
Redes neuronales: así de sencillo (Parte 62): Uso del transformador de decisiones en modelos jerárquicos

Introducción
En el proceso de resolución de problemas del mundo real, con frecuencia nos enfrentamos al problema de entornos estocásticos y dinámicamente cambiantes, lo cual nos obliga a buscar nuevos algoritmos adaptativos. En las últimas décadas, se ha dedicado un esfuerzo considerable al desarrollo de técnicas de aprendizaje por refuerzo (RL) que entrenan a los agentes para adaptarse a diversos entornos y tareas. No obstante, la aplicación de la RL en el mundo real se enfrenta a una serie de retos. Este es el problema del aprendizaje offline en entornos variables y estocásticos, así como las complejidades de la planificación y el control en espacios de estado y acciones de alta dimensionalidad.
Muy a menudo, al resolver problemas complejos, lo más eficaz resulta dividir una única tarea en subtareas. Ya hablamos de las ventajas de este enfoque al considerar los métodos jerárquicos. Estos enfoques integrados permiten crear modelos más adaptables.
Antes, analizamos los modelos jerárquicos para resolver problemas con, por así decirlo, el enfoque clásico de los procesos de Markov. Sin embargo, las ventajas de usar enfoques jerárquicos también son aplicables a los problemas de análisis de secuencias. Uno de estos algoritmos es el Control Transformer, presentado en el artículo "Control Transformer: Robot Navigation in Unknown Environments through PRM-Guided Return-Conditioned Sequence Modeling". Los autores del método lo posicionan como una nueva arquitectura diseñada para resolver tareas complejas de control y navegación basadas en el aprendizaje por refuerzo. Este método combina las técnicas más avanzadas de aprendizaje por refuerzo, planificación y aprendizaje automático para crear estrategias de control adaptativo en diversos entornos.
El Control Transformer abre nuevas perspectivas para resolver complejas tareas de control en robótica, conducción autónoma y otras áreas. No obstante, hoy me propongo examinar las perspectivas de uso de este método para resolver nuestros problemas comerciales.
1. Algoritmo del Control Transformer
El algoritmo del Control Transformer es un método bastante complejo e incluye varios bloques aparte, lo que en realidad es característico de los modelos jerárquicos. También debemos decir que el algoritmo se ha diseñado para navegar y controlar el comportamiento de robots. Por ello, la descripción del algoritmo también se presentará en este contexto.
Para resolver el problema de gestión en un horizonte de planificación largo, los autores del método proponen descomponerlo en subtareas más pequeñas, en forma de segmentos de distancia limitada. Los autores del método usan hojas de ruta probabilísticas para construir un grafo G en el que los vértices son puntos y las aristas indican la posibilidad de viajar entre puntos conectados utilizando un planificador local. Este grafo se construye muestreando n puntos aleatorios en el entorno, que posteriormente se conectan a puntos vecinos a una distancia no superior a d (hiperparámetro), formando una arista en el grafo siempre que exista un camino entre los puntos.
Así, en el grafo G resultante, podemos alcanzar cualquier punto objetivo Xg desde cualquier punto inicial X0. Para ello, se buscan los vecinos más próximos de los puntos inicial y final en el gráfico. Y luego, utilizando el algoritmo del camino más corto, obtenemos una secuencia de waypoints (trayectoria). A continuación, el robot puede pasar del estado inicial al objetivo ejecutando las acciones de la política del controlador local πc. La secuencia de waypoints o plan que guía la política πc puede fijarse o actualizarse a medida que avanza el robot.
Los autores del método usaron el aprendizaje por refuerzo dirigido a objetivos (GCRL) para entrenar la política πc local. En este caso, el problema se modela con la ayuda de un proceso de decisión de Markov con una condición sobre el objetivo. Se prevé que la planificación basada en el muestreo pueda usarse para fijar objetivos y enseñar estrategias.
Para ello, en el entorno de aprendizaje, primero se usan hojas de ruta probabilísticas para producir un grafo G como el descrito anteriormente. A continuación, para cada episodio de aprendizaje, se selecciona una arista del grafo que servirá de inicio y objetivo para ese episodio. Este proceso resulta compatible con cualquier algoritmo de aprendizaje por objetivos. Los autores utilizaron Soft Actor-Critic en sus experimentos con recompensas densas proporcionales al progreso hacia el objetivo. Las estrategias de bajo nivel pueden entrenarse de forma eficaz porque el espacio de estados de las estrategias solo contiene información sobre su propia posición y no necesitan aprender a evitar restricciones.
Tras entrenar a la política local πc tenemos que organizar un proceso que la guíe para alcanzar el objetivo global. En otras palabras, debemos entrenar un modelo que genere trayectorias planificadas. Los objetivos y las recompensas de este modelo se establecerán en relación con el objetivo final y no con los waypoints seguidos por πc. Obviamente, también se necesitan más datos de entrada para alcanzar los objetivos globales del modelo. Las observaciones de alta dimensionalidad y otra información disponible se añaden a los datos de baja dimensionalidad del estado local. Por ejemplo, un mapa local.
Para entrenar el modelo con los datos recogidos usando la planificación por muestreo, analizaremos un problema de modelización de secuencias, pero incluiremos la orientación por objetivos. En su artículo, los autores del método también consideran un entorno multitarea parcialmente observable en el que una estrategia puede operar en múltiples entornos con la misma tarea de navegación, pero con una estructura diferente para cada entorno. A pesar de la posibilidad de entrenar la predicción autorregresiva de acciones en esta secuencia, nos enfrentamos a algunos problemas. Como en el DT, el RTG óptimo se supone constante porque no conocemos la recompensa de previsión inicial óptima, que depende de la estructura desconocida del entorno, y puede cambiar de un episodio a otro, así como los estados y posiciones iniciales del objetivo. Por ello, necesitamos investigar cambios que permitan al DT generalizarse a entornos desconocidos, trabajando desde cualquier posición de partida hacia cualquier objetivo.
Un enfoque consiste en aprender la distribución de RTG completa a partir de datos offline, y luego elegir entre esta distribución de condiciones durante el funcionamiento. No obstante, resulta difícil aprender la distribución completa de RTG en una tarea dirigida a un objetivo para poder generalizar y predecir los RTG en entornos desconocidos. En su lugar, los autores del método proponen entrenar la función de valor medio de esta distribución, que estima la recompensa esperada en un punto S para un objetivo g dado dentro de una trayectoria T. Esta función tampoco está condicionada por la historia pasada, ya que predecimos una recompensa inicial esperada de R̃0 en el momento del inicio. A continuación, ajustaremos el RTG en función de la recompensa real del entorno. La función de valor se parametriza como una red neuronal independiente que se entrena usando MSE.
El valor aprendido puede ajustarse usando algún coeficiente-constante para obtener un comportamiento más óptimo. De forma alternativa, podemos entrenar la función de valor solo con las mejores trayectorias o con aquellas que cumplan alguna condición predefinida.
A continuación se muestra la visualización del autor del método de Control Transformer.
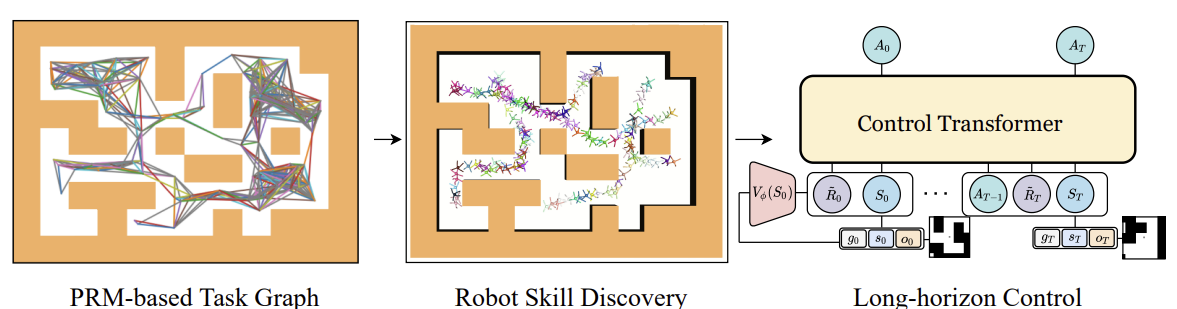
Un problema habitual en el aprendizaje offline es el desplazamiento distributivo, cuando la estrategia entrenada se aplica en la práctica y la distribución real de las trayectorias no coincide con la distribución de la muestra de entrenamiento. Esto puede hacer que los errores se acumulen y provoquen situaciones en las que la estrategia deje de resultar óptima. Para resolver este problema, los autores del método ofrecen ampliar la muestra de entrenamiento tras la fase de entrenamiento offline usando la política del modelo actual, y luego afinar un poco los modelos offline.
2. Implementación usando MQL5
Tras considerar los aspectos teóricos del método del Control Transformer, comenzaremos su implementación usando herramientas MQL5. Como ya hemos dicho, el algoritmo es complejo. Por consiguiente, en el proceso de aplicación usaremos lo aprendido en varios artículos anteriores. Y el primer lugar donde empezaremos el análisis del método es la construcción del grafo de posibles desplazamientos.
2.1. Recogida de la muestra de entrenamiento
En nuestro caso, con un entorno estocástico y un espacio continuo de acciones, construir un grafo de este tipo puede ser una tarea no trivial. Hemos decidido abordar la tarea desde otro enfoque y utilizar nuestros desarrollos del método Go-Explore. Así, hemos realizado pequeños ajustes en el asesor "...\CT\Faza1.mq5" y recopilado posibles trayectorias de operaciones comerciales dentro del periodo de entrenamiento. Haciendo esto, seleccionaremos las trayectorias con rendimientos máximos.
Para ello, añadimos el número máximo de acciones muestreadas y la longitud mínima de la trayectoria en los parámetros externos del asesor. La aparición de estos parámetros se debe a la probabilidad bastante baja (cercana a "0") de muestrear una trayectoria aceptable en todo el intervalo de entrenamiento en una sola pasada. Resulta mucho más probable muestrear gradualmente pequeñas áreas con operaciones rentables, que luego se ensamblen en una secuencia general de acciones rentables.
input int MaxSteps = 48; input int MinBars = 20;
Permítame recordarle que este asesor no utiliza modelos de redes neuronales. Todas las acciones se muestrean partiendo de una distribución uniforme.
En el método de inicialización del asesor, primero inicializamos los objetos de la clase indicadores y operaciones comerciales.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Luego inicializamos las variables necesarias y muestreamos la trayectoria y el estado inicial para continuar la trayectoria previamente guardada. Obviamente, este muestreo solo es posible si existen trayectorias previamente guardadas.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); AgentResult = vector<float>::Zeros(NActions); //--- int error_code; if(Buffer.Size() > 0 || LoadTotalBase()) { int tr = int(MathRand() / 32767.0 * Buffer.Size()); Loaded = Buffer[tr]; StartBar = MathMax(0,Loaded.Total - int(MathMax(Math::MathRandomNormal(0.5, 0.5, error_code), 0) * MaxSteps)); } //--- return(INIT_SUCCEEDED); }
Si no existen trayectorias pasadas anteriormente, el asesor comenzará a muestrear acciones desde la primera barra.
Los datos se recogen directamente en la función de procesamiento de ticks OnTick. Aquí, como antes, comprobamos la aparición de un nuevo evento de apertura de barra y, de ser necesario, cargamos los datos históricos de los movimientos de los instrumentos e indicadores.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- CurrentBar++; int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Luego transferimos los datos descargados a una estructura para escribirlos en el búfer de reproducción de la experiencia.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Después añadimos la información de la cuenta y las recompensas del entorno,
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(sState.account[1] / PrevBalance - 1.0);
y redefinimos las variables internas.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
A continuación, debemos elegir la acción del Agente. Como ya hemos dicho, aquí no utilizamos modelos. En su lugar, comprobamos el inicio de la etapa de muestreo. Cuando repetimos una trayectoria previamente guardada, tomamos la acción de nuestra trayectoria; si se ha producido un periodo de muestreo, generaremos un vector de acción a partir de una distribución uniforme.
vector<float> temp = vector<float>::Zeros(NActions); if((CurrentBar - StartBar) < MaxSteps) if(CurrentBar < StartBar) temp.Assign(Loaded.States[CurrentBar].action); else temp = SampleAction(NActions);
La acción resultante se realiza en el entorno,
//--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
mientras que los resultados de la interacción se añaden al búfer de reproducción de experiencias.
//--- int shift = BarDescr * (NBarInPattern - 1); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState) || (CurrentBar - StartBar) >= MaxSteps) ExpertRemove(); //--- }
Aquí también comprobamos que se haya alcanzado el número máximo de pasos muestreados y, de ser necesario, iniciaremos la finalización del programa.
Debemos decir unas palabras sobre los cambios en el método de adición de trayectorias al búfer de reproducción de experiencias. Mientras que antes las trayectorias se añadían siguiendo el método FIFO -primero en entrar, primero en salir-, ahora guardaremos las pasadas más rentables. Por ello, tras completar otra pasada, primero comprobamos el tamaño de nuestro búfer de reproducción de experiencias.
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(total >= MaxReplayBuffer) {
Al alcanzar el tamaño límite del búfer, primero buscamos la pasada con el rendimiento mínimo entre las almacenadas anteriormente.
for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Después comprobamos el rendimiento de la nueva pasada con el mínimo en el búfer de reproducción de experiencias y, si es necesario, registramos una nueva pasada en lugar de la pasada mínima.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
Esto nos permite prescindir de la costosa clasificación de los datos en el búfer. En una sola pasada, determinamos el valor mínimo y la viabilidad de mantener la nueva trayectoria.
Si aún no hemos alcanzado el tamaño límite del búfer de reproducción de experiencias, simplemente añadimos una nueva pasada. Luego finalizaremos el método.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
Con esto concluimos nuestra introducción al asesor de interacción con el entorno. Podrá ver su código completo en el archivo adjunto.
2.2. Entrenamiento de habilidades
El siguiente paso consiste en crear un asesor local de entrenamiento de la política. Hay que decir que la política local cumple el papel de un ejecutor, realizando las instrucciones del planificador de nivel superior. También en este caso, para simplificar el propio modelo de política local, y siguiendo el espíritu de los sistemas jerárquicos, hemos decidido no introducir el estado actual del entorno en la entrada del modelo. En nuestra visión de la arquitectura, será un modelo con cierto conjunto de habilidades, mientras que la elección de la habilidad a utilizar se dejará al planificador. No obstante, el propio modelo de política local no analizará el estado del entorno.
Para entrenar las destrezas, utilizamos la arquitectura del autocodificador y los desarrollos de los modelos jerárquicos comentados anteriormente. Durante el entrenamiento, suministraremos aleatoriamente una habilidad a la entrada de nuestro modelo de política local, mientras que el discriminador intentará identificar la habilidad utilizada.
Y aquí debemos determinar el número necesario de habilidades a entrenar. De la misma forma, aquí nos remitimos a nuestro trabajo anterior. Al analizar los métodos de clusterización, determinamos que el número óptimo de clústeres se situaba entre 100 y 500. Para evitar un déficit de habilidades, especificaremos que el tamaño del vector de datos de origen de la política local sea de 512 elementos.
#define WorkerInput 512
A continuación se presentan las arquitecturas de los modelos de la política local y el discriminador. No hemos complicado mucho estos modelos. En la entrada del modelo de política local, esperamos obtener un vector one-hot, o un vector de datos normalizado por la función SoftMax. Por consiguiente, no añadimos una capa de normalización por lotes después de la capa de datos de origen.
bool CreateWorkerDescriptions(CArrayObj *worker, CArrayObj *descriminator) { //--- CLayerDescription *descr; //--- if(!worker) { worker = new CArrayObj(); if(!worker) return false; } //--- Worker worker.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
Le siguen 2 capas neuronales totalmente conectadas con diferentes funciones de activación.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
A continuación, reducimos el tamaño de la capa y normalizamos los datos con la función SoftMax en términos del espacio de acción de nuestro Agente.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
La salida de la política local será una capa neuronal totalmente conectada de tamaño igual al vector de acción del Agente.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!worker.Add(descr)) { delete descr; return false; }
El modelo discriminador tiene una arquitectura en cierto sentido inversa a la del descodificador. Como entrada al modelo, introducimos el vector de acción del Agente, que es generado por el modelo de la política local. Aquí tampoco usamos la capa de normalización por lotes.
//--- Descriminator if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } //--- descriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Después están las mismas capas completamente conectadas que utilizamos en la política local.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
A continuación, cambiamos la dimensionalidad por el número de habilidades usadas y normalizamos las probabilidades de uso de las habilidades con la función SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Hemos simplificado al máximo los modelos. Esto nos permitirá maximizar su velocidad tanto en los entrenamientos como en la explotación.
Para el entrenamiento de habilidades crearemos un asesor "...\CT\StudyWorker.mq5". No nos detendremos mucho en hacer un repaso detallado de todos los métodos de este asesor. Vamos a analizar únicamente el método de entrenamiento directo de modelos Train.
El cuerpo de este método organiza un ciclo de modelos de entrenamiento según el número de iteraciones especificado en el parámetro externo del asesor. Dentro del ciclo, primero generamos un vector aleatorio one-hot con un tamaño igual al número de habilidades.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { Data.BufferInit(WorkerInput, 0); int pos = int(MathRand() / 32767.0 * (WorkerInput - 1)); Data.Update(pos, 1.0f);
Introducimos este vector en la entrada del modelo de política local y realizamos una pasada directa. El resultado obtenido se introduce en la entrada del discriminador.
//--- Study if(!Worker.feedForward(Data,1,false) || !Descrimitator.feedForward(GetPointer(Worker),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
No se olvide de supervisar el proceso de las operaciones.
Después de realizar la pasada directa de ambos modelos con éxito, realizamos una pasada inversa de los modelos para minimizar las desviaciones entre la habilidad real y la habilidad definida por el discriminador.
if(!Descrimitator.backProp(Data,(CBufferFloat *)NULL, (CBufferFloat *)NULL) || !Worker.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Luego solo tenemos que informar al usuario sobre el progreso del proceso de entrenamiento y pasar a la siguiente iteración del ciclo.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Desciminator", iter * 100.0 / (double)(Iterations), Descrimitator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Después de completar todas las iteraciones del ciclo, limpiaremos el campo de comentarios. Mostramos el resultado del entrenamiento. E iniciamos la finalización del programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Descriminator", Descrimitator.getRecentAverageError()); ExpertRemove(); //--- }
Este método, bastante sencillo, nos permite entrenar la cantidad justa de habilidades discernibles. En el proceso de construcción de modelos jerárquicos, resulta muy importante distinguir las habilidades según las acciones realizadas. Esto ayuda a diversificar el comportamiento del modelo y facilita al planificador la selección de la habilidad correspondiente en una determinada condición del entorno.
2.3. Entrenamiento de la función de coste
A continuación, comenzaremos el análisis de la función de coste. Se espera que el modelo entrenado sea capaz de predecir los posibles rendimientos tras analizar las actuales condiciones del entorno. Se trata esencialmente de una estimación del estado futuro en RL clásico, que estudiamos de una forma u otra en casi todos los modelos. Solo que los autores del método proponen analizarlo sin el factor de descuento.
Yo, en cambio, he decidido experimentar con la estimación del coste no hasta el final del episodio, sino solo a lo largo de un pequeño horizonte de planificación. Mi lógica es que no planeamos abrir una posición y mantenerla "hasta el fin de los tiempos". En un mercado estocástico, dichas previsiones a largo plazo tienen una probabilidad demasiado baja. Por lo demás, el planteamiento ha seguido siendo bastante reconocible. Nuevamente, no he complicado demasiado el modelo. La arquitectura del modelo será la siguiente.
Suministramos una pequeña cantidad de datos históricos de la descripción del entorno en la entrada del modelo. En este modelo solo evaluaremos la situación del mercado para estimar el potencial principal posible. Tenga en cuenta que en este caso no nos interesan las tendencias, solo estamos destacando la intensidad del mercado. Y como estamos utilizando los datos de origen, en el caso presente, usaremos una capa de normalización por lotes en este modelo.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
Los datos normalizados se procesan con una capa de convolución respecto a las velas, lo que permite identificar patrones subyacentes.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = ValueBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; }
A continuación, los datos son procesados por el bloque de capas completamente conectadas y el resultado se muestra como un vector de recompensa descompuesta.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
Para entrenar la función de valor, crearemos el asesor "...\CT\StudyValue.mq5". Aquí también nos centraremos en el método de entrenamiento del modelo Train. Para entrenar dicho modelo, necesitaremos ya una muestra de entrenamiento. Por ello, en el cuerpo del ciclo de entrenamiento, muestreamos la trayectoria y el estado.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); int check = 0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 * ValueBars)); if(i < 0) { iter--; continue; check++; if(check >= total_tr) break; }
Tenga en cuenta que al muestrear una trayectoria, estamos reduciendo el rango de estados posibles en la magnitud doble de ValueBars. Esto se debe a que en el búfer de reproducción de experiencias, cada estado contiene solo la última barra (esto está relacionado con el uso de la arquitectura GPT en DT), y necesitaremos múltiples barras de datos históricos para evaluar el potencial. Y el segundo punto, de la recompensa total acumulada hasta el final del episodio, retiraremos la recompensa más allá del horizonte de planificación.
A continuación, rellenamos el búfer de datos de origen.
check = 0; //--- History data State.AssignArray(Buffer[tr].States[i].state); for(int state = 1; state < ValueBars; state++) State.AddArray(Buffer[tr].States[i + state].state);
Y ejecutaremos un pasada directa del modelo.
//--- Study if(!Value.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
A continuación, debemos preparar los datos objetivo para entrenar el modelo. Así, tomamos la recompensa acumulada en el momento de la estimación del estado del búfer de reproducción de experiencias y restamos la recompensa acumulada fuera del horizonte de planificación. Después, cargamos los resultados de la pasada directa del modelo y usamos el método CAGrad para ajustar el vector de valores objetivo.
vector<float> target, result; target.Assign(Buffer[tr].States[i + ValueBars - 1].rewards); result.Assign(Buffer[tr].States[i + 2 * ValueBars - 1].rewards); target = target - result*MathPow(DiscFactor,ValueBars); Value.getResults(result); Result.AssignArray(CAGrad(target - result) + result);
El vector preparado de valores objetivo lo transmitimos al modelo y realizamos una pasada inversa. No se olvide de controlar el proceso de ejecución de las operaciones.
if(!Value.backProp(Result, (CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
A continuación, informamos al usuario sobre el proceso de entrenamiento del modelo y pasamos a la siguiente iteración del ciclo de entrenamiento.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Value", iter * 100.0 / (double)(Iterations), Value.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completadas con éxito todas las iteraciones del ciclo, eliminamos el campo de comentarios del gráfico del instrumento. Luego mostramos el resultado del entrenamiento del modelo en el registro. E iniciamos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Value", Value.getRecentAverageError()); ExpertRemove(); //--- }
El código completo del asesor, así como todos los programas usados en el artículo, se pueden encontrar en el archivo adjunto.
2.4. Entrenamiento del planificador
Vamos a pasar a la siguiente etapa de nuestro trabajo: la creación del Planificador de nuestro modelo jerárquico. En este caso, el Decision Transformer actúa como un planificador que analizará la secuencia de estados visitados y las acciones realizadas en ellos, mientras que en la salida del planificador, esperamos tener una habilidad que utilizará nuestro modelo de política local para generar acciones.
Comenzaremos por la arquitectura del modelo. Como entrada, usamos un vector de descripción del estado en nuestra trayectoria que incluya toda la información posible. Debemos decir que los datos se suministran sin procesar, por lo que utilizamos una capa de normalización por lotes para preprocesar los datos.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Además, los datos del vector de datos fuente proceden de distintas fuentes. Como consecuencia, poseen diferente dimensionalidad y distribución. Luego aplicamos una capa de incorporación para facilitar su uso futuro y darles una forma comparable.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Los datos preparados pasan por el bloque de Transformador disperso.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
A continuación, reducimos la dimensionalidad de los datos mediante una capa de convolución.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Luego los datos pasan por un bloque de decisión de capas totalmente conectadas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
En la salida, reducimos la dimensionalidad los datos al número de habilidades utilizadas y normalizamos sus probabilidades con la función SoftMax.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = WorkerInput; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Tras revisar la arquitectura del modelo, comenzaremos a construir el asesor de entrenamiento del Planificador "...\CT\Study.mq5". Por tradición, nos centraremos únicamente en el método de entrenamiento del modelo Train.
Hay que decir aquí que el enfoque de la formación de DT no ha cambiado mucho. En el modelo, construimos las dependencias entre las entradas (incluyendo RTGs) y la acción realizada por el Agente. No obstante, hay ciertos matices relacionados con los principios de construcción del algoritmo considerado:
- El RTG no debe ser para el resto del episodio, sino solo para el horizonte de planificación;
- La salida del DT constituye la habilidad, no la acción. Asimismo, utilizamos un modelo de política local para transmitir el gradiente de error.
Todos estos matices se reflejan en el proceso de entrenamiento del modelo.
En el cuerpo del método Train, al igual que antes, organizamos un sistema de ciclos de entrenamiento del modelo. En el cuerpo del ciclo externo, muestreamos la trayectoria y el estado inicial para entrenar el modelo,
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float err=0; int err_count=0; //--- bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars-ValueBars,MathMin(Buffer[tr].Total,20+ValueBars))); if(i < 0) { iter--; continue; }
mientras que el proceso de entrenamiento se realiza directamente en el cuerpo del ciclo anidado. Permítanme recordarles que debido a las peculiaridades de la arquitectura de GPT en el proceso de entrenamiento tenemos que utilizar los datos históricos en estricta conformidad con su llegada.
Luego cargamos secuencialmente los movimientos históricos de los precios y los indicadores en el búfer de datos de origen.
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - 2 - ValueBars,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Datos sobre el estado de la cuenta.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
La marca temporal y la última acción del Agente.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
A continuación debemos especificar el RTG. Y aquí es donde usaremos la recompensa real acumulada. Solo hay que corregirla previamente para el horizonte de planificación.
//--- Return-To-Go vector<float> rtg; rtg.Assign(Buffer[tr].States[state+1].rewards); Actions.Assign(Buffer[tr].States[state+ValueBars].rewards); rtg=rtg-Actions*MathPow(DiscFactor,ValueBars); State.AddArray(rtg);
Los datos recogidos de esta forma se introducen en la entrada del Planificador, y luego llamamos al método de pasada directa. Después transmitimos la habilidad predictiva resultante a la entrada del modelo de política local y realizamos su pasada directa para predecir la acción del Agente.
//--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat *)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
A continuación, comparamos la acción del Agente así predicha con la acción real del búfer de reproducción de experiencias que ha producido la recompensa dada en los datos de entrada. Para entrenar el modelo, debemos minimizar la desviación entre los 2 vectores de valores. Asimismo, suministramos el vector de acción objetivo a la salida del modelo de política local y realizamos una pasada inversa secuencial de ambos modelos.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Worker.getResults(rtg); if(err_count==0) err=rtg.Loss(Actions,LOSS_MSE); else err=(err*err_count + rtg.Loss(Actions,LOSS_MSE))/(err_count+1); if(err_count<1000) err_count++; Result.AssignArray(CAGrad(Actions - rtg) + rtg); if(!Worker.backProp(Result,NULL,NULL) || !Agent.backPropGradient((CBufferFloat *)NULL, (CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Cabe señalar que en este caso estamos usando un modelo de política local ya entrenado. Y durante la pasada inversa, solo actualizamos los parámetros del planificador. Para ello, debemos establecer la bandera de entrenamiento del modelo de política local en false (Worker.TrainMode(false)). En la implementación presentada, hicimos esto en el método de inicialización de asesor para no repetir la operación en cada iteración.
Después, solo debemos informar al usuario sobre el proceso de aprendizaje y pasar a la siguiente iteración del ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), err); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas todas las iteraciones del sistema de ciclos, repetiremos las operaciones de finalización del asesor, que ya hemos descrito dos veces anteriormente.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", err); ExpertRemove(); //--- }
Con esto concluye nuestro análisis de los algoritmos de entrenamiento de modelos. Podemos observar aquí que en este artículo, hemos creado 3 asesores de entrenamiento de modelos en lugar del utilizado anteriormente. Este enfoque nos permite paralelizar el proceso de entrenamiento del modelo. Como podemos ver, el asesor de entrenamiento de habilidades no necesita una muestra de entrenamiento, y podemos enseñar habilidades paralelamente al proceso de recogida de la muestra de entrenamiento. Y para entrenar al planificador y a la función de coste, utilizamos el búfer de reproducción de experiencias. No obstante, los procesos no se solapan y pueden ejecutarse en paralelo, incluso en máquinas diferentes.
2.5. Asesor de prueba de patrones
Una vez entrenados los modelos, debemos evaluar los resultados en la práctica. Obviamente, probaremos el modelo en el simulador de estrategias, pero necesitamos un asesor que combine todos los modelos mencionados en un único paquete de toma de decisiones. Implementaremos esta funcionalidad en el asesor "...\CT\Test.mq5". No vamos a repasar todos los métodos del asesor. Le propongo detenernos solo en la función OnTick, donde se organiza el algoritmo principal de la toma de decisiones.
Al principio del método comprobamos la aparición del evento de apertura de nueva barra. Como recordará, realizamos todas las operaciones comerciales en la apertura de una nueva barra. En este caso, además, solo analizamos las velas cerradas.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Aquí es también donde descargamos los datos históricos del servidor, de ser necesario.
A continuación, debemos rellenar los datos históricos de los búferes de datos de entrada para nuestros modelos. Aquí cabe señalar que el modelo de función de coste y el planificador utilizan diferentes estructuras de datos y profundidades de la historia distintas. En primer lugar, rellenamos el búfer con datos para la función de coste y hacemos una pasada directa por él.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars-1; b >=0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!Value.feedForward(GetPointer(bState), 1, false)) return;
A continuación, rellenamos el búfer con datos para el planificador. Tenga en cuenta que la secuencia de los datos deberá replicar completamente la secuencia de los datos al entrenar el modelo. Primero transferimos los datos históricos de los movimientos de los precios y las lecturas de los indicadores.
for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Y los complementamos con información sobre nuestra cuenta.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
A continuación viene la marca temporal y la última acción del Agente.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
Al final del búfer, añadimos el RTG. Tomaremos este valor del búfer de resultados de la función de coste.
//--- Return to go
Value.getResults(Result);
bState.AddArray(Result);
Una vez finalizado el proceso de preparación de datos, realizamos secuencialmente una pasada directa del Planificador y del modelo de política local. Al mismo tiempo, debemos asegurarnos de controlar el proceso de las operaciones.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !Worker.feedForward((CNet *)GetPointer(Agent), -1, (CBufferFloat *)NULL)) return;
Las acciones del Agente así pronosticadas se procesan y ejecutan en el entorno.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Worker.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Los resultados de la interacción con el entorno se guardan en el búfer de reproducción de experiencias para seguir ajustando el modelo.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Cabe señalar que los datos recogidos de este modo pueden usarse tanto para el ajuste fino del modelo como para su posterior perfeccionamiento durante el funcionamiento, lo cual nos permitirá adaptarlo constantemente a las cambiantes condiciones del entorno.
3. Simulación
Más arriba, hemos trabajado bastante en la creación de asesores para la recopilación de datos y el entrenamiento de modelos. Como ya hemos mencionado, hemos dividido todo el proceso en asesores independientes para poder realizar varias tareas en paralelo. Y en el primer paso ejecutamos el asesor de entrenamiento de habilidades "StudyWorker.mq5", que funciona de forma autónoma y no requiere muestra de entrenamiento. Al hacerlo, nosotros mismos estamos participando en el proceso de recogida de la muestra de entrenamiento.
Aquí debemos decir que el proceso de recogida de la muestra de entrenamiento durante el periodo histórico de los 7 primeros meses de 2023 nos ha llevado bastante tiempo. Nos hemos encontrado un problema: incluso con el pequeño horizonte de muestreo de las acciones del Agente, la mayoría de las pasadas no han cumplido el requisito de balance positivo.
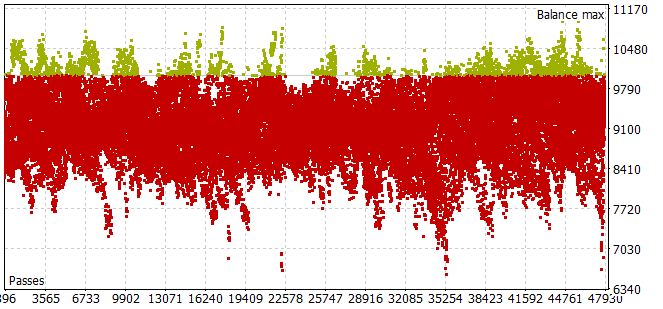
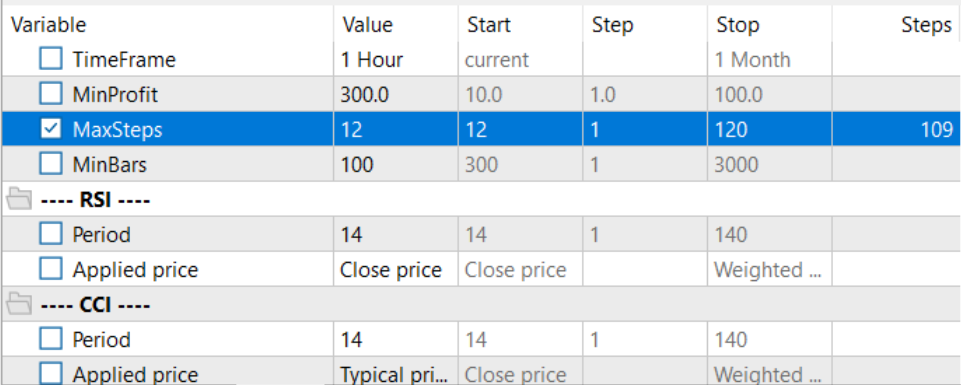
Para seleccionar el horizonte de planificación óptimo en el modo de optimización, el número de iteraciones por pasada se ha tomado de los parámetros optimizados.
Tras recoger la muestra de entrenamiento y entrenar el modelo de política local, hemos ejecutado en paralelo el entrenamiento del planificador y el modelo de función de coste. Este enfoque nos ha permitido reducir considerablemente el tiempo de entrenamiento de los modelos.
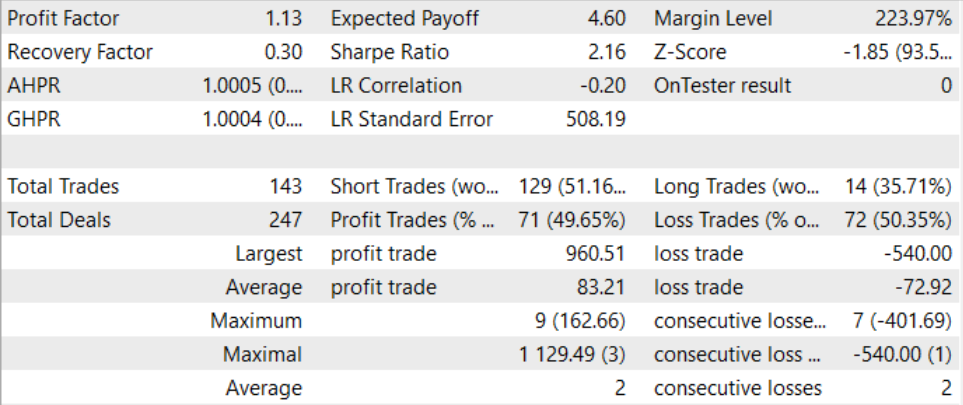
Tras un proceso de entrenamiento largo y bastante complejo, hemos logrado obtener un modelo capaz de generar beneficios fuera de la muestra de entrenamiento. El modelo entrenado se ha puesto a prueba con los datos históricos de agosto de 2023. Y según los resultados de la prueba, el factor de beneficio ha sido de 1,13. Debo decir que la proporción entre posiciones rentables y perdedoras es cercana a 1:1. Y todos los beneficios se obtienen porque la operación media rentable es superior a la pérdida media.
Conclusión
En este artículo, nos hemos familiarizado con el método del Control Transformer, que presenta una arquitectura innovadora para el entrenamiento de estrategias de control en entornos complejos y dinámicamente cambiantes. El Control Transformer combina las técnicas más avanzadas de aprendizaje por refuerzo, programación y aprendizaje automático para crear estrategias de control flexibles y adaptables.
El Control Transformer abre nuevas perspectivas para el desarrollo de diversos sistemas autónomos y robots. Su capacidad para adaptarse a diversos entornos, acomodarse a condiciones dinámicas y aprender offline lo convierte en una poderosa herramienta para construir sistemas inteligentes y autónomos capaces de resolver complejos problemas de control y navegación.
En la parte práctica del artículo, hemos implementado nuestra visión del método presentado usando MQL5. En esta implementación, hemos usado un enfoque novedoso consistente en dividir el proceso de entrenamiento del modelo en asesores independientes no relacionados entre sí, lo cual permite realizar varias tareas en paralelo. Esto puede reducir significativamente el tiempo total de entrenamiento de los modelos.
Mediante un proceso de entrenamiento y prueba del modelo, hemos podido crear un modelo capaz de generar beneficios. Esto nos permite hablar de la eficacia del planteamiento considerado y de la posibilidad de usar este para construir soluciones comerciales.
Una vez más, le recuerdo que todos los programas presentados en este artículo son informativos y tienen por objeto exclusivo demostrar el algoritmo presentado. No están preparados para ser utilizados en condiciones reales de mercado.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Faza1.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del Planificador |
| 3 | StudyWorker.mq5 | Asesor | Asesor de entrenamiento del modelo de política local |
| 4 | StudyValue.mq5 | Asesor | Asesor de entrenamiento de la función de coste |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13674
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso