
Квантование в машинном обучении (Часть 2): Предобработка данных, отбор таблиц, обучение моделий CatBoost

Введение
В настоящей статье речь пойдёт о практическом применении квантования при построении древовидных моделей. Материал будет подан без сложных математических формул, доступным языком. Эта статья является второй частью статьи "Квантование и иные способы предобработки входных данных в машинном обучении", поэтому настоятельно рекомендую начать знакомства с неё, а тут мы поговорим о следующем:
- В первой части познакомимся с реализованными на MQL5 методами предобработки данных выборки.
- Во второй части проведём эксперимент, который даст информацию о целесообразности проведения квантования данных.
1. Дополнительные методы предобработки данных
На примере описания функционала скрипта "Q_Error_Otbor" познакомимся с реализованными мной методами предобработки данных.
Если кратко описать цель работы скрипта "Q_Error_Otbor", то ей является загрузка выборки из файла "train.csv", перенес содержимого в матрицу, предобработка данных, и поочередная загрузка квантовых таблиц и их оценка ошибки восстановленных данных относительно оригинальных для каждого предиктора. Результаты оценки каждой квантовой таблицы будем сохранять в массив. После проверки всех вариантов создадим сводную таблицу с ошибками для каждого предиктора, отберём по заданному критерию лучшие варианты квантовых таблиц для каждого предиктора. Создадим и сохраним сводную квантовую таблицу, файл с настройками CatBoost, в который будут добавлены исключённые из перечня для обучения предикторы, с указанием порядковых номеров их столбцов. А так же созданы иные сопутствующие файлы, в зависимости от выбранных настроек скрипта.
Давайте подробней изучим настройки скрипта, которые я перечислил ниже по группам.
Загрузка данных
- Директория с выборкой1
- Директория для квантования2
1 Указываем путь к директории, где находится директория "Setup", в которой находятся файлы csv с выборкой. Данная директория будет упоминаться далее как "директория проекта".
2 Указываем путь к директории, где находится директория "Q", в которой находятся файлы csv с квантовыми таблицами.
Настройка обработки выбросов
- Использовать проверку на выбросы1
- Метод преобразования выбросов:2
- Значение выбросов преобразовываются в близкое к сплиту значение2.1
- Значение выбросов преобразовываются в случайное значение в диапазоне вне выбросов2.2
- Заменить данные после обработки выбросов3
- Сохранять или нет выборку train с преобразованными выбросами4
- Добавить информацию в подвыборки о выбросах5
- Удалить строки с большим числом выбросов5.1
- Максимальный процент выбросов предикторов в строке выборки5.2
1 При выборе значения "true" активируется обработка выбросов. Выбросами тут считаются редкие значения предикторов. Редкие значения могут быть статистически незначимыми, но в моделях, как правило, это не учитывается, что может привести к образованию сомнительных правил оценки вероятности классификации. На рисунке №1 можно видеть пример такого выброса. С помощью установки границ, разделяющих выбросы и нормальные данные мы сможем агрегировать выбросы в единое целое, за счёт чего возрастёт статистическая достоверность и с данными можно будет попробовать работать как с нормальными, либо полностью исключить их из обучения.
2 Выбираем один из методов преобразования выбросов, с помощью которого значение предиктора будет изменено, что позволит учитывать этот пример в выборке для обучения, а не исключать его, как аномальный. Для определения выбросов я использовал 2.5% данных для каждой из сторон числового ряда. Отмечу, что предварительно встречающиеся одинаковые значения чисел были сгруппированы и группам присвоены ранги, и если следующий ранг превышает 2,5%, то последним рангом с выбросами считается прошлый ранг. Предикторы, в которых мало рангов признаются категориальными и в них не производится обработка выбросов. Информация в виде списка категориальных предикторов сохраняется по следующему пути относительно директории проекта "..\CB\Categ.txt". Распространённым методом определения выбросов является правила трёх сигм, это когда от среднего значения делается отступ в три стандартных отклонения в левую и правую область данных и всё, что находится за пределами такой границы, считается выбросом. На графиках ниже можно будет видеть чёрным цветом три горизонтальные линии – центр, разницу и сумму трёх сигм от центра. Синие же линии на графике будут означать границы, в пределах которых находятся часто встречающиеся данные по предложенному мной алгоритму.
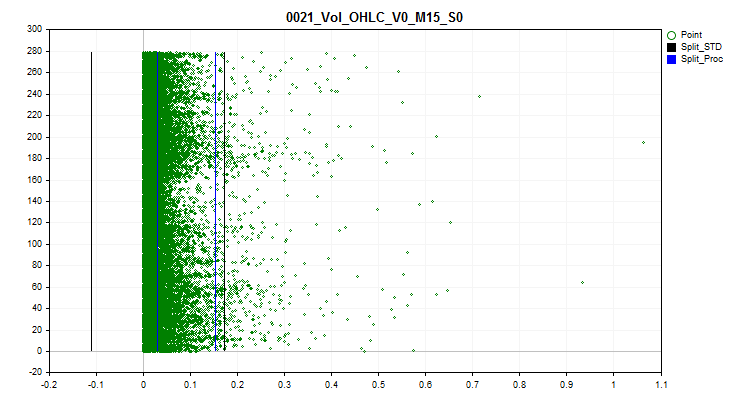
Рисунок 1 "Определение границ определения выбросов"
2.1 Данный метод заменяет все значения выброса на близкое к границе (сплиту) значение. Такой подход позволяет не искажать оценку аппроксимации квантовой таблицей внутри границ выброса.
Рисунок 2 "Значение выбросов преобразовываются в близкое к сплиту значение"
2.2 Данный метод заменяет все значения выброса на случайные значения, согласно рангов, внутри границ с нормальными данными. Такой подход позволяет рассеять ошибку оценки аппроксимации квантовой таблицей.
Рисунок 3 "Значение выбросов преобразовываются в случайное значение в диапазоне вне выбросов"
3 Если необходимо провести оценку и выбор квантовых таблиц с учётом преобразованных выбросов, то выбираем "true". При активации данной функции массив в виде матрицы с исходными данными будет изменён, значение предикторов с выбросами станут теми, что были выбраны согласно методу преобразования выбрасов.
4 Можно сохранить выборку train.csv, она сохранится в директорию "..\CB\Q_Vibros_Viborka". Это может понадобиться для проведения квантования с помощью CatBoost, так как данные уже будут изменены на преобразованные, то и таблицы квантования могут отличаться, а так же это может позволить уменьшить число разделителей (сплитов) для достижения минимального порога ошибки при оценке качества аппроксимации квантовой таблицей.
5 Активация данной настройки и установка переменной в положение "true" приведет к последовательной загрузке файлов с подвыборками train.csv, test.csv и exam.csv. В каждой строке подвыборки будет произведён подсчёт числа значений предикторов в области выброса, суммарный результат будет записан в дополнительно созданный столбец "Proc_Vibros". Изменённая выборка будет сохранена в директорию "..\CB\ADD_Drop_Info_Viborka".
Вне зависимости от активации данной настройки будет создан отдельный файл в директории проекта по следующему пути "..\CB\Proc_Vibros_Train.csv". Данный файл содержит только информацию о выбросах в выборке train.
5.1 Активация данной настройки приведёт к удалению строк с выбросами из выборок. Иногда стоит попробовать обучать модель на данных без выбросов.
5.2 Если решили удалять строки с выбросами, то стоит оценить процент предикторов, значение которых оказалось в зоне определения выброса.
Настройка оценки корреляции
- Использовать оценку корреляции для исключения предикторов1
- Метод исключения коррелирующих предикторов - определяет метод отбора (исключения предикторов) на выбор:2
- Обратный отбор предикторов2.1
- Отбор обобщающих предикторов2.2
- Отбор редких предикторов2.3
- Коэффициент корреляции3
1 При выборе значения "true" активируется оценка корреляции Пирсона. Результатом работы данного функционала будет получение таблицы корреляции предикторов по следующему пути "../CB" где имя файла состоит из имени "Corr_Matrix_" и размера коэффициента корреляции, "Corr_Matrix_70.csv". Сильно коррелирующие предикторы будут исключены.
2 На выбор предлагается три метода исключения предикторов.
2.1 Данный метод ищет в обратном порядке коррелирующие предикторы, и если есть более ранний, то текущий столбец с предиктором исключается из обучения.
2.2 Данный метод делает оценку числа коррелирующих предикторов с каждым предиктором и итеративно выбирает тот, который коррелирует с большим числом предикторов, исключая коррелирующие с ним другие предикторы. Логика тут в том, что отбираем предикторы с информацией, в наибольшей мере вмещающие информацию лругих предикторов, получается такое обобщение информации.
2.3 Даный метод похож на предыдущий, но тут напротив отбираем те предикторы, которые имеют наименьшую похожесть с другими. Тут происходит попытка напротив – найти предиктор с уникальной информацией.
3 Тут следует указать коэффициент корреляции Пирсона. Только достигнув или преодолев указанное значение коэффициента, предикторы считаются похожими для проведения манипуляций над ними для исключения из выборки.
Настройка обработки нестабильных во времени предикторов
- Использовать проверку на среднее значений в каждой части выборки1
- Процент разброса средних значений подвыборок2
1При выборе значения "true" активируется проверка на колебание среднего значения показателя предиктора на каждой из 1/10 части выборки. Данная проверка позволяет исключить предикторы, показатели которых сильно смещаются со временем. Подобные предикторы, теоретически, препятствуют обучению. Пример такого предиктора можно видеть на рисунке №4, а визуально процесс оценки на рисунке №5. Приведенный в пример предиктор был построен на базе индикатора Variable Index Dynamic Average (iVIDyA), который, по сути, показывает усреднённое значение цены, и его использование в модели будет приводить к заучиванию поведения при определённой абсолютной цене.
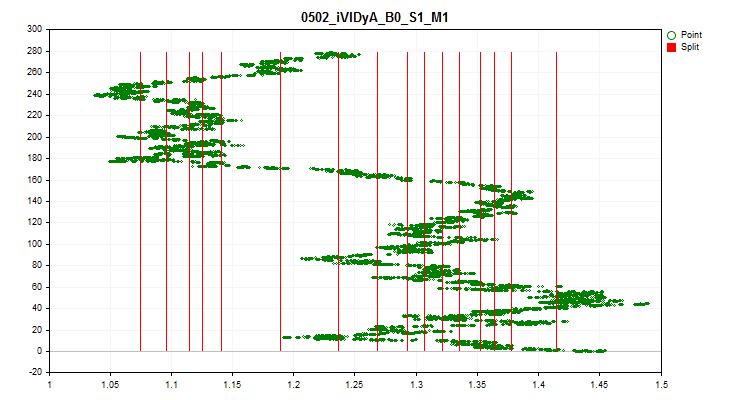
Рисунок №4 "Предиктор iVIDyA_B0_S1_M1 имеет сильное смещение"
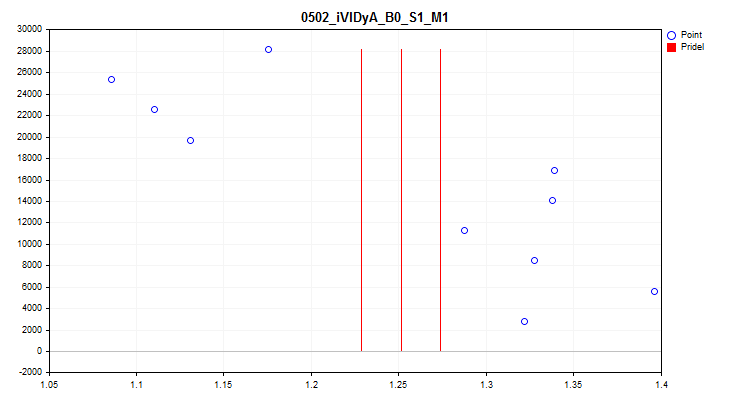
Рисунок №5 "Предиктор iVIDyA_B0_S1_M1 разброс среднего значения"
2 Здесь указывается ширина диапазона в процентах для каждой границы, которая определяется от всего диапазона значений предиктора – относительно среднего значения на всём периоде.
Настройка создания равномерной квантовой таблицы
- Создать равномерную квантованную таблицу1
- Число интервалов, на которые надо разделить (отквантовать) исходные данные2
1 При выборе значения "true" активируется алгоритм создания равномерной квантовой таблицы для всех предикторов в выборке. Таблица будет сохранена в поддиректорию проекта "Q_Bit".
2 Указывается число интервалов, на которые будет поделён предиктор.
Настройка создания квантовой таблицы с элементом случайности
- Создать случайную квантовую таблицу1
- Инициализирующее число для генератора случайных чисел2
- Число итераций для поиска лучшего варианта3
- Число интервалов, на которые надо разделить (отквантовать) исходные данные4
1 При выборе значения "true" активируется алгоритм создания случайной квантовой таблицы для всех предикторов в выборке. Таблица будет сохранена в поддиректорию проекта "Q_Random".
2 Номер даёт возможность сделать результат случайной генерации повторяемым. Меняя номер можно изменить последовательности генерируемых чисел.
3 Алгоритм производит оценку ошибки аппроксимации после каждой генерации случайной таблицы и выбирает лучший вариант. Чем больше попыток, тем больше шанс найти наиболее удачный вариант.
4 Указывается число интервалов, на которые будет поделён предиктор.
Настройка отбора квантовых таблиц
- Начать отбор квантовых таблиц1
- Использовать порог для отбора предиктора2
- Максимальная допустимая ошибка квантования3
1 При выборе значения "true" активируется алгоритм перебора и оценки квантовых таблиц из поддиректории "Q" проекта, иначе программа прекратит свою работу. Результатом выполнения этой функции скрипта будет создание двух директорий:
В директории "..\CB\Setup" будет находится 3 файла:
- "Auxiliary.txt" – вспомогательный файл с номерами индексов предикторов, которые были исключены
- "Quant_CB.csv" – файл с квантовыми таблицами для предикторов, которые будут участвовать в обучении
- "Test_CB_Setup_0_000000000" – файл с информацией для CatBoost – какие столбцы исключить из обучения, какой столбец считать целевой.
В директории "Test_Error" будет находиться файл "arr_Svod.csv" - он содержит сводные результаты вычисления ошибки восстановления (аппроксимации) для каждого предиктора при применении разных таблиц квантования. Первый столбец содержит перечень предикторов, последующие результат при применении конкретной квантовой таблицы, а последний столбец содержит индекс квантовой таблицы, который показал лучший результат. Лучший результат использовался для создания сводной квантовой таблицы "Quant_CB.csv".
2 Если значение настройки находится в положении "false", то для оценки квантовых таблиц используется только ошибка восстановления (аппроксимации), выбирается та таблица, при использовании которой получена наименьшая ошибка.
Если значение настройки находится в положении "true", то для оценки квантовых таблиц используется ошибка восстановления (аппроксимации) поделённая на число сплитов в квантовой таблице. Такой подход позволяет учесть при оценке число квантовых таблиц, что бы избежать ситуации избыточного квантования. Таблицы будут участвовать в отборе только, если их ошибка будет ниже заданной в следующем параметре настроек.
3 Здеь указываем максимальную допустимую ошибку восстановления (аппроксимации) значений предиктора.
Настройка сохранения преобразованной выборки
- Преобразовать и сохранить выборку1
- Вариант преобразования данных:2
- Сохранить в виде индексов2.1
- Сохранить в виде центройдов2.2
1 При выборе значения "true" выборка (три файла csv) будет преобразована и сохранена в поддиректорию проекта "..\CB\Index_Viborka". Данная настройка даёт возможность использовать квантовые таблицы в тех алгоритмах машинного обучения, где они изначально небыли предусмотрены. Другой способ применения – публичный обмен данными для обучения моделей без раскрытия показателей предикторов, что может защитить от раскрытия конкурентной информации об используемых источниках данных. Кроме того, сохранение в виде индексов способно существенно уменьшить объём занимаемого места на диске файлами выборки, а так же уменьшить объём ОЗУ для проведения манипуляций с выборкой.
2 Выбираем один из двух вариантов преобразования значений предикторов, после применения итоговой сводной таблицы квантования.
2.1 Будут сохранятся значение индексов отрезков квантовой таблицы, в диапазон которых попадает число предиктора.
2.2 Будет сохраняться значение между двух границ, к диапазон которых попадает число предиктора.
Настройка сохранения графиков
- Сохранять графики1
- Ширина графика2
- Высота графика3
- Размер шрифта в легенде4
1 При выборе значения "true" активируется функция создания и сохранения графиков. В директории "Grafics" будут созданы графические файлы, содержащие информацию о каждом предикторе в выборке. Имя файла начинается с номера предиктора, потом указывается название предиктора из заголовка столбца выборки, а после условное имя графика. Рассмотрим графики, полученные для предиктора "iCCI_B0_S1_M1":
- Первый график показывает плотность значений предиктора на конкретном интервале – чем больше плотность, тем сильней будет кривая графика наклонёна вверх на этом интервале. По оси X – значение предиктора, а по оси Y – упорядоченный по своему значению номер наблюдения. С помощью графика можно оценить плотность наблюдений в выборке, приходящихся на конкретные интервалы и увидеть выбросы.
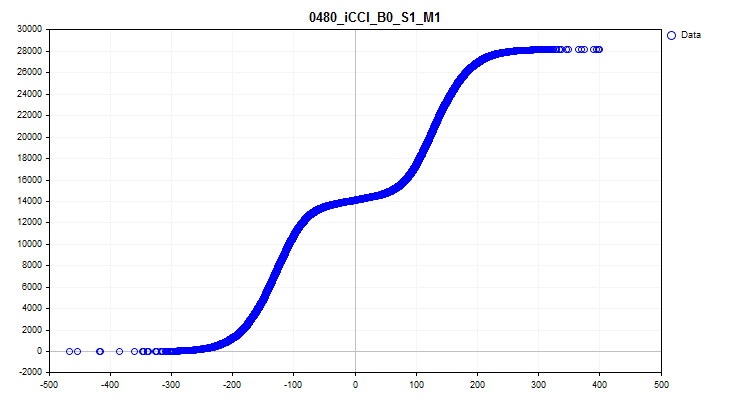
Рисунок №6 "Плотность значений предиктора"
- Второй график показывает, на каких интервалах наблюдались значения предикторов при целевой "0" и "1", в результате синим цветом представлены значения для нуля, а красным для единицы. Таким образом, есть возможность увидеть, на каких интервалах предиктора значение целевой представлена в большей мере. Рекомендую график строить шире, чем в иллюстрации для статьи.
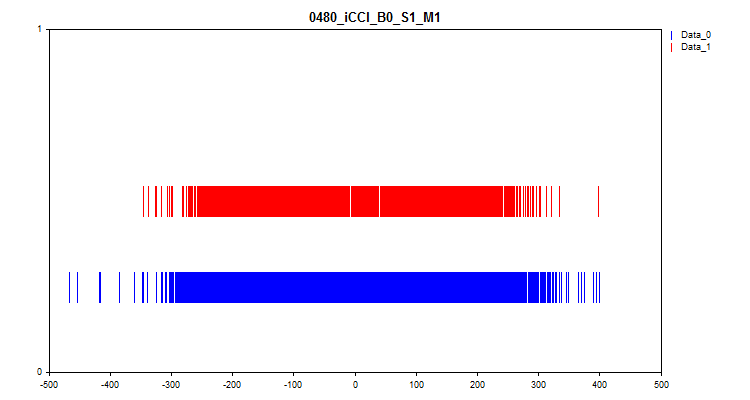
Рисунок №7 "Соответствие значения предиктора целевой разметке"
- Третий график строит гистограмму, при этом по оси Y откладывается процент наблюдений от всех наблюдений в выборке. График позволяет оценить выбросы, и сделать предположение о плотности распределения.
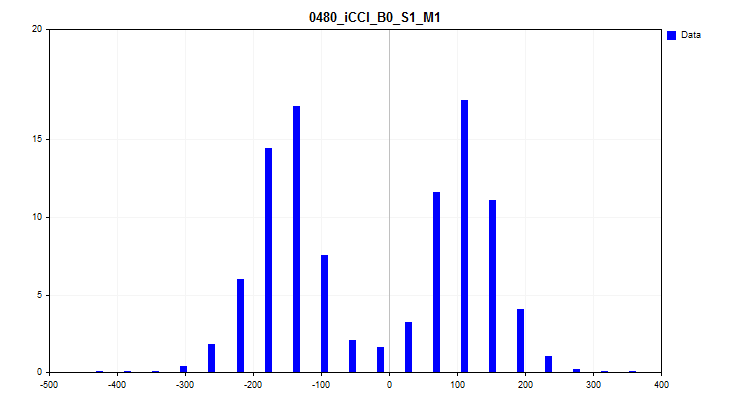
Рисунок №8 "Гистограмма плотности распределения"
- Четвёртый график показывает заполнение диапазона шкалы предиктора его значениями в хронологическом порядке, а так же показаны уровни, которые были отобраны для конечного квантования. По оси X – значение предиктора, а по оси Y –номер группы из 100 наблюдений.
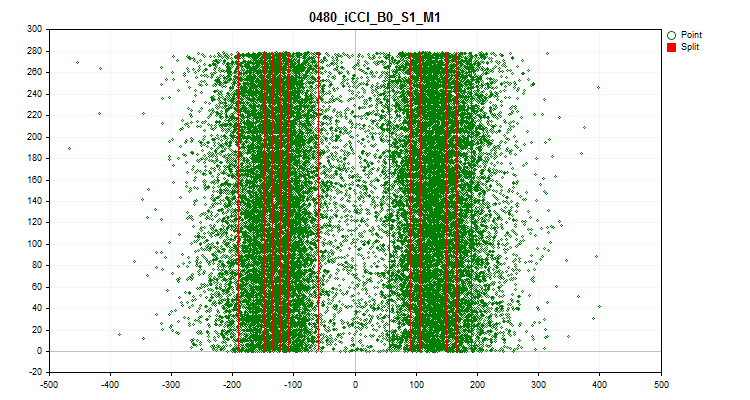
Рисунок №9 "Квантовая таблица"
- Пятый график показывает среднее значение предиктора за 10 интервалов выборки. При сильном разбросе предиктор рекомендуется исключить. По оси X – среднее значение предиктора, а по оси Y – номер группы из N наблюдений.
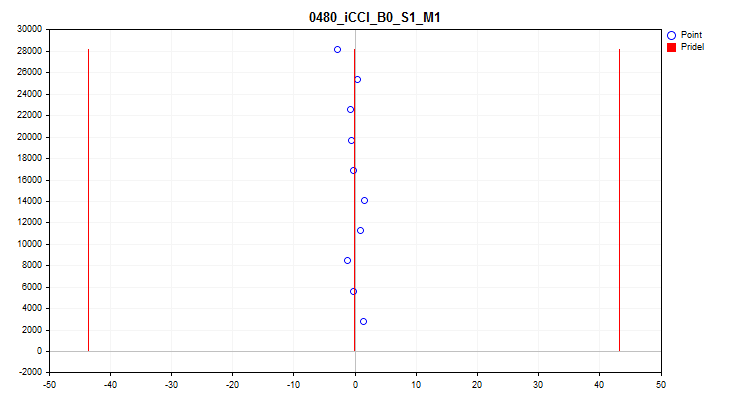
Рисунок №10 "Разброс среднего значения"
- Шестой график показывает предполагаемые выбросы. На график нанесены 3 черных линии – это среднее значение и плюс и минус три стандартных отклонения. Синие границы – это близкие к 2,5% наблюдений, отсчитанные от начала и конца диапазона выборки. По оси X – значение предиктора, а по оси Y –номер группы с фиксированным числом наблюдений.
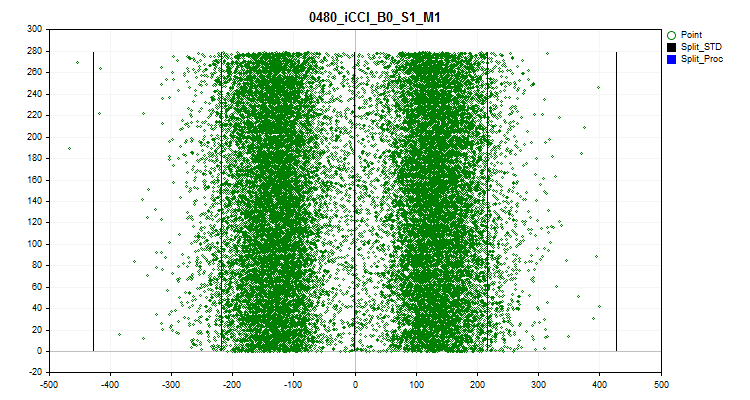
Рисунок №11 "Выбросы"
2 Указывается ширина графика в пикселях.
3 Указывается высота графика в пикселях.
4 Указывается размер шрифта и размер обозначений кривых в легенде графиков.
Настройка перебора сценариев настройки
- Перебрать сценарии настроек1
1 Активирует перебор настроек, согласно заложенному алгоритму - читайте далее в статье о деталях.
2. Проведение сравнительного эксперимента для оценки эффекта от квантования
Постановка эксперимента – цели
У нас есть инструмент, с немалым функционалом, пришло время оценить его возможности работе! Давайте проведём эксперимент, который даст ответы на волнующие вопросы:
- Есть ли смысл от всех этих действий и манипуляций с подбором квантовых таблиц для предикторов, может проще использовать настройки CatBoost по умолчанию?
- Сколько минимум нужно сплитов (границ) для достижения схожего результата, как и при настройках по умолчанию CatBoost?
- Стоит ли использовать такие методы квантования, как "равномерный" и "случайный"?
- Есть ли существенная разница между методами отбора квантовых таблиц?
Для ответа на данные вопросы понадобиться провести обучения с разными квантовыми таблицами, полученными при разных настройках скрипта "Q_Error_Otbor". Предлагаю перебирать следующие настройки:
Метод отбора:
- Для оценки квантовых таблиц используется только ошибка восстановления (аппроксимации).
- Для оценки квантовых таблиц используется ошибка восстановления (аппроксимации) поделённая на число сплитов в квантовой таблице, при этом максимальная ошибка равна 1%.
- Для оценки квантовых таблиц используется ошибка восстановления (аппроксимации) поделённая на число сплитов в квантовой таблице, при этом максимальная ошибка равна 0.5%.
Источник квантовых таблиц:
- Таблицы, полученные с помощью CatBoost.
- Таблицы, полученные методом равномерного квантования.
- Таблицы, полученные методом случайной постановки сплита.
Набор квантовых таблиц:
- Набор "1" - используются все имеющиеся квантовые таблице в директории источника.
- Набор "2" - используются только квантовые таблицы с 16 сплитами или интервалами.
- Набор "3" - используются только квантовые таблицы с 32 сплитами или интервалами.
- Набор "4" - используются только квантовые таблицы с 64 сплитами или интервалами.
- Набор "5" - используются только квантовые таблицы с 128 сплитами или интервалами.
- Набор "6" - используются только квантовые таблицы с 256 сплитами или интервалами.
Все комбинации настроек я привожу в таблице в виде рисунка №12, в коде данная задача реализовано в виде трёх вложенных циклов, меняющих соответствующие настройки, которая активируются установкой в настройках переменной с названием " Перебрать сценарии настроек " в режим true.
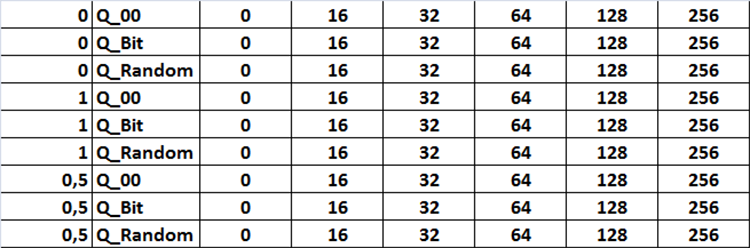
Рисунок №12 "Таблица комбинаций настроек перебора"
Будем обучать с каждой комбинацией настроек 101 модель, перебирая параметр Seed от 0 до 800 с шагом 8, что позволит усреднить полученный результат для оценки настроек с целью исключения случайного результата.
Вот такие показатели я предлагаю использовать для сравнительного анализа:
- Средняя прибыль всех моделей – показатель назовём "Profit_Avr";
- Среднее математическое ожидание моделей – показатель назовём "MO_Avr";
- Средняя точность классификации моделей – показатель назовём "Precision_Avr";
- Средняя полнота отзывов моделей – показатель назовём "Recall_Avr";
- Среднее число моделей, показавшее прибыль более 3000 единиц – показатель назовём "N_Exam_Model";
- Средняя максимальная прибыль из всех моделей – показатель назовём "Profit_Max".
После расчета показателей, предлагаю их суммировать и поделить на число показателей, таким образом, мы получим обобщающий показатель качества настройки отбора квантовых таблиц – назовём его просто "Q_Avr".
Подготовка данных к проведению эксперимента
Для получения выборки воспользуемся тем же советником и скриптами, что использовали ранее при знакомстве с CatBoost в статье "Машинное обучение от Яндекс (CatBoost) без изучения Python и R".
Я использовал следующие настройки:
А. Настройки тестера:
- Символ: EURUSD
- Тайм Фрейм: M1
- Интервал с 01.01.2010 по 01.09.2023
B. Настройки стратегии советника CB_Exp:
- Период: 104
- Тайм Фрейм: 2 Minutes
- Метод скользящих: Smoothed
- Ценовая база расчета: Close price
После получения выборки и разбития её на 3 части (train, test, exam), аналогичным способом, что я описывал ранее в своей статье, требуется получить квантовые таблицы. Для этой цели я модифицировал скрипт CB_Bat (приложен к данной статье) и теперь при выборе в настройке "Объект перебора" значения "Brut_Quantilization_grid" скрипт создаст файла "_01_Quant_All.txt". Настройки перебора диапазона остались прежними – задаётся начальное значение переменной, конечное значение переменной и шаг изменения, я использовал перебор от 8 до 256 с шагом 8. В результате работы скрипта будут подготовлены команды для получения таблиц квантования со всеми типами с заданным числом границ. Файл таблицы квантования будет иметь следующую структуру наименования: название файла в виде смыслового названия файла "quant", числа разделителей и порядкового номера типа разделения, связывать показатели будет нижнее подчёркивание, сами же файлы будут сохраняться в директорию "Q", которая там же где директория "Setup" проекта.
quant_"+IntegerToString(Seed,3,'0')+"_"+IntegerToString(ENUM_feature_border_type_NAME(Q),0)+".csv";
Получившемуся файлу "_01_Quant_All.txt", после отработки скрипта, необходимо сменить расширение на "*.bat", поместить в каталог с ним ранее указанную в скрипте версию CatBoost и запустить его – щелкнув два раза мышкой.
После работы скрипта в поддиректории "Q" появится набор файлов – это и есть таблицы квантования, с которыми мы будем дальше работать.

Рисунок № 13 "Cодержимое поддиректории Q"
С помощью скрипта "Q_Error_Otbor" генерируем равномерные и случайные квантовые таблицы с числом интервалов 16, 32, 64, 128, 256, соответствующие файлы появятся в директориях "Q_Bit" и "Q_Random". Сделаем копию директории "Q" в директорию проекта и назовём новую директорию "Q_00".
Отлично, у нас есть всё, что нужно для создания пакета заданий на обучение. Запускаем скрипт "Q_Error_Otbor" и в его настройках переключаем параметр "Перебрать сценарии настроек" в режим "true", нажимаем "Ok". Скрипт по заданному в коде сценарию создаст файлы с квантовой таблицей и настройками для обучения.
Для того, что бы при обучении использовать квантовые таблицы для каждой конфинурации настроек CatBoost скрипт к привычному названию квантовой таблицы "Quant_CB.csv" добавит ещё имя файла настройки.
Получим файлы для обучения с помощью скрипта "CB_Bat_v_02" – я выбрал перебор Seed от 0 до 800 с шагом 8, указал директорию проекта.
Теперь нужно немного отредактировать файл для обучения, заменив в нём имя файла "Quant_CB.csv" на такое "Quant_CB_%%a.csv", данное изменение позволит использовать в качестве переменной название настроек, от числа которых зависит количество циклов обучения. Копируем созданные файлы в директорию "Setup" проекта и запускаем обучение, переименовав файл "_00_Start.txt" в файл "_00_Start.bat" и нажав мышкой два раза на файл "_00_Start.bat".
Оценка результатов эксперимента
После окончания обучения, применим скрипт "CB_Calc_Svod", который посчитает метрики для каждой модели. Подробно настройки скрипта были ранее описаны в прошлой статье, поэтому не буду повторяться.
Также мной было проведено обучение 101 модели с настройками квантовой таблицы по умолчанию, и вот такие получились результаты:
- Profit_Avr=2810,17;
- МО_Avr=28,33;
- Precision _Avr=0,3625;
- Recall_Avr=0,023;
- N_Exam_Model=43;
-
Profit_Max=8026.
Давайте рассмотрим подробно таблицы результатов и графики для каждого показателя, прежде чем сделаем обобщающие выводы.
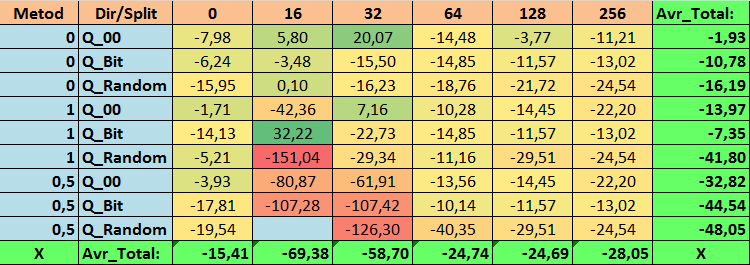
Таблица №14 "Сводные значения показателя Profit_Avr"
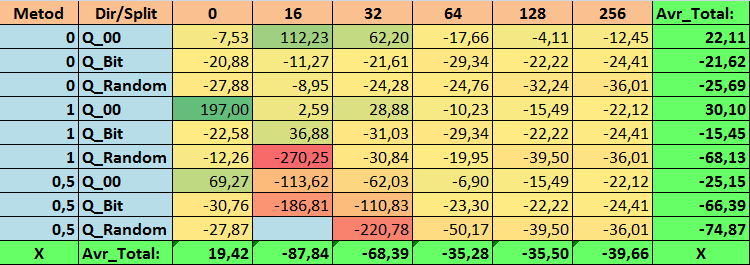
Таблица №15 "Сводные значения показателя МО_Avr"
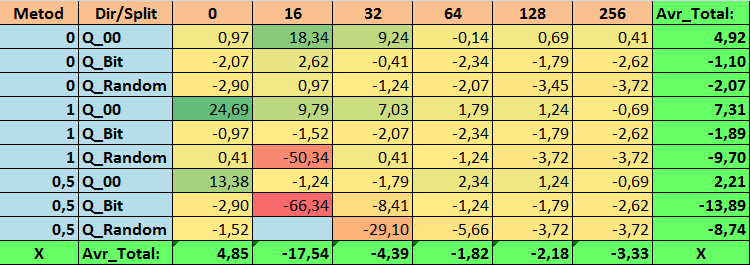
Таблица №16 "Сводные значения показателя Precision_Avr"
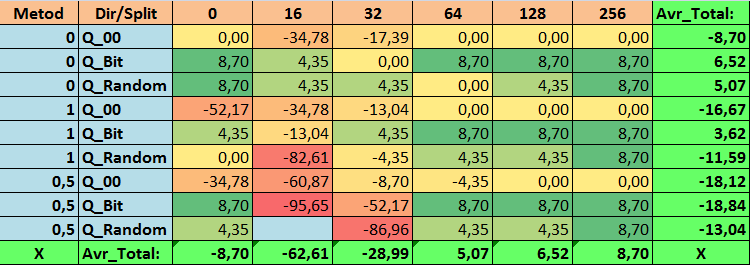
Таблица №17 "Сводные значения показателя Recall_Avr"
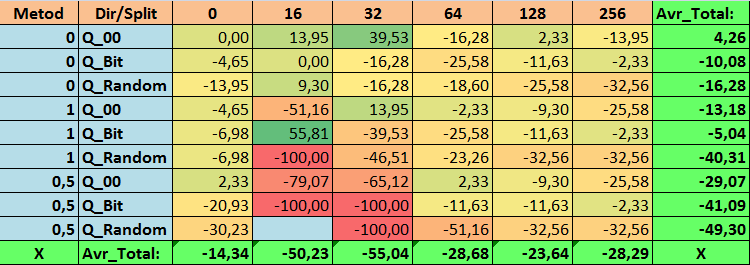
Таблица №18 "Сводные значения показателя N_Exam_Model"
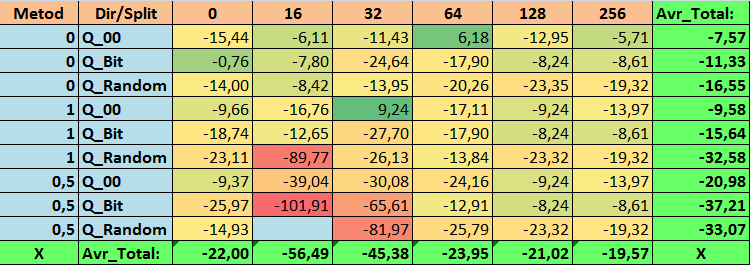
Таблица №19 "Сводные значения показателя Profit_Max"

Таблица №20 "Сводные значения показателя Q_Avr"
Обозрев наши информативные таблицы, мы смогли увидеть, что разброс показателей весьма велик, что говорит об эффекте влияния настроек в целом на результат обучения. Мы видим, что таблицы, полученные случайной постановкой сплита (Q_Random) показали самый слабый результат относительно квантовых таблиц, созданных иными методами. Интересным кажется то, что увеличение числа сплитов в основном ведёт к ухудшению показателей наших метрик, за исключением метрики Recall_Avr. Вероятно, это связано с тем, что информация в квантовых отрезках сильно разрознена, что приводит к только математическим манипуляциям при обучении, которое заканчивается ростом уверенности модели, но падением точности, а далее и средней прибыли. Тогда возникает справедливый вопрос "А как же модель обучается успешно с 254 сплитами по умолчанию?", что ж дело в том, что по умолчанию используется такой метод построения сетки, как GreedyLogSum, который, как мы уже видели ранее, строит сетку не с равномерным шагом. За счет того, что сетка построена не равномерно, часто выбранная нами метрика для оценки качества построения сетки показывает результат хуже, чем равномерная сетка, в результате чего при выборе таблиц квантования из набора, полученного всеми методами CatBoost, не часто выбирается именно такой метод, как GreedyLogSum. Мы даже можем посмотреть статистику, насколько часто выбирался данный метод. Так, для комбинации (0;Q_00;256) – это всего для 121 предиктора из 2408. А вот почему крайние участки диапазонов предикторов оказываются столь значимы - свои предположение напишите в комментариях к данной статье!
Хорошо, таблицы с большим количеством сплитов и со случайным способом постановки сплитов показали не очень хороший результат, а что же можно сказать про разницу методов отбора квантовых таблиц? Начнём с плохого - всё же требование к ошибке в 0,5% оказалось завышенным для значений таблиц от 16 до 64, в результате чего в обучении участвовало значительно меньше предикторов, чем есть изначально, но в то же время таблицы с большим числом сплитов успешно преодолевали этот порог, но как мы уже предположили, - это было не эффективно. Однако, при выборе из всех доступных таблиц (первый набор - по порядку) получились не плохие сбалансированные таблицы, особенно набор из таблиц CatBoost. В то же время метод отбора, предикторов заявляющий менее жесткие требования - минимум 1% ошибки при аппроксимации, показал себя, как решение, заслуживающее большего внимания.
Теперь давайте перейдём к ответу на поставленные вопросы - ведь именно ответ на них и является целью данного эксперимента.
Ответы на вопросы:
1. Используемая по умолчанию таблица квантования в CatBoost, объективно, показывает хороший результат на наших данных, но оказалось, что его можно значительно улучшить! Давайте рассмотрим показатели наших метрик для лучших методов получения квантовых таблиц:
- Profit _Avr - комбинация (1;Q_Bit;16) со значением на 32,22 % лучше базовых настроек.
- MO_Avr - комбинация (1;Q_00;0) со значением на 197,00 % лучше базовых настроек.
- Precision_Avr - комбинация (1;Q_00;0) со значением на 24,69 % лучше базовых настроек.
- Recall_Avr – комбинаций тут целая плеяда, и все со значением на 8,7 % лучше базовых настроек.
- N_Exam_Model - комбинация (1;Q_Bit;16) со значением на 55,81 % лучше базовых настроек.
- N_Profit_Max - комбинация (1;Q_00;32) со значением на 9,24 % лучше базовых настроек.
Таким образом, можно объективно дать положительный ответ на данный вопрос - стоит пробовать подбирать лучшие квантовые таблицы, что может улучшить результаты в важных для нас метриках.
2. Оказалось, что для нашей выборки достаточно всего 16 сплитов что бы получить хороший значения показателя Q_Avr, так для комбинации настроек (1;Q_Bit;16) он равен 16,28, а для комбинации (0;Q_00;16) уже 18,24.
3. Равномерный метод показал себя достаточно приемлемо, особенно интересен тот факт, что он позволил получить больше всех моделей при комбинации (1;Q_Bit;16), что на 55,81% больше базовых настроек, а учитывая, что он показал один из лучших результатов по математическому ожиданию - лучше базовых настроек на 36,88%, думаю, стоит использовать данный метод, при выборе таблиц квантования и внедрения его в иные проекты, связанные с машинным обучением. Что же касается таблиц, полученных методом случайной постановки сплита, то данный подход следует применять с осторожностью, возможно, выборочно там, где не удаётся пройти порог заданного критерия для отбора квантовых таблиц. Стоит отметить, что 10000 вариантов могло оказаться недостаточным для нахождения лучшего разделения предиктора на квантовые отрезки.
4. Как показали результаты эксперимента - метод отбора квантовых таблиц оказывает существенное влияние на результаты. Однако, одного эксперимента недостаточно, что бы с уверенностью рекомендовать применять только один из методов. Разные методы и их настройки позволяют акцентировать внимание модели на разные участки данных в выборке за счет отбора разных квантовых таблиц, что может помочь найти оптимальное решение.
Заключение
В данной статье мы познакомились с алгоритмом отбора квантовых таблиц, провели большой эксперимент по оценке целесообразности отбора квантовых таблиц. Были поверхностно рассмотрены иные методы предобработки данных, без разбора кода, без оценки эффективности этих методов, так как проведение серии экспериментов и описание их результатов потребует значительных трудозатрат, и если данная статья будет интересна читателям, то я, возможно, проведу эксперименты и опишу их в других статья.
В статье я не использовал графики баланса, хотя и есть симпатичные экземпляры моделей, но я бы рекомендовал использовать больше предикторов для отбора и последующего построения моделей для реальной торговли на финансовых рынках.
Для отбора квантовых таблиц использовалась оценка аппроксимации, но стоит пробовать применять и другие оценки, которые могут оценивать однородность и полезность данных.
| № | Приложение | Описание |
|---|---|---|
| 1 | Q_Error_Otbor.mq5 | Скрипт, отвечающий за предобработку данных и отбор квантовых таблиц для каждого предиктора. |
| 2 | CB_Bat_v_02.mq5 | Скрипт, отвечающий за генерацию заданий для обучения моделей с помощью CatBoost - новая версия 2.0 |
| 3 | CSV fast.mqh | Класс для работы с CSV файлами, все авторские права на программный код принадлежат Aliaksandr Hryshyn . Требуется самостоятельно скачать недостающие файлы по ссылке. |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования