
Нейросети — это просто (Часть 63): Предварительное обучение Трансформера решений без учителя (PDT)

Введение
Decision Transformer является довольно мощным инструментом для решения различных практических задач. И во многом это достигается благодаря использованию методов внимания Трансформера. Опыт предыдущих работ показал, что использование архитектуры Трансформера также требует длительного и тщательного обучения модели. При этом мы сталкиваемся с проблемой подготовки размеченных обучающих данных. При решении практических задач порой довольно сложно получить вознаграждение. А размеченные данные плохо масштабируются для расширения обучающей выборки. Однако, отказ от вознаграждений во время предварительного обучения также позволяет модели приобретать общие поведенческие паттерны, которые легко можно адаптировать для использования в различных последующих задачах.
В данной статье я предлагаю вам познакомиться с методом предварительного обучения RL под названием Pretrained Decision Transformer (PDT), который был представлен в статье "Future-conditioned Unsupervised Pretraining for Decision Transformer" (май 2023г.). Данный метод предоставляет DT возможность обучаться на данных без меток вознаграждений и с использованием субоптимальных данных. В частности, авторы метода рассматривают сценарий предварительного обучения, в котором модель сначала обучается офлайн на ранее собранных траекториях без меток вознаграждений, а затем донастраивается на целевую задачу путем онлайн взаимодействия.
Для эффективного предварительного обучения модель должна быть способной извлекать многогранные и универсальные сигналы обучения в отсутствие вознаграждений. Во время дообучения модель должна быстро адаптироваться к задачам вознаграждений, определяя какие сигналы обучения можно ассоциировать с вознаграждениями.
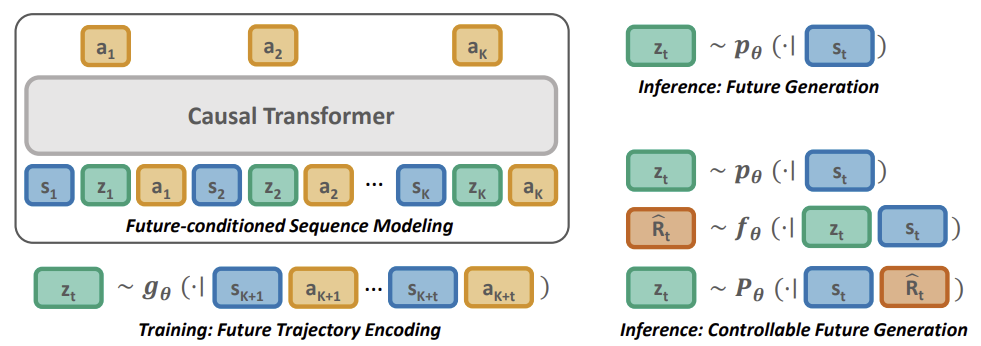
PDT изучает пространство вложений будущей траектории и будущую априорную вероятность, обусловленную только на прошлую информацию. Обученный прогнозировать действия для достижения целевого будущего вложение, PDT наделяется способностью "рассуждать о будущем". Эта способность не зависит от задачи и может быть обобщена для различных прикладных задач.
Для достижения эффективного онлайн дообучения в последующих задачах, фреймворк легко адаптируется к новым условиям, связывая каждое будущее вложение со своим возвратом, что достигается обучением сети прогнозирования ожидаемого вознаграждения для каждого целевого вложения.
Предлагаю перейти к следующему разделу нашей статьи и познакомиться по ближе с методом Pretrained Decision Transformer.
1. Метод Pretrained Decision Transformer
В основе метод PDT лежат принципы DT. В нем так же осуществляется прогнозирование действий Агента после анализа последовательности посещенных состояний и совершенных действий. В то же время PDT вносит в алгоритм DT дополнения позволяющие осуществлять предварительное обучение модель на неразмеченных данных, т. е. без анализа вознаграждений. Это кажется невозможным, ведь ожидаемое в будущем вознаграждение (Return To Go) является одним из членов анализируемой моделью последовательности и служит своеобразным компасом для ориентации модели в пространстве.
Авторы метода PDT предложили заменить RTG неким вектором латентного состояния Z. Это идея не нова, но авторами дана довольно интересная её интерпретация. В процессе предварительного обучения на неразмеченных данных фактически будем обучать 3 модели:
- Актера, который по сути является классическим DT с прогнозирование действий на базе анализа предшествующей траектории;
- Модель прогнозирования целей P(•|St) — осуществляет прогнозирование целей DT (латентного состояния Z) на основе анализа текущего состояния;
- Модель кодировщика будущего G(•|τt+1:t+k) — "заглядывает в будущее" и осуществляет его эмбедиинг в виде вектора латентного состояния Z.
Обратите внимание, 2 последние модели анализирую разные данные, но обе возвращают вектор латентного состояния Z. Таким образом, выстраивается своеобразный автоэнкодер между текущими и будущими состояниями. А его латентное состояние используется в качестве целеуказания для DT (Актера).
Однако обучение моделей отличается от процесса обучения автоэнкодера. Вначале мы обучаем кодировщик будущего и Актера, выстраивая зависимости между будущей траекторией и совершаемыми действиями. Мы позволяем PDT заглядывать в будущее на некоторый горизонт планирования. Мы сжимаем информацию о последующей траектории до латентного состояния. Таким образом мы позволяем модели принимать решение на основании доступной информации о будущем. И ожидаем, что в процессе предварительного обучения создать политику Актера с широким спектром поведенческих навыков, неограниченных вознаграждениями окружающей среды.
А затем мы обучаем модель прогнозирования целей, которая ищет зависимости между текущим состоянием и выученным эмбедингом будущей траектории.
Такой подход позволяет нам отделить вознаграждение от целевых результатов, открывая возможности для масштабного непрерывного предварительного обучения. При этом уменьшает проблему несогласованных поведений, когда поведение Агента значительно отклоняется от желаемых целей.
Хотя использование модели прогнозирования целей P(Z|St) для выборки будущих латентных переменных и генерации поведений, имитирующих распределение обучающей выборки, полезно, оно не кодирует никакой информации, специфичной для поставленной задачи. Поэтому необходимо направить P(Z|St) на выборку эмбедингов будущего, которые приводят к высокому будущему вознаграждения во время дообучения.
Это приводит к созданию экспертных поведений для DT, обусловленных на максимальное вознаграждение. В отличие от управления политикой, обусловленной на максимальный результат, путем назначения скалярного целевого вознаграждения, нам нужно скорректировать распределение модели прогнозирования целей P(Z|St). Поскольку это распределение неизвестно, мы используем дополнительную модель прогнозирования вознаграждения F(•|Z, St), чтобы спрогнозировать оптимальную траекторию. Модель прогнозирования вознаграждений обучается вместе со всеми другими во время дообучения.
Аналогично предварительному обучению для получения латентного состояния мы используем кодировщик будущего, что позволяет градиентам распространяться обратно, регулируя кодирования информации о наградах в латентном представлении. Это позволяет решать специфику поставленной задачи во время процесса дообучения.
Ниже представлена визуализация метода Pretrained Decision Transformer из оригинальной статьи.
2. Реализация средствами MQL5
После рассмотрения теоретических аспект метода Pretrained Decision Transformer мы переходим к практической части нашей статьи и рассмотрим вариант реализации метода средствами MQL5. И сразу скажу, что в этой статье мы будем останавливаться на советнике сбора обучающей выборки. В предыдущих статьях было рассмотрено несколько вариантов построения алгоритмов из семейства Decision Transformer. Все они содержат подобный состав буфера воспроизведения опыта. И для первичного сбора обучающей выборки мы можем воспользоваться ими. В своей работе я буду использовать буфер воспроизведения опыта, собранный в предыдущей статье. Напомню, что его мы собирали по случайным сэмплированием действий без привязки к конкретной модели (наработки метода Go-Explore).
2.1. Описание архитектуры моделей
Так как у нас уже есть набор обучающих данных, то мы переходим к следующему этапу — предварительное обучение без учителя. Как уже было сказано выше, на данном этапе мы будем обучать 3 модели. И начнем мы работу с описания архитектуры моделей, которое собрано в методе CreateDescriptions.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *planner, CArrayObj *future_embedding) { //--- CLayerDescription *descr;
В параметрах метод получает указатели на 3 динамических массива, в которые будут добавлены описания архитектуры нейронных слоев моделей.
В теле метода мы объявляем локальную переменную для записи указателя на объект описания одного нейронного слоя. В ней мы будем "держать" указатель на объект, с которым работаем в отдельно взятом блоке.
Свою работу мы начнем с описания архитектуры нашего Агента. Напомню, что в данном случае его роль играет Decision Transformer. Он принимает на вход пошаговое описание траектории и аккумулирует эмбединги всей последовательности в буфере результатов слоя Эмбединга. Но в отличии от предыдущих работ, во время обратного прохода нам предстоит передать градиент ошибки в модель кодировщика будущего. Для этого мы пойдем на небольшую хитрость. Мы разделим весь массив исходных данных на 2 потока. Основной объем данных мы будем передавать в модель как обычно через буфер слоя исходных данных. А эмбединг будущего передадим вторым потоком для объединения в слое конкатенации. При этом не обработанные исходные данные, которые мы подаем в буфер слоя исходных данных, мы будем нормализовать с использование слоя пакетной нормализации. А вот эмбединг будущего является результатом работы модели и может быть использован без нормализации.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count + EmbeddingSize; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!agent.Add(descr)) { delete descr; return false; }
Собранные в единый поток данные мы подаем на нейронный слой эмбединга представленной информации.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
А затем данные передаются в блок Трансформера. Я использовал "пирог" из 4 слоев с 16 головами Self-Attention.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
После блока Трансформера я использовал 2 сверточных слоя для выявления устойчивых паттернов.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
За ними следуют 3 полносвязных слоя блока принятия решения.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
И на выходе модели получаем полносвязный слой с количеством элементов равным пространству действий Агента.
Далее мы создадим описание модели прогнозирования целей P(Z|St). С использованием терминологии иерархических моделей мы можем назвать её Планировщиком. Ведь конструктивно их функционал очень близок, хотя подходы к обучению моделей отличается кардинально.
На слой исходных данных модели мы подаем описание лишь исторические данных и значений индикаторов одного паттерна. В нашем случае это данные лишь 1 бара.
Согласен, что это слишком мало информации для анализа рыночной ситуации и прогнозирования последующих состояний и действий. Тем более на несколько шагов вперед. Но давайте посмотрим на ситуацию иначе. В процессе эксплуатации сгенерированный прогноз будущего в виде эмбединга мы подаем вход нашего Актера, во внутренних слоях которого информация на заданную глубину истории. И в таком контексте нам более актуально обратить внимание на произошедшие изменения и скорректировать поведение Актера. Анализ более глубокой истории при составлении эмбединга будущего способно "смазать" локальные изменения. Однако, это мое субъективное мнение и не является требование алгоритма Pretrained Decision Transformer.
if(!planner) { planner = new CArrayObj(); if(!planner) return false; } //--- Planner planner.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Полученные необработанные исходные данные мы пропускаем через слой пакетной нормализации для приведения их в сопоставимый вид.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Далее я не стал сильно усложнять модель и поставил блок принятия решений из 3 полносвязных слоёв.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
На выходе модели мы понижаем величину вектора до размера эмбединга и нормализуем результаты функцией SoftMax.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
Мы уже описали архитектурное решение 2 моделей. И нам осталось добавить описание кодировщика будущего. Несмотря на то, что результат работы модели в принципе подразумевает соответствие выходу предыдущей модели, это будет заметно лишь в последних слоях модели. Сама же архитектура кодировщика немного сложнее. Прежде всего в эмбединг будущего мы включаем планирование на некоторую глубину. А значит на слой исходных данные мы подаем информацию о нескольких последующих свечах.
Тут же надо сказать, что в информацию о будущем я включил лишь данные о движении цены инструмента и показатели индикаторов. Я не стал включать информацию о состоянии счета и последующих действиях Агента. Действия Агента обусловлены его политикой. А мне бы хотелось акцентировать внимание на понимании процессов в окружающей среде. А вот состояние счета в какой-то мере уже содержат информацию о получаемом вознаграждении от окружающей среды, что несколько противоречит принципу неразмеченных данных.
//--- Future Embedding if(!future_embedding) { future_embedding = new CArrayObj(); if(!future_embedding) return false; } //--- future_embedding.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern * ValueBars; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Как и ранее, исходные данные без предварительной обработки мы пропускаем через слой пакетной нормализации для приведения в сопоставимый вид.
Далее я использовал блок Трансформера из 4 слоев и 16 голов Self-Attention. В данном случае блок внимания анализирует зависимости между отдельно взятыми барами в попытке выявления основных тенденций на горизонте планирования и отсеивания шумовой составляющей.
По логике метода PDT именно эмбединг будущего состояния должен указать Актеру на используемый навык и направление дальнейших действий. Поэтому результат работы кодировщика должен быть максимально информативен и точен.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = ValueBars; descr.window = BarDescr * NBarInPattern; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
За слоями внимания следуют полносвязные слои блока принятия решений.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
И на выходе модели мы используем полносвязный слой с нормализацией функцией SoftMax, как это было сделано выше в модели прогнозирования будущего.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- return true; }
На этом мы завершаем описание архитектуры моделей для советника предварительного обучения. Но прежде, чем перейти к работе над сами советником, хотелось бы завершить начатую работу по описанию архитектуры моделей. Я хочу напомнить, что на этапе тонкой настойки методом PDT предусмотрено добавление ещё одной модели — прогнозирования вознаграждения. И так как она добавляется на последующем этапе обучения, я решил вынести описание её архитектуры в отдельный метод CreateValueDescriptions.
Согласно методологии PDT данная модель должна оценить будущие тенденции, зашифрованные в латентном состоянии, и текущее состояние. По результатам анализа необходимо спрогнозировать вознаграждение от окружающей среды.
Целью же процесса дообучения модели является включение информации о вероятном вознаграждении в эмбединг будущего. Следовательно, как и на этапе предварительного обучения, нам необходимо передать градиент ошибки прогнозирования вознаграждения на модель кодировщика будущего. И здесь мы будем использовать апробированный выше подход по разделению потоков информации. Одним потоком исходных данных у нас будет идти текущее состояние. А вторым — эмбединг будущего.
Второй вопрос, который нам предстоит сейчас решить — что мы включаем в понимание текущего состояния на данном этапе. Конечно, на этапе тонкой настройки мы используем размеченные данные обучающей выборки и могли бы включить весь объем имеющейся информации. Но большой объем исходных данных в значительной мере усложняет модель и увеличивает затраты на её обработку. А какова эффективность использования такого объема данных на текущей стадии?
Анализ предшествующих состояний окружающей среды необходим для прогнозирования её последующих состояний. Но у нас уже есть информация о будущих состояния в виде эмбединга.
Анализ совершенных ранее действий Агента может указать на используемую политику. Но нам необходимо дать информацию Агенту для принятия решения о необходимости изменения используемых навыка и политики поведения.
А вот информация о текущем состоянии счета может быть полезна. Наличие свободной маржи укажет нам на возможность открытия дополнительных позиций при благоприятных тенденциях. А может ожидается изменения тенденций, и нам предстоит закрывать ранее открытые позиции с фиксацией накопленных прибылей и убытков. Кроме того, не забываем про штрафы за отсутствие открытых позиций, что так же скажется на вознаграждении.
Таким образом, на слой исходных данных мы подаем текущее описание состояния счета и открытых позиций.
bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Полученные данные проходят через слой пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
И далее мы объединяем 2 потока информации в слое конкатенации.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = SIGMOID; if(!value.Add(descr)) { delete descr; return false; }
Затем информация поступает в блок принятия решений из полносвязных слоев.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
И на выходе модели мы получаем вектор ожидаемых вознаграждений.
2.2. Советник предварительного обучения
После создания архитектуры используемых моделей мы переходим к непосредственной реализации алгоритма метода PDT. И, разумеется, мы начинаем с советника предварительного обучения "...\PDT\Pretrain.mq5". Как уже было сказано выше, в данном советнике осуществляется предварительное обучение 3 моделей: Актера, планировщик и кодировщик будущего.
CNet Agent; CNet Planner; CNet FutureEmbedding;
В методе инициализации советника мы сначала загружаем обучающую выборку.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Пробуем загрузить предварительно обученные модели и, при необходимости, инициализируем новые модели согласно вышеописанной архитектуре.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true) || !FutureEmbedding.Load(FileName + "FEm.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *planner = new CArrayObj(); CArrayObj *future_embedding = new CArrayObj(); if(!CreateDescriptions(agent, planner, future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } if(!Agent.Create(agent) || !Planner.Create(planner) || !FutureEmbedding.Create(future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } delete agent; delete planner; delete future_embedding; //--- }
После чего переносим все модели в один контекст OpenCL.
//---
COpenCL *opcl = Agent.GetOpenCL();
Planner.SetOpenCL(opcl);
FutureEmbedding.SetOpenCL(opcl); Тут же осуществляем минимальный контроль архитектуры моделей.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the worker does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
И инициализируем запуск процесса предварительного обучения, который реализован в методе Train.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
В методе деинициализации советника в обязательном порядке сохраняем обученные модели.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Planner.Save(FileName + "Pln.nnw", 0, 0, 0, TimeCurrent(), true); FutureEmbedding.Save(FileName + "FEm.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Процесс обучения моделей реализован в методе Train. В теле метода мы сначала определяем размер буфера воспроизведения опыта.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
А затем организовываем системы вложенных циклов обучения моделей. Внешний цикл ограничивается числом итераций обучения, заданном во внешнем параметре советника. В теле этого цикла мы сначала сэмплируем траекторию из буфера воспроизведения опыта и отдельное состояние окружающей среды на выбранной траектории для начала процесса обучения.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20 + ValueBars))); if(i < 0) { iter--; continue; }
После чего мы организовываем вложенный цикл для последовательного обучения модели DT.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state); if(!Planner.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
В теле цикла мы записываем в буфер исходных данных исторические данные о движении цены и показателей индикаторов. И здесь стоит обратить внимание, что этих данных уже достаточно для осуществления прямого прохода модели прогнозирования (Планировщика). Данную операцию мы осуществляем первой. После чего продолжаем заполнения буфера исходных данных для нашего Актера. Добавляем состояние счета.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Временную метку и последние действия Агента.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Теперь, для выполнения прямого прохода Актера нам не хватает лишь эмбединга будущего. У нас, конечно, есть буфер результатов Планировщика, но на данном этапе результат работы необученной модели ничем не обусловлен. Согласно алгоритму PDT нам необходимо загрузить информацию о последующих состояниях и сгенерировать эмбединг полученных данных.
//--- Target Result.AssignArray(Buffer[tr].States[state + 1].state); for(int s = 1; s < ValueBars; s++) Result.AddArray(Buffer[tr].States[state + 1].state); if(!FutureEmbedding.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Результат работы кодировщика мы подаем на 2 вход модели Актера и вызываем его прямой проход.
FutureEmbedding.getResults(Result); //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После осуществления прямого прохода всех используемых моделей мы переходим к их обучению. И первым метод обратного прохода мы вызываем для модели Планировщика (прогнозирования будущего). Такая последовательность продиктована готовностью вектора целевых результатов, который мы только что подавали на вход Актера.
//--- Planner Study if(!Planner.backProp(Result, NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Затем мы переходим к подготовке целевых результатов нашего Актера. Для этого мы используем действия из буфера воспроизведения опыта, которые привели к известным последствиям.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result);
После подготовки целевых значений мы осуществляем обратный проход Актера и тут же пропускаем градиент ошибки через модель кодировщика будущего.
if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После чего нам остается лишь проинформировать пользователя о ходе выполнения операций и перейти к новой итерации.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Planner", iter * 100.0 / (double)(Iterations), Planner.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
При завершении всех итераций системы циклов мы очищаем поле комментариев на графике. Выводим результаты обучения в журнал и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Planner", Planner.getRecentAverageError()); ExpertRemove(); //--- }
Все остальные методы советника перенесены без изменений из рассмотренных в предыдущих статьях советников обучения "...\Study.mq5". И мы не будем сейчас на них останавливаться. Вы можете самостоятельно ознакомиться с полным кодом программы во вложении. А мы переходим к следующему этапу нашей работы.
2.3. Советник тонкой настройки
После завершения реализации алгоритма предварительного обучения мы переходим к работе над созданием советника тонкой настройки "...\PDT\FineTune.mq5", в котором построим алгоритм дообучения моделей.
Сразу скажу, что советник приблизительно на 90% повторяет предыдущий. Поэтому мы не будем полностью рассматривать его методы. А остановимся лишь точечно на внесенных изменениях.
Как уже было сказано в теоретической части данной статьи, методом PDT на данном этапе предусмотрена оптимизация моделей к решению поставленной задачи. Это означает, что мы будем использовать размеченные данные и вознаграждения, полученные от окружающей среды, для оптимизации политики нашего Агента. Для этого в процесс обучения мы добавляем ещё одну модель прогнозирования внешнего вознаграждения.
CNet RTG;
И здесь мы именно добавляем модель, оставляя использование моделей из предыдущего советника без изменений.
Обращаю Ваше внимание, что в советнике тонкой настройки я оставил механизм создание новых моделей Агента, Планировщика и кодировщика будущего при невозможности загрузки предварительно обученных моделей. Тем самым предоставляя возможность пользователю обучения моделей "с нуля". При этом загрузка и, при необходимости, инициализация новой модели прогнозирования внешнего вознаграждения в методе инициализации советника вынесены в отдельный блок. Ведь при переходе от предварительного обучения к тонкой настройке мы будем иметь обученные в предыдущем советнике модели. А вот модель прогнозирования вознаграждения будем инициализировать случайными параметрами.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- if(!RTG.Load(FileName + "RTG.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *rtg = new CArrayObj(); if(!CreateValueDescriptions(rtg)) { delete rtg; return INIT_FAILED; } if(!RTG.Create(rtg)) { delete rtg; return INIT_FAILED; } delete rtg; //--- } //--- COpenCL *opcl = Agent.GetOpenCL(); Planner.SetOpenCL(opcl); FutureEmbedding.SetOpenCL(opcl); RTG.SetOpenCL(opcl); //--- RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Мы так же переводим все модели в единый контекст OpenCL и проверяем соответствие слоя результатов добавленной модели размерности вектора декомпозированного вознаграждения.
В методе обучения моделей Train мы также внесли точечные дополнения. После прямого прохода Агента мы добавили вызов прямого прохода модели прогнозирования вознаграждения. Как мы обсуждали выше, на вход модели подаем вектор описания состояния счета и эмбединг будущего.
........ ........ //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return-To-Go Account.AssignArray(Buffer[tr].States[state + 1].account); if(!RTG.feedForward(GetPointer(Account), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
Обновление параметров модели осуществляется так же после обновления параметров Агента. При этом алгоритм оптимизации моделей практически идентичен. Вызывая метод обратного прохода модели, мы осуществляем передачу градиента ошибки на модель кодирования будущего с последующим обновлением её параметров. Разница лишь в целевых значениях. Такой подход позволяет нам обучить зависимости действий Агента и получаемого внешнего вознаграждения от эмбединга будущего.
........ ........ //--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return To Go study vector<float> target; target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars); Result.AssignArray(target); if(!RTG.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
На этом завершаются наши точечные изменения. А с полным кодом советника, как и всех используемых в статье программ Вы можете познакомиться во вложении.
2.4. Советник тестирования обученных моделей
После обучения моделей в рассмотренных выше советниках нам необходимо будет провести проверку результативности полученных моделей на исторических данных, не входящих в обучающую выборку. Для реализации этого функционала мы создадим советник "...\PDT\Test.mq5". В отличии от выше рассмотренных советников, в которых осуществлялось офлайн обучение моделей, советник тестирования осуществляет онлайн взаимодействие с окружающей средой. Это отражается в построении его алгоритма.
В методе инициализации советника OnInit мы сначала инициализируем объекты анализируемых индикаторов.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Создаем объект торговых операций.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
И загружаем обученные модели. Здесь мы используем только 2 модели: Актера и Планировщика. И, в отличии от предыдущих советников, ошибка загрузки моделей ведет к прерыванию работы советника. Ведь в нем мы не реализовывали онлайн обучение моделей.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Can't load pretrained model"); return INIT_FAILED; }
После успешной загрузки моделей мы переводим их в один контекст OpenCL и осуществляем минимально-необходимый контроль архитектуры.
Planner.SetOpenCL(Agent.GetOpenCL()); Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear();
В завершении метода мы инициализируем переменные начальными значениями.
AgentResult = vector<float>::Zeros(NActions); PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Процесс непосредственного взаимодействия с окружающей средой реализован в методе обработки тиков OnTick. В теле метода мы сначала проверяем наступление события открытия нового бара. Напомню, что все наши модели анализируют закрытые свечи и осуществляют торговые операции на открытии нового бара.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Далее мы запрашиваем из терминала необходимые данные на анализируемую глубину истории. В данном случае под глубиной истории мы подразумеваем размер одного паттерна, что в нашем случае составляет один бар. Глубина анализируемой Агентом истории содержится в его латентном состоянии в виде эмбедингов и повторно не обрабатывается на каждом баре.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Далее нам предстоит перенести полученные данные в буфер для передачи в модель.
//--- History data float atr = 0; for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Полученных исторических данных нам достаточно для осуществления прямого прохода Планировщика, что мы и осуществляем.
if(!Planner.feedForward(GetPointer(bState), 1, false)) return;
Однако для полноценного функционирования Агента нам требуется дополнительная информация. Сначала мы добавляем в буфер информацию о состоянии счета, которую предварительно запрашиваем в терминале.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Далее мы добавляем метку времени и последние действия Агента.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
В отдельный буфер получаем результаты ранее выполненного прямого прохода Планировщика и вызываем метод прямого прохода Агента.
//--- Return to go Planner.getResults(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, Result)) return;
После чего обновляем переменные, необходимые для операций на следующем баре.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
На этом первый этап анализа исходных данных завершен. И мы переходим к этапу взаимодействия с окружающей средой. Здесь мы получаем результаты прямого прохода Агента и дешифруем их в вектор предстоящих операций. Как обычно, мы исключаем перекрывающиеся объемы и оставляем разницу в направлении более вероятного движения.
vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp;
Затем мы корректируем нашу позицию в рынке в соответствии с прогнозными значениями. Сначала корректируем свою длинную позицию.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
И повторяем операции для противоположного направления.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Результаты взаимодействия с окружающей средой мы компонуем в структуру и сохраняем в траекторию, которая позже будет добавлена в буфер воспроизведения опыта для последующей оптимизации политики моделей.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
На этом мы завершаем работу по реализации метода Pretrained Decision Transformer средствами MQL5. А с полным кодом всех используемых в статье программ вы можете ознакомиться во вложении.
3. Тестирование
После завершения работы над реализацией рассмотренного метода нам предстоит обучить модель и проверить её результативность на исторических данных. Как обычно, для обучения и тестирования моделей мы используем один из наиболее волатильных инструментов EURUSD и тайм-фрейм H1. Обучение моделей осуществляется на исторических данных за первые 7 месяцев 2023 года. А для проверки результативности обученных моделей я использовал исторические данные Августа 2023 года.
И перед началом этапа предварительного обучения моделей нам необходимо собрать набор обучающих данных. Как уже было сказано ранее, в данной работе я использовал набор обучающих данных из предыдущей статьи, где и описан весь процесс. Я лишь создал копию файла обучающей выборки с именем "PDT.bd".
После чего запустил советник предварительного обучения в режиме реального времени.
Напомню, что все советники обучения моделей работают на онлайн графиках. При этом весь процесс обучения проходит офлайн без совершения торговых операций.
Надо сказать, что на этом этапе нужно запастить терпением. Процесс предварительного обучения довольно длительный. И я оставлял компьютер включенным более суток.
Далее мы переходим к процессу тонкой настройки. И тут авторы метода говорят об онлайн обучении. Я же чередовал не длительное дообучение модели с проходом тестирования на интервале обучения в тестере стратегий. Но первично было "прогревание" модели на ранее собранной обучающей выборке.
Для периода тонкой настройки мне потребовалось несколько десятков последовательных итераций дообучения и тестирования моделей, что так же потребовало времени и усилий.
Однако результаты обучения были не столь радужными. В результате обучения я получил модель, торгующую минимальным объемом с переменным успехом. На некоторых участках истории линия баланса демонстрировала явную тенденцию к росту. На других наблюдается спад. В целом результаты работы модели как на обучающих данных, так и на новых были близки к "0".
К положительным моментам можно отнести способность модели переносить полученный опыт на новые данные, что подтверждается сопоставимостью результатов тестирования на участке исторических данных обучающей выборки и на последующем интервале истории. Кроме того, можно отметить значительное превышения размера прибыльной сделки над убыточной. На обоих участках исторических данных мы наблюдаем, что размер средней прибыльной сделки превышает максимальный убыток. Однако, все положительные моменты нивелируются низкой долей прибыльных сделок, которая составляет чуть менее 40% на обоих исторических интервалах.


Так при тестировании модели на исторических данных за Август 2023 года (новые данные) модель совершила 18 сделок. И только 39% из них были закрыты с прибылью. При этом максимальная прибыльная сделка составила 11.26, что почти в 3 раза превышает максимальный убыток 4.76. А средняя прибыльная сделка составила 5.15 при среднем убытке 3.19. Профит фактор за период тестирования составил 1.03.
Очевидно, что для повышения доли прибыльных сделок требуется дополнительный анализ полученных результатов и тонкая настройка модели. Метод демонстрирует потенциал, но требуется длительный период обучения моделей.
Заключение
В этой статье мы познакомились с методом Pretrained Decision Transformer (PDT), который предоставляет алгоритм предварительного обучения без учителя для обучения с подкреплением Decision Transformer. Основываясь на знаниях о будущих состояниях в процессе обучения моделей, PDT способен извлекать богатые априорные знания из обучающих данных. Эти знания могут быть дополнительно настроены и скорректированы на этапе дообучения моделей, поскольку PDT ассоциирует каждую будущую возможность с соответствующим возвратом и выбирает с максимальным прогнозируемый вознаграждением. Что позволяет принимать оптимальные решения.
Однако PDT требует больше времени на обучение и вычислительных ресурсов по сравнению с ранее рассмотренными DT и ODT, что может привести к практическим трудностям вследствие ограниченности доступных ресурсов. Кроме того, цель, обучения моделей создает компромисс между разнообразием изучаемых поведений и их согласованностью. Практические эксперименты авторов метода свидетельствуют, что оптимальное значение зависит от конкретного набора данных. И для улучшения кодирования будущих состояний, могут быть применены дополнительные техники.
Не могу не согласиться с выводами авторов метода. Наш практический опыт полностью подтверждает сказанное. Обучение моделей довольно длительное и трудоемкое. Для развития максимального разнообразия навыков Агента необходима довольно обширная обучающая выборка. Конечно, для предварительного обучения мы используем не размеченные данные, что облегчает процесс сбора данных. Но остается открытым вопрос доступности ресурсов для сбора, обработки данных и обучения моделей.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Faza1.mq5 | Советник | Советник сбора примеров |
| 2 | Pretrain.mq5 | Советник | Советник предварительного обучения |
| 3 | FineTune.mq5 | Советник | Советник тонкой настройки |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования