
Нейросети — это просто (Часть 58): Трансформер решений (Decision Transformer—DT)

Введение
В рамках данного цикла статей мы уже рассмотрели довольно широкий спектр различных алгоритмов обучения с подкреплением. И все они эксплуатируют базовый подход:
- Агент анализирует текущее состояние окружающей среды.
- Совершает оптимальное действие (в рамках выученной Политики — стратегии поведения).
- Переходит в новое состояние окружающей среды.
- Получает вознаграждение от окружающей среды за совершенный переход в новое состояние.
Данная последовательность основана на принципах марковского процесса. И предполагает, что отправной точкой является текущее состояние окружающей среды. Оптимальный выход из данного состояния один и он не зависит от предшествующего пути.
Я же хочу вас познакомить с альтернативным подходом, который был представлен командой Google в статье "Decision Transformer: Reinforcement Learning via Sequence Modeling" (2.06.2021г.) Основной "изюминкой" данной работы является проецирование задачи обучения с подкреплением в моделирование условной последовательности действий, обусловленную авторегрессионной моделью желаемого вознаграждения.
1. Особенности метода Decision Transformer
Decision Transformer — архитектура, которая меняет взгляд на обучение с подкреплением. В отличии от классического подхода к выбору действия Агента рассматривается задача последовательного принятия решений в рамках языкового моделирования.
Авторы метода предлагают строить траектории действий Агента в контексте совершенных ранее действий и посещенных состояний так же, как языковые модели строят предложения (последовательность слов) в контексте общего текста. Такая постановка задачи позволяет использовать широкий спектр инструментов языковых моделей с минимальными доработками. И, в частности, такую модель, как GPT (Generative Pre-trained Transformer).
Начать, наверное, стоит с принципов построения траекторий Агента. И в данном случае мы говорим именно о построении траекторий, а не последовательности действий.
Одним из требований при выборе представления траектории является возможность использования трансформеров, что позволит извлекать значимые закономерности в исходных данных. Среди которых кроме описания состояний окружающей среды будут совершенные Агентом действия и вознаграждения. И тут авторы метода предлагают довольно интересный подход к моделированию вознаграждений. Хочется, чтобы модель генерировала действия на основе будущих желаемых вознаграждений, а не прошлых наград. Ведь наше желание — достичь какой-то цели. И вместо подачи вознаграждения напрямую авторы предоставляют модели величины "Return-To-Go". Это аналог накопительного вознаграждения до конца эпизода. Только мы указываем модели не фактический, а желаемый результат.
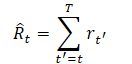
Это приводит к ниже следующему представлению траектории, которое подходит для авторегрессионного обучения и генерации:
![]()
При тестировании обученных моделей мы можем указать желаемое вознаграждение (например, 1 для успеха или 0 для неудачи), а также начальное состояние среды, как информацию для инициирования генерации. После выполнения сгенерированного действия для текущего состояния мы уменьшаем целевое вознаграждение на размер полученного от окружающей среды и повторяем процесс до получения желаемого суммарного вознаграждения или завершения эпизода.
Обратите внимание, что при подобном подходе и продолжении действий после достижения желаемого уровня суммарного вознаграждения в Return-To-Go может передаваться отрицательное значение. А это может привести к нежелательным результатам в виде убытков.
Для принятия решения Агентом в качестве исходных данных мы передаем последние K временных шагов в Decision Transformer. Всего 3*K токенов. По одному для каждой модальности: return-to-go, состояние и действие, которое привело в это состояние. Для получения векторных представлений токенов авторы метода используют обучаемый полносвязный нейронный слой для каждой модальности, который проецирует исходные данные в размерность векторных представлений. После чего осуществляется нормализация слоя. В случае анализа сложных (составных) состояний окружающей среды допускается использование сверточного энкодера вместо полносвязного нейронного слоя.
Дополнительно, для каждого временного шага обучается векторное представление временной метки, которое добавляется к каждому токену. Надо сказать, что такой подход отличается от стандартного позиционного векторного представления в трансформерах, поскольку один временной шаг соответствует нескольким токенам (в приведенном примере трем). Затем токены обрабатываются с помощью модели GPT, которая прогнозирует будущие токены действий с помощью авторегрессионного моделирования. Подробнее об архитектуре GPT-моделей мы рассказывали при рассмотрении методов обучения с учителем в статье "Вариации на тему GPT".
Как это не покажется странным, но процесс обучения модели строится с использованием методов обучения с учителем. Сначала мы организовываем процесс взаимодействия с окружающей средой и сэмплируем набор случайных траекторий. Мы с вами это осуществляли уже не один раз. И далее осуществляется оффлайн обучение. Мы выбираем мини-пакеты длиной K из собранного набора траекторий. Предсказательная голова, соответствующая входному токену st, обучается прогнозировать действие at — либо с использованием функции потерь кросс-энтропии для дискретных действий, либо с использованием среднеквадратичной ошибки для непрерывных действий. Потери для каждого временного шага усредняются.
При этом в процессе экспериментов авторы метода не обнаружили, чтобы прогнозирование последующих состояний или вознаграждений улучшало эффективность работы моделей.
Ниже представлена авторская визуализация метода.

Я не буду сейчас подробно останавливаться на архитектуре трансформеров и механизме Self-Attention в частности, так как этому уже было посвящено несколько статей данной серии. Предлагаю сразу перейти к практической части и посмотреть на реализацию механизма Decision Transformer средствами MQL5.
2. Реализация средствами MQL5
После небольшого погружения в теоретические аспекты метода Decision Transformer мы переходим к его реализации средствами MQL5. И первое, с чем мы сталкиваемся — это вопрос реализации эмбедингов сущностей исходных данных. При решении подобных задач в методах обучения с учителем мы использовали сверточные слои с шагом равным окну исходных данных. Но в данном случае здесь нас ожидает 2 сложности:
- Размер вектора описания состояния окружающей среды отличен от вектора пространства действий. А вектор вознаграждений имеет третий размер.
- Все сущности содержат исходные данные из разных распределений. И для приведения их в сопоставимый вид в едином пространстве потребуются различные матрицы эмбединга.
Тут же мы вспоминаем, что состояние окружающей среды мы разделили на 2 совершенно разных по содержанию и размеру блока: исторические данные ценового движения и описание текущего состояния счета. Что добавляет ещё одну модальность для анализа. А в процессе новых экспериментов могут появиться и дополнительные данные для анализа. Очевидно, что в подобных условиях мы не можем использовать сверточный слой и нам необходимо иное универсальное решение, способное осуществить эмбединг N модальностей с размерами векторов [n1, n2, n3,...,nN]. Как сказано выше, авторы метода использовали обучаемые полносвязные слои для каждой модальности. Такой подход довольно универсален, но в нашем случае влечет за собой отказ от параллельного эмбединга нескольких модальностей.
В данном случае наиболее оптимальным решением, на мой взгляд, является создание нового объекта в виде нейронного слоя эмбединга CNeuronEmbeddingOCL. Только такой подход позволит нам правильно выстроить процесс. Но перед созданием объектов и функционала нового класса нам ещё предстоит определиться с некоторыми его архитектурными особенностями.
На каждой итерации прямого прохода мы планируем передавать пять векторов исходных данных:
- Исторические данные ценового движения.
- Состояние счета.
- Вознаграждение.
- Действие, совершенное на предыдущем шаге.
- Временная метка.
Как можно заметить, информация различных модальностей сильно отличается по содержанию и объему данных. И нам предстоит определить технологию передачи исходных данных в слой эмбединга. Использование матрицы с выделением отдельной строки или столбца для каждой модальности не представляется возможным из-за разного размера векторов данных. Можно, конечно, использовать динамический массив векторов. Но такой вариант возможен только в рамках реализации средствами MQL5. Однако, мы будем испытывать сложности с передачей такого массива в контекст OpenCL для организации параллельных вычислений. Создание отдельных кернелов для различного количества модальностей исходных данных усложнит программу и не позволит сделать алгоритм полностью универсальным. А использование одного кернела для каждой отдельной модальности ведет к последовательному их эмбедингу и ограничивает возможности параллельных вычислений.
В подобной ситуации наиболее универсальным, на мой взгляд, будет использование 2 векторов (буферов). В одном мы последовательно указываем все исходные данные. А во втором предоставляется «карта данных», в виде размеров окон каждой последовательности. Таким образом, используя только 2 буфера, мы можем в кернел передать любое количество модальностей с независимым размером данных без изменения алгоритма действий внутри кернела. Вполне универсальное решение с возможностью параллельных вычислений эмбединга всех модальностей одновременно.
Помимо простоты и универсальности, такой подход нам позволяет легко совместить новый класс со всеми созданными ранее нейронными слоями.
С передачей исходных данных вопрос решили. Но у нас практически аналогичная ситуация с матрицами весов. Выше уже было сказано, что каждая модальность нуждается в собственной матрице эмбединга. Однако, в данном случае у нас есть одно преимущество — размеры эмбединга всех модальностей равны. Ведь цель процесса эмбединга привести различные модальности к сопоставимому виду. Следовательно, каждый элемент исходных данных имеет одинаковое количество весовых коэффициентов для передачи данных на выход нейронного слоя. Это позволяет нам использовать одну общую матрицу для хранения весовых коэффициентов эмбедингов всех модальностей. Количество столбцов матрицы равно размеру эмбединга одной модальности. А количество строк будет равно общему количеству исходных данных. Тут же мы можем добавить элементы байесовского смещения, что добавит нам по одной строке в матрице весовых коэффициентов для каждой модальности.
Следующий конструктивный момент, который мне хотелось бы обсудить, целесообразность эмбединга всей предшествующей последовательности. Сразу скажем, что мы не ставим под вопрос необходимость анализа Агентом предшествующей траектории. Ведь это основа рассматриваемого метода. Но давайте посмотрим на вопрос шире. Decision Transformer в своей сущности является авторегрессионной моделью, которая на вход получает K*N токенов. И на каждом временном шаге новыми являются только N токенов. Остальные (K-1)*N токенов полностью повторяют токены, используемые на предшествующем временном шаге. Конечно, на начальной стадии обучения даже повторяющиеся исходные данные будут иметь различные эмбединги из-за вносимых изменений в матрицы эмбединга. Но подобное влияние будет снижаться по мере обучения модели. А в процессе промышленной эксплуатации, когда матрицы весов не изменяются, подобные отклонения полностью отсутствуют. И вполне логично на каждом временном шаге осуществлять эмбединг только новых исходных данных. Это позволит нам значительно снизить затраты ресурсов на эмбединг данных в процессе обучения и промышленной эксплуатации модели.
Кроме того, обратим внимание еще на один момент — позиционное кодирование. В рамках нашей задачи на позицию исторических данных указывает время открытия бара. В своей модели исходных данных мы предусмотрели кодирование временной метки. Но авторы метода прибавляли токен позиции к эмбедингу других модальностей. Такое решение полностью соответствует архитектуре трансформера, но добавляет дополнительную операцию в последовательности действий. Мы же создадим эмбединг временной метки и добавим его отдельной модальностью, т.к. эмбединг позиции можно осуществить параллельно с эмбедингом остальных модальностей. Однако, такой подход увеличивает объем анализируемых данных. И в каждом отдельном случае нужно учитывать баланс различных факторов работы программы при выборе метода позиционного кодирования.
После определения основных конструктивных особенностей нашей реализации мы можем перейти к построению OpenCL программы. И начнем мы, как всегда, с построения кернела прямого прохода. Как вы понимаете, на выходе мы планируем получить матрицу эмбедингов. Каждая строка данной матрицы будет представлять эмбединг отдельной модальности. Аналогично мы сформируем и 2 мерное пространства задач кернела. В одном измерении укажем размер эмбединга одной модальности. А во втором — количество анализируемых модальностей.
Напомню, что мы решили осуществлять эмбединг только последних модальностей в последовательности. Эмбединг предшествующих данных мы переносим без изменений из ранее полученных результатов. При этом на выходе нашего слоя CNeuronEmbeddingOCL мы получаем эмбединг всей последовательности.
И так, в параметрах кернела мы передаем указатели на 5 буферов данных и 1 константу, в которой укажем размер последовательности. В данном случае под размером последовательности мы подразумеваем количество анализируемых шагов исторических данных.
В буферах данных мы будем передавать ниже следующую информацию:
- inputs — содержит исходные данные в виде последовательности всех модальностей (1 временной шаг);
- outputs — содержит последовательность эмбедингов всех модальностей на глубину анализируемой истории;
- weights — матрица весовых коэффициентов;
- windows — карта исходных данных (размеры окон данных каждой модальности в исходных данных);
- std — вектор среднеквадратических отклонений (используется для нормализации эмбедингов).
__kernel void Embedding(__global float *inputs, __global float *outputs, __global float *weights, __global int *windows, __global float *std, const int stack_size ) { const int window_out = get_global_size(0); const int pos = get_local_id(0); const int emb = get_global_id(1); const int emb_total = get_global_size(1); const int shift_out = emb * window_out + pos; const int step = emb_total * window_out; const uint ls = min((uint)get_local_size(0), (uint)LOCAL_ARRAY_SIZE);
В теле кернела мы идентифицируем поток в обоих измерениях и определяем константы смещений в буферах данных. После чего осуществляем смещение ранее полученных эмбедингов в буфере результатов. Обратите внимание, что в каждом потоке осуществляется перенос только отдельной позиции эмбединга. Это позволяет организовать копирование данных в параллельных потоках.
for(int i=stack_size-1;i>0;i--) outputs[i*step+shift_out]=outputs[(i-1)*step+shift_out];
Следующим шагом мы определим смещение в буфере исходных данных до анализируемой модальности. Для этого посчитаем суммарное количество элементов в модальностях, расположенных в буфере исходных данных до анализируемой.
int shift_in = 0; for(int i = 0; i < emb; i++) shift_in += windows[i];
Тут же мы определяем смещение в буфере матрицы весов с учетом байесовского элемента.
const int shift_weights = (shift_in + emb) * window_out;
Сохраним в локальную переменную размер окна исходных данных текущей модальности и определим константы работы с локальным массивом.
const int window_in = windows[emb]; const int local_pos = (pos >= ls ? pos % (ls - 1) : pos); const int local_orders = (window_out + ls - 1) / ls; const int local_order = pos / ls;
Создадим локальный массив и заполним его нулевыми значениями. Здесь мы установим барьер для локальной синхронизации потоков.
__local float temp[LOCAL_ARRAY_SIZE]; if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE);
На этом можно считать завершенной подготовительную работу, и мы приступаем непосредственно к операциям эмбэдинга. Вначале мы умножим вектор исходных данных анализируемой модальности на соответствующий вектор весовых коэффициентов. Таким образом мы получаем нужный нам элемент эмбединга.
float value = weights[shift_weights + window_in]; for(int i = 0; i < window_in; i++) value += inputs[shift_in + i] * weights[shift_weights + i];
В данном случае мы не используем функцию активации, так как нам необходимо получить проекцию каждого элемента последовательности в нужном подпространстве. Однако, мы отдаем себе отчет, что подобный подход не гарантирует сопоставимость эмбедингов различных исходных данных. Поэтому следующим этапом мы осуществим нормализацию данных в рамках эмбединга отдельно взятой модальности. Тем самым приводим данные всех эмбедингов к нулевой средней и единичной дисперсии. Напомню формулу нормализации.

Для этого мы сначала через локальный массив соберем сумму всех элементов анализируемого эмбединга. И разделим полученную сумму на размер вектора эмбединга. Тем самым мы определим среднее значение. И тут же мы скорректируем значение текущего элемента эмбединга на среднее значение. Для синхронизации локальных потоков мы используем барьеры.
for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += value; barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- value -= temp[0] / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE);
Здесь стоит сказать пару слов о производной выполненных операций. Как Вы знаете, для распространения градиента ошибки при обратном проходе мы используем производные функции прямого прохода. При суммировании или вычитании константы из переменной, градиент ошибки в полном объеме мы передаем переменной. Однако, нюанс данной ситуации состоит в том, что мы вычитаем среднее значение. Которое, в свою очередь, является функцией от анализируемых переменных и имеет свою производную. И для точного распределения градиента ошибки нам необходимо провести его и через производную функции среднего значение. Данное утверждение верно и для среднеквадратического отклонения, которую мы будем использовать далее. Но мой личный опыт показывает, что суммарный градиент ошибки, пропущенный через производную функции среднего значения и дисперсии, в разы меньше градиента ошибки на самой переменной. И с целью экономии ресурсов мы не будем сейчас усложнять алгоритм на сохранение промежуточных данных и последующего вычисления градиентов ошибки в этом направлении.
Но вернемся к алгоритму нашего кернела. На данном этапе мы уже привели вектор эмбединга к нулевой средней. И далее мы приведем его к единичной дисперсии. Для этого мы разделим все элементы анализируемого эмбеденига на его среднеквадратическое отклонение, которое мы вычисляем с использованием локального массива.
Напомню, что локальный массив используется для передачи данных между потоками локальной группы. А синхронизация потоков осуществляется посредством барьеров.
if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += pow(value,2.0f) / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(temp[0] > 0) value /= sqrt(temp[0]);
Теперь нам остается сохранить полученное значение в соответствующий элемент буфера результатов. А также не забудем сохранить вычисленное среднеквадратическое отклонение для последующего распределения градиента ошибки при обратном проходе.
outputs[shift_out] = value; if(pos == 0) std[emb] = sqrt(temp[0]); }
После завершения работы над кернелом прямого прохода предлагаю перейти к разбору алгоритма кернела распределения градиента ошибки. Выше мы уже начали обсуждение распределения градиента ошибки через функцию нормализации данных. И для оптимизации использования ресурсов было принято решения об упрощении алгоритма в части градиента ошибки через функции среднего значения и дисперсии вектора эмбединга. На данном этапе мы рассматриваем среднее значение и дисперсию как константы. Именно в такой парадигме и построен алгоритм кернела распределения градиента ошибки EmbeddingHiddenGradient.
В параметрах кернела мы передаем 5 буферов данных и 1 константу. С константу и 3 из используемых буферов мы уже познакомились в предыдущем кернеле. А буферы исходных данных и результатов заменяются на буферы соответствующих градиентов ошибки.
__kernel void EmbeddingHiddenGradient(__global float *inputs_gradient, __global float *outputs_gradient, __global float *weights, __global int *windows, __global float *std, const int window_out ) { const int pos = get_global_id(0);
Кернел мы будем вызывать в одномерном пространстве задач по количеству элементов исходных данных. В теле кернела мы сразу идентифицируем текущий поток. Однако, позиция элемента в буфере исходных данных не дает нам явного представления о зависимых элементах в буфере результатов. Поэтому мы сначала перебираем буфер карты исходных данных для определения анализируемой модальности.
int emb = -1; int count = 0; do { emb++; count += windows[emb]; } while(count <= pos);
А затем, на основании индекса анализируемой модальности мы определяем смещение в буферах результатов и весовых коэффициентов.
const int shift_out = emb * window_out; const int shift_weights = (pos + emb) * window_out;
После определения смещений в буферах данных мы собираем градиенты ошибки со всех зависимых элементов буфера результатов и корректируем их на среднеквадратическое отклонение вектора эмбединга до нормализации. Напомню, что его значение мы сохранили в буфере std при прямом проходе.
float value = 0; for(int i = 0; i < window_out; i++) value += outputs_gradient[shift_out + i] * weights[shift_weights + i]; float s = std[emb]; if(s > 0) value /= s; //--- inputs_gradient[pos] = value; }
Полученное значение сохраняем в буфере градиентов предшествующего слоя.
Для завершения работы с OpenCL программой нам остается рассмотреть алгоритм кернелов обновления матрицы весов. В рамках данной статьи мы рассмотрим лишь кернел метода Adam, который я использую наиболее часто. Основное отличие данного кернела от аналогичных рассмотренных ранее лежит в части определения смещений в буферах данных. Это вполне ожидаемо. ведь мы не вносим кардинальных изменений в алгоритм самого метода обновления весовых коэффициентов.
__kernel void EmbeddingUpdateWeightsAdam(__global float *weights, __global const float *gradient, __global const float *inputs, __global float *matrix_m, __global float *matrix_v, __global int *windows, __global float *std, const int window_out, const float l, const float b1, const float b2 ) { const int i = get_global_id(0);
В параметрах кернела передается довольно большое количество буферов и констант. Но все они уже знакомы нам. Кернел будет вызываться в одномерном пространстве задач по числу элементов в буфере весовых коэффициентов.
В теле кернела мы, как обычно, идентифицируем анализируемый элемент буфера по идентификатору потока. После чего мы определяем смещения в буферах данных до необходимых нам элементов.
int emb = -1; int count = 0; int shift = 0; do { emb++; shift = count; count += (windows[emb] + 1) * window_out; } while(count <= i); const int shift_out = emb * window_out; int shift_in = shift / window_out - emb; shift = (i - shift) / window_out;
А далее мы организовываем корректировку весового коэффициента. Процесс полностью повторяет рассмотренный в предыдущих статьях данной серии. Результат и необходимы данные мы сохраняем в соответствующие буферы.
float weight = weights[i]; float g = gradient[shift_out] * inp / std[emb]; float mt = b1 * matrix_m[i] + (1 - b1) * g; float vt = b2 * matrix_v[i] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(delta * g > 0) weights[i] = clamp(weights[i] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = mt; matrix_v[i] = vt; }
После завершения работы над кернелами программы OpenCL мы возвращаемся к работе на стороне основной программы. И теперь, когда у нас уже есть ясность функционала класса и полный список необходимых буферов данных, мы можем создать все условия для вызова и обслуживания выше рассмотренных кернелов.
Как уже было сказано выше, мы создаем новый класс CNeuronEmbeddingOCL на основе базового класса нейронных слоёв CNeuronBaseOCL. Основной функционал работы нейронного слоя наследуется от родительского класса. Нам же предстоит добавить в класс новый функционал.
Для хранения карты исходных данных мы создаем динамический массив a_Windows. При этом мы не будем создавать отдельный объект буфера для его обслуживания. Создадим лишь переменную для записи указателя на буфер в контексте OpenCL i_WindowsBuffer. Тут же мы создадим переменные для записи размера одного эмбединга и глубины анализируемой истории — i_WindowOut и i_StackSize, соответственно.
Для матрицы весовых коэффициентов эмбединга и моментов создадим буферы данных:
- WeightsEmbedding;
- FirstMomentumEmbed;
- SecondMomentumEmbed.
А вот буфер среднеквадратических отклонений используется только для промежуточных расчетов. Поэтому мы не будем его создавать на стороне основной программы. Создадим его только в памяти контекста OpenCL и сохраним на него указатель в переменной i_STDBuffer.
Набор переопределяемых методов довольно стандартный и мы не будем сейчас останавливаться на их назначении.
class CNeuronEmbeddingOCL : public CNeuronBaseOCL { protected: int a_Windows[]; int i_WindowOut; int i_StackSize; int i_WindowsBuffer; int i_STDBuffer; //--- CBufferFloat WeightsEmbedding; CBufferFloat FirstMomentumEmbed; CBufferFloat SecondMomentumEmbed; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronEmbeddingOCL(void); ~CNeuronEmbeddingOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint window_out, int &windows[]); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronEmbeddingOCL; } virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual bool Clear(void); };
В конструкторе класса мы инициализируем переменные и указатели на буферы начальными значениями.
CNeuronEmbeddingOCL::CNeuronEmbeddingOCL(void) { ArrayFree(a_Windows); if(!!OpenCL) { if(i_WindowsBuffer >= 0) OpenCL.BufferFree(i_WindowsBuffer); if(i_STDBuffer >= 0) OpenCL.BufferFree(i_STDBuffer); } //-- i_WindowsBuffer = INVALID_HANDLE; i_STDBuffer = INVALID_HANDLE; i_WindowOut = 0; i_StackSize = 1; }
Непосредственно инициализация объекта слоя эмбединга осуществляется в методе Init. В параметрах метода помимо уже привычных констант мы передаем глубину анализируемой истории (stack_size), размер вектора эмбединга (window_out) и «карту исходных данных» (динамический массив windows[]).
bool CNeuronEmbeddingOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint stack_size, uint window_out,int &windows[]) { if(CheckPointer(open_cl) == POINTER_INVALID || window_out <= 0 || windows.Size() <= 0 || stack_size <= 0) return false; if(!!OpenCL && OpenCL != open_cl) delete OpenCL; uint numNeurons = window_out * windows.Size() * stack_size; if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,numNeurons,ADAM,1)) return false;
В теле метода мы организовываем блок контроля исходных данных. А затем пересчитываем размер буфера результатов как произведения длины вектора одного эмбединга на количество модальностей и глубину анализируемой истории. Обратите внимание, что во внешних параметрах нет общего количества модальностей. Но мы получаем «карту исходных данных». Размер полученного массива и укажет нам на количество анализируемых модальностей.
Непосредственно инициализация буфера результатов, как и других унаследованных объектов, осуществляется в аналогичном методе родительского класса, который мы и вызываем после завершения подготовительных операций.
После успешной инициализации унаследованных объектов нам предстоит подготовить добавленные сущности. Вначале мы инициализируем буфер весовых коэффициентов эмбединга. Как было описано выше, данный буфер представляет собой матрицу с числом строк равным объему исходных данных и столбцов по размеру вектора одного эмбединга. Размер эмбединга нам известен. А вот для определения размера исходных данных нам необходимо суммировать все значения «карты данных». И к полученной сумме добавим по одной строке байесовского смещения для каждой модальности. Таким образом мы получаем размер буфера весовых коэффициентов эмбединга. Теперь мы заполним его случайными значениями и перенесем в память контекста OpenCL.
uint weights = 0; ArrayCopy(a_Windows,windows); i_WindowOut = (int)window_out; i_StackSize = (int)stack_size; for(uint i = 0; i < windows.Size(); i++) weights += (windows[i] + 1) * window_out; if(!WeightsEmbedding.Reserve(weights)) return false; float k = 1.0f / sqrt((float)weights / (float)window_out); for(uint i = 0; i < weights; i++) if(!WeightsEmbedding.Add(k * (2 * GenerateWeight() - 1.0f)*WeightsMultiplier)) return false; if(!WeightsEmbedding.BufferCreate(OpenCL)) return false;
Буферы первого и второго момента имеют аналогичный размер. Но их мы инициализируем нулевыми значениями и переносим в память контекста OpenCL.
if(!FirstMomentumEmbed.BufferInit(weights, 0)) return false; if(!FirstMomentumEmbed.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumEmbed.BufferInit(weights, 0)) return false; if(!SecondMomentumEmbed.BufferCreate(OpenCL)) return false;
Далее мы создаем буферы карты исходных данных и среднеквадратических отклонений.
i_WindowsBuffer = OpenCL.AddBuffer(sizeof(int) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_WindowsBuffer < 0 || !OpenCL.BufferWrite(i_WindowsBuffer,a_Windows,0,0,a_Windows.Size())) return false; i_STDBuffer = OpenCL.AddBuffer(sizeof(float) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_STDBuffer<0) return false; //--- return true; }
Обязательно контролируем процесс выполнения операций на каждом шаге и после завершения всех операций метода возвращаем вызывающей программе логический результат работы метода.
После инициализации объекта нам предстоит создать методы его основного функционала. В нашем случае это методы прямого и обратного проходов. Как вы уже догадались, основную работу по организации функционала мы уже выполнили в OpenCL программе. И сейчас нам остается организовать вызов соответствующих кернелов. Но, прежде чем приступить к данной работе, нам необходимо объявить константы для работы с кернелами: идентификаторы кернелов в программе и их параметров. Как всегда, данный функционал мы выполняем с использованием директивы #define.
#define def_k_Embedding 59 #define def_k_emb_inputs 0 #define def_k_emb_outputs 1 #define def_k_emb_weights 2 #define def_k_emb_windows 3 #define def_k_emb_std 4 #define def_k_emb_stack_size 5 //--- #define def_k_EmbeddingHiddenGradient 60 #define def_k_ehg_inputs_gradient 0 #define def_k_ehg_outputs_gradient 1 #define def_k_ehg_weights 2 #define def_k_ehg_windows 3 #define def_k_ehg_std 4 #define def_k_ehg_window_out 5 //--- #define def_k_EmbeddingUpdateWeightsAdam 61 #define def_k_euw_weights 0 #define def_k_euw_gradient 1 #define def_k_euw_inputs 2 #define def_k_euw_matrix_m 3 #define def_k_euw_matrix_v 4 #define def_k_euw_windows 5 #define def_k_euw_std 6 #define def_k_euw_window_out 7 #define def_k_euw_learning_rate 8 #define def_k_euw_b1 9 #define def_k_euw_b2 10
Организацию процесса постановки кернела в очередь выполнения мы рассмотрим на примере метода прямого прохода feedForward. В параметрах метода, как и во всех аналогичных ранее рассмотренных, мы получаем указатель на объект предыдущего нейронного слоя.
bool CNeuronEmbeddingOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false;
В теле метода мы проверяем полученный указатель и указатель на объект работы с контекстом OpenCL.
Далее мы передаем кернелу указатели на буферы данных и необходимые константы, которые ранее были указаны в параметрах кернела. Не забываем на каждом шаге проконтролировать процесс выполнения операций.
if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_std, i_STDBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_weights, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_windows, i_WindowsBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Embedding, def_k_emb_stack_size, i_StackSize)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; }
После успешной передачи всех параметров нам необходимо определить пространство задач для кернела. Как мы обсуждали выше, кернел будет запускаться в 2 мерном пространстве задач. В первом измерении мы укажем размер одного эмбединга. А во втором количество модальностей для анализа.
uint global_work_offset[2] = {0,0}; uint global_work_size[2] = {i_WindowOut,a_Windows.Size()};
Особенностью кернела эмбединга является нормализация данных в рамках вектора эмбединга одной модальности. Для построения этого подпроцесса мы организовали обмена данными между потоками в рамках одной рабочей группы через локальный массив. И теперь нам необходимо указать размер локальной группы, который равен размеру вектора эмбединга. Нюанс состоит в том, что при указании 2 мерного пространства нам необходимо указать 2 мерную локальную группу. Следовательно 2 измерение локальной группы равно 1.
uint local_work_size[2] = {i_WindowOut,1};
В завершении вызываем метод постановки кернела в очередь и контролируем процесс выполнения операций.
if(!OpenCL.Execute(def_k_Embedding, 2, global_work_offset, global_work_size,local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__,GetLastError()); return false; } //--- return true; }
Процедура вызова кернелов обратного прохода аналогична, и мы не будем сейчас останавливаться на рассмотрении этих методов. С их кодом, равно как и с кодом всех классов и их методов, используемых в статье, вы можете ознакомиться во вложении. А я хотел бы акцентировать внимание на одном моменте. Decision Transformer является авторегрессионной моделью и последовательность исходных данных имеет большое значение. Выше мы определились, что на каждом временном шаге на вход модели подаем только новые данные. Вся глубина анализируемой истории копируется из предыдущих операций модели. По существу, мы используем буфер результатов слоя CNeuronEmbeddingOCL в качестве стека эмбедингов. Такой подход позволяет снизить затраты на первичную обработку данных. Но вводит требование к последовательной подаче исходных данных как в процессе обучения, так и в процессе эксплуатации. В то же время, в процессе обучения мы часто используем случайные выборки исходных данных. Необходимость этого уже не раз обсуждалась ранее. И чтобы исключить искажение данных в следствии «временного скачка» исходных данных или при переходе на альтернативную траекторию нам необходим метод очисти стека эмбедингов. Для этих целей был создан метод Clear. Алгоритм его довольно прост: мы лишь заполняем весь буфер нулевыми значениями и копируем данные в память контекста OpenCL.
bool CNeuronEmbeddingOCL::Clear(void) { if(!Output.BufferInit(Output.Total(),0)) return false; if(!OpenCL) return true; //--- return Output.BufferWrite(); }
На этом предлагаю завершить обсуждение алгоритмов методов класса CNeuronEmbeddingOCL. А с полным его кодом и всех методов вы можете ознакомиться во вложении.
В результате проделанной работы мы имеем сопоставимые эмбединги нескольких различных модальностей на выходе слоя CNeuronEmbeddingOCL. И это позволяет нам использовать ранее созданные объекты трансформера для реализации представленного метода Decision Transformer. А значит мы можем перейти к работе над описанием архитектуры модели. Да, в данном случае мы будем использовать только одну модель — Агента. Давненько такого не было в нашей серии статей.
Но прежде я должен напомнить вам о «карте исходных данных». Для её описания мы использовали массив, которого ранее не было в классе описания нейронного слоя. Добавим его.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) float probability; ///< Probability of neurons shutdown, only Dropout used int windows[]; //--- virtual bool Copy(CLayerDescription *source); //--- virtual bool operator= (CLayerDescription *source) { return Copy(source); } };
Архитектуру модели мы описываем в методе CreateDescriptions. В параметрах метод получает указатель лишь на один динамический массив описания архитектуры Актера. В полученный массив мы и будем сохранять описание нейронных слоев модели.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear();
Первым слоем мы укажем полносвязный нейронный слой исходных данных, в который последовательно запишем все необходимые для анализа данные. Обратите внимание, что мы не разбиваем исходные данные на отдельные буферы по содержанию. В данном случае их разделение довольно условно. Мы лишь записываем их последовательно. А логическое их разделение будет осуществляться на уровне эмбедингов по «карте исходных данных», которую мы создадим позже.
Обратите внимание, что слой исходных данных содержит информацию только о последнем состоянии системы (вознаграждение, состояние окружающей среды, состояние счета, временная метка и последнее действие Агента).
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
За слоем исходных данных мы по обычаю укажем слой пакетной нормализации, в котором осуществляется предварительная обработка данных. Мы, опять же, не задумываемся о разной природе полученных данных. Ведь данный слой осуществляет нормализацию в разрезе исторических данных по каждому признаку независимо.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Далее следует слой пакетной нормализации. Здесь мы указываем глубину анализируемой истории, размер вектора одного эмбединга и «карту исходных данных».
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NRewards,NActions}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
За слоем эмбединга мы поставим блок разреженного внимания defNeuronMLMHSparseAttentionOCL, который и составит основу нашего трансформера. Должен честно сказать, что авторами метода использовался оригинальный трансформер. Однако, использование блока разреженного внимания позволит нам значительно увеличить глубину анализируемой истории при незначительном увеличении расходов ресурсов и времени работы модели.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
И завершается модель блоком принятия решения из полносвязных слоев и латентным слоем вариационного автоэнкодера на выходе для создания стохастичности политики Актера.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Надо сказать, что блок принятия решения также отличается от используемого в авторском алгоритме DT. Авторы метода использовали декодер последнего токена в последовательности на выходе трансформера. Мы же анализируем всю последовательность для принятия взвешенного решения.
После указания архитектуры модели мы переходим к созданию советника взаимодействия с окружающей средой и сбора данных для обучения модели в буфер воспроизведения опыта «\DT\Research.mq5». Структура построения советника полностью повторяет рассмотренные нами ранее, но стоит остановиться на методе обработки тиков OnTick. Именно здесь формируется последовательность исходных данных в соответствии с описанной выше картой.
В теле метода мы, как и ранее, проверяем наступление события открытия нового бара и, при необходимости, загружаем исторические данные. Только сейчас мы загружаем не всю глубину анализируемой истории, а только обновления в размере паттерна одного временного шага. Это могут быть данные одной последней закрытой свечи. А может быть и более. для регулирования глубины загрузки данных мы ввели константу NBarInPattern. Не путайте, пожалуйста, с константой HistoryBars, которой мы будем определять глубину стека эмбедингов.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Затем мы создаем из исторических данных массив для сохранения в траектории и переносим его в буфер исходных данных. Процедура полностью идентична рассмотренным ранее советникам.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Следующим шагом мы формируем описание состояния счета. Сбор данных осуществляется по отработанной ранее процедуре. Только данные переносятся не в отдельный буфер, а в единый буфер исходных данных bState.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
В этот же буфер мы добавляем временную метку.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Следующие данные уже порождаются требованиями метода Decision Transformer. Здесь мы добавляем в буфер исходных данных модальность Return-To-Go. Здесь может быть один элемент желаемого вознаграждения, а может быть и вектор декомпозированного вознаграждения. Мы укажем 3 элемента: изменение баланса, изменение эквити и просадка. Все 3 показателя указываем в относительных величинах.
//--- Return to go bState.Add(float(1-(sState.account[0] - PrevBalance) / PrevBalance)); bState.Add(float(0.1f-(sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(0);
И в завершение вектора исходных данных мы добавляем вектор последних действий Агента. При первом вызове данный вектор заполнен нулевыми значениями.
//--- Prev action
bState.AddArray(AgentResult);
Вектор исходных данных готов, и мы осуществляем прямой проход Агента.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Дальнейший алгоритм трактования результатов модели и совершения сделок перенесен без изменений, и мы не будем на нем останавливаться. А с полным кодом советника и всех его методов вы можете самостоятельно ознакомиться во вложении. А мы переходим к построению процесса обучения модели в советнике «\DT\Study.mq5». Советник так же много унаследовал от предшествующих работ. И сейчас мы подробно остановимся только на методе обучения моделей Train.
В теле метода мы сначала определяем количество траекторий, сохраненных в локальном буфере воспроизведения опыта.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
И далее мы организовываем цикл по числу итераций обучения, в котором случайным образом мы выбираем одну траекторию и отдельное состояние на этой траектории. Здесь все, как и ранее.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
Отличия начинаются далее. Помните, что мы говорили о необходимости подачи последовательных данных на вход модели. Но мы случайное состояние на траектории. С целью исключения искажения данных в анализируемой последовательности мы очищаем буфер эмбединга и вектор последних действий Агента.
Actions = vector<float>::Zeros(NActions); Agent.Clear();
И далее мы организовываем вложенный цикл, число итераций которого в 3 раза превышает глубину анализируемой истории. Конечно, если это позволяет размер сохраненной траектории. В теле этого вложенного цикла мы и будем осуществлять обучение модели, подавая ей на вход данные из сохраненной траектории в строгой последовательности взаимодействия со средой. Сначала мы загрузим в буфер исторические данные ценового движения индикаторов.
for(int state = i; state < MathMin(Buffer[tr].Total - 1,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Далее следует информация о состоянии счета.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
И временная метка.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
А вот в Return-To-Go на данном этапе мы передаем фактическое накопительное вознаграждение до конца траектории. Немного отличается подход от аналогичного токена в советнике взаимодействия с окружающей средой. Но именно это позволяет нам обучать модель.
//--- Return to go
State.AddArray(Buffer[tr].States[state].rewards);
И добавим действие Агента на предыдущем временном шаге из буфера воспроизведения опыта.
//--- Prev action
State.AddArray(Actions);
Буфер исходных данных для одной итерации обучения готов, и мы вызываем метод прямого прохода Агента.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После успешного выполнения прямого прохода нам предстоит провести обратный проход и скорректировать параметры модели. И тут возникает вопрос целевых значений, который решается довольно просто. В качестве целевых значений мы используем фактически совершенные Агентом действия при взаимодействии с окружающей средой. Как ни парадоксально, это обучение с учителем «чистой воды». Но где же обучение с подкреплением? Где оптимизации вознаграждения? Мы даже не можем использовать обучение с учителем, т.к. действия, совершенные при взаимодействии с окружающей средой не оптимальные.
Мы обучаем авторегрессионную модель, которая на основании знания пройденной траектории и желаемого результата генерирует оптимальное действие. В этом аспекте основную роль играет указание фактического накопленного вознаграждения в токене return-to-go. Ведь ни у кого не вызывает сомнений, что именно фактически совершенные действия привели к фактически полученным вознаграждениям. Следовательно, мы вполне можем обучить модель отождествлять эти действия с полученным вознаграждением. А хорошо обученная модель в последствии сможет генерировать действия для получения желаемого результата в процессе эксплуатации.
Авторы Decision Transformer предлагают использовать MSE для непрерывного пространства действий. Мы же дополним его методом CAGrad.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После успешного обратного прохода мы информируем пользователя о состоянии процесса обучения и переходим на следующую итерации нашей системы циклов процесса обучения. А по завершении всех итераций мы инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом всех программ, используемых в статье, вы можете ознакомиться во вложении.
3. Тестирование
Выше была проведена довольно большая работа по имплементации метода Decision Transformer средствами MQL5. В данной части нашей статьи мы проведем обучение и тестирование модели. Как всегда, обучение и тестирование моделей осуществляется на исторических данных EURUSD таймфрейм H1. Параметры всех индикаторов используются по умолчанию. Период обучения составляет 7 месяцев 2023 года. Тестирование работы модели будем осуществлять на исторических данных за август 2023 года.
По результатам тестирования данного метода можно сказать, что идея довольно интересная. Но в условиях стохастичности рынка мне удалось достичь желаемого результата. Если на обучающей выборке еще удается достичь приемлемых результатов. То на новых данных мы видим рост баланса в первой декаде периода тестирования. Но затем идет череда убыточных сделок. В результате модель принесла убытки на тестовых данных. Хотя мы и наблюдаем превышение средней прибыльной сделки над средним убытком немного более 1.0%, этого недостаточно. Ведь доля прибыльных сделок составляет всего 47.76%. В сухом остатке профит-фактор на уровне 0.92.


Заключение
В данной статье мы познакомились с довольно интересным методом Decision Transformer, который представляет собой новый и инновационный подход к обучению с подкреплением. В отличие от традиционных методов, Decision Transformer моделирует последовательности действий в контексте авторегрессионной модели желаемых вознаграждений. Это позволяет Агенту обучаться принимать решения, ориентируясь на будущие цели и оптимизировать свое поведение на основе этих целей.
В практической части статьи мы реализовали представленный метод средствами MQL5. Провели обучение и тестирование модели. Однако, обученная модель не смогла сгенерировать прибыль на всем промежутке периода тестирования. В первой половине тестовой выборки модель получила прибыль, но вся она была потеряна при продолжении тестирования. Можно сказать, что алгоритм имеет потенциал. Но необходимы дополнительные работы с моделью для получения желаемого результата.
Ссылки
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Нейросети — это просто (Часть 57): Стохастический маргинальный актер-критик (SMAC)
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования