
Нейросети — это просто (Часть 62): Использование Трансформера решений в иерархических моделях

Введение
В процессе решения реальных задач мы часто сталкиваемся с проблемой стохастических и динамически меняющихся окружений, что заставляет нас искать новый адаптивные алгоритмы. В последние десятилетия значительные усилия были направлены на разработку методов обучения с подкреплением (RL), которые позволяют обучать агентов адаптироваться к разнообразным средам и задачам. Однако применение RL в реальных условиях сталкивается с рядом сложностей. Это проблема офлайн обучения в условиях переменных и стохастических сред. А также сложности планирования и управления в высокоразмерных пространствах состояний и действий.
Очень часто, при решении сложных задач, наиболее эффективным способом оказывается деление одной проблемы на составляющие её подзадачи. О преимуществах такого подхода мы разговаривали при рассмотрении иерархических методов. Подобные комплексные подходы позволяют создавать более адаптивные модели.
Ранее мы рассматривали иерархические модели для решения задач с, так сказать, классическим подходом марковского процесса. Однако, преимущества использования иерархических подходов применимо и к задачам анализа последовательностей. Одним из таких алгоритмов является Control Transformer, представленный в статье "Control Transformer: Robot Navigation in Unknown Environments through PRM-Guided Return-Conditioned Sequence Modeling". Авторы метода позиционируют его, как новую архитектуру, предназначенную для решения сложных задач управления и навигации на основе обучения с подкреплением. Данный метод объединяет в себе современные методы обучения с подкреплением, планирования и машинного обучения, что позволяет создавать адаптивные стратегии управления в разнообразных средах.
Control Transformer открывает новые перспективы для решения сложных задач управления в робототехнике, автономном вождении и других областях. Я же предлагаю посмотреть на перспективы использования данного метода в решении наших задач трейдинга.
1. Алгоритм Control Transformer
Алгоритм Control Transformer является довольно комплексным методом и включает в себя несколько отдельных блоков, что, собственно, свойственно иерархическим моделям. Так же надо сказать, что алгоритм был разработан для навигации и управления поведения роботов. Поэтому и описание алгоритма представлено в данном контексте.
Для решения проблемы управления на длинном горизонте планирования авторы метода предлагают декомпозировать её на более мелки подзадачи, в виде некоторых отрезков ограниченного расстояния. Авторы метода используют Вероятностные Дорожные Карты для построения графа G, в котором вершины — это точки, а ребра свидетельствуют о возможности перемещения между соединенными точками при использовании локального планировщика. Данный граф строится на основе выборки n случайных точек в окружающей среде, которые в последствии соединяются с соседними точками на расстоянии не более d (гиперпараметр), образуя ребро в графе при условии существования пути между точками.
Таким образом, в полученном графе G мы можем достичь любой целевой точки Xg из любой начальной точки X0. Это достигается поиском в графе ближайших соседей начальной и целевой точек. А затем с использованием алгоритма поиска кратчайшего пути получаем последовательность путевых точек (траекторию). После чего робот может двигаться от начального состояния к цели, выполняя действия политики локального контролера πc. Последовательность путевых точек или план, которые направляют политику πc, могут быть фиксированными или обновляться по мере продвижения робота.
Для обучения локальной политики πc авторы метода использовали метод обучения с подкреплением, направленное на достижение цели (GCRL). При этом моделируется задача с помощью Марковского процесса принятия решений с условием на цель. Предполагается возможность использования планирования на основе выборки для постановки целей и обучения стратегий.
Для этого, в рамках обучающей среды, сначала используются Вероятностные Дорожные Карты для получения графа G, как было описано выше. Далее для каждого эпизода обучения выбирается ребро из графа, которое служит началом и целью для данного эпизода. Этот процесс совместим с любым алгоритмом обучения с учетом цели. В своих экспериментах с плотными наградами, пропорциональными прогрессу до цели, авторы использовали Soft Actor-Critic. Низкоуровневые стратегии могут быть эффективно обучены, так как пространство состояний стратегий содержит только информацию о собственном положении и им не нужно учиться избегать ограничения.
После обучения локальной политики πc нам необходимо организовать процесс, который будет направлять её для достижения глобальной цели. Иными словами, нам предстоит обучить модель генерирующую плановые траектории. Цели и вознаграждения данной модели устанавливаются относительно конечной цели, а не путевых точек, которым следовала πc. Очевидно, что для достижения глобальных целей модели требуется и больше исходных данных. К низкоразмерным данным о локальном состоянии добавляются высокоразмерные наблюдения и другая доступная информация. К примеру, локальная карта.
Для обучения модели на данных, собранных с использованием планирования на основе выборки, мы рассматриваем задачу моделирования последовательности. Но включаем ориентацию на достижение цели. В своей работе авторы метода также рассматривают частично наблюдаемую многозадачную среду, в которой стратегия может работать в нескольких средах с одной и той же задачей навигации, но с разной структурой для каждого окружения. Несмотря на возможность обучения авторегрессионного прогнозирования действия на этой последовательности, мы сталкиваемся с некоторыми проблемами. Как и в DT, оптимальное RTG предполагается постоянным потому, что мы не знаем оптимальное начальное прогнозное вознаграждение, которое зависит от неизвестной структуры среды. И оно может меняться в разных эпизодах. А также от начальных состояний и позиций цели. Поэтому нам нужно исследовать изменения, которые позволят DT обобщаться к неизвестным средам, работая из любого начального положения к любой цели.
Один из подходов — это учить полное распределение RTG из офлайн данных. А затем выбирать из этого распределения условия во время эксплуатации. Однако сложно выучить полное распределение RTG в задаче, ориентированной на цель, чтобы можно было обобщать и прогнозировать RTG в неизвестных средах. Вместо этого авторы метода предлагают учить среднюю для этого распределения функцию ценности. Которая оценивает ожидаемое вознаграждение в точке S при заданной цели g в рамках траектории T. Эта функция также не обусловлена на прошлую историю, так как в момент начала эксплуатации мы прогнозируем начальное ожидаемое вознаграждение R̃0. Далее корректируем RTG на фактическое вознаграждение от окружающей среды. Функция ценности параметризуется как отдельная нейронная сеть обучается с использованием MSE.
Для получения более оптимального поведения можно скорректировать выученное значение ценности на некий коэффициент-константу. Кроме того, можно обучать функцию ценности только на лучших траекториях или на тех, которые удовлетворяют какому-то заранее заданному условию.
Авторская визуализация метода Control Transformer представлена ниже.
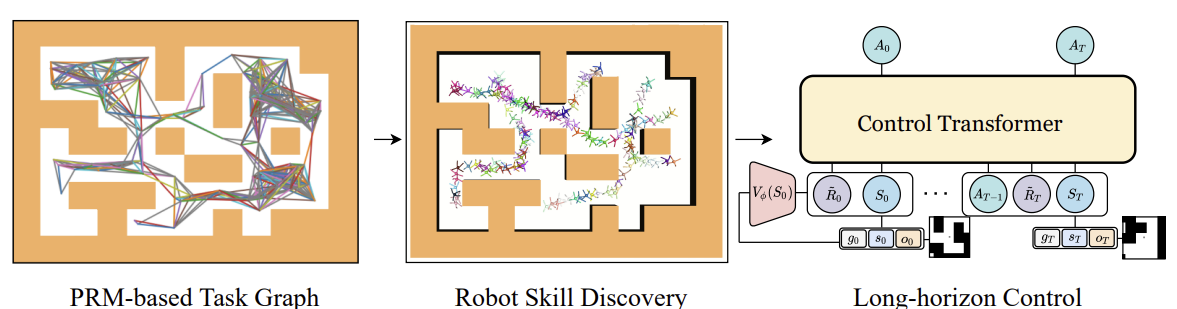
Одной из общих проблем при офлайн обучении является сдвиг распределения. Когда обученная стратегия применяется на практике, и фактическое распределение траекторий не соответствует распределению обучающей выборки. Это может вызвать накапливающиеся ошибки и привести к ситуациям, когда стратегия становится не оптимальной. Для решения данной проблемы авторы метода предлагают после этапа офлайн обучения расширить обучающую выборку с использованием текущей политики модели. И затем провести тонкую настройку моделей офлайн.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода Control Transformer мы переходим к его реализации средствами MQL5. Как уже было сказано ранее, алгоритм является комплексным. Поэтому в процессе реализации мы воспользуемся наработками из ряда предыдущих статей. И первое, с чего мы начинали рассмотрение метода — это построения графа возможных перемещений.
2.1. Сбор обучающей выборки
В нашем случае стохастической окружающей среды и непрерывного пространства действий построение подобного графа может оказаться нетривиальной задачей. Мы же решили подойти к задаче с другой стороны и воспользоваться своими наработками из метода Go-Explore. Мы внесли небольшие корректировки в советник "...\CT\Faza1.mq5" и собрали возможные траектории совершения торговых операций в рамках обучающего периода. При этом мы отбирали траектории с максимальной доходностью.
Для этого во внешних параметрах советника мы добавили максимальное количество сэмплированных действий и минимальную длину траектории. Появление данных параметров вызвано довольно низкой вероятностью (близкой к "0") семплирования приемлемой траектории на всем обучающем интервале за один проход. Гораздо больше вероятность постепенного сэмплирования небольших участков с прибыльными сделками, которые потом собираются в общую прибыльную последовательность действий.
input int MaxSteps = 48; input int MinBars = 20;
Сразу напомню, что в данном советнике не используются модели нейронных сетей. Все действия сэмплируются из равномерного распределения.
В методе инициализации советника мы сначала инициализируем объекты индикаторов и класса торговых операций.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Инициализируем необходимые переменные и сэмплируем траекторию и начальное состояние для продолжения ранее сохраненной траектории. Конечно, такое сэмплирование возможно только при наличии ранее сохраненных траекторий.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); AgentResult = vector<float>::Zeros(NActions); //--- int error_code; if(Buffer.Size() > 0 || LoadTotalBase()) { int tr = int(MathRand() / 32767.0 * Buffer.Size()); Loaded = Buffer[tr]; StartBar = MathMax(0,Loaded.Total - int(MathMax(Math::MathRandomNormal(0.5, 0.5, error_code), 0) * MaxSteps)); } //--- return(INIT_SUCCEEDED); }
При отсутствии ранее пройденных траекторий советник начинает сэмплировать действия с первого бара.
Непосредственно сбор данных осуществляется в функции обработки тиков OnTick. Здесь мы, как и ранее, проверяем наступление события открытия нового бара и, при необходимости, загружаем исторические данные движения инструмента и показателей индикаторов.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- CurrentBar++; int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Загруженные данные мы переносим в структуру для записи в буфер воспроизведения опыта.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Добавляем информацию о состоянии счета и вознаграждение от окружающей среды.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(sState.account[1] / PrevBalance - 1.0);
И переопределим внутренние переменные.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Далее нам предстоит выбрать действие Агента. Как уже было сказано выше, здесь мы не используем модели. Вместо этого мы проверяем начало этапа сэмплирования. При повторении ранее сохраненной траектории мы берем действие из нашей траектории. Если наступил период сэмплирования, то мы генерируем вектор действий из равномерного распределения.
vector<float> temp = vector<float>::Zeros(NActions); if((CurrentBar - StartBar) < MaxSteps) if(CurrentBar < StartBar) temp.Assign(Loaded.States[CurrentBar].action); else temp = SampleAction(NActions);
Полученное действие выполняется в окружающей среде.
//--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
А результаты взаимодействия добавляются в буфер воспроизведения опыта.
//--- int shift = BarDescr * (NBarInPattern - 1); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState) || (CurrentBar - StartBar) >= MaxSteps) ExpertRemove(); //--- }
Здесь же мы проверяем достижение максимального количества сэмплированных шагов и, при необходимости, инициируем завершение работы программы.
Несколько слов надо сказать об изменениях в методе добавления траекторий в буфер воспроизведения опыта. Если ранее траектории добавлялись по методу FIFO — первый вошел - первый вышел; то сейчас мы сохраняем наиболее прибыльные проходы. Поэтому, после завершения очередного прохода мы сначала проверяем размер нашего буфера воспроизведения опыта.
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(total >= MaxReplayBuffer) {
При достижении граничного размера буфера мы сначала осуществляем поиск прохода с минимальной доходностью из ранее сохраненных.
for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Сравниваем доходность нового прохода с минимальной в буфере воспроизведения опыта и, при необходимости, записываем новый проход вместо минимального.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
Это позволяет нам отказаться от затратной сортировки данных в буфере. За один проход мы определяем минимальное значение и целесообразность сохранения новой траектории.
Если же граничный размер буфера воспроизведения опыта ещё не достигнут, то мы просто добавляем новый проход. И завершаем работу метода.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
На этом мы завершаем знакомство с советником взаимодействия с окружающей средой. А с полным его кодом вы можете познакомиться во вложении.
2.2. Обучение навыков
Следующим этапом мы создадим советник обучения локальной политики. Надо сказать, что локальная политика выполняет роль исполнителя, выполняющего указания вышестоящего планировщика. И здесь с целью упрощения самой модели локальной политики и в духе иерархических систем мы решили не подавать на вход модели текущее состояние окружающей среды. В нашем видении архитектуры это будет модель, обладающая некоторым набором навыков. А выбор используемого навыка остается за планировщиком. При этом сама модель локальной политики не будет анализировать состояние окружающей среды.
Для обучения навыков мы воспользуемся архитектурой автоэнкодера и наработками рассмотренных ранее иерархических моделей. В процессе обучения мы будем случайным образом подавать один навык на вход нашей модели локальной политики. А дискриминатор будет стараться идентифицировать используемый навык.
И тут нам предстоит определить необходимое количество обучаемых навыков. Здесь мы также обращаемся к нашим прошлым работам. При рассмотрении методов кластеризации мы определили оптимальное количество кластеров в диапазоне 100-500. Чтобы не испытывать дефицита навыков, мы укажем размер вектора исходных данных локальной политики 512 элементов.
#define WorkerInput 512
Ниже представлены архитектуры моделей локальной политики и дискриминатора. Мы не стали сильно усложнять данные модели. На вход модели локальной политики мы ожидаем получать one-hot вектор. Или вектор данных, нормализованных функцией SoftMax. Поэтому мы не стали добавлять слой пакетной нормализации после слоя исходных данных.
bool CreateWorkerDescriptions(CArrayObj *worker, CArrayObj *descriminator) { //--- CLayerDescription *descr; //--- if(!worker) { worker = new CArrayObj(); if(!worker) return false; } //--- Worker worker.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Далее следуют 2 полносвязных нейронных слоя с различными функциями активации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
После чего мы понижаем размерность слоя и нормализуем данные функцией SoftMax в разрезе пространства действий нашего Агента.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
И на выходе локальной политики полносвязный нейронный слой размером равным вектору действий Агента.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Модель дискриминатора имеет несколько обратную архитектуру по образу декодера. На вход модели мы подаем вектор действий Агента, который генерируется моделью локальной политики. Здесь мы так же не используем слой пакетной нормализации.
//--- Descriminator if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } //--- descriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Далее идут те же полносвязные слои, которые мы использовали в локальной политике.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
После чего мы изменяем размерность до количества используемых навыков и нормализуем вероятности использования навыков функцией SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Мы создали модели максимально простыми. Это позволит нам максимально ускорить их работу как в процессе обучения, так и в процессе эксплуатации.
Для обучения навыков мы создадим советник "...\CT\StudyWorker.mq5". Мы не будем долго останавливаться на подробном рассмотрении всех методов данного советника. Рассмотрим лишь метод непосредственного обучения моделей Train.
В теле данного метода организован цикл обучения моделей по числу итераций, указанных во внешнем параметре советника. Внутри цикла мы сначала формируем случайный one-hot вектор с размером равным количеству навыков.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { Data.BufferInit(WorkerInput, 0); int pos = int(MathRand() / 32767.0 * (WorkerInput - 1)); Data.Update(pos, 1.0f);
Данный вектор мы подаем на вход модели локальной политики и осуществляем прямой проход. Полученный результат подаем на вход дискриминатора.
//--- Study if(!Worker.feedForward(Data,1,false) || !Descrimitator.feedForward(GetPointer(Worker),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Не забываем контролировать процесс выполнения операций.
После успешного прямого прохода обоих моделей мы осуществляем обратный проход моделей с целью минимизации отклонений между фактическим и определенным дискриминатором навыком.
if(!Descrimitator.backProp(Data,(CBufferFloat *)NULL, (CBufferFloat *)NULL) || !Worker.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Далее нам остается лишь проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации цикла.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Desciminator", iter * 100.0 / (double)(Iterations), Descrimitator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения всех итераций цикла мы очищаем поле комментариев. Выводим результат обучения. И инициируем завершение работы программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Descriminator", Descrimitator.getRecentAverageError()); ExpertRemove(); //--- }
Такой довольно простой способ позволяет нам обучить нужное количество различимых навыков. В процессе построения иерархических моделей очень важна различимость навыков по совершаемым действиям. Это помогает разнообразить поведение модели и облегчить работу планировщика в части выбора нужного навыка в конкретном состоянии окружающей среды.
2.3. Обучение функции стоимости
Далее мы переходим к изучению функции стоимости. Ожидается, что обученная модель сможет прогнозировать возможную доходность после анализа текущего состояния окружающей среды. По существу, это оценка будущего состояния в классическом RL, которую мы в том или ином виде изучаем практически во всех моделях. Только авторы метода предлагают рассматривать её без коэффициента дисконтирования.
Я же решил провести эксперимент с оценкой стоимости не до конца эпизода, а лишь на небольшом горизонте планирования. Моя логика заключалась в том, что мы не планируем открывать позицию и держать её "до скончания века". В условиях стохастичности рынка такие далеко идущие прогнозы имеют слишком малую вероятность. В остальном подход остался довольно узнаваем. И я опять не стал слишком усложнять модель. Архитектура модели представлена ниже.
На вход модели мы подаем небольшое количество исторических данных описания состояния окружающей среды. В данной модели мы будем оценивать только рыночную ситуацию, чтобы оценить основные возможный потенциал. Обратите внимание, что в данном случае нас не интересуют тренды и тенденции. Мы акцентируем внимание на интенсивности рынка. И так как мы используем сырые данные, то в данной модели мы уже используем слой пакетной нормализации.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Нормализованные данные обрабатываются сверточным слоем в разрезе свечей, что позволяет нам выявить основные паттерны.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = ValueBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; }
После чего данные обрабатываются блоком полносвязных слоев и выдается результат в виде вектора декомпозированного вознаграждения.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
Для обучения функции стоимости мы создаем советник "...\CT\StudyValue.mq5". Здесь мы так же остановимся методе обучения модели Train. Для обучения данной модели нам уже потребуется обучающая выборка. Поэтому в теле цикла обучения мы сэмплируем траекторию и состояние.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); int check = 0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 * ValueBars)); if(i < 0) { iter--; continue; check++; if(check >= total_tr) break; }
Обратите внимание, что при сэмплировании траектории мы диапазон возможных состояний уменьшаем на двойную величину ValueBars. Это связано с тем, что в буфере воспроизведения опыта каждое состояние содержит только последний бар (связано с использование архитектуры GPT в DT), а нам необходимо несколько баров исторических данных для оценки потенциала. И второй момент, из общего накопительного вознаграждения до конца эпизода мы будем снимать вознаграждение за пределами горизонта планирования.
Далее мы заполняем буфер исходных данных.
check = 0; //--- History data State.AssignArray(Buffer[tr].States[i].state); for(int state = 1; state < ValueBars; state++) State.AddArray(Buffer[tr].States[i + state].state);
И осуществляем прямой проход модели.
//--- Study if(!Value.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Затем нам предстоит подготовить целевые данные для обучения модели. Мы берем из буфера воспроизведения опыта накопленное вознаграждение на момент оценки состояния и отнимаем накопленное вознаграждение за пределами гори зонта планирования. После чего загружаем результаты прямого прохода модели и с помощью метода CAGrad корректируем вектор целевых значений.
vector<float> target, result; target.Assign(Buffer[tr].States[i + ValueBars - 1].rewards); result.Assign(Buffer[tr].States[i + 2 * ValueBars - 1].rewards); target = target - result*MathPow(DiscFactor,ValueBars); Value.getResults(result); Result.AssignArray(CAGrad(target - result) + result);
Подготовленный вектор целевых значений передаем в модель и осуществляем обратный проход. При этом не забываем контролировать процесс выполнения операций.
if(!Value.backProp(Result, (CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Далее мы информируем пользователя о процессе обучения модели и переходим к следующей итерации цикла обучения.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Value", iter * 100.0 / (double)(Iterations), Value.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После успешного прохождения всех итераций цикла мы очищаем поле комментариев на графике инструмента. Выводим в журнал результат обучения модели. И инициируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Value", Value.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом советника, как и всех программ, используемых в статье, можно познакомиться во вложении.
2.4. Обучение Планировщика
А мы переходим к следующей стадии нашей работы и создадим Планировщика нашей иерархической модели. В данном случае в роли планировщика выступает Decision Transformer, который будет анализировать последовательность посещенных состояний и совершенных в них действий. А на выходе планировщика мы ожидаем получить навык, который будет использовать наша модель локальной политики для генерации действий.
И начнем мы с архитектуры модели. В качестве исходных данных мы будем использовать вектор описания одного состояния в нашей траектории, который включает всю возможную информацию. Надо сказать, что информация подается необработанная, поэтому мы используем слой пакетной нормализации данных для предварительной их обработки.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Кроме того, данные в векторе исходных данных собраны из разных источников. Соответственно, имеют разную размерность и распределение. Для удобства их дальнейшего использования и приведения в сопоставимый вид применяется слой эмбединга.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Подготовленные данные проходят через блок разреженного Трансформера.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
После чего мы понижаем размерность данных с помощью сверточного слоя.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Далее данные проходят через блок принятия решения из полносвязных слоев.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
На выходе мы понижаем размерность данных до числа используемых навыков и нормализуем их вероятность функцией SoftMax.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
После рассмотрения архитектуры модели мы переходим к построению советника обучения Планировщика "...\CT\Study.mq5". И уже по сложившейся традиции мы остановимся только на методе обучения модели Train.
Здесь надо сказать, что подход к обучению DT практически не изменился. В модели мы выстраиваем зависимости между исходными данными (в том числе RTG) и совершаемым Агентом действием. Но есть нюансы, связанные с принципами построения рассматриваемого алгоритма:
- RTG должна быть не до конца эпизода, а только на горизонт планирования;
- на выходе DT мы имеем навык, а не действия. Для передачи градиента ошибки используется модель локальной политики.
Все эти нюансы отражаются на процессе обучения модели.
В теле метода Train мы, как и ранее, организовываем систему циклов обучения модели. В теле внешнего цикла мы сэмплируем траекторию и начальное состояние для обучения модели.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float err=0; int err_count=0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars-ValueBars,MathMin(Buffer[tr].Total,20+ValueBars))); if(i < 0) { iter--; continue; }
А непосредственно процесс обучения осуществляется в теле вложенного цикла. Напомню, что в связи с особенностями архитектуры GPT в процессе обучения нам необходимо использовать исторические данные в строго соответствии их поступления.
В буфер исходных данных мы последовательно загружаем исторические показатели ценового движения и индикаторов.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - 2 - ValueBars,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Данные о состоянии счета.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Временную метку и последнее действие Агента.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
Далее нам предстоит указать RTG. И здесь мы используем фактическое накопленное вознаграждение. Только предварительно скорректируем его на горизонт планирования.
//--- Return-To-Go vector<float> rtg; rtg.Assign(Buffer[tr].States[state+1].rewards); Actions.Assign(Buffer[tr].States[state+ValueBars].rewards); rtg=rtg-Actions*MathPow(DiscFactor,ValueBars); State.AddArray(rtg);
Собранные таким образом данные подаем на вход Планировщика и вызываем метод прямого прохода. Полученный прогнозный навык мы передаем на вход модели локальной политики и осуществляем её прямой проход для прогнозирования действия Агента.
//--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat *)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Спрогнозированное таким образом действие Агента мы сравниваем с фактическим действием из буфера воспроизведения опыта, которое дало вознаграждение, заданное в исходных данных. Для обучения модели нам необходимо минимизировать отклонение между 2 векторами значений. Мы подаем вектор целевого действия на выход модели локально политики и осуществляем последовательный обратный проход обоих моделей.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Worker.getResults(rtg); if(err_count==0) err=rtg.Loss(Actions,LOSS_MSE); else err=(err*err_count + rtg.Loss(Actions,LOSS_MSE))/(err_count+1); if(err_count<1000) err_count++; Result.AssignArray(CAGrad(Actions - rtg) + rtg); if(!Worker.backProp(Result,NULL,NULL) || !Agent.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Здесь стоит обратить внимание, что в данном случаем мы используем уже обученную модель локальной политики. И во время обратного прохода мы обновляем параметры только планировщика. Для этого нам необходимо установить флаг обучения модели локальной политики в положение false (Worker.TrainMode(false)). В представленной реализации я сделал это в методе инициализации советника, чтобы не повторять операцию на каждой итерации.
Далее нам остается лишь проинформировать пользователя о процессе обучения и перейти к следующей итерации цикла.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), err); Comment(str); ticks = GetTickCount(); } } }
После завершения всех итераций системы циклов мы повторяем операции завершения работы советника, которые уже дважды описаны выше.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", err); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение алгоритмов обучения моделей. Здесь можно обратить внимание, что в этой статье мы создали 3 советника обучения моделей вместо одного, используемого ранее. Такой подход позволяет нам распараллелить процесс обучения моделей. Как можно заметить, советник обучения навыков не требует обучающей выборки. И мы можем обучать навыки параллельно с процессом сбора обучающей выборки. А в процессе обучения Планировщика и Функции стоимости мы используем буфер воспроизведения опыта. Но при этом процессы не пересекаются и могут быть запущены параллельно, даже на разных машинах.
2.5. Советник тестирования моделей
После обучения моделей нам будет нужно оценить полученные результаты в практическом трейдинге. Конечно, мы будем проверять модель в тестере стратегий. Но нам необходим советник, который объединит все рассмотренные выше модели в единый комплекс принятия решения. Это функционал мы реализуем в советнике "...\CT\Test.mq5". Мы не будем рассматривать все методы советника. Я предлагаю остановиться лишь на функции OnTick, в которой и организован основной алгоритм принятия решения.
В начале метода мы проверяем наступления события открытия нового бара. Как вы помните, все торговые операции мы совершаем при открытии нового бара. При этом анализируем только закрытые свечи.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Тут же мы, при необходимости, загружаем исторические данные с сервера.
Далее нам предстоит заполнить историческими данными буфера исходных данных для наших моделей. Здесь стоит обратить внимание, что модель функции стоимости и планировщик используют разные по структуре и глубине истории данные. Вначале мы заполняем буфер данными для функции стоимости и осуществляем её прямой проход.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars-1; b >=0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!Value.feedForward(GetPointer(bState), 1, false)) return;
Затем мы заполняем буфер данными для планировщика. Обратите внимание, что последовательность данных должна полностью повторять последовательность их подачи при обучении модели. Первыми мы переносим исторические данные о ценовом движении и показатели индикаторов.
for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Дополняем их информацией о состоянии счета.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Далее идут временная метка и последнее действие Агента.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
В завершении буфера мы добавляем RTG. Данное значение мы берем из буфера результатов функции стоимости.
//--- Return to go
Value.getResults(Result);
bState.AddArray(Result);
После завершения процесса подготовки данных мы последовательно осуществляем прямой проход Планировщика и модели локальной политики. При этом обязательно контролируем процесс выполнения операций.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent), -1, (CBufferFloat *)NULL)) return;
Спрогнозированные таким образом действия Агента обрабатываются и выполняются в окружающей среде.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Worker.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Результаты взаимодействия с окружающей средой сохраняются в буфер воспроизведения опыта для последующей тонкой настройки модели.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Надо отметить, что собранные таким образом данные могут быть использованы как для тонкой настройки модели, так и для последующего дообучения модели в процессе эксплуатации. Что позволит нам постоянно её адаптировать к изменяющимся условиям окружающей среды.
3. Тестирование
Выше мы проделали довольно большую работу по созданию советников сбора данных и обучения моделей. Как уже было выше сказано, мы разбили весь процесс на отдельные советники для возможности выполнения нескольких задач параллельно. И первым этапом мы запускаем советник обучения навыков "StudyWorker.mq5", который работает автономно и не требует обучающей выборки. При этом сами занимаемся процессом сбора обучающей выборки.
Тут я должен сказать, что процесс сбора обучающей выборки на историческом периоде в первые 7 месяцев 2023 года оказался довольно трудоемким. Я столкнулся с проблемой, что даже при малом горизонте сэмплирования действий Агента большинство проходов не удовлетворяли требования положительного баланса.
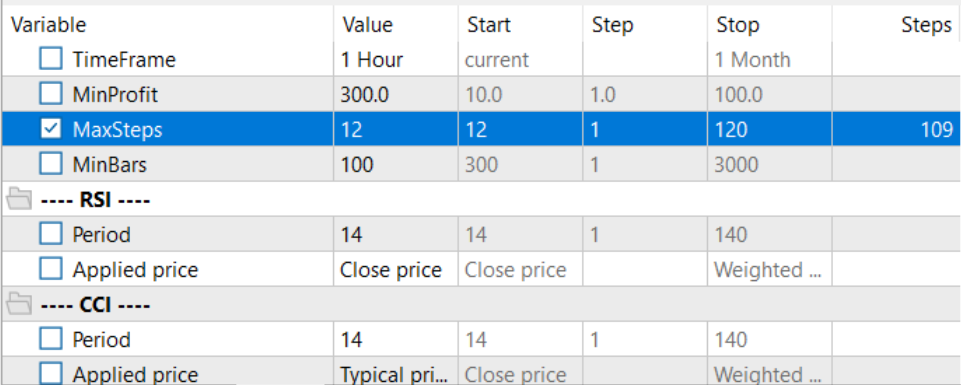
Для выбора оптимального горизонта планирования в режиме оптимизации количества итераций на один проход было вынесено с оптимизируемые параметры.
После сбора обучающей выборки и обучения модели локальной политики я параллельно запустил обучение планировщика и модели функции стоимости. Такой подход мне позволил значительно сократить время на обучение моделей.
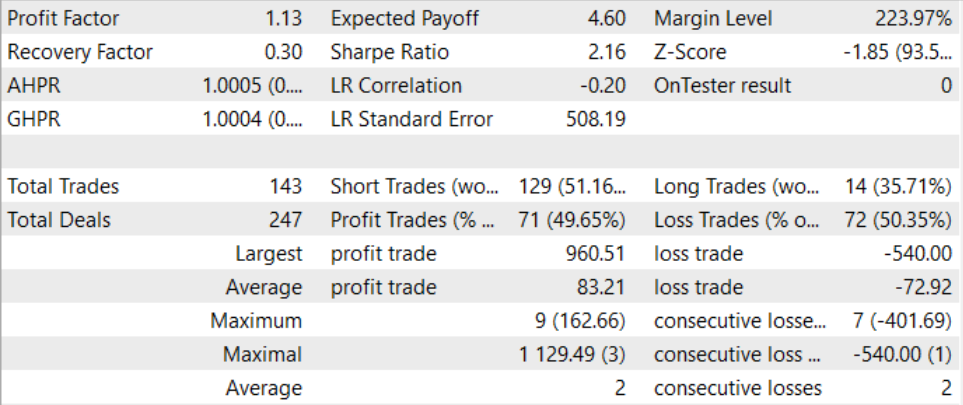
После длительного и довольно сложного процесса обучения нам удалось получить модель, способную генерировать прибыль за пределами обучающей выборке. Обученная модель была протестирована на исторических данных за август 2023 года. И по результатам тестирования профит-фактор составил 1.13. Должен сказать, что соотношение прибыльных и убыточных позиций близко 1:1. И вся прибыль достигнута благодаря превышению средней прибыльной сделки над средним убытком.
Заключение
В данной статье мы познакомились с методом Control Transformer, который представляет инновационную архитектуру для обучения стратегий управления в сложных и динамически изменяющихся средах. Control Transformer объединяет в себе современные методы обучения с подкреплением, планирования и машинного обучения, создавая гибкие и адаптивные стратегии управления.
Control Transformer открывает новые перспективы для развития различных автономных систем и роботов. Его способность адаптироваться к разнообразным средам, учитывать динамические условия и обучаться в офлайн режиме делает его мощным инструментом для создания интеллектуальных и автономных систем, способных решать сложные задачи управления и навигации.
В практической части статьи мы реализовали свое видение представленного метода средствами MQL5. В данной реализации мы использовали новый подход разделения процесса обучения моделей на отдельные не связанные советники, что позволяет выполнять несколько задач параллельно. И это позволяет значительно сократить общее время обучения моделей.
В процессе обучения и тестирования моделей нам удалось создать модель, способную генерировать прибыль. Это позволяет нам говорить об эффективности рассмотренного подхода и возможности его использования для построения торговых решений.
И ещё раз напоминаю, что все представленные в статье программы носят информативный характер и предназначены для демонстрации представленного алгоритма. Они не готовы для использования в условиях реального рынка.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Faza1.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения Планировщика |
| 3 | StudyWorker.mq5 | Советник | Советник обучения модели локальной политики |
| 4 | StudyValue.mq5 | Советник | Советник обучения Функции стоимости |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования