
OpenCL : Le Pont vers les Mondes Parallèles

Introduction
Cet article est le premier d'une courte série de publications sur la programmation en OpenCL, ou Open Computing Language. La plateforme MetaTrader 5 dans sa forme actuelle, avant de prendre en charge OpenCL, ne permettait pas directement, c'est-à-dire de nativement d'utiliser et de profiter des avantages des processeurs multi-noyaux pour accélérer les calculs.
Évidemment, les développeurs pourraient répéter sans cesse que le terminal est multithreadet que "chaque EA/ script s'exécute dans un thread séparé", mais le codeur n'a pas eu la possibilité d'exécuter facilement et en parallèle relativement la boucle simple suivante (il s'agit d'un code pour calculer la valeur pi = 3.14159265...) :
long num_steps = 1000000000; double step = 1.0 / num_steps; double x, pi, sum = 0.0; for (long i = 0; i<num_steps; i++) { x = (i + 0.5)*step; sum += 4.0/(1.0 + x*x); } pi = sum*step;
Cependant, il y a 18 mois, une important œuvre intitulée "Calculs Parallèles MetaTrader 5" est apparue dans la section "Articles". Et pourtant... nous avons l'impression que malgré l'ingéniosité de l'approche, elle est quelque peu contre nature - toute une hiérarchie de programme (l'Expert Advisor et deux indicateurs) écrite pour accélérer les calculs dans la boucle ci-dessus aurait été trop bonne chose.
Nous savons déjà qu’il n’y apas de plans de prendre en charge OpenMP et sommes conscients du fait queajouter OMP exige une reprogrammation drastique du compilateur. Hélas, il n'y aura pas de solution simple et bon marché pour un codeur où aucune réflexion n'est requise.
L’annoncede prise en charge d’ OpenCL en МQL5 était, donc, une bonne nouvelle. A partir de la page 22 du même fil d’informations, MetaDriver commença la publication de scripts permettant d’évaluer le différence entre l’implémentation CPU et GPU. OpenCL a suscité un vif intérêt.
L'auteur de cet article s'est d'abord retiré du processus : une configuration informatique assez bas de gamme (Pentium G840/8 Go DDR-III 1333/Pas de carte vidéo) ne semblait pas permettre une utilisation efficace d'OpenCL.
Cependant, suite à l'installation d'AMD APP SDK, un logiciel spécialisé élaboré par AMD, le premier script proposé parMetaDriverqui avait été exécuté par d'autres uniquement si une carte vidéo distincte était disponible, a été exécuté avec succès sur l'ordinateur de l'auteur et a démontré une augmentation de la vitesse ce qui était loin d'être négligeable par rapport à un script d'exécution standard sur un noyau de processeur, étant environ 25 fois plus rapide. Plus tard, l'accélération du même script d'exécution a atteint 75, en raison de l'installation réussie d'Intel OpenCL Runtime avec l'aide de l'équipe de support.
Après avoir soigneusement étudié le forum et les documents fournis par ixbt.com, l'auteur a découvert que le processeur graphique intégré (IGP) d'Intel prend en charge OpenCL 1.1, en commençant uniquement par les processeurs Ivy Bridge et plus. Par conséquent, l'accélération atteinte sur le PC avec la configuration ci-dessus ne pouvait rien à voir avec IGP et le code du programme OpenCL dans ce cas particulier n'était exécuté que sur le processeur х86 core CPU.
Lorsque l'auteur a partagé les chiffres d'accélération avec des experts ixbt, ils ont instantanément répondu et d'un seul coup que tout cela était le résultat d'une sous-optimisation substantielle de la langue source (MQL5). Dans la communauté des professionnels d'OpenCL, il est de notoriété publique qu'une optimisation correcte d'un code source en ++ (bien entendu, sous réserve de l'utilisation d'un processeur multi-noyau et d'instructions vectorielles SSEx) peut au mieux se traduire par un gain de plusieurs dizaines de pour cent sur l'émulation OpenCL ; dans le pire des cas, vous pouvez même perdre, par exemple en raison d'une dépense (de temps) extrêmement élevée lors de la transmission de données.
Par conséquent, une autre hypothèse : les chiffres d'accélération « miraculeux » dans MetaTrader 5 sur une émulation OpenCL pure devraient être traités de manière adéquate sans être attribués à la « fraîcheur » d'OpenCL lui-même. Un avantage vraiment fort du GPU par rapport à un programme bien optimisé dans С++ ne peut être obtenu qu'en utilisant une carte vidéo discrète assez puissante, car ses capacités de calcul dans certains algorithmes sont bien au-delà des capacités de n'importe quel processeur moderne.
Les développeurs du terminal précisent qu'il n'a pas encore été correctement optimisé. Ils ont également laissé tomber un indice sur le degré d'accélération qui sera plusieurs fois supérieur à la suite de l'optimisation. Tous les chiffres d'accélération dans OpenCL seront en conséquence réduits par les mêmes "plusieurs fois". Cependant, ils seront toujours considérablement supérieurs à l'unité.
C'est une bonne raison d'apprendre le langage OpenCL (même si votre carte vidéo ne prend pas en charge OpenCL 1.1 ou est tout simplement manquante) avec laquelle nous allons procéder. Mais permettez-moi d'abord de dire quelques mots sur la base essentielle - un logiciel prenant en charge Open CL et le matériel approprié.
1. Logiciels et Matériel de Base
1.1.AMD
Le logiciel approprié est produit par AMD, Intel and NVidia,le membres d’un consortium industriel non-lucratif - le groupe Khronos élabore différentes spécifications de langage en rapport avec les calculs dans des environnements hétérogènes.
Certains documents utiles peuvent être trouvés sur le site officiel du groupe Khronos, par exemple :
Ces documents devront être utilisés assez souvent dans le processus d'apprentissage d'OpenCL car le terminal n'offre pas encore d'informations d'aide sur OpenCL (il n'y a qu'un bref résumé de l'API OpenCL). Toutes les trois sociétés (AMD, Intel et NVidia) sont des fournisseurs de matériel vidéo et chacune d'entre elles a sa propre implémentation OpenCL Runtime et ses kits de développement logiciel respectifs - SDK. Entrons dans les spécificités du choix des cartes vidéo, en prenant comme exemple les produits AMD.
Si votre carte vidéo AMD n'est pas très ancienne (mise en production pour la première fois en 2009-2010 ou plus tard), ce sera assez simple - une mise à jour du pilote de votre carte vidéo devrait suffire pour vous mettre immédiatement au travail. Une liste de cartes vidéo OpenCL compatibles peut être disponibleici. En revanche, même une carte vidéo plutôt bonne pour l'époque, comme une Radeon HD 4850 (4870), ne vous évitera pas la peine d'avoir affaire à OpenCL.
Si vous n'avez pas encore de carte vidéo AMD mais que vous souhaitez en acheter, jetez d'abord un coup d'œil à ses spécifications. Ici vous pouvez visionner un tableau assez complet de cartes vidéo AMD modernes de spécification. Les plus importants pour nous sont les suivants :
- Mémoire embarquée — le volume de mémoire locale Plus c'est grand, mieux c'est. 1 Go serait généralement suffisant.
- .Horloge de base — .Fréquence de fonctionnement du noyau Il est également clair : plus la fréquence de fonctionnement des multiprocesseurs GPU est élevée, mieux c'est. 650-700 MHz c'est pas mal du tout.
- [Memory] Type — Type de mémoire vidéo. La mémoire doit idéalement être rapide, c'est-à-dire GDDR5. Mais la GDDR3 conviendrait également, bien qu'environ deux fois moins bonne en termes de bande passante mémoire.
- [Memory] Clock (Eff.) - Fréquence de fonctionnement (effective) de mémoire vidéo. Techniquement, ce paramètre est étroitement lié au précédent. La fréquence effective de fonctionnement de la GDDR5 est en moyenne deux fois plus élevée que la fréquence de la GDDR3. Cela n'a rien à voir avec le fait que les types de mémoire "plus élevés" fonctionnent sur des fréquences plus élevées, mais est dû au nombre de canaux de transfert de données utilisés par la mémoire. En d'autres termes, il s'agit de la bande passante mémoire.
- [Mémoire] Bus - largeur des données du bus. Il est conseillé d'être d'au moins 256 bits.
- MBW — Bande passante mémoire. Ce paramètre est en fait une combinaison des trois paramètres de mémoire vidéo ci-dessus. Plus il est haut, mieux c'est.
- Config Core (SPU:TMU(TF):ROP) — configuration des unités centrales GPU. Ce qui est important pour nous, c'est-à-dire pour les calculs non graphiques, c'est le premier nombre. 1024:64:32 exprimé indiquerait que nous avons besoin du numéro 1024 (le nombre de processeurs ou de shaders de streaming unifiés). Évidemment, plus il est élevé, mieux c'est.
- Puissance de traitement — performances théoriques dans les calculs en virgule flottante (FP32 (Single Precision) / FP64 (Double Precision). Alors que les tableaux de spécifications comportent toujours une valeur correspondant à FP32 (toutes les cartes vidéo peuvent gérer des calculs en simple précision), c'est loin d'être le cas avec FP64 puisque la double précision n'est pas prise en charge par toutes les cartes vidéo. Si vous êtes sûr de ne jamais avoir besoin de double précision (double type) dans les calculs GPU, vous pouvez ignorer le deuxième paramètre. Mais quel que soit le cas, plus ce paramètre est élevé, mieux c'est.
- TDP — Puissance de Conception Thermique. C'est en gros, la puissance maximale que la carte vidéo dissipe dans les calculs les plus difficiles. Si votre Expert Advisor accède fréquemment au GPU, la carte vidéo non seulement consommera beaucoup d'énergie (ce qui n'est pas mal si cela rapporte) mais sera également assez bruyante.
Maintenant, le deuxième cas : il n'y a pas de carte vidéo ou la carte vidéo existante ne prend pas en charge OpenCL 1.1 mais vous avez un processeur AMD. Icivous pouvez télécharger AMD APP SDK qui à part de temps d’exécution ,comporte également SDK, Kernel Analyzer and Profiler. Après l'installation d'AMD APP SDK, le processeur doit être reconnu comme un périphérique OpenCL. Et vous pourrez élaborer des applications OpenCL complètes en mode émulation sur CPU.
La principale caractéristique du SDK, par opposition à AMD, est qu'il est également compatible avec les processeurs Intel (bien que lors du développement sur un processeur Intel, le SDK natif est encore nettement plus efficace car il est capable de prendre en charge le SSE4.1, SSE4.2 et jeux d'instructions AVX qui ne sont disponibles que récemment sur les processeurs AMD).
1.2. Intel
Avant de se mettre au travail sur les processeurs Intel, il est souhaitable de téléchargerIntel OpenCL SDK/Runtime.
Nous devons signaler les points suivants :
- Si vous avez l'intention d’élaborer des applications OpenCL uniquement à l'aide du processeur (mode d'émulation OpenCL), vous devez savoir que le noyau graphique du processeur Intel ne prend pas en charge OpenCL 1.1 pour les processeurs antérieurs à Sandy Bridge inclus. Cette prise en charge n'est disponible qu'avec les processeurs Ivy Bridge mais cela ne fera guère de différence même pour l'unité graphique intégrée ultra puissante Intel HD 4000. Pour les processeurs plus anciens qu'Ivy Bridge, cela indiquerait que l'accélération obtenue dans l'environnement MQL5 est uniquement due aux instructions vectorielles SS(S)Ex utilisées. Pourtant, il semble également important.
- Après l’installation d’ Intel OpenCL SDK,l’entrée registre HKEY_LOCAL_MACHINE\SOFTWARE\Khronos\OpenCL\Vendors doit être modifiée comme suit: remplacez IntelOpenCL64.dlldans la colonne Nom intelocl.dll Ensuite, redémarrez et démarrez MetaTrader 5. La CPU est maintenant reconnue comme un périphérique OpenCL 1.1.
Pour être tout à fait honnête, le problème concernant la prise en charge OpenCL d'Intel n'a pas encore été entièrement résolu, nous devons donc nous attendre à des éclaircissements de la part des développeurs du terminal à l'avenir. Fondamentalement, le fait est que personne ne va surveiller les erreurs de code du noyau (le noyau OpenCL est un programme exécuté sur GPU) pour vous - ce n'est pas le compilateur MQL5. Le compilateur prendra simplement une grande ligne entière du noyau et tentera de l'exécuter. Si, par exemple, vous n'avez pas déclaré une variable interneх utilisée dans le noyau, le noyau sera quand même techniquement exécuté, bien qu'avec des erreurs.
Cependant toutes les erreurs que vous aurez dans le terminal tombent à moins d’une douzaine de celles décrites dans l’Aide surAPI OpenCL pour les fonctionsCLKernelCreate() and CLProgramCreate(). La syntaxe du langage est très similaire à celle du C, enrichie de fonctions vectorielles et de types de données (en fait, ce langage est le C99 qui a été adopté comme norme ANSI С en 1999).
C'est le compilateur hors ligne Intel OpenCL SDK que l'auteur de cet article utilise pour déboguer le code pour OpenCL ; c'est beaucoup plus pratique que de rechercher aveuglément les erreurs du noyau dans MetaEditor. Espérons qu'à l'avenir, la situation s'améliorera.
1.3. NVidia
Malheureusement, l'auteur n'a pas cherché d'informations à ce sujet. Les recommandations générales restent néanmoins les mêmes. Les pilotes des nouvelles cartes vidéo NVidia prennent automatiquement en charge OpenCL.
Fondamentalement, l'auteur de l'article n'a rien contre les cartes vidéo NVidia mais la conclusion tirée sur la base des connaissances acquises lors de la recherche d'informations et des discussions sur le forum est la suivante : pour les calculs non graphiques, les cartes vidéo AMD semblent être plus optimales en termes de rapport qualité/prix que les cartes vidéo NVidia.
Passons maintenant à la programmation.
2. Le Premier Programme MQL5 Utilisant OpenCL
Pour pouvoir élaborer notre premier programme très simple, nous devons définir la tâche en tant que telle. Il doit être devenu de coutume dans les cours de programmation parallèle d'utiliser le calcul de la valeur pi qui est approximativement égale à 3,14159265 comme exemple.
À cette fin, la formule suivante est utilisée (l'auteur n'a jamais rencontré cette formule particulière auparavant mais cela semble être vrai):

Nous voulons calculer la valeur avec une précision de 12 décimales. Fondamentalement, une telle précision peut être obtenue avec environ 1 million d'itérations mais ce nombre ne nous permettra pas d'évaluer l'intérêt des calculs en OpenCL car la durée des calculs sur GPU devient trop courte.
Les cours de programmation GPGPU suggèrent de sélectionner le volume de calculs de sorte que la durée de la tâche GPU soit d'au moins 20 millisecondes. Dans notre cas, cette limite devrait être plus élevée en raison d'une erreur importante de la fonction GetTickCount() comparable à 100 ms.
Ci-dessous se trouve le programme MQL5 où ce calcul est implémenté :
//+------------------------------------------------------------------+ //| pi.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" long _num_steps = 1000000000; long _divisor = 40000; double _step = 1.0 / _num_steps; long _intrnCnt = _num_steps / _divisor; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { uint start,stop; double x,pi,sum=0.0; start=GetTickCount(); //--- first option - direct calculation for(long i=0; i<_num_steps; i++) { x=(i+0.5)*_step; sum+=4.0/(1.+x*x); } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); //--- calculate using the second option start=GetTickCount(); sum=0.; long divisor=40000; long internalCnt=_num_steps/divisor; double partsum=0.; for(long i=0; i<divisor; i++) { partsum=0.; for(long j=i*internalCnt; j<(i+1)*internalCnt; j++) { x=(j+0.5)*_step; partsum+=4.0/(1.+x*x); } sum+=partsum; } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); Print("_______________________________________________"); return(0); } //+------------------------------------------------------------------+Après avoir compilé et exécuté ce script, nous obtenons :
2012.05.03 02:02:23 pi (EURUSD,H1) The time to calculate PI was 8.783 seconds 2012.05.03 02:02:23 pi (EURUSD,H1) The value of PI is 3.141592653590 2012.05.03 02:02:15 pi (EURUSD,H1) The time to calculate PI was 7.940 seconds 2012.05.03 02:02:15 pi (EURUSD,H1) The value of PI is 3.141592653590
La valeur pi ~ 3.14159265 est calculée de deux manières légèrement différentes.
La première peut presque être considérée comme une méthode classique de démonstration des capacités des bibliothèques multi-threads comme OpenMP, Intel TPP, Intel MKL et autres.
La seconde est le même calcul sous la forme d'une double boucle. L'ensemble du calcul composé de 1 milliard d'itérations est décomposé en larges blocs de la boucle externe (il y en a 40 000 là-bas) où chaque bloc exécute 25 000 itérations "de base" constituant la boucle interne.
Vous pouvez constater que ce calcul est un peu plus lent, de 10 à 15 %. Mais c'est ce calcul particulier que nous allons utiliser comme base lors de la conversion vers OpenCL. La raison principale est la sélection du noyau (la tâche de calcul de base exécutée sur GPU) qui réaliserait un compromis raisonnable entre le temps passé à transférer des données d'une zone de mémoire à une autre et les calculs en tant que tels exécutés dans le noyau. Ainsi, au regard de la tâche courante, le noyau sera, en gros, la boucle interne du deuxième algorithme de calcul.
Calculons maintenant la valeur en utilisant OpenCL. Un code de programme complet sera suivi de courts commentaires sur les fonctions caractéristiques du langage hôte (MQL5) se liant à OpenCL. Mais d'abord, je voudrais souligner quelques points liés aux "obstacles" typiques qui pourraient interférer avec le codage dans OpenCL :
- Le noyau ne voit pas les variables déclarées en dehors du noyau. C'est pourquoi les variables globales _step et _intrnCnt ont dû être à nouveau déclarées au début du code du noyau (voir ci-dessous). Et leurs valeurs respectives devaient être transformées en chaînes pour être correctement lues dans le code du noyau. Cependant, cette spécificité de la programmation en OpenCL s'est avérée très utile par la suite, par exemple lors de la création de types de données vectorielles qui sont nativement absents de C.
- Tentez de donner autant de calculs au noyau que possible tout en gardant leur nombre raisonnable. Ce n'est pas très critique pour ce code car le noyau n'est pas très rapide dans ce code sur le matériel existant. Mais ce facteur vous aidera à accélérer les calculs si une puissante carte vidéo discrète est utilisée.
Voici donc le code du script avec le noyau OpenCL :
//+------------------------------------------------------------------+ //| OCL_pi_float.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs; input int _device=0; /// OpenCL device number (0, I have CPU) #define _num_steps 1000000000 #define _divisor 40000 #define _step 1.0 / _num_steps #define _intrnCnt _num_steps / _divisor string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(int arg) { return IntegerToString(arg); } const string clSrc= "#define _step "+d2s(_step,12)+" \r\n" "#define _intrnCnt "+i2s(_intrnCnt)+" \r\n" " \r\n" "__kernel void pi( __global float *out ) \r\n" // type float "{ \r\n" " int i = get_global_id( 0 ); \r\n" " float partsum = 0.0; \r\n" // type float " float x = 0.0; \r\n" // type float " long from = i * _intrnCnt; \r\n" " long to = from + _intrnCnt; \r\n" " for( long j = from; j < to; j ++ ) \r\n" " { \r\n" " x = ( j + 0.5 ) * _step; \r\n" " partsum += 4.0 / ( 1. + x * x ); \r\n" " } \r\n" " out[ i ] = partsum; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { Print("FLOAT: _step = "+d2s(_step,12)+"; _intrnCnt = "+i2s(_intrnCnt)); int clCtx=CLContextCreate(_device); int clPrg = CLProgramCreate( clCtx, clSrc ); int clKrn = CLKernelCreate( clPrg, "pi" ); uint st=GetTickCount(); int clMem=CLBufferCreate(clCtx,_divisor*sizeof(float),CL_MEM_READ_WRITE); // type float CLSetKernelArgMem(clKrn,0,clMem); const uint offs[ 1 ] = { 0 }; const uint works[ 1 ] = { _divisor }; bool ex=CLExecute(clKrn,1,offs,works); //--- Print( "CL program executed: " + ex ); float buf[]; // type float ArrayResize(buf,_divisor); uint read=CLBufferRead(clMem,buf); Print("read = "+i2s(read)+" elements"); float sum=0.0; // type float for(int cnt=0; cnt<_divisor; cnt++) sum+=buf[cnt]; float pi=float(sum*_step); // type float Print("pi = "+d2s(pi,12)); CLBufferFree(clMem); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); double gone=(GetTickCount()-st)/1000.; Print("OpenCl: gone = "+d2s(gone,3)+" sec."); Print("________________________"); return(0); } //+------------------------------------------------------------------+
Une explication plus détaillée du code du script sera fournie un peu plus tard.
En attendant, compilez et démarrez le programme pour obtenir les éléments suivants :
2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) ________________________ 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) OpenCl: gone = 5.538 sec. 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) pi = 3.141622066498 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) read = 40000 elements 2012.05.03 02:20:15 OCl_pi_float (EURUSD,H1) FLOAT: _step = 0.000000001000; _intrnCnt = 25000
Comme nous pouvons le constater, le temps d'exécution a légèrement diminué. Mais cela ne suffit pas à nous faire plaisir : la valeur de pi ~ 3.14159265 n'est évidemment précise que jusqu'au 3ème chiffre après la virgule. Une telle rugosité des calculs est due au fait que dans les calculs réels, le noyau utilise des nombres de type flottant dont la précision est nettement inférieure à la précision requise à 12 décimales près.
Selon la Documentation MQL5, la précision d’un type de numéro float est seulement fiable à 7 chiffres importants. Alors que la précision d'un numéro de type double est fiable à 15 chiffres importants.
Par conséquent, nous devons rendre le type de données réel "plus précis". Dans le code ci-dessus, les lignes où le type flottant doit être remplacé par un type double, sont marquées du commentaire ///type float. Après compilation en utilisant les mêmes données d'entrée, nous obtenons ce qui suit (nouveau fichier avec le code source - OCL_pi_double.mq5) :
2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) OpenCl: gone = 12.480 sec. 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.03 03:25:23 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Le temps d'exécution a considérablement augmenté et même dépassé le temps du code source sans OpenCL (8,783 s).
"C'est clairement le double type qui ralentit les calculs", penserions-nous. Pourtant, testons et modifions substantiellement le paramètre d'entrée _diviseur de 40000 à 40000000 :
2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) OpenCl: gone = 5.070 sec. 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) read = 40000000 elements 2012.05.03 03:26:50 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25
Cela n'a pas altéré la précision et la durée d'exécution est même légèrement plus courte que dans le cas du type flottant Mais si nous changeons simplement tous les types d'entiers de long à int et restaurons la valeur précédente de _diviseur = 40000, le temps d'exécution du noyau diminuera de plus de la moitié :
2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) OpenCl: gone = 2.262 sec. 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.16 00:22:44 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Vous devez toujours vous rappeler : s'il y a une boucle assez "longue" mais "légère" (c'est-à-dire une boucle composée de beaucoup d'itérations chacune n'a pas beaucoup d'arithmétique), une simple modification de type de données par rapport aux types "lourds" (type long - 8 octets) à "légers" (int - 4 octets) peuvent réduire considérablement le temps d'exécution du noyau.
Arrêtons maintenant nos expériences de programmation pendant un court instant et concentrons-nous sur la signification de l'ensemble de "fixation" du code du noyau pour comprendre ce que nous faisons. Nous entendons provisoirement par le code noyau«fixation»,nous entendons provisoirement OpenCL API, c’est-à-dire un système de commandes permettant au noyau de communiquer avec le programme hôte (dans ca cas, le programme en MQL5).
3. Fonctions API OpenCL
3.1. Créer un contexte
Une commande donnée ci-dessous créé un contexte, c’est-à-dire un environnement pour la gestion des objets et ressources.
int clCtx = CLContextCreate( _device ); Tout d'abord, quelques mots sur le modèle de plate-forme.
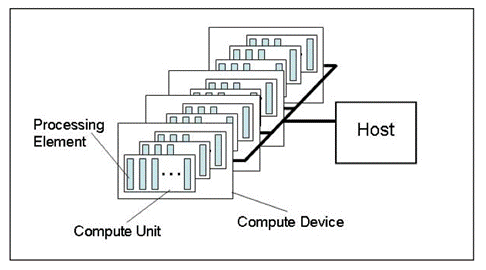
Fig. 1. Modèle abstrait d'une plate-forme informatique
La figure montre un modèle abstrait d'une plate-forme informatique. Ce n'est pas une description très détaillée de la structure du matériel par rapport aux cartes vidéo mais est assez proche de la réalité et donne une bonne idée générale.
L'hôte est le processeur principal contrôlant l'ensemble du processus d'exécution du programme. Il peut reconnaître quelques appareils OpenCL (Compute Devices). Dans la plupart des cas, lorsqu'un trader dispose d'une carte vidéo pour les calculs disponible dans l'unité centrale, une carte vidéo est considérée comme un périphérique (une carte vidéo à double processeur sera considérée comme deux appareils !). En plus de cela, l'hôte en soi, c'est-à-dire le CPU, est toujours considéré comme un périphérique OpenCL. Chaque appareil a son numéro unique au sein de la plate-forme.
Il existe plusieurs unités Compute dans chaque appareil qui dans ce cas avec des CPU correspondent aux х86 noyaux (y compris l’ Intel CPU "virtual" cores, i.e "noyaux" créés via Hyper-threading); pour une carte vidéo, ceux-ci seraient des engins SIMD c’est-à-dire des noyaux SIMD ou mini-processeurs dans les termes de l’articleGPU Computing. Caractéristiques architecturales AMD/ATI Radeon. Les cartes vidéo puissantes ont généralement environ 20 noyaux SIMD.
Chaque noyau SIMD comporte des processeurs de flux, par exemple la carte vidéo Radeon HD 5870 possède 16 processeurs de flux dans chaque moteur SIMD.
Enfin, chaque processeur de flux possède 4 ou 5 éléments de traitement, c'est-à-dire ALU, dans une même carte.
Il convient de noter que la terminologie utilisée par tous les principaux fournisseurs de graphiques pour le matériel est assez déroutante, notamment pour les débutants. Il n’est pas toujours évident de connaître le sens du mot «abeilles» largement utilisé dans le forum populairefil sur OpenCL Néanmoins, le nombre de fils, c'est-à-dire les fils de calculs simultanés, dans les cartes vidéo modernes est très grand. Par exemple, le nombre estimé de fils dans la carte vidéo Radeon HD 5870 est supérieur à 5 000.
La figure ci-dessous montre les spécifications techniques standard de cette carte vidéo.

Fig. 2. Fonctionnalités du GPU Radeon HD 5870
Tout ce qui est spécifié plus loin (ressources OpenCL) doit nécessairement être associé au contexte créé par la fonctionCLContextCreate() :
- appareils OpenCL, c'est-à-dire matériel utilisé dans les calculs ;
- Objets de programme, c'est-à-dire code de programme exécutant le noyau ;
- Les noyaux, c'est-à-dire les fonctions exécutées sur les appareils ;
- Objets mémoire, c'est-à-dire données (par exemple tampons, images 2D et 3D) manipulées par l'appareil ;
- Files d'attente de commandes (l'implémentation actuelle du langage de terminal ne fournit pas d'API respectif).
Le contexte créé peut être illustré sous la forme d'un champ vide avec des appareils qui lui sont attachés ci-dessous.
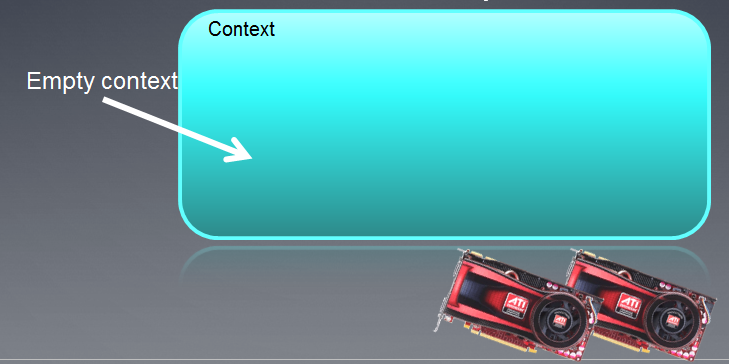
Fig. 3. Contexte OpenCL
Suite à l'exécution de la fonction, le champ de contexte est actuellement vide.
Il convient de noter que le contexte OpenCL dans MQL5 fonctionne avec un seul périphérique.
3.2. Création d'un programme
int clPrg = CLProgramCreate( clCtx, clSrc ); La fonctionCLProgramCreate()crée une ressource du "Programme OpenCL".
L'objet "Program" est en fait une collection de noyaux OpenCL (qui seront discutés dans le prochain article) mais dans l'implémentation de MetaQuotes, il ne peut apparemment y avoir qu'un seul noyau dans le programme OpenCL. Afin de créer l'objet "Program", vous devez vous assurer que le code source (ici - clSrc) est lu dans une chaîne.
Dans notre cas, ce n'est pas nécessaire car la chaîne clSrc a déjà été déclarée en tant que variable globale :

La figure ci-dessous montre que le programme fait partie du contexte précédemment créé.

Fig. 4. Le programme fait partie du contexte
Si le programme n'a pas réussi à compiler, le développeur doit lancer indépendamment une demande de données à la sortie du compilateur. Une API OpenCL entièrement opérationnelle dispose de la fonction API clGetProgramBuildInfo() après l'appel,quelle une chaîne est renvoyée à la sortie du compilateur.
La version actuelle (b.642) ne prend pas en charge cette fonction qui devrait probablement valoir la peine d'être comprise dans l'API OpenCL pour fournir à un développeur OpenCL plus d'informations sur l'exactitude du code du noyau.
Les "langues" provenant des appareils (cartes vidéo) sont des files d'attente de commandes qui ne seront apparemment pas prises en charge dans MQL5 au niveau de l'API.
3.3. Création d'un noyau
La fonction CLKernelCreate() crée une ressource OpenCL "Kernel".
int clKrn = CLKernelCreate( clPrg, "pi" );
Le noyau est une fonction déclarée dans le programme exécuté sur le périphérique OpenCL.
Dans notre cas, il s'agit de la fonction pi() nommée "pi". L'objet "noyau" est la fonction du noyau avec ses arguments respectifs. Le deuxième argument de cette fonction est le nom de la fonction qui doit correspondre exactement au nom de la fonction dans le programme.

Fig. 5. Noyau
Les objets "noyau" peuvent être utilisés autant de fois que nécessaire lors de la définition de différents arguments pour une même fonction déclarée comme noyau.
Nous devons passer aux fonctions CLSetKernelArg() etCLSetKernelArgMem()mais tout d’abord disons quelques mots sur les objets stockés dans la mémoire des appareils
3.4. Objets mémoire
Tout d'abord, il faut comprendre que tout "gros" objet traité sur GPU doit d'abord être créé dans la mémoire du GPU lui-même ou déplacé depuis la mémoire hôte (RAM). Par un "grand" objet, nous entendons soit un tampon (tableau à une dimension) soit une image qui peut être à deux ou trois dimensions (2D ou 3D).
Un tampon est une grande zone de mémoire contenant des éléments de tampon adjacents séparés. Il peut s'agir de types de données simples (char, double, float, long, etc.) ou de types de données complexes (structures, unions, etc.). Des éléments de tampon séparés sont accessibles directement, lus et écrits.
Nous n'allons pas examiner les images pour le moment car il s'agit d'un type de données particulier. Le code fourni par les développeurs du terminalsur la première page du fil sur OpenCLsuggère que les développeurs ne se sont pas engagés dans l’utilisation d’images.
Dans le code introduit, la fonction créant le tampon apparaît comme suit :
int clMem = CLBufferCreate( clCtx, _divisor * sizeof( double ), CL_MEM_READ_WRITE );
Le premier paramètre est un identificateur contextuel auquel le tampon OpenCL est associé en tant que ressource ; le deuxième paramètre est la mémoire allouée au tampon ; le troisième paramètre montre ce qui peut être fait avec cet objet. La valeur renvoyée est un identificateur vers le tampon OpenCL (si créé avec succès) ou -1 (si la création a échoué en raison d'une erreur).
Dans notre cas, le tampon a été directement créé dans la mémoire du GPU, c'est-à-dire du périphérique OpenCL. S'il a été créé dans la RAM sans utiliser cette fonction, il doit être déplacé vers la mémoire de l'appareil OpenCL (GPU) comme illustré ci-dessous :

Fig. 6. Objets mémoire OpenCL
Les tampons d'entrée/sortie (pas nécessairement des images - la Joconde est ici à des fins d'illustration seulement !) qui ne sont pas des objets mémoire OpenCL sont affichés sur la gauche. Les objets mémoire OpenCL vides et non initialisés sont affichés plus à droite, dans le champ de contexte principal. Les données initiales "la Joconde" seront ensuite déplacées dans le champ de contexte OpenCL et tout ce qui est généré par le programme OpenCL devra être déplacé vers la gauche, c'est-à-dire dans la RAM.
Les termes utilisés dans OpenCL pour copier des données depuis/dans un hôte/un périphérique OpenCL sont les suivants :
- La copie de données depuis l’hôte dans le périphérique mémoire est appelée fonction d’écriture (CLBufferWrite() );;
- La copie de données depuis le périphérique de mémoire dans la mémoire hôte est appeléefonction de lecture (CLBufferRead()voir ci-dessous).
La commande d'écriture (hôte -> appareil) initialise un objet mémoire par données et place en même temps l'objet dans la mémoire de l'appareil.
Gardez à l'esprit que la validité des objets mémoire disponibles dans l'appareil n'est pas indiquée dans la spécification OpenCL car elle dépend du fournisseur du matériel correspondant à l'appareil. Par conséquent, soyez prudent lors de la création d'objets mémoire.
Une fois que les objets mémoire ont été initialisés et écrits sur les appareils, l'image ressemble à ceci :

Fig. 7. Résultat de l'initialisation des objets mémoire OpenCL
Nous pouvons maintenant passer aux fonctions qui définissent les paramètres du noyau.
3.5. Définition des paramètres du noyau
CLSetKernelArgMem( clKrn, 0, clMem ); La fonctionCLSetKernelArgMem() définit le tampon crée précédemment comme paramètre zéro du noyau.
Si nous examinons maintenant le même paramètre dans le code du noyau, nous pouvons constater qu'il apparaît comme suit :
__kernel void pi( __global float *out )
Dans le noyau,c’est le tableau de sortie[ ] qui dispose du même type tel que créé par la fonction APICLBufferCreate().
Il existe une fonction similaire pour définir les paramètres hors tampon :
bool CLSetKernelArg( int kernel, // handle to the kernel of the OpenCL program uint arg_index, // OpenCL function argument number void arg_value ); // function argument value
Si, par exemple, nous décidions de définir un double x0 comme deuxième paramètre du noyau, il faudrait d'abord le déclarer et l'initialiser dans le programme MQL5 :
double x0 = -2;
et la fonction devra alors être appelée (également dans le code MQL5) :
CLSetKernelArg( cl_krn, 1, x0 ); Suite aux manipulations ci-dessus, l'image sera la suivante :

Fig. 8. Résultats de définition des paramètres du noyau
3.6. Exécution du programme
bool ex = CLExecute( clKrn, 1, offs, works );
L'auteur n'a pas trouvé d'analogue direct de cette fonction dans la spécification OpenCL. La fonction exécute le noyau clKrn avec les paramètres donnés. Le dernier paramètre « works » définit le nombre de tâches à exécuter pour chaque calcul de la tâche de calcul. La fonction démontre le principe SPMD (Single Program Multiple Data) : un appel de la fonction crée des instances de noyau avec leurs propres paramètres dans un nombre égal à la valeur du paramètre Works ; ces instances de noyau sont, de manière conventionnelle, exécutées simultanément mais sur des noyaux de flux différents, en termes AMD.
La généralité d'OpenCL réside dans le fait que le langage n'est pas lié à l'infrastructure matérielle sous-jacente impliquée dans l'exécution du code : le codeur n'a pas besoin de connaître les spécifications matérielles pour exécuter correctement un programme OpenCL. Il sera toujours exécuté. Pourtant il est fortement conseillé de connaître ces spécifications pour améliorer l'efficacité du code (par exemple la vitesse).
Par exemple, ce code s'exécute parfaitement sur le matériel de l'auteur dépourvu de carte vidéo discrète. Cela dit, l'auteur a une idée très vague de la structure du CPU elle-même où se déroule toute l'émulation.
Ainsi, le programme OpenCL a finalement été exécuté et nous pouvons maintenant utiliser ses résultats dans le programme hôte.
3.7. Lecture des données de sortie
Vous trouverez ci-dessous un fragment du programme hôte lisant les données de l'appareil :
float buf[ ]; ArrayResize( buf, _divisor ); uint read = CLBufferRead( clMem, buf );
N'oubliez pas que la lecture de données dans OpenCL copie ces données de l'appareil vers l'hôte. Ces trois lignes indiquent comment cela s’effectue. Il suffira de déclarer le buffer buf[] du même type que le buffer OpenCL lu dans le programme principal et d'appeler la fonction. Le type de tampon créé dans le programme hôte (ici - dans le langage MQL5) peut être différent du type de tampon dans le noyau mais leurs tailles doivent correctement correspondre.
Les données ont maintenant été copiées dans la mémoire hôte et sont entièrement disponibles pour nous dans le programme principal, c'est-à-dire le programme en MQL5.
Une fois que tous les calculs requis sur le périphérique OpenCL ont été effectués, la mémoire doit être libérée de tous les objets.
3.8. Destruction de tous les objets OpenCL
Cela se fait à l'aide des commandes suivantes :
CLBufferFree( clMem ); CLKernelFree( clKrn ); CLProgramFree( clPrg ); CLContextFree( clCtx );
La particularité principale de ces séries de fonctions est que les objets doivent être détruits dans l'ordre inverse de celui de leur création.
Voyons maintenant rapidement le code du noyau lui-même.
3.9. Noyau
Comme nous pouvons le constater, l'ensemble du code du noyau est une seule longue chaîne composée de plusieurs chaînes.
L'en-tête du noyau ressemble à une fonction standard :
__kernel void pi( __global float *out )
Il y a quelques exigences pour l'en-tête du noyau :
- Le type d'une valeur renvoyée est toujours nul ;
- Le spécificateur __kernel ne doit pas inclure deux caractères de soulignement ; il peut aussi s'agir du noyau ;
- Si un argument est un tableau (tampon), il n'est transmis que par référence. Le spécificateur de mémoire __global (ou global) indique que ce tampon est stocké dans la mémoire globale du périphérique.
- Les arguments de types de données simples sont transmis par valeur.
Le corps du noyau n'est en rien différent du code standard en C.
Important : la chaîne :
int i = get_global_id( 0 );
Indique que i est un nombre d'une cellule de calcul dans le GPU qui détermine le résultat du calcul dans cette cellule. Ce résultat est ensuite écrit dans le tableau de sortie (dans notre cas, out[]), après quoi ses valeurs sont additionnées dans le programme hôte après avoir lu le tableau de la mémoire GPU dans la mémoire CPU.
Il convient de noter qu'il peut y avoir plus d'une fonction dans le code du programme OpenCL. Par exemple, une simple fonction inline située à l'extérieur de la fonction pi() peut être appelée à l'intérieur de la fonction noyau "principale" pi(). Ce cas sera examiné plus tard.
Maintenant que nous nous sommes brièvement familiarisés avec l'API OpenCL dans l'implémentation de MetaQuotes, nous pouvons poursuivre l’expérimentation. Dans cet article, l'auteur n'a pas prévu d'entrer dans les détails du matériel qui permettrait d'optimiser au maximum le temps d'exécution. La tâche principale pour le moment est de fournir un point de départ pour la programmation en OpenCL en tant que tel.
En d'autres termes, le code est plutôt naïf car il ne prend pas en compte les spécifications matérielles. En même temps, il est assez général pour qu'il puisse être exécuté sur n'importe quel matériel - CPU, IGP par AMD (GPU intégré au CPU) ou une carte vidéo discrète par AMD / NVidia.
Avant d’envisager davantage optimisations naïves à l’aide deTypes de données vectorielles,nous devons en premier lieu nous familiariser avec elles.
4. Types de Données Vectorielles
Les types de données vectorielles sont les types spécifiques à OpenCL, ce qui le distingue de C99. Parmi ceux-ci se trouvent tous les types de (u)charN, (u)shortN, (u)intN, (u)longN, floatN, où N = {2|3|4|8|16}.
Ces types sont censés être utilisés lorsque nous savons (ou admettons) que le compilateur intégré parviendra à paralléliser les calculs en plus. Il faut noter ici que ce n'est pas toujours le cas, même si les codes noyau ne diffèrent que par la valeur de N et sont identiques à tous autres égards (l'auteur a pu le constater par lui-même).
Vous trouverez ci-dessous la liste detypes de donnéesintégrés:

Tableau 1. Types de données vectorielles intégrés dans OpenCL
Ces types sont pris en charge par n'importe quel appareil. Chacun de ces types dispose d’ un type correspondant d'API pour la communication entre le noyau et le programme hôte. Ce n'est pas prévu dans l'implémentation actuelle de MQL5 mais ce n'est pas grave.
Il existe également des types supplémentaires, mais ils doivent être explicitement indiqués pour être utilisés car ils ne sont pas pris en charge par tous les appareils :

Tableau 2. Autres types de données intégrés dans OpenCL
De plus, il existe des types de données réservés qui ne sont pas encore pris en charge dans OpenCL. Il y en a une assez longue liste dans la spécification du langage.
Pour déclarer une constante ou une variable de type vecteur, vous devez suivre des règles simples et intuitives.
Quelques exemples sont présentés ci-dessous :
float4 f = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f); uint4 u = ( uint4 ) ( 1 ); /// u is converted to a vector (1, 1, 1, 1). float4 f = ( float4 ) ( ( float2 )( 1.0f, 2.0f ), ( float2 )( 3.0f, 4.0f ) ); float4 f = ( float4 ) ( 1.0f, ( float2 )( 2.0f, 3.0f ), 4.0f ); float4 f = ( float4 ) ( 1.0f, 2.0f ); /// error
Comme vous pouvez le constater, il suffit de faire correspondre les types de données de droite, mis ensemble, avec la "largeur" de la variable déclarée de gauche (ici, elle est égale à 4). La seule exception est la conversion d'un scalaire en vecteur avec les composants égaux au scalaire (ligne 2).
Il existe un mécanisme simple d'adressage des composants vectoriels pour chaque type de données vectorielles. D'une part, ce sont des vecteurs (tableaux),d'autre part, ce sont des structures. Ainsi, par exemple, le premier composant des vecteurs de largeur 2 (par exemple, float2 u) peut être adressé comme ux et le second comme uy
Les trois composants pour un vecteur de type long3 u seront : ux, uy, uz
Pour un vecteur de type float4 u, ceux-ci seront donc .xyzw, ieux, uy, uz, uw
float2 pos; pos.x = 1.0f; // valid pos.z = 1.0f; // invalid because pos.z does not exist float3 pos; pos.z = 1.0f; // valid pos.w = 1.0f; // invalid because pos.w does not exist
Vous pouvez sélectionner plusieurs composants à la fois et même les permuter (notation de groupe) :
float4 c; c.xyzw = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); c.z = 1.0f; c.xy = ( float2 ) ( 3.0f, 4.0f ); c.xyz = ( float3 ) ( 3.0f, 4.0f, 5.0f ); float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 swiz= pos.wzyx; // swiz = ( 4.0f, 3.0f, 2.0f, 1.0f ) float4 dup = pos.xxyy; // dup = ( 1.0f, 1.0f, 2.0f, 2.0f )La notation de groupe de composants, c'est-à-dire la spécification de plusieurs composants, peut apparaître sur le côté gauche de l'instruction d'affectation (c'est-à-dire la valeur l) :
float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); pos.xw = ( float2 ) ( 5.0f, 6.0f ); // pos = ( 5.0f, 2.0f, 3.0f, 6.0f ) pos.wx = ( float2 ) ( 7.0f, 8.0f ); // pos = ( 8.0f, 2.0f, 3.0f, 7.0f ) pos.xyz = ( float3 ) ( 3.0f, 5.0f, 9.0f ); // pos = ( 3.0f, 5.0f, 9.0f, 4.0f ) pos.xx = ( float2 ) ( 3.0f, 4.0f ); // invalid as 'x' is used twice pos.xy = ( float4 ) (1.0f, 2.0f, 3.0f, 4.0f ); // mismatch between float2 and float4 float4 a, b, c, d; float16 x; x = ( float16 ) ( a, b, c, d ); x = ( float16 ) ( a.xxxx, b.xyz, c.xyz, d.xyz, a.yzw ); x = ( float16 ) ( a.xxxxxxx, b.xyz, c.xyz, d.xyz ); // invalid as the component a.xxxxxxx is not a valid vector type
Les composants individuels sont accessibles en utilisant une autre notation - la lettre s (ou S) qui est insérée avant un chiffre hexadécimal ou plusieurs chiffres dans une notation de groupe :

Tableau 3. Indices utilisés pour accéder aux composants individuels des types de données vectorielles
Si vous déclarez une variable vectorielle f
float8 f;alors f.s0 est la 1er composant du vecteur et f.s7 est le 8ème composant.
De même, si nous déclarons un vecteur à 16 dimensions x,
float16 x;alors x.sa (ou x.sA) est le 11eme composant du vecteur x et x.sf (ou x.sF) fait référence au 16e composant du vecteur x.
Les indices numériques (.s0123456789abcdef) et les notations de lettres (.xyzw) ne peuvent pas être mélangés dans le même identifiant avec la notation de groupe de composants :
float4 f, a; a = f.x12w; // invalid as numeric indices are intermixed with the letter notations .xyzw a.xyzw = f.s0123; // valid
Et enfin, il existe encore une autre façon de manipuler les composants de type vectoriel en utilisant .lo, .hi, .even, .odd.
Ces suffixes sont utilisés comme suit :
- .lo fait référence à la moitié inférieure d'un vecteur donné ;
- .hi fait référence à la moitié supérieure d'un vecteur donné ;
- .even fait référence à tous les composants pairs d'un vecteur ;
- .impair fait référence à tous les composants impairs d'un vecteur.
Par exemple :
float4 vf; float2 low = vf.lo; // vf.xy float2 high = vf.hi; // vf.zw float2 even = vf.even; // vf.xz float2 odd = vf.odd; // vf.yw
Cette notation peut être utilisée à plusieurs reprises jusqu'à ce qu'un scalaire (type de données non vectorielles) apparaisse.
float8 u = (float8) ( 1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f ); float2 s = u.lo.lo; // ( 1.0f, 2.0f ) float2 t = u.hi.lo; // ( 5.0f, 6.0f ) float2 q = u.even.lo; // ( 1.0f, 3.0f ) float r = u.odd.lo.hi; // 4.0f
La situation est un peu plus compliquée dans un type vectoriel à 3 composants : techniquement c'est un type vectoriel à 4 composants avec la valeur du 4ème composant indéfini..
float3 vf = (float3) (1.0f, 2.0f, 3.0f); float2 low = vf.lo; // ( 1.0f, 2.0f ); float2 high = vf.hi; // ( 3.0f, undefined );
Brèves règles d'arithmétique (+, -, *, /).
Toutes les opérations arithmétiques indiquées sont définies pour des vecteurs de même dimension et sont effectuées par composant.
float4 d = (float4) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 w = (float4) ( 5.0f, 8.0f, 10.0f, -1.0f ); float4 _sum = d + w; // ( 6.0f, 10.0f, 13.0f, 3.0f ) float4 _mul = d * w; // ( 5.0f, 16.0f, 30.0f, -4.0f ) float4 _div = w / d; // ( 5.0f, 4.0f, 3.333333f, -0.25f )
La seule exception est lorsque l'un des opérandes est un scalaire et l'autre est un vecteur. Dans ce cas, le type scalaire est converti en type de données déclaré dans le vecteur tandis que le scalaire lui-même est converti en un vecteur de même dimension que l'opérande vectoriel. Ceci est suivi d'une opération arithmétique. Il en est de même pour les opérateurs relationnels (<, >, <=, >=).
Les types de données natifs dérivés C99 (par exemple, struct, union, tableaux et autres) qui peuvent être constitués des types de données intégrés répertoriés dans le premier tableau de cette section sont également pris en charge dans le langage OpenCL.
Et la dernière chose : si vous souhaitez utiliser le GPU pour des calculs exacts, vous devrez forcément utiliser le type de données double et par conséquent doubleN.
Pour cela, il suffit d'insérer la ligne :
#pragma OPENCL EXTENSION cl_khr_fp64 : enable au début du code du noyau.
Cette information devrait déjà être suffisante pour comprendre une grande partie de ce qui suit. Si vous avez des questions, veuillez consulter la spécification OpenCL 1.1.
5. Implémentation du noyau avec des types de données vectorielles
Pour être tout à fait honnête, l'auteur n'a pas réussi à écrire un code fonctionnel avec des types de données vectorielles spontanément.
Au début, l'auteur n'a pas prêté beaucoup d'attention à la lecture de la spécification du langage pensant que tout s'arrangera tout seul dès qu'un type de données vectorielles, par exemple double8, sera déclaré dans le noyau. En plus, le tentative de l’auteur de déclarer uniquement un tableau de sortie en tant que tableau de vecteurs double 8 a également échoué.
Il a fallu du temps pour se rendre compte que ce n'est absolument pas suffisant pour vectoriser efficacement le noyau et obtenir une réelle accélération. Le problème ne sera pas résolu en faisant sortir les résultats dans le tableau vectoriel comme font les données n’exigeant pas uniquement d’être rapidement saisies et sorties mais rapidement calculées. La réalisation de ce fait a accéléré le processus et augmenté son efficacité permettant enfin de développer un code beaucoup plus rapide.
Mais il y a plus que cela. Alors que le code du noyau exposé ci-dessus pouvait être débogué presque aveuglement la recherche d'erreurs est maintenant devenue assez difficile en raison de l'utilisation de données vectorielles. Quelles informations constructives pouvons-nous obtenir de ce message standard :
ERR_OPENCL_INVALID_HANDLE - invalid handle to the OpenCL program
ou celui-ci
ERR_OPENCL_KERNEL_CREATE - internal error while creating an OpenCL object
?
Par conséquent, l'auteur a dû recourir au SDK. Dans ce cas, compte tenu de la configuration matérielle disponible pour l'auteur, il s'agissait du compilateur hors ligne Intel OpenCL SDK (32 bits) fourni dans Intel OpenCL SDK (pour les CPU/GPU autres qu'Intel, le SDK devrait également contenir les compilateurs hors ligne pertinents). C'est pratique car cela permet de déboguer le code du noyau sans se lier à l'API hôte.
Vous insérez simplement le code du noyau dans la fenêtre du compilateur, mais pas sous la forme utilisée dans le code MQL5 mais à la place sans guillemets externes et "\r\n" (caractères de retour à la ligne) et appuyez sur le bouton Build avec une icône de roue dentée sur ceci.
Ce faisant, la fenêtre Build Log affichera des informations sur le processus de Build et sa progression :
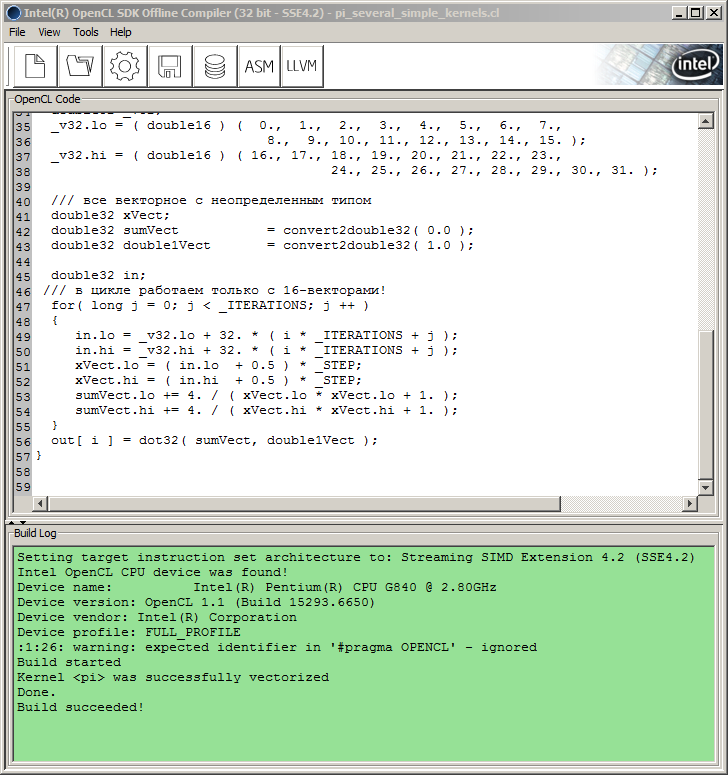
Fig. 9. Compilation de programmes dans le compilateur hors ligne Intel OpenCL SDK
Afin d'obtenir le code du noyau sans guillemets, il serait utile d'écrire un programme simple dans le langage hôte (MQL5) qui produirait le code du noyau dans un fichier - WriteCLProgram(). Il est maintenant compris dans le code du programme hôte.
Les messages du compilateur ne sont pas toujours très clairs mais ils fournissent beaucoup plus d'informations que MQL5 en peut actuellement. Les erreurs peuvent être immédiatement corrigées dans la fenêtre du compilateur et une fois que vous vous êtes assuré qu'il n'y en a plus, les corrections peuvent être transférées dans le code du noyau dans MetaEditor.
Et la dernière chose. L'idée initiale de l'auteur était d’élaborer un code vectorisé capable de travailler avec les vecteurs double4, double8 et double16 en définissant un seul paramètre global "nombre de canaux". Cela a finalement été accompli, après quelques jours de difficultés avec l'opérateur de collage de jetons ## qui, pour une certaine raison, refusait de travailler dans le code du noyau.
Pendant ce temps, l'auteur a élaboré avec succès un code de travail du script avec trois codes de noyau dont chacun est adapté à sa dimension - 4, 8 ou 16. Ce code intermédiaire ne sera pas fourni dans l'article mais il valait la peine de le mentionner au cas où vous souhaiteriez écrire un code noyau sans trop de soucis. Le code de cette implémentation de script (OCL_pi_double_several_simple_kernels.mq5) est joint ci-dessous à la fin de l'article.
Et voici le code du noyau vectorisé :
"/// enable extensions with doubles \r\n" "#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _intrnCnt ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" "#define _CH " + i2s( _ch ) + " \r\n" "#define _DOUBLETYPE double" + i2s( _ch ) + " \r\n" " \r\n" "/// extensions for 4-, 8- and 16- scalar products \r\n" "#define dot4( a, b ) dot( a, b ) \r\n" " \r\n" "inline double dot8( double8 a, double8 b ) \r\n" "{ \r\n" " return dot4( a.lo, b.lo ) + dot4( a.hi, b.hi ); \r\n" "} \r\n" " \r\n" "inline double dot16( double16 a, double16 b ) \r\n" "{ \r\n" " double16 c = a * b; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot4( c.lo.lo + c.lo.hi + c.hi.lo + c.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double16 v16 = ( double16 ) ( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ); \r\n" " double8 v8 = v16.lo; \r\n" " double4 v4 = v16.lo.lo; \r\n" " double2 v2 = v16.lo.lo.lo; \r\n" " \r\n" " /// all vector-related with the calculated type \r\n" " _DOUBLETYPE in; \r\n" " _DOUBLETYPE xVect; \r\n" " _DOUBLETYPE sumVect = ( _DOUBLETYPE ) ( 0.0 ); \r\n" " _DOUBLETYPE doubleOneVect = ( _DOUBLETYPE ) ( 1.0 ); \r\n" " _DOUBLETYPE doubleCHVect = ( _DOUBLETYPE ) ( _CH + 0. ); \r\n" " _DOUBLETYPE doubleSTEPVect = ( _DOUBLETYPE ) ( _STEP ); \r\n" " \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in = v" + i2s( _ch ) + " + doubleCHVect * ( i * _ITERATIONS + j ); \r\n" " xVect = ( in + 0.5 ) * doubleSTEPVect; \r\n" " sumVect += 4.0 / ( xVect * xVect + 1. ); \r\n" " } \r\n" " out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n" "} \r\n";
Le programme hôte externe n'a pas beaucoup changé, à part la nouvelle constante globale _ch fixant le nombre de "canaux de vectorisation" et la constante globale _intrnCnt qui est devenue _ch fois plus petite. C'est pourquoi l'auteur a décidé de ne pas montrer le code du programme hôte ici. Il se trouve dans le fichier de script joint ci-dessous à la fin de l'article (OCL_pi_double_parallel_straight.mq5).
Comme nous pouvons le constater, outre la fonction "principale" du noyau pi(), nous avons maintenant deux fonctions en ligne qui déterminent le produit scalaire des vecteurs dotN( a, b ) et une macro substitution. Ces fonctions sont impliquées du fait que la fonction dot() dans OpenCL est définie par rapport à des vecteurs dont la dimension n'excède pas 4.
La macro dot4() redéfinissant la fonction dot() n'est là que pour la commodité d'appeler la fonction dotN() avec le nom calculé :
" out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n"
Si nous avions utilisé la fonction point() sous sa forme habituelle, sans l'indice 4, nous n'aurions pas pu l'appeler aussi facilement qu'il est montré ici, lorsque _ch = 4 (nombre de canaux de vectorisation étant égal à 4).
Cette ligne illustre une autre caractéristique utile de le forme du noyau reposant sur la fait que le noyau comme tel est traité avec un programme hôte en tant que chaîne nous pouvons utiliser des identifiants calculés dans le noyau seulement pour les fonctions mais aussi pour les types de données!
Le code complet du programme hôte avec ce noyau est joint ci-dessous (OCL_pi_double_parallel_straight.mq5).
En exécutant le script avec le vecteur "width" étant 16 ( _ch = 16 ), nous obtenons ce qui suit :
2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) ================================================== 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) CPUtime / GPUtime = 4.130 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The time to calculate PI was 8.830 seconds 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The value of PI is 3.141592653590 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The time to calculate PI was 8.002 seconds 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The value of PI is 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: gone = 2.138 sec. 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: pi = 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) read = 20000 elements 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) CLProgramCreate: unknown error. 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) ==================================================
Vous pouvez voir que même l'optimisation utilisant des types de données vectorielles n'a pas rendu le noyau plus rapide.
Mais si vous exécutez le même code sur GPU, le gain de vitesse sera bien plus considérable.
Selon les informations fournies par MetaDriver (video card - HIS Radeon HD 6930, CPU - AMD Phenom II x6 1100T), le même code donne les résultats suivants:
2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) ================================================== 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) CPUtime / GPUtime = 84.983 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The time to calculate PI was 14.617 seconds 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The value of PI is 3.141592653590 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The time to calculate PI was 14.040 seconds 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The value of PI is 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: gone = 0.172 sec. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) read = 20000 elements 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) CLProgramCreate: unknown error. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) ==================================================
6. La Touche Finale
Voici un autre noyau (il peut être trouvé dans le fichier OCL_pi_double_several_simple_kernels.mq5 joint ci-dessous qui n'est cependant pas démontré ici).
Le script est une implémentation de l'idée que l'auteur avait lorsqu'il a temporairement abandonné une tentative d'écrire un noyau "unique" et a pensé à écrire quatre noyaux simples pour différentes dimensions vectorielles (4, 8, 16, 32), :
"#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _itInKern ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" " \r\n" "typedef struct \r\n" "{ \r\n" " double16 lo; \r\n" " double16 hi; \r\n" "} double32; \r\n" " \r\n" "inline double32 convert2double32( double a ) \r\n" "{ \r\n" " double32 b; \r\n" " b.lo = ( double16 )( a ); \r\n" " b.hi = ( double16 )( a ); \r\n" " return b; \r\n" "} \r\n" " \r\n" "inline double dot32( double32 a, double32 b ) \r\n" "{ \r\n" " double32 c; \r\n" " c.lo = a.lo * b.lo; \r\n" " c.hi = a.hi * b.hi; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot( c.lo.lo.lo + c.lo.lo.hi + c.lo.hi.lo + c.lo.hi.hi + \r\n" " c.hi.lo.lo + c.hi.lo.hi + c.hi.hi.lo + c.hi.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double32 _v32; \r\n" " _v32.lo = ( double16 ) ( 0., 1., 2., 3., 4., 5., 6., 7., \r\n" " 8., 9., 10., 11., 12., 13., 14., 15. ); \r\n" " _v32.hi = ( double16 ) ( 16., 17., 18., 19., 20., 21., 22., 23., \r\n" " 24., 25., 26., 27., 28., 29., 30., 31. ); \r\n" " \r\n" " /// all vector-related with undefined type \r\n" " double32 xVect; \r\n" " double32 sumVect = convert2double32( 0.0 ); \r\n" " double32 double1Vect = convert2double32( 1.0 ); \r\n" " \r\n" " double32 in; \r\n" " /// work only with 16-vectors in the loop! \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in.lo = _v32.lo + 32. * ( i * _ITERATIONS + j ); \r\n" " in.hi = _v32.hi + 32. * ( i * _ITERATIONS + j ); \r\n" " xVect.lo = ( in.lo + 0.5 ) * _STEP; \r\n" " xVect.hi = ( in.hi + 0.5 ) * _STEP; \r\n" " sumVect.lo += 4. / ( xVect.lo * xVect.lo + 1. ); \r\n" " sumVect.hi += 4. / ( xVect.hi * xVect.hi + 1. ); \r\n" " } \r\n" " out[ i ] = dot32( sumVect, double1Vect ); \r\n" "} \r\n";
Ce noyau même implémente la dimension vectorielle 32. Le nouveau type de vecteur et quelques fonctions en ligne nécessaires sont définis en dehors de la fonction principale du noyau. En plus de cela (et c'est important !), tous les calculs dans la boucle principale sont intentionnellement effectués uniquement avec des types de données vectorielles standard ; les types non standard sont traités en dehors de la boucle. Cela permet d'accélérer considérablement le temps d'exécution du code.
Dans notre calcul, ce noyau ne semble pas plus lent que lorsqu'il est utilisé pour des vecteurs d'une largeur de 16, mais il n'est pas beaucoup plus rapide non plus.
Selon les informations fournis par MetaDriver,le script avec ce noyau (_ch=32) donne les résultats suivants:
2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: gone = 0.156 sec. 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) read = 10000 elements 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) CLProgramCreate: unknown error or no error. 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) GetLastError returned .. 0 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _itInKern = 3125; vectorization channels - 32 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) =================================================================
Résumé et Conclusions
L'auteur comprend parfaitement que la tâche choisie pour la démonstration des ressources OpenCL n'est pas tout à fait typique de ce langage.
Il aurait été beaucoup plus simple de prendre un manuel et d'écrire un exemple standard de multiplication de grandes matrices pour le poster ici. Cet exemple serait évidemment impressionnant. Cependant, y a-t-il de nombreux utilisateurs du forum mql5.com qui sont engagés dans des calculs financiers nécessitant la multiplication de grandes matrices ? C'est assez douteux. L'auteur a voulu choisir son propre exemple et surmonter par lui-même toutes les difficultés rencontrées sur le chemin, tout en tentant de partager son expérience avec les autres. Bien sûr, vous êtes les seuls à juger, chers utilisateurs du forum.
Le gain en efficacité sur l'émulation OpenCL (sur CPU "nu") s'est avéré assez faible en comparaison des centaines voire des milliers obtenus à l'aide des scripts de MetaDriver Mais sur un GPU adéquat, ce sera au moins un ordre de grandeur supérieur à celui sur l'émulation, même si l'on fait abstraction d'un temps d’exécution un peu plus long sur CPU avec CPU AMD. OpenCL vauttoujours la peine d’être appris même si le gain en vitesse de calcul est seulement aussi grand!
Le prochain article de l'auteur devrait aborder les problèmes liés aux spécificités de l'affichage de modèles abstraits OpenCL sur du matériel réel. La connaissance de ces choses permet parfois d'accélérer considérablement les calculs.
l’auteur souhaiterait remercier particulièrement MetaDriverpour leurs précieux conseils en terme de programmation et optimisation de performance et l’ Equipe de Soutien pour nous avoir offert la possibilité d’utiliser Intel OpenCL SDK.
Contenus des fichiers attachés.
- pi.mq5 - un script en MQL5 pur présentant deux façons de calculer la valeur "pi" ;
- OCl_pi_float.mq5 - la première implémentation du script avec le noyau OpenCL impliquant des calculs réels avec le type float ;
- OCL_pi_double.mq5 - le même, n'impliquant que des calculs réels avec le type double ;
- OCL_pi_double_several_simple_kernels.mq5 - un script avec plusieurs noyaux spécifiques pour différentes "largeurs" vectorielles (4, 8, 16, 32);
- OCL_pi_double_parallel_straight.mq5 - un script avec un seul noyau pour certaines "largeurs" vectorielles (4, 8, 16).
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/405
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Pourquoi le Marché MQL5 est-il le Meilleur Endroit pour Vendre des Stratégies de Trading et des Indicateurs Techniques
Pourquoi le Marché MQL5 est-il le Meilleur Endroit pour Vendre des Stratégies de Trading et des Indicateurs Techniques
 La Programmation Basée sur des Automates comme Nouvelle Approche pour créer des Systèmes de Trading Automatisés
La Programmation Basée sur des Automates comme Nouvelle Approche pour créer des Systèmes de Trading Automatisés
 Opportunités Illimitées avec MetaTrader 5 et MQL5
Opportunités Illimitées avec MetaTrader 5 et MQL5
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Un nouvel article intitulé OpenCL : A Bridge to a Parallel World a été publié :
Par Sceptic Philozoff
Le support d'OpenCL est un très bon choix, aujourd'hui et à l'avenir l'hétérogénéité des plateformes informatiques est très évidente, mais aujourd'hui les mêmes algorithmes dans les conditions d'utilisation d'OpenCL sont beaucoup moins performants que CUDA, peut-être que CUDA est plus sous-jacent qu'OpenCL, mieux optimisé pour son propre GPU. Les GPU de NVIDIA ont de meilleures performances, une meilleure dynamique, et le compilateur CUDA a adopté LLVM. Les performances des GPU NVIDIA sont meilleures, la dynamique de développement est meilleure et le compilateur CUDA a adopté LLVM. De plus en plus de langages prendront en charge CUDA, Python peut désormais le faire, en particulier CUDA6.0 dans la facilité d'utilisation de la programmation, en particulier la technologie de mémoire unifiée, à l'avenir, la prise en charge de la migration automatique des données par le runtime CUDA sera meilleure, les performances du programme et la productivité de la programmation seront améliorées. La prise en charge d'OpenCL par MQL5 est un bon début, et il y a peut-être des choses à faire avec CUDA à l'avenir.
Réponse d'un auteur ou d'un expert s'il vous plaît :
Où le code ci-dessous fonctionnera-t-il plus rapidement sur la pierre principale ou dans le vidicon ? Et y a-t-il des spécificités ?
void OnStart()
{
long total= 1000000000;
for(long i=0;i<total;i++)
for(long q=0;q<total;q++)
for(long w=0;w<total;w++)
for(long e=0;e<total;e++)
for(long r=0;r<total;r++)
for(long t=0;t<total;t++)
for(long y=0;y<total;y++)
for(long u=0;u<total;u++)
func(i,q,w,e,r,t,y,u);
}
Par exemple :
Pi = 4*atan(1) ;
ou
Pi = acos(-1) ;
Je ne pense pas que plus de 7 secondes pour obtenir la valeur de PI sur 12 décimales soit la meilleure efficacité.
J'ai entendu parler d'OpenCV pour Python et Machine Learning qui peut être utile même dans le domaine hautement psychologique qu'est le trading mais jamais d'OpenCL. Sur ces bases, il existe un environnement d'interface agréable qui est aujourd'hui ZeroMQ. J'imagine que la communication entre la plateforme MTx et l'environnement Python peut prendre un peu de temps surtout s'il y a beaucoup de données qui doivent transiter.
Merci pour cet article.