
OpenCL: Paralel dünyalara köprü

Giriş
Bu makale, OpenCL veya Open Computing Language'de programlamayla ilgili kısa bir dizi yayının ilkidir. Mevcut haliyle MetaTrader 5 platformu, OpenCL için destek sağlamadan önce, hesaplamaları hızlandırmak için çok çekirdekli işlemcilerin doğrudan, yani özgün olarak kullanılmasına ve avantajlarından yararlanılmasına izin vermiyordu.
Açıkçası, geliştiriciler terminalin çok iş parçacıklı olduğunu ve "her EA/ komut dosyasının ayrı bir iş parçacığında çalıştığını", ancak kodlayıcıya aşağıdaki basit döngünün (bu, pi değerini = 3.14159265...'i hesaplamak için bir koddur) nispeten kolay paralel yürütülmesi için bir fırsat verilmediğini durmadan tekrarlayabilirdi:
long num_steps = 1000000000; double step = 1.0 / num_steps; double x, pi, sum = 0.0; for (long i = 0; i<num_steps; i++) { x = (i + 0.5)*step; sum += 4.0/(1.0 + x*x); } pi = sum*step;
Ancak bundan 18 ay kadar önce, "Makaleler" bölümünde "Parallel Calculations in MetaTrader 5 (MetaTrader 5'te Paralel Hesaplamalar)" başlıklı çok ilginç bir çalışma ortaya çıktı. Ve yine de... insan, yaklaşımın yaratıcılığına rağmen, bunun bir şekilde doğal olmadığı izlenimine kapılıyor - yukarıdaki döngüde hesaplamaları hızlandırmak için yazılmış tüm bir program hiyerarşisi (Uzman Danışman ve iki gösterge) gereğinden fazla iyi olurdu.
OpenMP'yi destekleme planları olmadığını zaten biliyoruz ve OMP eklemenin, derleyicinin ciddi bir şekilde yeniden programlanmasını gerektirdiğinin farkındayız. Ne yazık ki, düşünmenin gerekmediği bir kodlayıcı için ucuz ve kolay bir çözüm olmayacak.
МQL5'te OpenCL için özgün desteğin duyurusu bu nedenle çok hoş bir haberdi. Aynı haber dizisinin 22. sayfasından başlayarak MetaDriver, CPU ve GPU'daki uygulama arasındaki farkı değerlendirmeye izin veren komut dosyaları göndermeye başladı. OpenCL muazzam bir ilgi uyandırdı.
Bu makalenin yazarı ilk olarak sürecin dışında kalmayı tercih etti: oldukça düşük kaliteli bir bilgisayar konfigürasyonu (Pentium G840/8 Gb DDR-III 1333/Video kartı yok) OpenCL'nin etkin kullanımını sağlamıyor gibi görünüyordu.
Ancak, AMD tarafından geliştirilen özel bir yazılım olan AMD APP SDK'nın yüklenmesinin ardından, MetaDriver tarafından önerilen ve yalnızca ayrı bir video kartı mevcut olduğunda başkaları tarafından çalıştırılan ilk komut dosyası, yazarın bilgisayarında başarıyla çalıştırıldı ve bir hız artışı gösterdi; bu, bir işlemci çekirdeğindeki standart bir komut dosyası çalışma zamanı ile karşılaştırıldığında önemsiz olmaktan çok uzaktı ve yaklaşık 25 kat daha hızlıydı. Daha sonra, Intel OpenCL Runtime'ın Destek Ekibi'nin yardımıyla başarıyla yüklenmesi sayesinde aynı komut dosyası çalışma zamanının hızlanması 75'e ulaştı.
ixbt.com tarafından sağlanan forumu ve materyalleri dikkatle inceleyen yazar, Intel'in Tümleşik Grafik İşlemcisinin (IGP) OpenCL 1.1'i desteklediğini, yalnızca Ivy Bridge işlemcileri ve sonraki sürümlerle başladığını öğrendi. Sonuç olarak, yukarıdaki konfigürasyona sahip PC'de elde edilen hızlanmanın IGP ile hiçbir ilgisi olamazdı ve bu özel durumda OpenCL program kodu sadece х86 çekirdekli CPU'da yürütüldü.
Yazar, hızlanma rakamlarını ixbt uzmanlarıyla paylaştığında, anında ve hep bir ağızdan tüm bunların kaynak dilin (MQL5) önemli ölçüde yetersiz optimizasyonunun bir sonucu olduğunu söylediler. OpenCL profesyonelleri topluluğunda, bir kaynak kodunun С++ dilinde (tabii ki, çok çekirdekli bir işlemci ve SSEx vektör talimatlarının kullanımına tabi olarak) doğru bir şekilde optimize edilmesinin en iyi şekilde OpenCL öykünmesinde yüzde birkaç düzine kazançla sonuçlanabileceği bilinen bir gerçektir; en kötü senaryoda, örneğin veri aktarırken (zamanın) aşırı yüksek olması nedeniyle kaybedebilirsiniz.
Dolayısıyla - başka bir varsayım: MetaTrader 5'teki saf OpenCL öykünmesi üzerindeki 'mucizevi' hızlanma rakamları, OpenCL'nin kendisinin "cool’luğuna" atfedilmeden yeterince ele alınmalıdır. С++'da iyi optimize edilmiş bir programa göre GPU'nun gerçekten güçlü bir avantajı, yalnızca oldukça güçlü bir ayrı video kartı kullanılarak elde edilebilir, çünkü bazı algoritmalardaki hesaplama yetenekleri herhangi bir modern CPU'nun yeteneklerinin çok ötesindedir.
Terminalin geliştiricileri, henüz uygun şekilde optimize edilmediğini belirtmektedir. Ayrıca, optimizasyonun ardından birkaç kat fazla olacak olan hızlanma derecesi hakkında bir ipucu verdiler. OpenCL'deki tüm hızlanma rakamları buna göre aynı ölçüde "birkaç kat" azaltılacaktır. Ancak yine de unity’den çok daha büyük olacaklar.
Devam edeceğimiz OpenCL dilini (video kartınız OpenCL 1.1'i desteklemiyor olsa veya eksik olsa bile) öğrenmek için iyi bir nedendir. Ama önce konunun temeli hakkında birkaç söz söylememe izin verin - Open CL'yi destekleyen yazılım ve uygun donanım.
1. Temel Yazılım ve Donanım
1.1.AMD
Uygun yazılım, kar amacı gütmeyen endüstri konsorsiyumunun üyeleri olan AMD, Intel ve NVidia tarafından üretilir - heterojen ortamlardaki hesaplamalarla ilgili farklı dil özellikleri geliştiren Khronos Group.
Bazı faydalı materyaller Khronos Group'un resmi web sitesinde bulunabilir, örneğin:
Terminal henüz OpenCL hakkında Yardım bilgisi sunmadığından (OpenCL API'sinin sadece kısa bir özeti vardır) bu belgelerin OpenCL öğrenme sürecinde oldukça sık kullanılması gerekecektir. Her üç şirket de (AMD, Intel ve NVidia) video donanımı tedarikçisidir ve her birinin kendi OpenCL Runtime uygulaması ve ilgili yazılım geliştirme kitleri - SDK vardır. AMD ürünlerini örnek alarak video kartı seçmenin özelliklerine geçelim.
AMD video kartınız çok eski değilse (ilk olarak 2009-2010 veya sonrasında üretime geçmiştir), oldukça basit olacaktır - hemen çalışmaya başlamak için video kartı sürücünüzün güncellenmesi yeterli olacaktır. OpenCL uyumlu video kartlarının listesi burada bulunabilir. Öte yandan Radeon HD 4850 (4870) gibi zamanına göre oldukça iyi bir video kartı bile OpenCL ile uğraşırken sizi zahmetten kurtarmaz.
Henüz bir AMD video kartınız yoksa ancak bir tane edinmeye hazırsanız, önce özelliklerine bir göz atın. Burada oldukça kapsamlı bir Modern AMD Video Kartları Özellikleri Tablosu görebilirsiniz. Bizim için en önemlileri şunlardır:
- Yerleşik Bellek — yerel bellek miktarı. Ne kadar büyükse o kadar iyidir. 1 GB genellikle yeterli olacaktır.
- Core Clock — çalışma çekirdek frekansı. Ayrıca şu açıktır: GPU çoklu işlemcilerinin çalışma frekansı ne kadar yüksekse, o kadar iyidir. 650-700 MHz hiç de fena değildir.
- [Bellek] Türü — video belleği türü. Bellek idealde hızlı, yani GDDR5 olmalıdır. Ancak bellek bant genişliği açısından yaklaşık iki kat daha kötü olsa da GDDR3 de iyi olur.
- [Bellek] Saati (Eff.) - video belleğinin çalışma (etkin) frekansı. Teknik olarak, bu parametre bir öncekiyle yakından ilişkilidir. GDDR5'in etkin çalışma frekansı, GDDR3'ün frekansının ortalama iki katı kadar yüksektir. "Yüksek" bellek türlerinin daha yüksek frekanslarda çalışmasıyla hiçbir ilgisi yoktur, ancak bellek tarafından kullanılan veri aktarım kanallarının sayısından kaynaklanır. Başka bir deyişle, bellek bant genişliği ile ilgilidir.
- [Bellek] Veri Yolu - veri yolu veri genişliği. En az 256 bit olması tavsiye edilir.
- MBW - Bellek Bant Genişliği. Bu parametre aslında yukarıdaki video belleği parametrelerinin üçünün birleşimidir. Ne kadar yüksekse o kadar iyidir.
- Config Core (SPU:TMU(TF):ROP) — GPU çekirdek birimlerinin konfigürasyonu. Bizim için önemli olan yani grafiksel olmayan hesaplamalar için ilk sayıdır. Belirtilen 1024:64:32, 1024 sayısına (birleşik akış işlemcileri veya gölgelendiricilerin sayısı) ihtiyacımız olduğu anlamına gelir. Açıkçası, ne kadar yüksekse o kadar iyidir.
- İşlem Gücü — kayan nokta hesaplamalarında teorik performans (FP32 (Tek Duyarlıklı) / FP64 (Çift Duyarlıklı). Özellik tabloları her zaman FP32'ye karşılık gelen bir değer içerse de (tüm video kartları tek duyarlıklı hesaplamaları işleyebilir), çift duyarlık her video kartı tarafından desteklenmediğinden FP64'te durum böyle değildir. GPU hesaplamalarında asla çift duyarlığa (çift tip) ihtiyacınız olmayacağından eminseniz ikinci parametreyi göz ardı edebilirsiniz. Ancak durum ne olursa olsun, bu parametre ne kadar yüksekse o kadar iyidir.
- TDP — Termal Tasarım Gücü. Bu, kabaca konuşursak, video kartının en zor hesaplamalarda harcadığı maksimum güçtür. Uzman Danışmanınız sık sık GPU'ya erişecekse, video kartı yalnızca çok fazla güç tüketmekle kalmayacak (bu işe yararsa fena değil) aynı zamanda oldukça gürültülü olacaktır.
Gelelim ikinci duruma: Video kartı yok veya mevcut video kartı OpenCL 1.1'i desteklemiyor ama AMD işlemciniz var. Buradan çalışma zamanı dışında SDK, Kernel Analyzer ve Profiler içeren AMD APP SDK'sını indirebilirsiniz. AMD APP SDK kurulumunun ardından, işlemci bir OpenCL cihazı olarak tanınmalıdır. Ve CPU üzerinde öykünme modunda tam özellikli OpenCL uygulamaları geliştirebileceksiniz.
AMD'nin aksine SDK'nın temel özelliği, Intel işlemcilerle de uyumlu olmasıdır (her ne kadar Intel CPU üzerinde geliştirme yapılırken özgün SDK, SSE4.1, SSE4.2 ve SSE4.2'yi ve AMD işlemcilerde henüz yeni kullanıma sunulan AVX komut setlerini destekleyebildiği için önemli ölçüde daha verimli olsa).
1.2. Intel
Intel işlemciler üzerinde çalışmaya başlamadan önce Intel OpenCL SDK/Runtime dosyasını indirmeniz önerilir.
Aşağıdakileri belirtmeliyiz:
- OpenCL uygulamalarını yalnızca CPU (OpenCL öykünme modu) kullanarak geliştirmeyi düşünüyorsanız, Intel CPU grafik çekirdeğinin Sandy Bridge dahil ve bundan daha eski işlemciler için OpenCL 1.1'i desteklemediğini bilmelisiniz. Bu destek yalnızca Ivy Bridge işlemcilerde mevcuttur, ancak ultra güçlü Intel HD 4000 tümleşik grafik birimi için bile neredeyse hiçbir fark yaratmayacaktır. Ivy Bridge'den daha eski işlemciler için bu, MQL5 ortamında elde edilen hızlanmanın yalnızca kullanılan SS(S)Ex vektör komutları nedeniyle olduğu anlamına gelir. Ancak önemli de görünmektedir.
- Intel OpenCL SDK'nın yüklenmesinden sonra, HKEY_LOCAL_MACHINE\SOFTWARE\Khronos\OpenCL\Vendors kayıt defteri girişinin şu şekilde değiştirilmesi gerekir: Ad sütunundaki IntelOpenCL64.dll'yi intelocl.dll ile değiştirin. Ardından yeniden başlatın ve MetaTrader 5'i başlatın. CPU artık bir OpenCL 1.1 aygıtı olarak tanınır.
Dürüst olmak gerekirse, Intel'in OpenCL desteğiyle ilgili sorun henüz tam olarak çözülmedi, bu nedenle gelecekte terminal geliştiricilerinden bazı açıklamalar beklemeliyiz. Temel olarak, mesele şu ki, hiç kimse sizin için çekirdek kod hatalarını takip etmeyecek (OpenCL çekirdeği GPU'da yürütülen bir programdır) - MQL5 derleyicisi değil. Derleyici, yalnızca çekirdeğin büyük bir satırını alır ve onu çalıştırmaya çalışır. Örneğin, çekirdekte kullanılan х dahili değişkenini bildirmediyseniz, çekirdek hatalarla da olsa teknik olarak yürütülmeye devam edecektir.
Bununla birlikte, terminalde alacağınız tüm hatalar, CLKernelCreate() ve CLProgramCreate() fonksiyonları için API OpenCL Yardım'da açıklananlardan bir düzineden daha azına iner. Dil sözdizimi, vektör fonksiyonları ve veri türleri ile geliştirilmiş C'ye çok benzer (aslında bu dil, 1999'da ANSI С standardı olarak kabul edilen C99'dur).
Bu makalenin yazarının OpenCL kodunda hata ayıklamak için kullandığı Intel OpenCL SDK Çevrimdışı Derleyicisidir; MetaEditor'da körü körüne çekirdek hatalarını aramaktan çok daha uygundur. Umarım, gelecekte durum daha iyiye doğru değişecektir.
1.3. NVidia
Ne yazık ki, yazar bu konuda bilgi aramamıştır. Bununla birlikte, genel öneriler aynıdır. Yeni NVidia video kartlarının sürücüleri otomatik olarak OpenCL'yi destekler.
Temel olarak, makalenin yazarının NVidia video kartlarına karşı hiçbir şeyi yok, ancak bilgi arama ve forum tartışmalarından elde edilen bilgilere dayanarak çıkarılan sonuç şu şekilde: grafiksel olmayan hesaplamalar için AMD video kartları fiyat/performans oranı açısından NVidia ekran kartlarına göre daha uygun görünüyor.
Şimdi programlamaya geçelim.
2. OpenCL Kullanan İlk MQL5 Programı
İlk, çok basit programımızı geliştirebilmek için, görevi bu şekilde tanımlamamız gerekiyor. Paralel programlama derslerinde yaklaşık olarak 3.14159265'e eşit olan pi değerinin hesaplanmasını örnek olarak kullanmak alışkanlık haline gelmiş olmalıdır.
Bu amaçla şu formül kullanılır (yazar bu formüle daha önce hiç rastlamamıştır ama doğru görünmektedir):

Değeri, 12 ondalık basamağa kadar doğru hesaplamak istiyoruz. Temelde böyle bir kesinlik yaklaşık 1 milyon yinelemeyle elde edilebilir ancak bu sayı GPU üzerinde hesaplamaların süresi çok kısaldığı için OpenCL'deki hesaplamaların faydasını değerlendirmemize olanak vermeyecektir.
GPGPU programlama dersleri, GPU görev süresinin en az 20 milisaniye olacağı şekilde hesaplama miktarının seçilmesini önerir. Bizim durumumuzda, GetTickCount() fonksiyonunun 100 ms ile karşılaştırılabilir önemli hatası nedeniyle bu sınır daha yüksek ayarlanmalıdır.
Bu hesaplamanın uygulandığı MQL5 programı aşağıdadır:
//+------------------------------------------------------------------+ //| pi.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" long _num_steps = 1000000000; long _divisor = 40000; double _step = 1.0 / _num_steps; long _intrnCnt = _num_steps / _divisor; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { uint start,stop; double x,pi,sum=0.0; start=GetTickCount(); //--- first option - direct calculation for(long i=0; i<_num_steps; i++) { x=(i+0.5)*_step; sum+=4.0/(1.+x*x); } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); //--- calculate using the second option start=GetTickCount(); sum=0.; long divisor=40000; long internalCnt=_num_steps/divisor; double partsum=0.; for(long i=0; i<divisor; i++) { partsum=0.; for(long j=i*internalCnt; j<(i+1)*internalCnt; j++) { x=(j+0.5)*_step; partsum+=4.0/(1.+x*x); } sum+=partsum; } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); Print("_______________________________________________"); return(0); } //+------------------------------------------------------------------+Bu komut dosyasını derleyip çalıştırdıktan sonra şunu elde ederiz:
2012.05.03 02:02:23 pi (EURUSD,H1) The time to calculate PI was 8.783 seconds 2012.05.03 02:02:23 pi (EURUSD,H1) The value of PI is 3.141592653590 2012.05.03 02:02:15 pi (EURUSD,H1) The time to calculate PI was 7.940 seconds 2012.05.03 02:02:15 pi (EURUSD,H1) The value of PI is 3.141592653590
Pi değeri ~ 3.14159265 biraz farklı iki yolla hesaplanır.
Birincisi, OpenMP, Intel TPP, Intel MKL ve diğerleri gibi çoklu iş parçacıklı kitaplıkların yeteneklerinin gösterilmesi için neredeyse klasik bir yöntem olarak kabul edilebilir.
İkincisi, çift döngü şeklinde aynı hesaplamadır. 1 milyar yinelemeden oluşan tüm hesaplama, her bloğun iç döngüyü oluşturan 25000 "temel" yinelemeyi yürüttüğü dış döngünün (40000 tane vardır) büyük bloklarına bölünür.
Bu hesaplamanın %10-15 gibi biraz daha yavaş çalıştığını görebilirsiniz. Ancak OpenCL'ye dönüştürürken temel olarak kullanacağımız bu özel hesaplamadır. Ana neden, bir bellek alanından diğerine veri aktarımı için harcanan süre ile çekirdekte yürütülen hesaplamalar arasında makul bir uzlaşmayı gerçekleştirecek çekirdek (GPU'da yürütülen temel hesaplama görevi) seçimidir. Böylece, mevcut görev açısından, çekirdek kabaca ikinci hesaplama algoritmasının iç döngüsü olacaktır.
Şimdi, değeri OpenCL kullanarak hesaplayalım. Tam bir program kodunun ardından, OpenCL'ye bağlanan ana bilgisayar dilinin (MQL5) fonksiyon özellikleri hakkında kısa yorumlar gelecektir. Ama önce, OpenCL'de kodlamaya engel olabilecek tipik "engeller" ile ilgili birkaç noktayı vurgulamak istiyorum:
- Çekirdek, çekirdeğin dışında bildirilen değişkenleri görmez. Bu nedenle, _step ve _intrnCnt global değişkenlerinin çekirdek kodunun başında yeniden bildirilmesi gerekiyordu (aşağıya bakın). Ve bunların ilgili değerleri, çekirdek kodunda düzgün bir şekilde okunabilmesi için dizelere dönüştürülmek zorundaydı. Bununla birlikte, OpenCL'deki programlamanın bu özelliği, daha sonra, örneğin C'de özgün olarak bulunmayan vektör veri türleri yaparken çok yararlı olduğunu kanıtladı.
- Çekirdeğe, sayılarını makul tutarken mümkün olduğunca çok hesaplama vermeye çalışın. Mevcut donanımdaki bu kodda çekirdek çok hızlı olmadığı için bu kod için bu çok kritik değildir. Ancak bu faktör, güçlü bir farklı video kartı kullanılıyorsa hesaplamaları hızlandırmanıza yardımcı olacaktır.
İşte OpenCL çekirdeğine sahip komut dosyası kodu:
//+------------------------------------------------------------------+ //| OCL_pi_float.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs; input int _device=0; /// OpenCL device number (0, I have CPU) #define _num_steps 1000000000 #define _divisor 40000 #define _step 1.0 / _num_steps #define _intrnCnt _num_steps / _divisor string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(int arg) { return IntegerToString(arg); } const string clSrc= "#define _step "+d2s(_step,12)+" \r\n" "#define _intrnCnt "+i2s(_intrnCnt)+" \r\n" " \r\n" "__kernel void pi( __global float *out ) \r\n" // type float "{ \r\n" " int i = get_global_id( 0 ); \r\n" " float partsum = 0.0; \r\n" // type float " float x = 0.0; \r\n" // type float " long from = i * _intrnCnt; \r\n" " long to = from + _intrnCnt; \r\n" " for( long j = from; j < to; j ++ ) \r\n" " { \r\n" " x = ( j + 0.5 ) * _step; \r\n" " partsum += 4.0 / ( 1. + x * x ); \r\n" " } \r\n" " out[ i ] = partsum; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { Print("FLOAT: _step = "+d2s(_step,12)+"; _intrnCnt = "+i2s(_intrnCnt)); int clCtx=CLContextCreate(_device); int clPrg = CLProgramCreate( clCtx, clSrc ); int clKrn = CLKernelCreate( clPrg, "pi" ); uint st=GetTickCount(); int clMem=CLBufferCreate(clCtx,_divisor*sizeof(float),CL_MEM_READ_WRITE); // type float CLSetKernelArgMem(clKrn,0,clMem); const uint offs[ 1 ] = { 0 }; const uint works[ 1 ] = { _divisor }; bool ex=CLExecute(clKrn,1,offs,works); //--- Print( "CL program executed: " + ex ); float buf[]; // type float ArrayResize(buf,_divisor); uint read=CLBufferRead(clMem,buf); Print("read = "+i2s(read)+" elements"); float sum=0.0; // type float for(int cnt=0; cnt<_divisor; cnt++) sum+=buf[cnt]; float pi=float(sum*_step); // type float Print("pi = "+d2s(pi,12)); CLBufferFree(clMem); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); double gone=(GetTickCount()-st)/1000.; Print("OpenCl: gone = "+d2s(gone,3)+" sec."); Print("________________________"); return(0); } //+------------------------------------------------------------------+
Komut dosyası kodunun daha ayrıntılı bir açıklaması biraz sonra verilecektir.
Bu arada, aşağıdakileri elde etmek için programı derleyin ve başlatın:
2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) ________________________ 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) OpenCl: gone = 5.538 sec. 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) pi = 3.141622066498 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) read = 40000 elements 2012.05.03 02:20:15 OCl_pi_float (EURUSD,H1) FLOAT: _step = 0.000000001000; _intrnCnt = 25000
Görüldüğü gibi, çalışma zamanı biraz azaldı. Ancak bu bizi mutlu etmek için yeterli değil: görülüyor ki pi ~ 3.14159265 değeri, ondalık noktadan sonraki 3. haneye kadar doğrudur. Hesaplamaların bu pürüzlülüğü, gerçek hesaplamalarda çekirdeğin, doğruluğu, 12 ondalık basamağa kadar doğru olan gerekli kesinliğin açıkça altında olan kayan tipteki sayıları kullanmasından kaynaklanmaktadır.
MQL5 Belgelerine göre, bir kaydırma türünde bir sayının kesinliği yalnızca 7 anlamlı rakam için doğrudur. Çift türde sayının kesinliği 15 anlamlı rakama kadar doğrudur.
Bu nedenle, gerçek veri türünü "daha doğru" hale getirmemiz gerekiyor. Yukarıdaki kodda, kaydırma türünün çift tür ile değiştirilmesi gereken satırlar ///type float yorumu ile işaretlenmiştir. Aynı girdi verilerini kullanarak derlemeden sonra aşağıdakileri elde ederiz (kaynak kodlu yeni dosya - OCL_pi_double.mq5):
2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) OpenCl: gone = 12.480 sec. 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.03 03:25:23 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Çalışma zamanı, OpenCL olmadan kaynak kodunun süresini (8.783 sn) önemli ölçüde artırdı ve hatta aştı.
"Açıkça görülüyor ki, hesaplamaları yavaşlatan çift türdür", diye düşünürdünüz. Yine de, _divisor girdi parametresini 40000'den 40000000'e değiştirelim ve deneyelim:
2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) OpenCl: gone = 5.070 sec. 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) read = 40000000 elements 2012.05.03 03:26:50 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25
Doğruluğu bozmadı ve çalışma zamanı, kaydırma türüne göre biraz daha kısaldı. Ancak tüm tamsayı türlerini long'dan int'ye değiştirirsek ve önceki _divisor = 40000 değerini geri yüklersek, çekirdek çalışma zamanı yarıdan fazla azalır:
2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) OpenCl: gone = 2.262 sec. 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.16 00:22:44 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Her zaman hatırlamanız gerekir: Eğer oldukça "uzun" ama "hafif" bir döngü varsa (yani, her birinin çok fazla aritmetiği olmayan çok sayıda yinelemeden oluşan bir döngü), veri türlerinde "ağır" olanlardan (uzun tip - 8 bayt) "hafif" olanlara (int - 4 bayt) yalnızca bir değişiklik, çekirdek çalışma zamanını önemli ölçüde azaltabilir.
Şimdi kısa bir süre için programlama deneylerimizi durduralım ve ne yaptığımızı biraz anlamak için tüm bu çekirdek kodunun "bağlanması" ile ne kastedildiğine odaklanalım. Çekirdek kodu "bağlama" ile, geçici olarak OpenCL API'sini kastediyoruz, yani, çekirdeğin ana bilgisayar programıyla (bu durumda, MQL5'teki programla) iletişim kurmasına izin veren bir komutlar sistemi.
3. OpenCL API Fonksiyonları
3.1. Bir bağlam oluşturma
Aşağıda verilen bir komut, bağlam, yani OpenCL nesnelerinin ve kaynaklarının yönetimi için bir ortam yaratır.
int clCtx = CLContextCreate( _device ); İlk olarak, platform modeli hakkında birkaç söz söyleyelim.
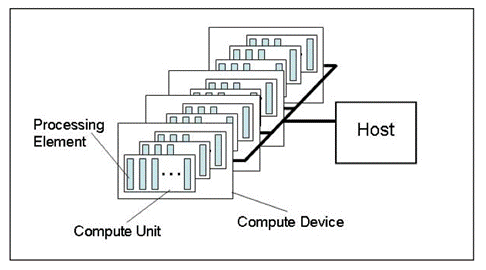
Şekil 1. Bir bilgi işlem platformu soyut modeli
Şekil, bir bilgi işlem platformunun soyut bir modelini göstermektedir. Video kartlarıyla ilgili olarak donanım yapısının çok ayrıntılı bir tasviri değildir, ancak gerçeğe oldukça yakındır ve iyi bir genel fikir verir.
Ana bilgisayar, tüm program yürütme sürecini kontrol eden ana CPU'dur. Birkaç OpenCL cihazını (Hesaplama Cihazları) tanıyabilir. Çoğu durumda, bir yatırımcının sistem biriminde hesaplamalar için bir video kartı varsa, bir video kartı bir cihaz olarak kabul edilir (çift işlemcili bir video kartı iki cihaz olarak kabul edilecektir!). Bunun yanı sıra, ana bilgisayar, yani CPU her zaman bir OpenCL cihazı olarak kabul edilir. Her cihazın platform içinde benzersiz bir numarası vardır.
Her cihazda, CPU olması durumunda х86 çekirdeğe karşılık gelen birkaç Hesaplama Birimi vardır (Intel CPU "sanal" çekirdekleri, yani Hiper-iş parçacığı aracılığıyla oluşturulan "çekirdekler" dahil); bir video kartı için bunlar SIMD Motorları, yani GPU Hesaplama makalesine göre SIMD çekirdekleri veya mini işlemciler olacaktır. AMD/ATI Radeon Mimari Özellikleri. Güçlü video kartlarında genellikle yaklaşık 20 SIMD çekirdeği bulunur.
Her SIMD çekirdeği akış işlemcileri içerir, örneğin Radeon HD 5870 video kartı her SIMD Motorunda 16 akış işlemcisine sahiptir.
Son olarak, her akış işlemcisi aynı kartta 4 veya 5 işleme elemanına, yani ALU'ya sahiptir.
Tüm büyük grafik satıcıları tarafından donanım için kullanılan terminolojinin, özellikle yeni başlayanlar için oldukça kafa karıştırıcı olduğu belirtilmelidir. OpenCL ile ilgili popüler bir forum başlığında çok yaygın olarak kullanılan "arılar" ile ne kastedildiği her zaman açık değildir. Bununla birlikte, modern video kartlarında iş parçacığı sayısı, yani eşzamanlı hesaplama iş parçacığı sayısı çok fazladır. Örneğin Radeon HD 5870 video kartındaki tahmini iş parçacığı sayısı 5 binin üzerindedir.
Aşağıdaki şekil, bu video kartının standart teknik özelliklerini göstermektedir.

Şekil 2. Radeon HD 5870 GPU özellikleri
Aşağıda daha ayrıntılı olarak belirtilen her şey (OpenCL kaynakları), mutlaka CLContextCreate() fonksiyonu tarafından oluşturulan bağlamla ilişkilendirilmelidir:
- OpenCL cihazları, yani hesaplamalarda kullanılan donanımlar;
- Program nesneleri, yani çekirdeği çalıştıran program kodu;
- Çekirdekler yani cihazlarda çalışan fonksiyonlar;
- Cihaz tarafından manipüle edilen bellek nesneleri, yani veriler (örn. arabellekler, 2D ve 3D görüntüler);
- Komut kuyrukları (terminal dilinin mevcut uygulaması, ilgili bir API sağlamaz).
Oluşturulan bağlam, aşağıda kendisine bağlı cihazlarla birlikte boş bir alan olarak gösterilebilir.
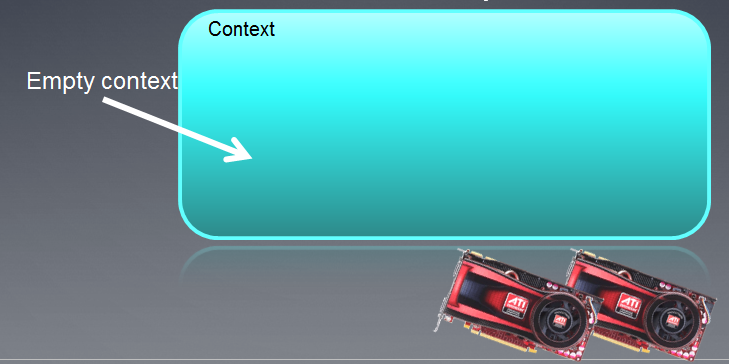
Şekil 3. OpenCL Bağlamı
Fonksiyonun yürütülmesinin ardından bağlam alanı şu anda boştur.
MQL5'teki OpenCL bağlamının yalnızca bir cihazla çalıştığına dikkat edilmelidir.
3.2. Bir program oluşturma
int clPrg = CLProgramCreate( clCtx, clSrc ); CLProgramCreate() fonksiyonu, bir "OpenCL programı" kaynağı oluşturur.
"Program" nesnesi aslında OpenCL çekirdeklerinin bir koleksiyonudur (bir sonraki maddede tartışılacaktır), ancak MetaQuotes uygulamasında, görünüşe göre OpenCL programında yalnızca bir çekirdek olabilir. "Program" nesnesini oluşturmak için, kaynak kodun (burada - clSrc) bir dizeye okunduğundan emin olmalısınız.
Bizim durumumuzda, clSrc dizesi zaten global bir değişken olarak bildirildiği için gerekli değildir:

Aşağıdaki şekil, programın daha önce oluşturulan bağlamın bir parçası olduğunu göstermektedir.

Şekil 4. Program bağlamın bir parçasıdır
Program derlenemediyse, geliştirici bağımsız olarak derleyicinin çıkışında bir veri talebi başlatmalıdır. Tam özellikli bir OpenCL API, çağrıldıktan sonra bir dizenin derleyicinin çıkışında döndürüldüğü API fonksiyonuna clGetProgramBuildInfo() sahiptir.
Mevcut sürüm (b.642), bir OpenCL geliştiricisine çekirdek kodunun doğruluğu hakkında daha fazla bilgi sağlamak için muhtemelen OpenCL API'sine dahil edilmeye değer olması gereken bu fonksiyonu desteklemez.
Cihazlardan (video kartları) gelen "diller", görünüşe göre MQL5'te API düzeyinde desteklenmeyecek olan komut kuyruklarıdır.
3.3. Bir çekirdek oluşturma
CLKernelCreate() fonksiyonu, bir OpenCL kaynağı olan "Çekirdek"i oluşturur.
int clKrn = CLKernelCreate( clPrg, "pi" );
Çekirdek, OpenCL cihazında çalışan programda bildirilen bir fonksiyondur.
Bizim durumumuzda, "pi" adındaki pi() fonksiyonudur. "Çekirdek" nesnesi, ilgili argümanlarla birlikte çekirdeğin fonksiyonudur. Bu fonksiyondaki ikinci argüman, program içindeki fonksiyon adıyla tam olarak uyumlu olması gereken fonksiyon adıdır.

Şekil 5. Çekirdek
"Çekirdek" nesneleri, çekirdek olarak bildirilen bir ve aynı fonksiyon için farklı bağımsız değişkenler ayarlarken gerektiği kadar kullanılabilir.
Şimdi CLSetKernelArg() ve CLSetKernelArgMem() fonksiyonlarına geçmeliyiz ama önce cihazların belleklerinde saklanan nesneler hakkında birkaç kelime söyleyelim.
3.4. Bellek nesneleri
Her şeyden önce, GPU'da işlenen herhangi bir "büyük" nesnenin önce GPU'nun kendi belleğinde oluşturulacağını veya ana bilgisayar belleğinden (RAM) taşınacağını anlamalıyız. "Büyük" bir nesne ile ya bir arabellek (tek boyutlu dizi) ya da iki veya üç boyutlu (2B veya 3B) olabilen bir görüntü kastedilmektedir.
Bir arabellek, ayrı bitişik arabellek öğeleri içeren geniş bir bellek alanıdır. Bunlar basit veri türleri (char, double, float, long, vb.) veya karmaşık veri türleri (yapılar, birlikler vb.) olabilir. Ayrı arabellek öğelerine doğrudan erişilebilir, okunabilir ve yazılabilir.
Özel bir veri türü olduğu için şu anda görüntülere bakmayacağız. OpenCL ile ilgili başlığın ilk sayfasında terminal geliştiricileri tarafından sağlanan kod, geliştiricilerin görüntü kullanımıyla ilgilenmediğini gösteriyor.
Tanıtılan kodda, arabelleği oluşturan fonksiyon aşağıdaki gibi görünmektedir:
int clMem = CLBufferCreate( clCtx, _divisor * sizeof( double ), CL_MEM_READ_WRITE );
İlk parametre, OpenCL arabelleğinin bir kaynak olarak ilişkilendirildiği bir bağlam tanıtıcısıdır; ikinci parametre, arabellek için ayrılan bellektir; üçüncü parametre bu nesne ile neler yapılabileceğini gösterir. Döndürülen değer, OpenCL arabelleğine (başarıyla oluşturulduysa) veya -1'e (oluşturma bir hata nedeniyle başarısız olduysa) yönelik bir tanıtıcıdır.
Bizim durumumuzda, arabellek doğrudan GPU, yani OpenCL cihazının belleğinde oluşturulmuştur. Bu fonksiyon kullanılmadan RAM'de oluşturulmuşsa, aşağıda gösterildiği gibi OpenCL cihaz belleğine (GPU) taşınmalıdır:

Şekil 6. OpenCL bellek nesneleri
OpenCL bellek nesneleri olmayan giriş/çıkış arabellekleri (görüntü olması gerekmez - Mona Lisa yalnızca örnekleme amaçlıdır!) solda gösterilmektedir. Boş, başlatılmamış OpenCL bellek nesneleri, ana bağlam alanında daha sağda görüntülenir. Başlangıçtaki "Mona Lisa" verisi daha sonra OpenCL bağlam alanına taşınacaktır ve OpenCL programından çıkan her şeyin sola, yani RAM'e taşınması gerekecektir.
OpenCL'de ana bilgisayar/OpenCL cihazından ana bilgisayar/OpenCL cihazına veri kopyalamak için kullanılan terimler aşağıdaki gibidir:
- Ana bilgisayardan cihaz belleğine veri kopyalamak yazma (CLBufferWrite() fonksiyonu) olarak adlandırılır;
- Verilerin cihaz belleğinden ana bilgisayar belleğine kopyalanmasına okuma (CLBufferRead() fonksiyonu, aşağıya bakın) denir.
Yazma komutu (ana bilgisayar -> cihaz) bir bellek nesnesini verilerle başlatır ve aynı zamanda nesneyi cihaz belleğine yerleştirir.
Cihazda bulunan bellek nesnelerinin geçerliliğinin, cihaza karşılık gelen donanımın satıcısına bağlı olduğundan OpenCL özelliklerinde belirtilmediğini unutmayın. Bu nedenle, bellek nesneleri oluştururken dikkatli olun.
Bellek nesneleri başlatıldıktan ve cihazlara yazıldıktan sonra, resim şöyle görünür:

Şekil 7. OpenCL bellek nesnelerinin başlatılmasının sonucu
Artık çekirdeğin parametrelerini ayarlayan fonksiyonlara geçebiliriz.
3.5. Çekirdeğin parametrelerini ayarlama
CLSetKernelArgMem( clKrn, 0, clMem ); CLSetKernelArgMem() fonksiyonu, daha önce oluşturulan arabelleği çekirdeğin sıfır parametresi olarak tanımlar.
Şimdi aynı parametreye çekirdek kodunda bir göz atarsak, aşağıdaki gibi göründüğünü görebiliriz:
__kernel void pi( __global float *out )
Çekirdekte, API fonksiyonu CLBufferCreate() tarafından oluşturulan ile aynı türe sahip olan out[ ] dizisidir.
Ara bellek olmayan parametreleri ayarlamak için benzer bir fonksiyon vardır:
bool CLSetKernelArg( int kernel, // handle to the kernel of the OpenCL program uint arg_index, // OpenCL function argument number void arg_value ); // function argument value
Örneğin, çekirdeğin ikinci parametresi olarak bir çift x0 ayarlamaya karar verirsek, bunun önce MQL5 programında bildirilmesi ve başlatılması gerekir:
double x0 = -2;
ve daha sonra fonksiyonun çağrılması gerekir (ayrıca MQL5 kodunda):
CLSetKernelArg( cl_krn, 1, x0 ); Yukarıdaki işlemlerin ardından, resim aşağıdaki gibi olacaktır:

Şekil 8. Çekirdeğin parametrelerinin ayarlanmasının sonuçları
3.6. Program yürütme
bool ex = CLExecute( clKrn, 1, offs, works );
Yazar, OpenCL özelliklerinde bu fonksiyonun doğrudan bir benzerini bulamamıştır. Fonksiyon, clKrn çekirdeğini verilen parametrelerle yürütür. Son parametre 'works', hesaplama görevinin her hesaplaması başına yürütülecek görev sayısını belirler. Fonksiyon SPMD (Tek Program Çoklu Veri) ilkesini gösterir: fonksiyonun bir çağrısı, works parametre değerine eşit sayıda kendi parametreleriyle çekirdek örnekleri oluşturur; bu çekirdek örnekleri, geleneksel olarak konuşursak, aynı anda ancak AMD terimleriyle farklı akış çekirdeklerinde yürütülür.
OpenCL'nin genelliği, dilin, kod yürütmede yer alan temel donanım altyapısına bağlı olmaması gerçeğinde yatmaktadır: kodlayıcı, bir OpenCL programını düzgün bir şekilde yürütmek için donanım özelliklerini bilmek zorunda değildir. Yine de yürütülecektir. Yine de kodun etkinliğini (örn. hız) artırmak için bu özelliklerin bilinmesi şiddetle tavsiye edilir.
Örneğin, bu kod, yazarın ayrı bir video kartı olmayan donanımında gayet iyi yürütülür. Bununla birlikte, yazarın tüm öykünmenin gerçekleştiği CPU'nun yapısı hakkında çok belirsiz bir fikri vardır.
Bundan dolayı, OpenCL programı nihayet çalıştırılmıştır ve artık sonuçlarını ana bilgisayar programında kullanabiliriz.
3.7. Çıkış verilerini okuma
Aşağıda, cihazdan veri okuyan ana bilgisayar programının bir parçası verilmiştir:
float buf[ ]; ArrayResize( buf, _divisor ); uint read = CLBufferRead( clMem, buf );
OpenCL'deki verileri okumanın bu verileri cihazdan ana bilgisayara kopyaladığını unutmayın. Bu üç satır bunun nasıl yapıldığını gösteriyor. Ana programdaki okuma OpenCL arabelleği ile aynı tipte buf[] arabelleğini bildirmek ve fonksiyonu çağırmak yeterli olacaktır. Ana bilgisayar programında (burada - MQL5 dilinde) oluşturulan arabellek türü, çekirdekteki arabellek türünden farklı olabilir, ancak boyutları tam olarak eşleşmelidir.
Veriler artık ana bilgisayar belleğine kopyalanmıştır ve ana programda, yani MQL5'teki programda tamamen bizim için mevcuttur.
OpenCL cihazında gerekli tüm hesaplamalar yapıldıktan sonra, bellek tüm nesnelerden arındırılmalıdır.
3.8. Tüm OpenCL nesnelerinin imhası
Bu, aşağıdaki komutlar kullanılarak yapılır:
CLBufferFree( clMem ); CLKernelFree( clKrn ); CLProgramFree( clPrg ); CLContextFree( clCtx );
Bu fonksiyonlar dizisinin temel özelliği, nesnelerin oluşturulma sırasının tersi sırayla yok edilmesi gerektiğidir.
Şimdi çekirdek kodunun kendisine hızlıca bir göz atalım.
3.9. Çekirdek
Görülebileceği gibi, tüm çekirdek kodu, birden çok dizeden oluşan tek bir uzun dizedir.
Çekirdek başlığı standart bir fonksiyona benzemektedir:
__kernel void pi( __global float *out )
Çekirdek başlığı için birkaç gereksinim vardır:
- Döndürülen bir değerin türü her zaman geçersizdir;
- __kernel belirtecinin iki alt çizgi karakteri içermesi gerekmez; kernel de olabilir;
- Bağımsız değişken bir dizi (arabellek) ise, yalnızca referans yoluyla iletilir. Bellek belirteci __global (veya global), bu arabelleğin cihazın global belleğinde depolandığı anlamına gelir.
- Basit veri türlerinin bağımsız değişkenleri değere göre iletilir.
Çekirdeğin gövdesi, C'deki standart koddan hiçbir şekilde farklı değildir.
Önemli: dize:
int i = get_global_id( 0 );
i, o hücre içindeki hesaplama sonucunu belirleyen GPU içindeki bir hesaplama hücresinin sayısı olduğu anlamına gelir. Bu sonuç, çıkış dizisine (bizim durumumuzda, out[]) yazılır, ardından diziyi GPU belleğinden CPU belleğine okuduktan sonra ana programda değerleri eklenir.
OpenCL program kodunda birden fazla fonksiyon olabileceği unutulmamalıdır. Örneğin, pi() fonksiyonunun dışında yer alan basit bir satır içi fonksiyon, "ana" çekirdek fonksiyonu pi() içinde çağrılabilir. Bu durum, daha detaylı ele alınacaktır.
Artık MetaQuotes uygulamasında OpenCL API'sini kısaca tanıdığımıza göre, denemeye devam edebiliriz. Bu makalede yazar, çalışma zamanını optimize edecek donanım ayrıntılarına derinlemesine girmeyi planlamamıştı. Şu anda ana görev, OpenCL'de bu şekilde programlama için bir başlangıç noktası sağlamaktır.
Başka bir deyişle, donanım özelliklerini dikkate almadığından kod oldukça sadedir. Aynı zamanda, herhangi bir donanımda - CPU, AMD’ye ait IGP (CPU'ya entegre GPU) veya AMD / NVidia’ya ait ayrı bir video kartı üzerinde çalıştırılabilmesi için oldukça geneldir.
Vektör veri türlerini kullanarak daha fazla denenmemiş optimizasyonu düşünmeden önce, önce bunlara aşina olmamız gerekecek.
4. Vektör Veri Türleri
Vektör veri türleri, OpenCL'ye özgü türlerdir ve onu C99'dan ayırır. Bunların arasında herhangi bir (u)charN, (u)shortN, (u)intN, (u)longN, floatN türü vardır, burada N = {2|3|4|8|16}’dır.
Bu türlerin, yerleşik derleyicinin hesaplamaları ek olarak paralelleştirmeyi başaracağını bildiğimizde (veya varsaydığımızda) kullanılması gerekir. Çekirdek kodları yalnızca N değerinde farklılık gösterse ve diğer tüm açılardan aynı olsa bile (yazar bunu kendisi görebilir), durumun her zaman böyle olmadığını unutmamalıyız.
Aşağıda yerleşik veri türlerinin listesi bulunmaktadır:

Tablo 1. OpenCL'de yerleşik vektör veri türleri
Bu türler herhangi bir cihaz tarafından desteklenir. Bu türlerin her biri, çekirdek ve ana bilgisayar programı arasındaki iletişim için karşılık gelen bir API türüne sahiptir. Bu, mevcut MQL5 uygulamasında sağlanmamıştır, ancak çok da önemli değildir.
Ek türler de vardır, ancak her cihaz tarafından desteklenmediklerinden kullanılmaları için açıkça belirtilmeleri gerekir:

Tablo 2. OpenCL'deki diğer yerleşik veri türleri
Ayrıca, OpenCL'de henüz desteklenmeyen ayrılmış veri türleri vardır. Dil özelliklerinde oldukça uzun bir liste var.
Vektör türünde bir sabit veya değişken bildirmek için basit, sezgisel kuralları izlemelisiniz.
Aşağıda birkaç örnek verilmiştir:
float4 f = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f); uint4 u = ( uint4 ) ( 1 ); /// u is converted to a vector (1, 1, 1, 1). float4 f = ( float4 ) ( ( float2 )( 1.0f, 2.0f ), ( float2 )( 3.0f, 4.0f ) ); float4 f = ( float4 ) ( 1.0f, ( float2 )( 2.0f, 3.0f ), 4.0f ); float4 f = ( float4 ) ( 1.0f, 2.0f ); /// error
Görüldüğü gibi, sağdaki veri tiplerini, sol tarafta belirtilen değişkenin (burada 4'e eşittir) "genişliği" ile bir araya getirmek yeterlidir. Tek istisna, bileşenlerin skalere eşit olduğu bir skalerin bir vektöre dönüştürülmesidir (2. satır).
Her vektör veri türü için vektör bileşenlerini adresleyen basit bir mekanizma vardır. Bir yandan bunlar vektörlerdir (diziler), diğer yandan ise bunlar yapılardır. Yani örneğin genişliği 2 olan vektörlerin ilk bileşeni (örneğin, float2 u) u.x olarak ve ikincisi u.y olarak adreslenebilir.
long3 u türünde bir vektörün üç bileşeni şöyle olacaktır: u.x, u.y, u.z.
float4 u türünde bir vektör için, bunlar buna göre, .xyzw, i.e. u.x, u.y, u.z, u.w olacaktır.
float2 pos; pos.x = 1.0f; // valid pos.z = 1.0f; // invalid because pos.z does not exist float3 pos; pos.z = 1.0f; // valid pos.w = 1.0f; // invalid because pos.w does not exist
Aynı anda birden fazla bileşen seçebilir ve hatta bunlara izin verebilirsiniz (grup gösterimi):
float4 c; c.xyzw = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); c.z = 1.0f; c.xy = ( float2 ) ( 3.0f, 4.0f ); c.xyz = ( float3 ) ( 3.0f, 4.0f, 5.0f ); float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 swiz= pos.wzyx; // swiz = ( 4.0f, 3.0f, 2.0f, 1.0f ) float4 dup = pos.xxyy; // dup = ( 1.0f, 1.0f, 2.0f, 2.0f )Bileşen grubu gösterimi, yani birkaç bileşenin belirtimi, atama ifadesinin (yani l-değeri) sol tarafında yer alabilir:
float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); pos.xw = ( float2 ) ( 5.0f, 6.0f ); // pos = ( 5.0f, 2.0f, 3.0f, 6.0f ) pos.wx = ( float2 ) ( 7.0f, 8.0f ); // pos = ( 8.0f, 2.0f, 3.0f, 7.0f ) pos.xyz = ( float3 ) ( 3.0f, 5.0f, 9.0f ); // pos = ( 3.0f, 5.0f, 9.0f, 4.0f ) pos.xx = ( float2 ) ( 3.0f, 4.0f ); // invalid as 'x' is used twice pos.xy = ( float4 ) (1.0f, 2.0f, 3.0f, 4.0f ); // mismatch between float2 and float4 float4 a, b, c, d; float16 x; x = ( float16 ) ( a, b, c, d ); x = ( float16 ) ( a.xxxx, b.xyz, c.xyz, d.xyz, a.yzw ); x = ( float16 ) ( a.xxxxxxx, b.xyz, c.xyz, d.xyz ); // invalid as the component a.xxxxxxx is not a valid vector type
Tekli bileşenlere başka bir gösterim kullanılarak erişilebilir - bir grup gösteriminde onaltılık bir basamaktan veya birkaç basamaktan önce eklenen s (veya S) harfi:

Tablo 3. Vektör veri türlerinin tek tek bileşenlerine erişmek için kullanılan dizinler
Bir vektör değişkeni f bildirirseniz
float8 f;o zaman f.s0 vektörün 1. bileşenidir ve f.s7, 8. bileşendir.
Aynı şekilde, 16 boyutlu bir x vektörü bildirirsek,
float16 x;o zaman x.sa (veya x.sA), x vektörünün 11. bileşenidir ve x.sf (veya x.sF), x vektörünün 16. bileşenine karşılık gelir.
Sayısal dizinler (.s0123456789abcdef) ve harf gösterimleri (.xyzw), bileşen grubu gösterimiyle aynı tanımlayıcıda karıştırılamaz:
float4 f, a; a = f.x12w; // invalid as numeric indices are intermixed with the letter notations .xyzw a.xyzw = f.s0123; // valid
Ve son olarak, vektör türü bileşenlerini .lo, .hi, .even, .odd kullanarak değiştirmenin başka bir yolu daha var.
Bu ekler şu şekilde kullanılır:
- .lo, belirli bir vektörün alt yarısını belirtir;
- .hi, belirli bir vektörün üst yarısını belirtir;
- .even bir vektörün tüm çift bileşenlerini ifade eder;
- .odd, bir vektörün tüm tek bileşenlerini ifade eder.
Örneğin:
float4 vf; float2 low = vf.lo; // vf.xy float2 high = vf.hi; // vf.zw float2 even = vf.even; // vf.xz float2 odd = vf.odd; // vf.yw
Bu gösterim, bir skaler (vektör olmayan veri türü) görünene kadar tekrar tekrar kullanılabilir.
float8 u = (float8) ( 1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f ); float2 s = u.lo.lo; // ( 1.0f, 2.0f ) float2 t = u.hi.lo; // ( 5.0f, 6.0f ) float2 q = u.even.lo; // ( 1.0f, 3.0f ) float r = u.odd.lo.hi; // 4.0f
3 bileşenli bir vektör türünde durum biraz daha karmaşıktır: teknik olarak, 4. bileşenin değeri tanımsız olan 4 bileşenli bir vektör türüdür.
float3 vf = (float3) (1.0f, 2.0f, 3.0f); float2 low = vf.lo; // ( 1.0f, 2.0f ); float2 high = vf.hi; // ( 3.0f, undefined );
Kısa aritmetik kuralları (+, -, *, /).
Belirtilen tüm aritmetik işlemler aynı boyuttaki vektörler için tanımlanır ve bileşen bazında yapılır.
float4 d = (float4) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 w = (float4) ( 5.0f, 8.0f, 10.0f, -1.0f ); float4 _sum = d + w; // ( 6.0f, 10.0f, 13.0f, 3.0f ) float4 _mul = d * w; // ( 5.0f, 16.0f, 30.0f, -4.0f ) float4 _div = w / d; // ( 5.0f, 4.0f, 3.333333f, -0.25f )
Bunun tek istisnası, işlenenlerden birinin skaler, diğerinin ise vektör olmasıdır. Bu durumda, skaler tür vektörde bildirilen veri türüne dönüştürülürken, skaler türün kendisi vektör işleneniyle aynı boyuta sahip bir vektöre dönüştürülür. Bunu aritmetik bir işlem izler. Aynısı ilişkisel işleçler için de geçerlidir (<, >, <=, >=).
Bu bölümün ilk tablosunda listelenen yerleşik veri türlerinden oluşabilen türetilmiş, C99 yerel veri türleri (örneğin, yapı, birleşim, diziler ve diğerleri) OpenCL dilinde de desteklenir.
Ve son olarak: Kesin hesaplamalar için GPU kullanmak istiyorsanız, kaçınılmaz olarak çift veri türünü ve dolayısıyla doubleN'yi kullanmanız gerekecektir.
Bunun için satırı:
#pragma OPENCL EXTENSION cl_khr_fp64 : enable çekirdek kodunun başına eklemeniz yeterlidir.
Bu bilgi, aşağıdakilerin çoğunu anlamak için zaten yeterli olmalıdır. Herhangi bir sorunuz varsa lütfen OpenCL 1.1 Özelliklerine bakın.
5. Vektör Veri Türleriyle Çekirdeğin Uygulanması
Dürüst olmak gerekirse, yazar, vektör veri türleri ile ilk bakışta bir kod yazmayı başaramadı.
Başlangıçta yazar, çekirdek içinde bir vektör veri türü, örneğin double8 bildirilir bildirilmez her şeyin kendi kendine çalışacağını düşünerek dil özelliklerini okumaya fazla dikkat etmedi. Ayrıca, yazarın yalnızca bir çıktı dizisini bir double8 vektör dizisi olarak bildirme girişimi de başarısız olmuştur.
Çekirdeği etkili bir şekilde vektörleştirmek ve gerçek ivmeyi elde etmek için bunun kesinlikle yeterli olmadığını anlamak biraz zaman aldı. Verilerin sadece hızlı bir şekilde giriş ve çıkışı değil, aynı zamanda hızlı bir şekilde hesaplanmasını gerektirdiğinden, vektör dizisindeki sonuçların çıktısı alınarak sorun çözülmeyecektir. Bu gerçeğin farkına varılması süreci hızlandırdı ve verimliliğini artırdı ve sonunda çok daha hızlı bir kod geliştirmeyi mümkün kıldı.
Ama bundan daha fazlası var. Yukarıda belirtilen çekirdek kodundan neredeyse körü körüne hata ayıklanabilirken, vektör verilerinin kullanımı nedeniyle hataları aramak artık oldukça zor hale gelmiştir. Bu standart mesajdan hangi yapıcı bilgileri alabiliriz:
ERR_OPENCL_INVALID_HANDLE - invalid handle to the OpenCL program
ya da bu
ERR_OPENCL_KERNEL_CREATE - internal error while creating an OpenCL object
?
Bu nedenle, yazar SDK'ya başvurmak zorunda kaldı. Bu durumda, yazara sunulan donanım yapılandırması göz önüne alındığında, Intel OpenCL SDK'da sağlanan Intel OpenCL SDK Çevrimdışı Derleyicisi (32 bit) olmuştur (Intel dışındaki CPU'lar/GPU'lar için SDK ayrıca ilgili çevrimdışı derleyicileri içermelidir). Ana bilgisayar API'sine bağlanmadan çekirdek kodunda hata ayıklamaya izin verdiği için uygundur.
Çekirdek kodunu, MQL5 kodunda kullanılan biçimde olmasa da, bunun yerine harici tırnak işaretleri ve "\r\n" (satır başı karakterleri) olmadan derleyici penceresine eklemeniz ve üzerinde bir dişli çark simgesi olan Derleme düğmesine basmanız yeterlidir.
Bunu yaparken, Derleme Günlüğü penceresi, Derleme süreci ve ilerlemesi hakkında bilgi görüntüler:
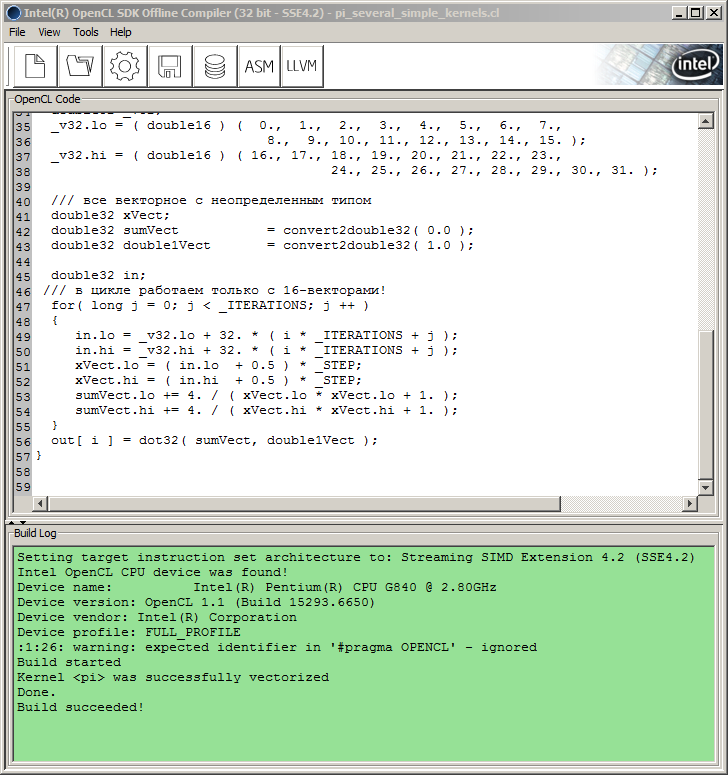
Şekil 9. Intel OpenCL SDK Çevrimdışı Derleyicisinde program derlemesi
Çekirdek kodunu tırnak işareti olmadan elde etmek için, ana bilgisayar dilinde (MQL5), çekirdek kodunu bir dosyaya çıkaracak basit bir program yazmak faydalı olacaktır - WriteCLProgram(). Artık ana program koduna dahil edilmiştir.
Derleyicinin mesajları her zaman çok net değildir ancak şu anda MQL5'in sağlayabileceğinden çok daha fazla bilgi sağlarlar. Hatalar derleyici penceresinde hemen düzeltilebilir ve daha fazla hata olmadığından emin olduğunuzda, düzeltmeler MetaEditor'daki çekirdek koduna aktarılabilir.
Ve son bir şey. Yazarın ilk fikri, tek bir global parametre "kanal sayısı" ayarlayarak double4, double8 ve double16 vektörleriyle çalışabilen vektörleştirilmiş bir kod geliştirmekti. Bu, birkaç gün sonra, bir nedenden dolayı çekirdek kodu içinde çalışmayı reddeden belirteç yapıştırma işleci ## ile zor zamanlar geçirdikten sonra gerçekleştirildi.
Bu süre zarfında yazar, her biri boyutuna uygun olan 4, 8 veya 16 olmak üzere üç çekirdek koduyla komut dosyasının çalışan bir kodunu başarıyla geliştirdi. Bu ara koda makalede yer verilmeyecek ancak çok fazla sorun yaşamadan bir çekirdek kodu yazmak isteyebileceğinizden bahsetmekte fayda var. Bu komut dosyası uygulamasının kodu (OCL_pi_double_several_simple_kernels.mq5), aşağıda makalenin sonuna eklenmiştir.
Ve işte vektörleştirilmiş çekirdeğin kodu:
"/// enable extensions with doubles \r\n" "#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _intrnCnt ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" "#define _CH " + i2s( _ch ) + " \r\n" "#define _DOUBLETYPE double" + i2s( _ch ) + " \r\n" " \r\n" "/// extensions for 4-, 8- and 16- scalar products \r\n" "#define dot4( a, b ) dot( a, b ) \r\n" " \r\n" "inline double dot8( double8 a, double8 b ) \r\n" "{ \r\n" " return dot4( a.lo, b.lo ) + dot4( a.hi, b.hi ); \r\n" "} \r\n" " \r\n" "inline double dot16( double16 a, double16 b ) \r\n" "{ \r\n" " double16 c = a * b; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot4( c.lo.lo + c.lo.hi + c.hi.lo + c.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double16 v16 = ( double16 ) ( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ); \r\n" " double8 v8 = v16.lo; \r\n" " double4 v4 = v16.lo.lo; \r\n" " double2 v2 = v16.lo.lo.lo; \r\n" " \r\n" " /// all vector-related with the calculated type \r\n" " _DOUBLETYPE in; \r\n" " _DOUBLETYPE xVect; \r\n" " _DOUBLETYPE sumVect = ( _DOUBLETYPE ) ( 0.0 ); \r\n" " _DOUBLETYPE doubleOneVect = ( _DOUBLETYPE ) ( 1.0 ); \r\n" " _DOUBLETYPE doubleCHVect = ( _DOUBLETYPE ) ( _CH + 0. ); \r\n" " _DOUBLETYPE doubleSTEPVect = ( _DOUBLETYPE ) ( _STEP ); \r\n" " \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in = v" + i2s( _ch ) + " + doubleCHVect * ( i * _ITERATIONS + j ); \r\n" " xVect = ( in + 0.5 ) * doubleSTEPVect; \r\n" " sumVect += 4.0 / ( xVect * xVect + 1. ); \r\n" " } \r\n" " out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n" "} \r\n";
Harici ana bilgisayar programı, "vektörleştirme kanallarının" sayısını ayarlayan yeni global sabit _ch ve _ch kat daha küçük hale gelen global sabit _intrnCnt dışında pek değişmedi. Bu nedenle yazar, ana bilgisayar program kodunu burada göstermemeye karar verdi. Makalenin sonunda eklenmiş olan komut dosyasında (OCL_pi_double_parallel_straight.mq5) bulunabilir.
Görülebileceği gibi, çekirdeğin pi() "ana" fonksiyonundan ayrı olarak, dotN( a, b ) vektörlerinin skaler çarpımını belirleyen iki satır içi fonksiyonumuz ve bir makro alternatifimiz var. Bu fonksiyonlar, OpenCL'deki dot() fonksiyonunun, boyutu 4'ü geçmeyen vektörlerle ilgili olarak tanımlanması nedeniyle dahil edilir.
dot() fonksiyonunu yeniden tanımlayan dot4() makrosu, yalnızca dotN() fonksiyonunu hesaplanan adla çağırmanın rahatlığı için vardır:
" out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n"
dot() fonksiyonunu dizin 4 olmadan her zamanki biçiminde kullansaydık, _ch = 4 olduğunda (vektörizasyon kanallarının sayısı 4'e eşit olduğunda) onu burada gösterildiği gibi kolayca çağıramayacaktık.
Bu satır, çekirdeğin ana bilgisayar programında bir dize olarak ele alınması sayesinde spesifik çekirdek formunun başka bir yararlı özelliğini gösterir: Çekirdekte hesaplanmış tanımlayıcıları yalnızca fonksiyonlar için değil, aynı zamanda veri türleri için de kullanabiliriz!
Bu çekirdeğe sahip ana bilgisayar program kodunun tamamı aşağıda eklenmiştir (OCL_pi_double_parallel_straight.mq5).
Komut dosyasını "genişlik" vektörü 16 ( _ch = 16 ) olacak şekilde çalıştırarak aşağıdakileri elde ederiz:
2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) ================================================== 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) CPUtime / GPUtime = 4.130 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The time to calculate PI was 8.830 seconds 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The value of PI is 3.141592653590 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The time to calculate PI was 8.002 seconds 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The value of PI is 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: gone = 2.138 sec. 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: pi = 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) read = 20000 elements 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) CLProgramCreate: unknown error. 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) ==================================================
Vektör veri türlerini kullanan optimizasyonun bile çekirdeği daha hızlı yapmadığını görebilirsiniz.
Ancak aynı kodu GPU üzerinde çalıştırırsanız, hız kazancı çok daha büyük olacaktır.
MetaDriver (video kartı - HIS Radeon HD 6930, CPU - AMD Phenom II x6 1100T) tarafından sağlanan bilgilere göre aynı kod aşağıdaki sonuçları verir:
2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) ================================================== 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) CPUtime / GPUtime = 84.983 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The time to calculate PI was 14.617 seconds 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The value of PI is 3.141592653590 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The time to calculate PI was 14.040 seconds 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The value of PI is 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: gone = 0.172 sec. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) read = 20000 elements 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) CLProgramCreate: unknown error. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) ==================================================
6. Bitirici Dokunuş
İşte başka bir çekirdek (buraya eklenen OCL_pi_double_several_simple_kernels.mq5 dosyasında bulunabilir, ancak burada gösterilmemiştir).
Komut dosyası, yazarın "tek" bir çekirdek yazma girişimini geçici olarak terk ettiğinde ve farklı vektör boyutları (4, 8, 16, 32) için dört basit çekirdek yazmayı düşündüğünde sahip olduğu fikrin bir uygulamasıdır:
"#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _itInKern ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" " \r\n" "typedef struct \r\n" "{ \r\n" " double16 lo; \r\n" " double16 hi; \r\n" "} double32; \r\n" " \r\n" "inline double32 convert2double32( double a ) \r\n" "{ \r\n" " double32 b; \r\n" " b.lo = ( double16 )( a ); \r\n" " b.hi = ( double16 )( a ); \r\n" " return b; \r\n" "} \r\n" " \r\n" "inline double dot32( double32 a, double32 b ) \r\n" "{ \r\n" " double32 c; \r\n" " c.lo = a.lo * b.lo; \r\n" " c.hi = a.hi * b.hi; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot( c.lo.lo.lo + c.lo.lo.hi + c.lo.hi.lo + c.lo.hi.hi + \r\n" " c.hi.lo.lo + c.hi.lo.hi + c.hi.hi.lo + c.hi.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double32 _v32; \r\n" " _v32.lo = ( double16 ) ( 0., 1., 2., 3., 4., 5., 6., 7., \r\n" " 8., 9., 10., 11., 12., 13., 14., 15. ); \r\n" " _v32.hi = ( double16 ) ( 16., 17., 18., 19., 20., 21., 22., 23., \r\n" " 24., 25., 26., 27., 28., 29., 30., 31. ); \r\n" " \r\n" " /// all vector-related with undefined type \r\n" " double32 xVect; \r\n" " double32 sumVect = convert2double32( 0.0 ); \r\n" " double32 double1Vect = convert2double32( 1.0 ); \r\n" " \r\n" " double32 in; \r\n" " /// work only with 16-vectors in the loop! \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in.lo = _v32.lo + 32. * ( i * _ITERATIONS + j ); \r\n" " in.hi = _v32.hi + 32. * ( i * _ITERATIONS + j ); \r\n" " xVect.lo = ( in.lo + 0.5 ) * _STEP; \r\n" " xVect.hi = ( in.hi + 0.5 ) * _STEP; \r\n" " sumVect.lo += 4. / ( xVect.lo * xVect.lo + 1. ); \r\n" " sumVect.hi += 4. / ( xVect.hi * xVect.hi + 1. ); \r\n" " } \r\n" " out[ i ] = dot32( sumVect, double1Vect ); \r\n" "} \r\n";
Bu çekirdek, vektör boyutu 32'yi uygular. Yeni vektör türü ve birkaç gerekli satır içi fonksiyon, çekirdeğin ana fonksiyonunun dışında tanımlanır. Bunun yanı sıra (ve bu önemlidir!), ana döngü içindeki tüm hesaplamalar kasıtlı olarak yalnızca standart vektör veri türleri ile yapılır; standart olmayan türler döngünün dışında işlenir. Bu, kod yürütme süresini önemli ölçüde hızlandırmaya izin verir.
Hesaplamamızda, bu çekirdek 16 genişliğindeki vektörler için kullanıldığından daha yavaş görünmüyor, ancak çok daha hızlı da değil.
MetaDriver tarafından sağlanan bilgilere göre, bu çekirdeğe (_ch=32) sahip olan komut dosyası aşağıdaki sonuçları verir:
2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: gone = 0.156 sec. 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) read = 10000 elements 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) CLProgramCreate: unknown error or no error. 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) GetLastError returned .. 0 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _itInKern = 3125; vectorization channels - 32 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) =================================================================
Özet ve Sonuçlar
Yazar, OpenCL kaynaklarının gösterilmesi için seçilen görevin bu dil için pek tipik olmadığını gayet iyi anlamaktadır.
Bir ders kitabı alıp büyük matrislerin standart bir çarpım örneğini buraya yerleştirmek çok daha kolay olurdu. Bu örnek açıkça etkileyici olurdu. Ancak, büyük matrislerin çarpılmasını gerektiren finansal hesaplamalarla uğraşan birçok mql5.com forum kullanıcısı var mı? Oldukça şüpheli. Yazar kendi örneğini seçip yolda karşılaştığı tüm zorlukları tek başına aşmak isterken bir yandan da tecrübesini başkalarıyla paylaşmaya çalışıyor. Tabi ki yargılayacak olan sizsiniz sayın forum kullanıcıları.
OpenCL öykünmesinde ("çıplak" CPU'da) verimlilik artışının, MetaDriver'ın komut dosyaları kullanılarak elde edilen yüzlerce ve hatta binlercesi ile karşılaştırıldığında oldukça küçük olduğu ortaya çıktı. Ancak yeterli bir GPU'da, CPU AMD ile CPU'da biraz daha uzun bir çalışma zamanını göz ardı etsek bile, öykünmeden en az bir büyüklük sırası daha büyük olacaktır. Hesaplama hızındaki kazanç sadece bu kadar büyük olsa bile OpenCL hala öğrenmeye değer!
Yazarın bir sonraki makalesinin, OpenCL soyut modellerini gerçek donanım üzerinde görüntülemenin özellikleriyle ilgili sorunları ele alması bekleniyor. Bu şeylerin bilgisi bazen hesaplamaları önemli ölçüde hızlandırmaya izin verir.
Yazar, çok değerli programlama ve performans optimizasyon ipuçları için MetaDriver'a ve Intel OpenCL SDK'yı kullanma imkanı için Destek Ekibine özel teşekkürlerini ifade etmek istiyor.
Ekli dosyaların içeriği:
- pi.mq5 - "pi" değerini hesaplamanın iki yolunu içeren saf MQL5'te bir komut dosyası;
- OCl_pi_float.mq5 - kayan tipte gerçek hesaplamaları içeren komut dosyasının OpenCL çekirdeği ile ilk uygulaması;
- OCL_pi_double.mq5 - aynı şekilde, yalnızca çift tipli gerçek hesaplamaları içerir;
- OCL_pi_double_several_simple_kernels.mq5 - çeşitli vektör "genişlikleri" (4, 8, 16, 32) için birkaç spesifik çekirdeğe sahip bir komut dosyası;
- OCL_pi_double_parallel_straight.mq5 - bazı vektör "genişlikleri" (4, 8, 16) için tek bir çekirdeğe sahip bir komut dosyası.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/405
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

 En Aktif MQL5.community Üyelerine iPhone Ödülü Verildi!
En Aktif MQL5.community Üyelerine iPhone Ödülü Verildi!
 MQL5 Market Neden Alım Satım Stratejileri ve Teknik Göstergeleri Satmak İçin En İyi Yer?
MQL5 Market Neden Alım Satım Stratejileri ve Teknik Göstergeleri Satmak İçin En İyi Yer?
 Otomatik Alım Satım Sistemleri Oluşturmada Yeni Bir Yaklaşım Olarak Otomat Tabanlı Programlama
Otomatik Alım Satım Sistemleri Oluşturmada Yeni Bir Yaklaşım Olarak Otomat Tabanlı Programlama
 MetaTrader 5 ve MQL5 ile Sınırsız Fırsatlar
MetaTrader 5 ve MQL5 ile Sınırsız Fırsatlar
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
OpenCL: A Bridge to a Parallel World adlı yeni makale yayımlandı:
Sceptic Philozoff tarafından
OpenCL desteği çok iyi bir seçimdir, şimdi ve gelecekte bilgi işlem platformunun heterojenliği çok açıktır, ancak şimdi OpenCL kullanma koşulları altında aynı algoritmalar CUDA performansından çok daha düşüktür, belki de OpenCL'den daha fazla CUDA daha temeldir, kendi GPU'su için daha iyi optimize edilmiştir. NVIDIA'nın GPU'ları daha iyi performansa, daha iyi ivmeye sahiptir ve CUDA derleyicisi LLVM'yi benimsemiştir. NVIDIA'nın GPU performansı daha iyi, geliştirme ivmesi daha iyi ve CUDA derleyicisi LLVM'yi benimsedi, CUDA'yı destekleyecek daha fazla dil olacak, Python artık destekleyebilir, özellikle programlamada CUDA6.0 kullanım kolaylığı daha belirgindir, özellikle Birleşik Bellek teknolojisi, gelecekte, otomatik veri geçişi için CUDA çalışma zamanı desteği daha iyidir, programın performansı ve programlama verimliliği daha iyi olacaktır. OpenCL için MQL5 desteği iyi bir başlangıçtır ve gelecekte CUDA üzerinde yapılabilecek bazı şeyler olabilir.
Yazar veya uzmanlar cevaplasın lütfen:
Aşağıdaki kod nerede daha hızlı çalışacak ana taşta mı yoksa vidicon'da mı ? Ve herhangi bir ayrıntı var mı ?
void OnStart()
{
long total= 1000000000;
for(long i=0;i<total;i++)
for(long q=0;q<total;q++)
for(long w=0;w<total;w++)
for(long e=0;e<total;e++)
for(long r=0;r<total;r++)
for(long t=0;t<total;t++)
for(long y=0;y<total;y++)
for(long u=0;u<total;u++)
func(i,q,w,e,r,t,y,u);
}
Örneğin :
Pi = 4*atan(1);
veya
Pi = acos(-1);
PI değerini 12 ondalıkta elde etmek için 7 saniyeden fazla sürenin en yüksek verimlilik olduğunu sanmıyorum.
Python ve Makine Öğrenimi için OpenCV'yi duymuştum, ticaret gibi son derece psikolojik bir alanda bile işe yarayabilir ama OpenCL'i hiç duymadım. Bu gerekçelerle, bugün ZeroMQ olan güzel bir arayüz ortamı var. Sanırım MTx platformu ve Python ortamı arasındaki iletişim, özellikle geçmesi gereken çok fazla veri varsa biraz zaman alabilir.
Makale için gerçekten teşekkürler.