试是否需要使用目标模型来估算后续状态。如果迭代次数未达到阈值,则我们依据累积值运作训练。但此处有细微差别。将数据保存到经验回放缓冲区时,我们计算了所有奖励分量值的累加和。不过,我们需要没有累积总数的熵分量。因此,我们安排一个循环,仅从奖励函数的熵分量中删除累积值。
//--- if(iter < StartTargetIter) { ulong start = rewards.Size() - bActions.Total(); for(ulong r = start; r < rewards.Size(); r++) rewards[r] -= Buffer[tr].States[i + 1].rewards[r] * DiscFactor; if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), rewards, NULL, NULL, DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
然后我们调用新类的训练方法。在此,我们在后续状态参数中指定 “NULL”。
在达到使用目标函数的阈值后,我们将首先准备有关系统后续状态的信息。
else { //--- Target bNextState.AssignArray(Buffer[tr].States[i + 1].state); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(PrevBalance == 0) { iter--; continue; } bNextAccount.Clear(); bNextAccount.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); bNextAccount.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); bNextAccount.Add(Buffer[tr].States[i + 1].account[2]); bNextAccount.Add(Buffer[tr].States[i + 1].account[3]); bNextAccount.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); bNextAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
然后,我们删除奖励函数所有分量的累积值,只保留当前状态的奖励。
for(ulong r = 0; r < rewards.Size(); r++) rewards[r] -= Buffer[tr].States[i + 1].rewards[r] * DiscFactor; if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), rewards, GetPointer(bNextState), GetPointer(bNextAccount), DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
调用类模型的训练方法。这一次,我们使用后续状态数据指定对象。
在循环迭代结束时,我们打印一条消息通知用户,然后转入下一次迭代。
//--- if(GetTickCount() - ticks > 500) { float loss1, loss2; Net.GetLoss(loss1, loss2); string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), loss1); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), loss2); Comment(str); ticks = GetTickCount(); } }
所有循环迭代成功完成后,清除图表上的注释字段。强制更新目标模型。在 MetaTrader 5 日志里显示训练结果,到并关闭 EA。
Comment(""); //--- float loss1, loss2; Net.GetLoss(loss1, loss2); Net.TargetsUpdate(Tau); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", loss1); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", loss2); ExpertRemove(); //--- }
模型训练 EA 的工作到此完结。本文所有程序的完整代码可在附件中找到。
3. 测试
我们提出了一套基于 SAC+DICE 算法的奖励函数分解方法的实现方案,现在我们可以在实践中评估所做工作的结果。如前,这些模型依据 2023 年前 5 个月的 EURUSD H1 进行了训练。所有指标参数采用默认值。初始本金为 10,000 美元。
模型训练过程是迭代的,样本收集到经验积累缓冲区阶段,以及更新模型参数交替进行。
在第一阶段,我们以扮演者模型创建一个主样本数据库,并填充随机参数。结果就是,我们得到了一系列随机验算,这些验算生成了非政策的“状态→动作→新状态→奖励”数据集。
与之前研究的所有算法不同,在这种情况下,我们收集的是对应代理者动作的环境奖励的分解数据。
收集样本后,我们运作模型的初始训练。为了达成这一目标,我们启动 “..\SAC-D&DICE\Study.mq5“ EA。
在不使用目标模型的初级训练期间,我们观察到两个评论者的误差都有稳步下降的趋势。然而,当使用目标模型估算后续状态时,会观察到预测误差的混乱(不频繁)峰值,然后平滑地返回到以前的误差水平。
在第二阶段,我们在策略测试器的优化模式下重新启动训练数据收集 EA,并对参数进行完整搜索。这一次,我们使用在第一阶段训练的乐观情绪扮演者,进行所有验算。单独验算结果的离散度低于初始数据集合,这是由于扮演者政策的随机性。
收集样本和训练模型重复若干次,直至获得所需的结果,或收集样本和训练模型的下一次迭代没有产生任何进展,达到局部最小值。
在训练模型时,我们获得了一个能够在训练期间产生微薄盈利的扮演者政策。


尽管获得了利润,但学到的政策远非我们想要的。在余额图形上,我们看到一个振幅相当大的波浪状走势。在 28 笔交易中,只有 32% 的交易以盈利了结。总利润是由于盈利交易的规模超过亏损交易而达成的。交易的平均利润超过平均损失的 2 倍。每笔交易的最大利润几乎是最大损失的 3.5 倍。结果就是,盈利因子略高于 1。
EA 还展现出依据新数据盈利。在训练期结束后的一个月内,模型能够获得近 20% 的利润,这高于训练集上的结果。不过,结果的统计值与训练集数据相当。在测试期间,只进行了 4 笔交易,其中只有一笔获利了结。但这笔交易的利润是最糟糕的亏损交易的 12.8 倍。


比较训练样本和后续期间的结果,我们可以推测我们正在观察到新数据上盈利浪潮的开始,随后可能会在可预见的未来出现下降。
总体而言,该模型能够产生盈利,但需要进一步优化。
结束语
在本文中,我们讲述了奖励函数分解方法,它令我们能够更有效地训练代理者。奖励分解允许用户分析各种分量对代理者决策的影响。
我们利用 MQL5 实现了该算法,并将奖励函数的分解集成到 SAC+DICE 方法之中。
在测试所实现算法时,我们设法获得了一个能够在训练集内外产生盈利的模型。这表明了算法的普适能力。
然而,获得的结果远非我们想要的。同时,通过对奖励函数的分解,可以分析奖励函数的各分量对训练结果的影响。我鼓励您试验包含/排除单独分量,从而评估它们对训练结果的影响。
链接
本文中用到的程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | 智能交易系统 | 样本收集 EA |
| 2 | Study.mq5 | 智能交易系统 | 代理者训练 EA |
| 3 | Test.mq5 | 智能交易系统 | 模型测试 EA |
| 4 | Trajectory.mqh | 类库 | 系统状态定义结构 |
| 5 | Net_SAC_D_DICE.mqh | 类库 | 模型类 |
| 6 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 7 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/13098