
OpenCL: il ponte verso mondi paralleli

Introduzione
Questo articolo è il primo di una breve serie di pubblicazioni sulla programmazione in OpenCL, o Open Computing Language. La piattaforma MetaTrader 5 nella sua forma attuale, prima di fornire supporto per OpenCL, non permetteva di utilizzare direttamente, cioè nativamente, e godere dei vantaggi dei processori multi-core per velocizzare i calcoli.
Ovviamente, gli sviluppatori potrebbero ripetere all'infinito che il terminale è multithread e che "ogni EA/ script viene eseguito in un thread separato". Tuttavia, al programmatore non è stata data l'opportunità di un'esecuzione parallela relativamente semplice del seguente ciclo semplice (questo è un codice per calcolare il valore pi = 3,14159265...):
long num_steps = 1000000000; double step = 1.0 / num_steps; double x, pi, sum = 0.0; for (long i = 0; i<num_steps; i++) { x = (i + 0.5)*step; sum += 4.0/(1.0 + x*x); } pi = sum*step;
Tuttavia, già 18 mesi fa, nella sezione "Articoli" è apparso un lavoro molto interessante intitolato "Calcoli paralleli su MetaTrader 5". Eppure... si ha l'impressione che, nonostante l'ingegnosità dell'approccio, sia in qualche modo innaturale: un'intera gerarchia di programmi (l'Expert Advisor e due indicatori) scritta per accelerare i calcoli nel ciclo di cui sopra sarebbe stata davvero una buona cosa.
Sappiamo già che non ci sono piani per supportare OpenMP e siamo consapevoli del fatto che l'aggiunta di OMP richiede una drastica riprogrammazione del compilatore. Ahimè, non ci sarà una soluzione economica e facile per un programmatore in cui non è necessario pensare.
L'annuncio del supporto nativo per OpenCL in МQL5 è stata quindi una notizia molto gradita. A partire dalla pagina 22 dello stesso thread di notizie, MetaDriver ha iniziato a pubblicare script che consentono di valutare la differenza tra l'implementazione su CPU e GPU. OpenCL ha suscitato un enorme interesse.
L'autore di questo articolo ha inizialmente rinunciato al processo: una configurazione del computer di fascia abbastanza bassa (Pentium G840/8 Gb DDR-III 1333/Nessuna scheda video) non sembrava fornire un uso efficace di OpenCL.
Tuttavia, in seguito all'installazione di AMD APP SDK, un software specializzato sviluppato da AMD, il primo script proposto da MetaDriver, il quale era stato eseguito da altri solo se era disponibile una scheda video discreta, è stato eseguito con successo sul computer dell'autore e ha dimostrato un aumento di velocità tutt'altro che insignificante rispetto a un runtime di script standard su un core del processore, essendo circa 25 volte più veloce. Successivamente, l'accelerazione dello stesso runtime di script ha raggiunto 75, grazie alla corretta installazione di Intel OpenCL Runtime con l'aiuto del team di supporto.
Dopo aver studiato attentamente il forum e i materiali forniti da ixbt.com, l'autore ha scoperto che l'Integrated Graphics Processor (IGP) di Intel supporta OpenCL 1.1 solo a partire dai processori Ivy Bridge in poi. Di conseguenza, l'accelerazione ottenuta sul PC con la configurazione di cui sopra non potrebbe avere nulla a che fare con IGP e il codice del programma OpenCL, in questo caso particolare, è stato eseguito solo su CPU core х86.
Quando l'autore ha condiviso le cifre dell'accelerazione con gli esperti di ixbt, questi hanno risposto immediatamente e tutto d’un tratto che tutto questo era il risultato di una sostanziale sotto-ottimizzazione del linguaggio di partenza (MQL5). Nella community dei professionisti di OpenCL è risaputo che una corretta ottimizzazione di un codice sorgente in С++ (ovviamente, previo utilizzo di un processore multi-core e istruzioni vettoriali SSEx) può al suo meglio tradursi in un guadagno di diverse dozzine percento sull'emulazione OpenCL; nel peggiore dei casi, puoi persino perdere, ad esempio a causa della spesa (di tempo) estremamente elevata durante il passaggio dei dati.
Quindi - un'altra ipotesi: le cifre di accelerazione "miracolose" su MetaTrader 5 sulla pura emulazione OpenCL devono essere trattate adeguatamente senza essere attribuite alla "freddezza" di OpenCL stesso. Un vantaggio davvero forte della GPU su un programma ben ottimizzato in С++ può essere ottenuto solo utilizzando una scheda video discreta abbastanza potente, poiché le sue capacità di calcolo in alcuni algoritmi sono ben oltre le capacità di qualsiasi CPU moderna.
Gli sviluppatori del terminale affermano che non è stato ancora adeguatamente ottimizzato. Hanno anche lasciato un suggerimento sul grado di accelerazione che sarà n certo numero di volte superiore dopo l'ottimizzazione. Tutte le cifre di accelerazione in OpenCL saranno di conseguenza ridotte dello stesso "numero di volte". Tuttavia, saranno ancora considerevolmente maggiori dell'unità.
È un buon motivo per imparare il linguaggio OpenCL (anche se la tua scheda video non supporta OpenCL 1.1 o semplicemente manca), con il quale procederemo. Ma prima lasciami dire alcune parole sulla base essenziale: il software che supporta Open CL e l'hardware appropriato.
1. Software e hardware essenziali
1.1.AMD
Il software appropriato è prodotto da AMD, Intel e NVidia, i membri del consorzio industriale senza scopo di lucro - il gruppo che sviluppa specifiche linguistiche diverse in relazione ai calcoli in ambienti eterogenei.
Alcuni materiali utili possono essere trovati nel sito ufficiale del Gruppo Khronos, ad esempio:
Questi documenti dovranno essere usati abbastanza spesso nel processo di apprendimento di OpenCL poiché il terminale non offre ancora informazioni di aiuto su OpenCL (c'è solo un breve riassunto dell'API OpenCL). Tutte e tre le società (AMD, Intel e NVidia) sono fornitori di hardware video e ognuna di esse ha la propria implementazione OpenCL Runtime e i rispettivi kit di sviluppo software - SDK. Entriamo nelle peculiarità della scelta delle schede video, prendendo come esempio i prodotti AMD.
Se la tua scheda video AMD non è molto vecchia (rilasciata per la prima volta in produzione nel 2009-2010 o successivamente), sarà abbastanza semplice: un aggiornamento del driver della tua scheda video dovrebbe essere sufficiente per iniziare subito a lavorare. Un elenco di schede video compatibili con OpenCL è disponibile qui. D'altra parte, anche una scheda video abbastanza buona per i suoi tempi, come la Radeon HD 4850 (4870), non ti risparmierà il problema quando hai a che fare con OpenCL.
Se non hai ancora una scheda video AMD, ma hai voglia di prenderne una, dai un'occhiata prima alle sue specifiche. Qui puoi vedere una tabella delle specifiche delle schede video AMD abbastanza completa. I più importanti per noi sono i seguenti:
- Memoria integrata: la quantità di memoria locale. Più è grande, meglio è. 1 GB di solito è sufficiente.
- Core Clock — frequenza del core operativo. È anche chiaro: maggiore è la frequenza operativa dei multiprocessori GPU, meglio è. 650-700 MHz non è affatto male.
- [Memoria] Tipo — tipo di memoria video. La memoria dovrebbe essere idealmente veloce, cioè GDDR5. Ma anche GDDR3 va bene, anche se è circa il doppio in termini di larghezza di banda della memoria.
- [Memory] Clock (Eff.) - frequenza operativa (effettiva) della memoria video. Tecnicamente, questo parametro è strettamente correlato al precedente. La frequenza operativa effettiva di GDDR5 è in media doppia rispetto alla frequenza di GDDR3. Non ha nulla a che fare con il fatto che i tipi di memoria "più alti" funzionano su frequenze più alte, ma è dovuto al numero di canali di trasferimento dati utilizzati dalla memoria. In altre parole, ha a che fare con la larghezza di banda della memoria.
- [Memoria] Bus - larghezza bus dati. Si consiglia almeno 256 bit.
- MBW — Larghezza di banda della memoria. Questo parametro è in realtà una combinazione di tutti e tre i parametri della memoria video sopra. Più è alto, meglio è.
- Config Core (SPU:TMU(TF):ROP) — configurazione delle unità core GPU. Ciò che è importante per noi, cioè per i calcoli non grafici, è il primo numero. 1024:64:32 dichiarato significherebbe che abbiamo bisogno del numero 1024 (il numero di processori di streaming o shader unificati). Ovviamente più è alto, meglio è.
- Potenza di elaborazione: prestazioni teoriche nei calcoli in virgola mobile (FP32 (Single Precision) / FP64 (Double Precision). Mentre le tabelle delle specifiche contengono sempre un valore corrispondente a FP32 (tutte le schede video possono gestire calcoli a precisione singola), questo è ben lungi dall'essere il caso di FP64, poiché la doppia precisione non è supportata da tutte le schede video. Se sei sicuro che non avrai mai bisogno della doppia precisione (doppio tipo) nei calcoli GPU, puoi ignorare il secondo parametro. Ma in ogni caso, più alto è questo parametro, meglio è.
- TDP — Potenza di progettazione termica. Questa è, grosso modo, la potenza massima che la scheda video dissipa nei calcoli più difficili. Se il tuo Expert Advisor accederà frequentemente alla GPU, la scheda video non solo consumerà molta energia (il che non è male se ripaga), ma sarà anche piuttosto rumorosa.
Ora, il secondo caso: non c'è una scheda video o la scheda video esistente non supporta OpenCL 1.1, ma hai un processore AMD. Qui puoi scaricare AMD APP SDK che, oltre al runtime, contiene anche SDK, Kernel Analyzer e Profiler. Dopo l'installazione di AMD APP SDK, il processore dovrebbe essere riconosciuto come un dispositivo OpenCL. E sarai in grado di sviluppare applicazioni OpenCL complete in modalità di emulazione sulla CPU.
La caratteristica chiave di SDK, al contrario di AMD, è che è anche compatibile con i processori Intel (sebbene durante lo sviluppo su CPU Intel, l'SDK nativo sia ancora significativamente più efficiente in quanto è in grado di supportare SSE4.1, SSE4.2 e il set di istruzioni AVX, diventati disponibili solo di recente sui processori AMD).
1.2. Intel
Prima di iniziare a lavorare sui processori Intel, è consigliabile scaricare Intel OpenCL SDK/Runtime.
Dobbiamo sottolineare quanto segue:
- Se intendi sviluppare applicazioni OpenCL utilizzando solo CPU (modalità di emulazione OpenCL), dovresti sapere che il kernel grafico della CPU Intel non supporta OpenCL 1.1 per processori precedenti e che includono Sandy Bridge. Questo supporto è disponibile solo con i processori Ivy Bridge, ma difficilmente farà alcuna differenza anche per l'ultra potente unità grafica integrata Intel HD 4000. Per i processori più vecchi di Ivy Bridge, ciò significherebbe che l'accelerazione ottenuta nell'ambiente MQL5 è dovuta solo alle istruzioni vettoriali SS(S)Ex utilizzate. Eppure sembra anche essere significativo.
- Dopo l'installazione di Intel OpenCL SDK, è necessario modificare la voce di registro HKEY_LOCAL_MACHINE\SOFTWARE\Khronos\OpenCL\Vendors come segue: sostituire IntelOpenCL64.dll nella colonna Nome con intelocl.dll. Quindi riavvia e avvia MetaTrader 5. La CPU è ora riconosciuta come dispositivo OpenCL 1.1.
Ad essere onesti, il problema relativo al supporto OpenCL di Intel non è stato ancora completamente risolto, quindi dovremmo aspettarci alcuni chiarimenti dagli sviluppatori del terminale in futuro. Fondamentalmente, il punto è che nessuno starà a guardare gli errori del codice del kernel (il kernel OpenCL è un programma eseguito su GPU) per te - non si tratta del compilatore MQL5. Il compilatore prenderà semplicemente un'intera grande riga del kernel e cercherà di eseguirlo. Se, ad esempio, non hai dichiarato una variabile interna х utilizzata nel kernel, il kernel verrà comunque tecnicamente eseguito, anche se con errori.
Tuttavia, tutti gli errori che si otterranno nel terminale si riducono a meno di una dozzina di quelli descritti nella Guida sull'API OpenCL per le funzioni CLKernelCreate() e CLProgramCreate(). La sintassi del linguaggio è molto simile a quella di C, arricchita con funzioni vettoriali e tipi di dati (infatti questo linguaggio è C99, adottato come standard ANSI С nel 1999).
L'autore di questo articolo utilizza Intel OpenCL SDK Offline Compiler per eseguire il debug del codice per OpenCL; è molto più conveniente che cercare alla cieca gli errori del kernel in MetaEditor. Speriamo che in futuro la situazione cambi in meglio.
1.3. NVidia
Sfortunatamente, l'autore non ha cercato informazioni su questo argomento. Le raccomandazioni generali rimangono comunque le stesse. I driver per le nuove schede video NVidia supportano automaticamente OpenCL.
Fondamentalmente, l'autore dell'articolo non ha nulla contro le schede video NVidia, ma la conclusione tratta in base alle conoscenze acquisite dalla ricerca di informazioni e discussioni sui forum è la seguente: per i calcoli non grafici, le schede video AMD sembrano essere più ottimali in termini di rapporto prezzo/prestazioni rispetto alle schede video NVidia.
Passiamo ora alla programmazione.
2. Il primo programma MQL5 che utilizza OpenCL
Per poter sviluppare il nostro primo programma molto semplice, dobbiamo definire l'attività in quanto tale. Deve essere diventata consuetudine nei corsi di programmazione parallela utilizzare il calcolo del valore pi, approssimativamente uguale a 3,14159265, come esempio.
A tale scopo viene utilizzata la seguente formula (l'autore non si è mai imbattuto in questa particolare formula prima, ma sembra essere vera):

Vogliamo calcolare il valore con una precisione di 12 cifre decimali. Fondamentalmente, tale precisione può essere ottenuta con circa 1 milione di iterazioni, ma questo numero non ci consentirà di valutare il vantaggio dei calcoli in OpenCL poiché la durata dei calcoli su GPU diventa troppo breve.
I corsi di programmazione GPGPU suggeriscono di selezionare la quantità di calcoli in modo che la durata dell'attività GPU sia di almeno 20 millisecondi. Nel nostro caso, questo limite deve essere più alto a causa di un errore significativo della funzione GetTickCount(), paragonabile a 100 ms.
Di seguito è riportato il programma MQL5 in cui è implementato questo calcolo:
//+------------------------------------------------------------------+ //| pi.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" long _num_steps = 1000000000; long _divisor = 40000; double _step = 1.0 / _num_steps; long _intrnCnt = _num_steps / _divisor; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { uint start,stop; double x,pi,sum=0.0; start=GetTickCount(); //--- first option - direct calculation for(long i=0; i<_num_steps; i++) { x=(i+0.5)*_step; sum+=4.0/(1.+x*x); } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); //--- calculate using the second option start=GetTickCount(); sum=0.; long divisor=40000; long internalCnt=_num_steps/divisor; double partsum=0.; for(long i=0; i<divisor; i++) { partsum=0.; for(long j=i*internalCnt; j<(i+1)*internalCnt; j++) { x=(j+0.5)*_step; partsum+=4.0/(1.+x*x); } sum+=partsum; } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); Print("_______________________________________________"); return(0); } //+------------------------------------------------------------------+Dopo aver compilato ed eseguito questo script, otteniamo:
2012.05.03 02:02:23 pi (EURUSD,H1) The time to calculate PI was 8.783 seconds 2012.05.03 02:02:23 pi (EURUSD,H1) The value of PI is 3.141592653590 2012.05.03 02:02:15 pi (EURUSD,H1) The time to calculate PI was 7.940 seconds 2012.05.03 02:02:15 pi (EURUSD,H1) The value of PI is 3.141592653590
Il valore pi ~ 3,14159265 viene calcolato in due modi leggermente diversi.
Il primo può essere considerato quasi un metodo classico per la dimostrazione delle capacità delle librerie multi-threading come OpenMP, Intel TPP, Intel MKL e altre.
Il secondo è lo stesso calcolo sotto forma di doppio anello. L'intero calcolo costituito da 1 miliardo di iterazioni è suddiviso in grandi blocchi del ciclo esterno (ce ne sono 40000 lì) in cui ogni blocco esegue 25000 iterazioni "di base" che costituiscono il ciclo interno.
Puoi vedere che questo calcolo viene eseguito un po' più lentamente, del 10-15%. Ma è questo particolare calcolo che useremo come base durante la conversione in OpenCL. Il motivo principale è la selezione del kernel (l'attività di elaborazione di base eseguita sulla GPU), il quale effettuerebbe un ragionevole compromesso tra il tempo impiegato per il trasferimento dei dati da un'area di memoria a un'altra e i calcoli in quanto tali eseguiti nel kernel. Quindi, in termini dell'attività corrente, il kernel sarà, grosso modo, il ciclo interno del secondo algoritmo di calcolo.
Calcoliamo ora il valore utilizzando OpenCL. Un codice programma completo sarà seguito da brevi commenti sulle funzioni caratteristiche del linguaggio dell’host (MQL5) che si legano a OpenCL. Ma, prima, vorrei evidenziare alcuni punti relativi ai tipici "ostacoli" che potrebbero interferire con la codifica in OpenCL:
- Il kernel non vede le variabili dichiarate al di fuori del kernel. Ecco perché le variabili globali _step e _intrnCnt dovevano essere dichiarate di nuovo all'inizio del codice del kernel (vedi sotto). E i loro rispettivi valori dovevano essere trasformati in stringhe per essere letti correttamente nel codice del kernel. Tuttavia, questa peculiarità della programmazione in OpenCL si è rivelata molto utile in seguito, ad esempio quando si creano tipi di dati vettoriali che sono nativamente assenti da C.
- Cerca di dare il maggior numero di calcoli possibile al kernel mantenendo il loro numero ragionevole. Ciò non è molto critico per questo codice poiché il kernel non è molto veloce in questo codice sull'hardware esistente. Ma questo fattore ti aiuterà ad accelerare i calcoli se viene utilizzata una potente scheda video discreta.
Quindi, ecco il codice dello script con il kernel OpenCL:
//+------------------------------------------------------------------+ //| OCL_pi_float.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs; input int _device=0; /// OpenCL device number (0, I have CPU) #define _num_steps 1000000000 #define _divisor 40000 #define _step 1.0 / _num_steps #define _intrnCnt _num_steps / _divisor string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(int arg) { return IntegerToString(arg); } const string clSrc= "#define _step "+d2s(_step,12)+" \r\n" "#define _intrnCnt "+i2s(_intrnCnt)+" \r\n" " \r\n" "__kernel void pi( __global float *out ) \r\n" // type float "{ \r\n" " int i = get_global_id( 0 ); \r\n" " float partsum = 0.0; \r\n" // type float " float x = 0.0; \r\n" // type float " long from = i * _intrnCnt; \r\n" " long to = from + _intrnCnt; \r\n" " for( long j = from; j < to; j ++ ) \r\n" " { \r\n" " x = ( j + 0.5 ) * _step; \r\n" " partsum += 4.0 / ( 1. + x * x ); \r\n" " } \r\n" " out[ i ] = partsum; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { Print("FLOAT: _step = "+d2s(_step,12)+"; _intrnCnt = "+i2s(_intrnCnt)); int clCtx=CLContextCreate(_device); int clPrg = CLProgramCreate( clCtx, clSrc ); int clKrn = CLKernelCreate( clPrg, "pi" ); uint st=GetTickCount(); int clMem=CLBufferCreate(clCtx,_divisor*sizeof(float),CL_MEM_READ_WRITE); // type float CLSetKernelArgMem(clKrn,0,clMem); const uint offs[ 1 ] = { 0 }; const uint works[ 1 ] = { _divisor }; bool ex=CLExecute(clKrn,1,offs,works); //--- Print( "CL program executed: " + ex ); float buf[]; // type float ArrayResize(buf,_divisor); uint read=CLBufferRead(clMem,buf); Print("read = "+i2s(read)+" elements"); float sum=0.0; // type float for(int cnt=0; cnt<_divisor; cnt++) sum+=buf[cnt]; float pi=float(sum*_step); // type float Print("pi = "+d2s(pi,12)); CLBufferFree(clMem); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); double gone=(GetTickCount()-st)/1000.; Print("OpenCl: gone = "+d2s(gone,3)+" sec."); Print("________________________"); return(0); } //+------------------------------------------------------------------+
Una spiegazione più dettagliata del codice dello script verrà data un po' più avanti.
Nel frattempo, compila e avvia il programma per ottenere quanto segue:
2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) ________________________ 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) OpenCl: gone = 5.538 sec. 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) pi = 3.141622066498 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) read = 40000 elements 2012.05.03 02:20:15 OCl_pi_float (EURUSD,H1) FLOAT: _step = 0.000000001000; _intrnCnt = 25000
Come si può vedere, l'autonomia è leggermente ridotta. Ma questo non basta a renderci felici: il valore di pi ~ 3,14159265 è ovviamente preciso solo fino alla 3° cifra dopo la virgola. Tale rugosità dei calcoli è dovuta al fatto che nei calcoli reali il kernel utilizza numeri di tipo float la cui accuratezza è nettamente inferiore alla precisione richiesta precisa fino a 12 cifre decimali.
Secondo la documentazione MQL5, la precisione di un numero di tipo float è accurata solo fino a 7 cifre significative. Mentre la precisione di un numero di tipo doppio è accurata fino a 15 cifre significative.
Pertanto, dobbiamo rendere il tipo di dati reale "più accurato". Nel codice sopra, le righe in cui il tipo float deve essere sostituito con il tipo double sono contrassegnate con il commento ///type float. Dopo la compilazione, utilizzando gli stessi dati di input, otteniamo quanto segue (nuovo file con il codice sorgente - OCL_pi_double.mq5):
2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) OpenCl: gone = 12.480 sec. 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.03 03:25:23 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Il runtime è notevolmente aumentato e ha persino superato il tempo del codice sorgente senza OpenCL (8.783 sec).
"E' chiaramente il tipo doppio che rallenta i calcoli",- penserete. Eppure sperimentiamo e modifichiamo sostanzialmente il parametro di input _divisor da 40000 a 4000000:
2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) OpenCl: gone = 5.070 sec. 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) read = 40000000 elements 2012.05.03 03:26:50 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25
Non ha compromesso la precisione e il tempo di esecuzione è diventato anche leggermente più breve rispetto al caso con il tipo a galleggiante. Ma se cambiamo semplicemente tutti i tipi interi da long a int e ripristiniamo il valore precedente di _divisor = 40000, il runtime del kernel diminuirà di oltre la metà:
2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) OpenCl: gone = 2.262 sec. 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.16 00:22:44 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Devi sempre ricordare: se c'è un ciclo abbastanza "lungo", ma "leggero" (cioè un ciclo composto da molte iterazioni ognuna delle quali non ha molta aritmetica), un semplice cambiamento nei tipi di dati da quelli "pesanti" (tipo lungo - 8 byte) a quelli "leggeri" (int - 4 byte) possono ridurre drasticamente il runtime del kernel.
Fermiamo ora i nostri esperimenti di programmazione per un breve periodo e concentriamoci sul significato dell'intero "binding" del codice del kernel per capire cosa stiamo facendo. Per codice kernel "binding" si intende provvisoriamente OpenCL API, cioè un sistema di comandi che permette al kernel di comunicare con il programma host (in questo caso, con il programma in MQL5).
3. Funzioni API OpenCL
3.1. Creare un contesto
Un comando riportato di seguito crea un contesto, ovvero un ambiente per la gestione di oggetti e risorse OpenCL.
int clCtx = CLContextCreate( _device ); Innanzitutto, alcune parole sul modello della piattaforma.
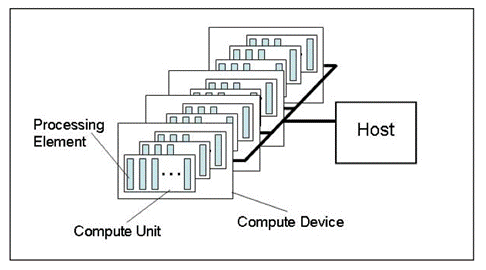
Fig.1. Modello astratto di una piattaforma informatica
La figura mostra un modello astratto di una piattaforma informatica. Non è una rappresentazione molto dettagliata della struttura dell'hardware in relazione alle schede video, ma è abbastanza vicina alla realtà e dà una buona idea generale.
L'host è la CPU principale che controlla l'intero processo di esecuzione del programma. Può riconoscere alcuni dispositivi OpenCL (Compute Devices). Nella maggior parte dei casi, quando un trader ha una scheda video per i calcoli disponibile nell'unità di sistema, una scheda video è considerata un dispositivo (una scheda video a doppio processore sarà considerata come due dispositivi!). Oltre a ciò, l'host di per sé, ovvero la CPU, è sempre considerato come un dispositivo OpenCL. Ogni dispositivo ha il suo numero univoco all'interno della piattaforma.
In ogni dispositivo sono presenti diverse Compute Unit che, se con CPU, corrispondono a х86 core (compresi i core "virtuali" della CPU Intel, ovvero "core" creati tramite Hyper-threading); per una scheda video, questi sarebbero i motori SIMD, ovvero i core SIMD o i mini-processori, nei termini dell’articolo GPU Computing. Caratteristiche architetturali AMD/ATI Radeon. Le potenti schede video hanno in genere circa 20 core SIMD.
Ogni core SIMD contiene stream processor, ad esempio la scheda video Radeon HD 5870 ha 16 stream processor in ogni SIMD Engine.
Infine, ogni stream processor ha 4 o 5 elementi di elaborazione, cioè ALU, nella stessa scheda.
Va notato che la terminologia utilizzata da tutti i principali fornitori di grafica per l'hardware è piuttosto confusa, specialmente per i principianti. Non è sempre ovvio cosa si intende per "api", così comunemente usato in un popolare thread del forum su OpenCL. Tuttavia, il numero di thread nelle schede video moderne, cioè thread simultanei di calcoli, è molto grande. Ad esempio, il numero stimato di thread nella scheda video Radeon HD 5870 è superiore a 5 mila.
La figura seguente mostra le specifiche tecniche standard di questa scheda video.

Fig.2. Caratteristiche della GPU Radeon HD 5870
Tutto quanto specificato più avanti (risorse OpenCL) deve essere necessariamente associato al contesto creato dalla funzione CLContextCreate():
- dispositivi OpenCL, ovvero hardware utilizzato nei calcoli;
- Oggetti programma, ovvero codice del programma che esegue il kernel;
- Kernel, cioè funzioni eseguite sui dispositivi;
- Oggetti di memoria, ovvero dati (es. buffer, immagini 2D e 3D) manipolati dal dispositivo;
- Code di comando (l'attuale implementazione del linguaggio del terminale non prevede una rispettiva API).
Il contesto creato può essere illustrato come un campo vuoto con dei dispositivi ad esso collegati di seguito.
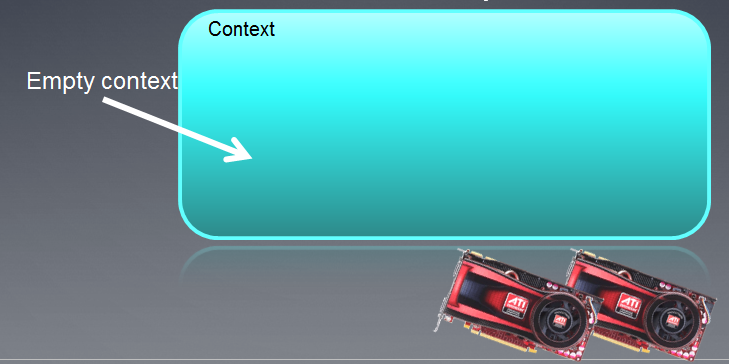
Fig.3. OPENCL_CONTEXT
Dopo l'esecuzione della funzione, il campo del contesto è attualmente vuoto.
Va notato che il contesto OpenCL in MQL5 funziona con un solo dispositivo.
3.2. Creare un progetto
int clPrg = CLProgramCreate( clCtx, clSrc ); La funzione CLProgramCreate() crea una risorsa "Programma OpenCL".
L'oggetto "Programma" è in effetti una raccolta di kernel OpenCL (che verranno discussi nella prossima clausola) ma, nell'implementazione di MetaQuotes, apparentemente può esserci solo un kernel nel programma OpenCL. Per creare l'oggetto "Programma", devi assicurarti che il codice sorgente (qui - clSrc) sia letto in una stringa.
Nel nostro caso non è necessario in quanto la stringa clSrc è già stata dichiarata come variabile globale:

La figura seguente mostra il programma come parte del contesto creato in precedenza.

Fig.4. Il programma fa parte del contesto
Se il programma non è stato compilato, lo sviluppatore deve avviare autonomamente una richiesta di dati all'output del compilatore. Un’API OpenCL completa ha la funzione API clGetProgramBuildInfo() e, dopo averla chiamata, viene restituita una stringa nell'output del compilatore.
La versione corrente (b.642) non supporta questa funzione, la quale, probabilmente, deve valere la pena di essere inclusa nell'API OpenCL per fornire a uno sviluppatore OpenCL maggiori informazioni sulla correttezza del codice del kernel.
Le "lingue" provenienti dai dispositivi (schede video) sono code di comandi che apparentemente non saranno supportate in MQL5 a livello di API.
3.3. Creare un kernel
La funzione CLKernelCreate() crea una risorsa OpenCL "Kernel".
int clKrn = CLKernelCreate( clPrg, "pi" );
Il kernel è una funzione dichiarata nel programma che viene eseguito sul dispositivo OpenCL.
Nel nostro caso, è la funzione pi() con il nome "pi". L'oggetto "kernel" è la funzione del kernel insieme ai rispettivi argomenti. Il secondo argomento in questa funzione è il nome della funzione che dovrebbe corrispondere esattamente al nome della funzione all'interno del programma.

Fig.5. Kernel
Gli oggetti "kernel" possono essere usati tutte le volte che è necessario quando si impostano argomenti diversi per una stessa funzione dichiarata come kernel.
Dobbiamo ora passare alle funzioni CLSetKernelArg() e CLSetKernelArgMem(), ma diciamo prima qualche parola sugli oggetti immagazzinati nella memoria dei dispositivi.
3.4. Oggetti di memoria
Prima di tutto, dobbiamo capire che qualsiasi oggetto "grande" elaborato su GPU deve essere prima creato nella memoria della GPU stessa o spostato dalla memoria host (RAM). Per oggetto "grande" intendiamo o un buffer (array unidimensionale) o un'immagine che può essere bi o tridimensionale (2D o 3D).
Un buffer è un'ampia area di memoria contenente elementi buffer adiacenti separati. Questi possono essere tipi di dati semplici (char, double, float, long, ecc.) o tipi di dati complessi (strutture, unioni, ecc.). È possibile accedere direttamente, leggere e scrivere a elementi buffer separati.
Al momento non esamineremo le immagini in quanto si tratta di un tipo di dati peculiare. Il codice fornito dagli sviluppatori del terminale nella prima pagina del thread su OpenCL suggerisce che gli sviluppatori non si sono impegnati nell'uso delle immagini.
Nel codice introdotto, la funzione che crea il buffer sembra essere la seguente:
int clMem = CLBufferCreate( clCtx, _divisor * sizeof( double ), CL_MEM_READ_WRITE );
Il primo parametro è un handle di contesto a cui il buffer OpenCL è associato come risorsa; il secondo parametro è la memoria allocata per il buffer; il terzo parametro mostra cosa si può fare con questo oggetto. Il valore restituito è un handle per il buffer OpenCL (se creato correttamente) o -1 (se la creazione non è riuscita a causa di un errore).
Nel nostro caso, il buffer è stato creato direttamente nella memoria della GPU, cioè del dispositivo OpenCL. Se è stato creato in RAM senza utilizzare questa funzione, deve essere spostato nella memoria del dispositivo OpenCL (GPU) come illustrato di seguito:

Fig.6. Oggetti di memoria OpenCL
I buffer di input/output (non necessariamente immagini - la Gioconda è qui solo a scopo illustrativo!), che non sono oggetti di memoria OpenCL, sono mostrati a sinistra. Gli oggetti di memoria OpenCL vuoti e non inizializzati vengono visualizzati più a destra, nel campo del contesto principale. I dati iniziali della "Gioconda" verranno successivamente spostati nel campo di contesto OpenCL e tutto ciò che viene emesso dal programma OpenCL dovrà essere spostato di nuovo a sinistra, cioè nella RAM.
I termini utilizzati in OpenCL per la copia dei dati da/nell'host/dispositivo OpenCL sono i seguenti:
- La copia dei dati dall'host nella memoria del dispositivo è chiamata scrittura (funzione CLBufferWrite());
- La copia dei dati dalla memoria del dispositivo alla memoria dell'host è chiamata lettura (funzione CLBufferRead(), vedi di seguito).
Il comando di scrittura (host -> dispositivo) inizializza un oggetto di memoria tramite dati e allo stesso tempo colloca l'oggetto nella memoria del dispositivo.
Tieni presente che la validità degli oggetti di memoria disponibili nel dispositivo non è specificata nella specifica OpenCL poiché dipende dal fornitore dell'hardware corrispondente al dispositivo. Pertanto, presta attenzione durante la creazione di oggetti di memoria.
Dopo che gli oggetti di memoria sono stati inizializzati e scritti sui dispositivi, l'immagine sembra essere qualcosa del genere:

Fig.7. Risultato dell'inizializzazione degli oggetti di memoria OpenCL
Ora possiamo procedere alle funzioni che impostano i parametri del kernel.
3.5. Impostazione dei parametri del kernel
CLSetKernelArgMem( clKrn, 0, clMem ); La funzione CLSetKernelArgMem() definisce il buffer creato in precedenza come parametro zero del kernel.
Se ora diamo un'occhiata allo stesso parametro nel codice del kernel, possiamo vedere che appare come segue:
__kernel void pi( __global float *out )
Nel kernel, è l'array out[ ] che ha lo stesso tipo di quello creato dalla funzione API CLBufferCreate().
Esiste una funzione simile per impostare i parametri non buffer:
bool CLSetKernelArg( int kernel, // handle to the kernel of the OpenCL program uint arg_index, // OpenCL function argument number void arg_value ); // function argument value
Se, ad esempio, decidessimo di impostare un double x0 come secondo parametro del kernel, bisognerebbe prima dichiararlo e inizializzarlo nel programma MQL5:
double x0 = -2;
e poi sarà necessario chiamare la funzione (anche nel codice MQL5):
CLSetKernelArg( cl_krn, 1, x0 ); A seguito delle manipolazioni di cui sopra, l'immagine sarà la seguente:

Fig.8. Risultati dell'impostazione dei parametri del kernel
3.6. Esecuzione del programma
bool ex = CLExecute( clKrn, 1, offs, works );
L'autore non ha trovato un analogo diretto di questa funzione nella specifica OpenCL. La funzione esegue il kernel clKrn con i parametri indicati. L'ultimo parametro 'works' imposta il numero di compiti da eseguire per ogni calcolo del compito di calcolo. La funzione dimostra il principio SPMD (Single Program Multiple Data): una chiamata della funzione crea istanze del kernel con i propri parametri nel numero uguale al valore del parametro di lavoro; queste istanze del kernel sono, convenzionalmente parlando, eseguite simultaneamente, a su diversi stream core in termini AMD.
La generalità di OpenCL consiste nel fatto che il linguaggio non è vincolato all'infrastruttura hardware sottostante coinvolta nell'esecuzione del codice: il programmatore non deve conoscere le specifiche hardware per eseguire correttamente un programma OpenCL. Sarà comunque eseguito. Eppure è fortemente consigliabile conoscere queste specifiche per migliorare l'efficienza del codice (es. velocità).
Ad esempio, questo codice viene eseguito correttamente sull'hardware dell'autore privo di una scheda video discreta. Detto questo, l'autore ha un'idea molto vaga della struttura della CPU stessa dove avviene l'intera emulazione.
Quindi, il programma OpenCL è stato finalmente eseguito e ora possiamo utilizzare i suoi risultati nel programma host.
3.7. Lettura dei dati in uscita
Di seguito è riportato un frammento del programma host che legge i dati dal dispositivo:
float buf[ ]; ArrayResize( buf, _divisor ); uint read = CLBufferRead( clMem, buf );
Ricorda che la lettura dei dati in OpenCL sta copiando questi dati dal dispositivo nell'host. Queste tre righe mostrano come si fa. Sarà sufficiente dichiarare il buffer buf[] dello stesso tipo del buffer OpenCL letto nel programma principale e chiamare la funzione. Il tipo di buffer creato nel programma host (qui - nel linguaggio MQL5) può essere diverso dal tipo di buffer nel kernel,ma le loro dimensioni devono corrispondere esattamente.
I dati sono stati ora copiati nella memoria host e sono completamente a nostra disposizione all'interno del programma principale, ovvero il programma in MQL5.
Dopo aver eseguito tutti i calcoli richiesti sul dispositivo OpenCL, la memoria dovrebbe essere liberata da tutti gli oggetti.
3.8. Distruzione di tutti gli oggetti OpenCL
Questo viene fatto usando i seguenti comandi:
CLBufferFree( clMem ); CLKernelFree( clKrn ); CLProgramFree( clPrg ); CLContextFree( clCtx );
La principale particolarità di queste serie di funzioni è che gli oggetti devono essere distrutti nell'ordine inverso rispetto all'ordine in cui sono stati creati.
Diamo ora una rapida occhiata al codice del kernel stesso.
3.9. Kernel
Come si può vedere, l'intero codice del kernel è un'unica lunga stringa composta da più stringhe.
L'intestazione del kernel sembra una funzione standard:
__kernel void pi( __global float *out )
Ci sono alcuni requisiti per l'intestazione del kernel:
- Il tipo di un valore restituito è sempre void;
- L'identificatore __kernel non deve includere due caratteri di sottolineatura; può anche essere kernel;
- Se un argomento è un array (buffer), viene passato solo per riferimento. L'identificatore di memoria __global (o globale) indica che questo buffer è archiviato nella memoria globale del dispositivo.
- Gli argomenti dei tipi di dati semplici vengono passati per valore.
Il corpo del kernel non è in alcun modo diverso dal codice standard in C.
Importante: la stringa:
int i = get_global_id( 0 );
significa che i è un numero di una cella di calcolo all'interno della GPU che determina il risultato del calcolo all'interno di quella cella. Questo risultato viene ulteriormente scritto nell'array di output (nel nostro caso, out[]) dopo di che i suoi valori vengono sommati nel programma host dopo aver letto l'array dalla memoria della GPU alla memoria della CPU.
Va notato che potrebbe esserci più di una funzione nel codice del programma OpenCL. Ad esempio, una semplice funzione in linea situata all'esterno della funzione pi() può essere chiamata all'interno della funzione kernel "main" pi(). Questo caso sarà considerato ulteriormente.
Ora che abbiamo familiarizzato brevemente con l'API OpenCL nell'implementazione di MetaQuotes, possiamo continuare a sperimentare. In questo articolo, l'autore non aveva intenzione di approfondire i dettagli dell'hardware che consentissero di ottimizzare al massimo il runtime. Il compito principale al momento è fornire un punto di partenza per la programmazione in OpenCL in quanto tale.
In altre parole, il codice è piuttosto semplice in quanto non tiene conto delle specifiche hardware. Allo stesso tempo, è abbastanza generico in modo che possa essere eseguito su qualsiasi hardware: CPU, IGP di AMD (GPU integrata nella CPU) o una scheda video discreta di AMD / NVidia.
Prima di considerare ulteriori ottimizzazioni semplici che utilizzano tipi di dati vettoriali, dovremo prima familiarizzare con essi.
4. Tipi di dati vettoriali
I tipi di dati vettoriali sono i tipi specifici di OpenCL, che lo distinguono da C99. Tra questi ci sono tutti i tipi di (u)charN, (u)shortN, (u)intN, (u)longN, floatN, dove N = {2|3|4|8|16}.
Questi tipi devono essere utilizzati quando sappiamo (o presumiamo) che il compilatore integrato riuscirà a parallelizzare ulteriormente i calcoli. Dobbiamo qui notare che questo non è sempre il caso, anche se i codici del kernel differiscono solo per il valore di N e sono identici sotto tutti gli altri aspetti (l'autore potrebbe vederlo da solo).
Di seguito è riportato l'elenco dei tipi di dati incorporati:

Tabella 1. Tipi di dati vettoriali integrati in OpenCL
Questi tipi sono supportati da qualsiasi dispositivo. Ciascuno di questi tipi ha un tipo corrispondente di API per la comunicazione tra il kernel e il programma host. Questo non è previsto nell'attuale implementazione MQL5, ma non è un grosso problema.
Esistono anche altri tipi, ma devono essere specificati esplicitamente per poter essere utilizzati in quanto non sono supportati da tutti i dispositivi:

Tabella 2. Altri tipi di dati incorporati in OpenCL
Inoltre, esistono tipi di dati riservati che devono ancora essere supportati in OpenCL. C'è un elenco piuttosto lungo nelle specifiche della lingua.
Per dichiarare una costante o una variabile di tipo vettoriale è necessario seguire regole semplici e intuitive.
Alcuni esempi sono riportati di seguito:
float4 f = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f); uint4 u = ( uint4 ) ( 1 ); /// u is converted to a vector (1, 1, 1, 1). float4 f = ( float4 ) ( ( float2 )( 1.0f, 2.0f ), ( float2 )( 3.0f, 4.0f ) ); float4 f = ( float4 ) ( 1.0f, ( float2 )( 2.0f, 3.0f ), 4.0f ); float4 f = ( float4 ) ( 1.0f, 2.0f ); /// error
Come si vede è sufficiente far corrispondere i tipi di dati a destra, accostati, con la "larghezza" della variabile dichiarata a sinistra (qui è uguale a 4). L'unica eccezione è la conversione di uno scalare in un vettore con le componenti uguali allo scalare (riga 2).
Esiste un meccanismo semplice per indirizzare i componenti vettoriali per ogni tipo di dati vettoriali. Da un lato sono vettori (array), dall'altro sono strutture. Quindi, ad esempio, la prima componente di vettori di larghezza 2 (es. float2 u) può essere indirizzata come u.x e la seconda come u.y
Le tre componenti per un vettore di tipo long3 u saranno: u.x, u.y, u.z.
Per un vettore di tipo float4 u, questi saranno, di conseguenza, .xyzw, i.e. u.x, u.y, u.z, u.w.
float2 pos; pos.x = 1.0f; // valid pos.z = 1.0f; // invalid because pos.z does not exist float3 pos; pos.z = 1.0f; // valid pos.w = 1.0f; // invalid because pos.w does not exist
Puoi selezionare più componenti contemporaneamente e persino permutarli (notazione di gruppo):
float4 c; c.xyzw = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); c.z = 1.0f; c.xy = ( float2 ) ( 3.0f, 4.0f ); c.xyz = ( float3 ) ( 3.0f, 4.0f, 5.0f ); float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 swiz= pos.wzyx; // swiz = ( 4.0f, 3.0f, 2.0f, 1.0f ) float4 dup = pos.xxyy; // dup = ( 1.0f, 1.0f, 2.0f, 2.0f )La notazione del gruppo di componenti, cioè la specifica di più componenti, può verificarsi sul lato sinistro dell'istruzione di assegnazione (cioè l-value):
float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); pos.xw = ( float2 ) ( 5.0f, 6.0f ); // pos = ( 5.0f, 2.0f, 3.0f, 6.0f ) pos.wx = ( float2 ) ( 7.0f, 8.0f ); // pos = ( 8.0f, 2.0f, 3.0f, 7.0f ) pos.xyz = ( float3 ) ( 3.0f, 5.0f, 9.0f ); // pos = ( 3.0f, 5.0f, 9.0f, 4.0f ) pos.xx = ( float2 ) ( 3.0f, 4.0f ); // invalid as 'x' is used twice pos.xy = ( float4 ) (1.0f, 2.0f, 3.0f, 4.0f ); // mismatch between float2 and float4 float4 a, b, c, d; float16 x; x = ( float16 ) ( a, b, c, d ); x = ( float16 ) ( a.xxxx, b.xyz, c.xyz, d.xyz, a.yzw ); x = ( float16 ) ( a.xxxxxxx, b.xyz, c.xyz, d.xyz ); // invalid as the component a.xxxxxxx is not a valid vector type
È possibile accedere ai singoli componenti utilizzando un'altra notazione: la lettera s (o S) che viene inserita prima di una cifra esadecimale o più cifre in una notazione di gruppo:

Tabella 3. Indici utilizzati per accedere ai singoli componenti dei tipi di dati vettoriali
Se dichiari una variabile vettoriale f,
float8 f;allora f.s0 è la prima componente del vettore e f.s7 è l'ottava componente.
Allo stesso modo, se dichiariamo un vettore a 16 dimensioni x,
float16 x;allora x.sa (o x.sA) è l'undicesima componente del vettore x e x.sf (o x.sF) si riferisce alla sedicesima componente del vettore x.
Gli indici numerici (.s0123456789abcdef) e le notazioni di lettere (.xyzw) non possono essere mescolati nello stesso identificatore con la notazione del gruppo di componenti:
float4 f, a; a = f.x12w; // invalid as numeric indices are intermixed with the letter notations .xyzw a.xyzw = f.s0123; // valid
E, infine, c'è ancora un altro modo per manipolare i componenti di tipo vettoriale usando .lo, .hi, .even, .odd.
Questi suffissi sono usati come segue:
- .lo si riferisce alla metà inferiore di un dato vettore;
- .hi si riferisce alla metà superiore di un dato vettore;
- .even si riferisce a tutti i componenti pari di un vettore;
- .odd si riferisce a tutte le componenti dispari di un vettore.
Per esempio:
float4 vf; float2 low = vf.lo; // vf.xy float2 high = vf.hi; // vf.zw float2 even = vf.even; // vf.xz float2 odd = vf.odd; // vf.yw
Questa notazione può essere usata ripetutamente finché non appare uno scalare (tipo di dati non vettoriale).
float8 u = (float8) ( 1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f ); float2 s = u.lo.lo; // ( 1.0f, 2.0f ) float2 t = u.hi.lo; // ( 5.0f, 6.0f ) float2 q = u.even.lo; // ( 1.0f, 3.0f ) float r = u.odd.lo.hi; // 4.0f
La situazione è leggermente più complicata in un tipo di vettore a 3 componenti: tecnicamente si tratta di un tipo di vettore a 4 componenti con il valore del 4° componente indefinito.
float3 vf = (float3) (1.0f, 2.0f, 3.0f); float2 low = vf.lo; // ( 1.0f, 2.0f ); float2 high = vf.hi; // ( 3.0f, undefined );
Brevi regole di aritmetica (+, -, *, /).
Tutte le operazioni aritmetiche specificate sono definite per vettori della stessa dimensione e vengono eseguite per componente.
float4 d = (float4) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 w = (float4) ( 5.0f, 8.0f, 10.0f, -1.0f ); float4 _sum = d + w; // ( 6.0f, 10.0f, 13.0f, 3.0f ) float4 _mul = d * w; // ( 5.0f, 16.0f, 30.0f, -4.0f ) float4 _div = w / d; // ( 5.0f, 4.0f, 3.333333f, -0.25f )
L'unica eccezione è quando uno degli operandi è uno scalare e l'altro è un vettore. In questo caso, il tipo scalare viene convertito al tipo di dati dichiarato nel vettore, mentre lo scalare stesso viene convertito in un vettore con la stessa dimensione dell'operando vettoriale. Segue un'operazione aritmetica. Lo stesso vale per gli operatori relazionali (<, >, <=, >=).
Nel linguaggio OpenCL sono supportati anche i tipi di dati derivati nativi C99 (ad esempio, struct, union, array e altri) che possono essere costituiti dai tipi di dati incorporati elencati nella prima tabella di questa sezione.
Ultima cosa: se vuoi usare GPU per calcoli esatti, dovrai inevitabilmente usare il tipo di dati double e di conseguenza doubleN.
A tal fine, basta inserire la riga:
#pragma OPENCL EXTENSION cl_khr_fp64 : enable all'inizio del codice del kernel.
Queste informazioni dovrebbero essere già sufficienti per capire molto di ciò che segue. In caso di domande, consulta le specifiche OpenCL 1.1.
5. Implementazione del kernel con tipi di dati vettoriali
Ad essere onesti, l'autore non è riuscito a scrivere un codice funzionante con tipi di dati vettoriali a mano libera.
All'inizio l'autore non ha prestato molta attenzione alla lettura delle specifiche del linguaggio, pensando che tutto avrebbe funzionato da solo non appena un tipo di dati vettoriali, ad esempio double8, sarebbe stato dichiarato all'interno del kernel. Inoltre, anche il tentativo dell'autore di dichiarare un solo array di output come un array di vettori double8 è fallito.
Ci è voluto un po' per rendersi conto che questo non è assolutamente sufficiente per vettorizzare efficacemente il kernel e ottenere una vera accelerazione. Il problema non verrà risolto emettendo risultati nell'array vettoriale poiché i dati non richiedono solo di essere immessi e emessi rapidamente, ma anche calcolati rapidamente. La realizzazione di questo fatto ha accelerato il processo e ne ha aumentato l'efficienza rendendo possibile sviluppare finalmente un codice molto più veloce.
Ma c'è dell'altro. Mentre il codice del kernel sopra esposto potrebbe essere sottoposto a debug quasi alla cieca, la ricerca di errori è diventata piuttosto difficile a causa dell'uso di dati vettoriali. Quali informazioni costruttive possiamo ottenere da questo messaggio standard:
ERR_OPENCL_INVALID_HANDLE - invalid handle to the OpenCL program
o questo
ERR_OPENCL_KERNEL_CREATE - internal error while creating an OpenCL object
?
Pertanto, l'autore ha dovuto ricorrere a SDK. In questo caso, data la configurazione hardware a disposizione dell'autore, si trattava di Intel OpenCL SDK Offline Compiler (32 bit) fornito in Intel OpenCL SDK (per CPU/GPU diverse da Intel, SDK deve contenere anche i compilatori offline rilevanti). È conveniente perché consente di eseguire il debug del codice del kernel senza vincolarsi all'API host.
È sufficiente inserire il codice del kernel nella finestra del compilatore, anche se non nella forma utilizzata all'interno del codice MQL5, ma senza virgolette esterne e "\r\n" (caratteri di ritorno a capo) e premere il pulsante Build con l'icona di una ruota dentata accesa esso.
Così facendo, la finestra Build Log visualizzerà le informazioni sul processo di Build e il suo avanzamento:
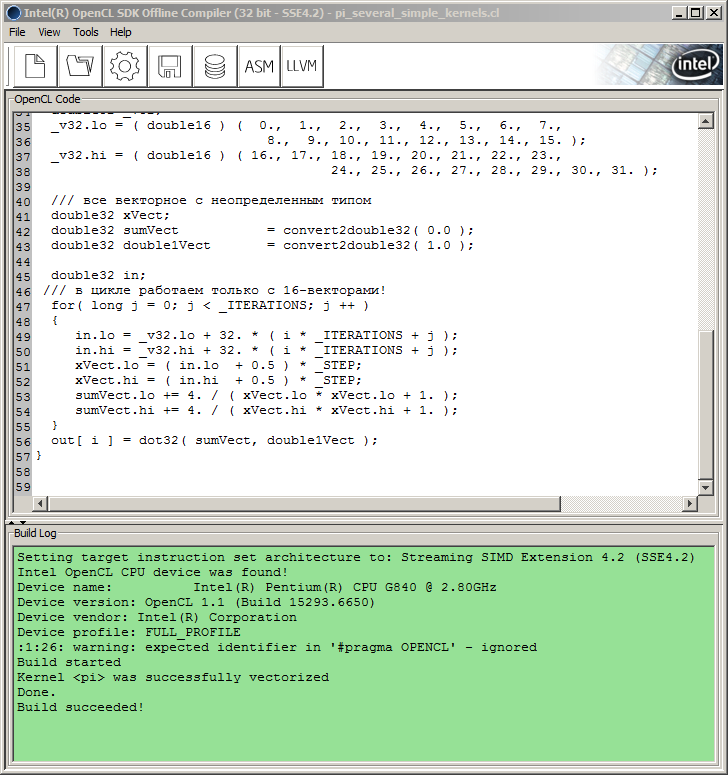
Fig.9. Compilazione del programma nel compilatore offline Intel OpenCL SDK
Per ottenere il codice del kernel senza virgolette, sarebbe utile scrivere un semplice programma nel linguaggio host (MQL5) che restituisca il codice del kernel in un file - WriteCLProgram(). Ora è incluso nel codice del programma host.
I messaggi del compilatore non sono sempre molto chiari, ma forniscono molte più informazioni di quelle attualmente in grado di fornire MQL5. Gli errori possono essere corretti immediatamente nella finestra del compilatore e, una volta accertato che non ce ne sono più, le correzioni possono essere trasferite al codice del kernel in MetaEditor.
E un'ultima cosa. L'idea iniziale dell'autore era quella di sviluppare un codice vettorizzato in grado di lavorare con vettori double4, double8 e double16 mediante l'impostazione di un unico parametro globale "numero dei canali". Questo è stato infine realizzato, dopo alcuni giorni di difficoltà con l'operatore di incollaggio di token ## che, per qualche motivo, si rifiutava di funzionare all'interno del codice del kernel.
Durante questo periodo l'autore ha sviluppato con successo un codice funzionante dello script con tre codici kernel, ognuno dei quali è adatto alla sua dimensione: 4, 8 o 16. Questo codice intermedio non verrà fornito nell'articolo, ma valeva la pena menzionarlo nel caso in cui volessi scrivere un codice del kernel senza avere troppi problemi. Il codice di questa implementazione dello script (OCL_pi_double_several_simple_kernels.mq5) è allegato di seguito alla fine dell'articolo.
Ed ecco il codice del kernel vettorizzato:
"/// enable extensions with doubles \r\n" "#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _intrnCnt ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" "#define _CH " + i2s( _ch ) + " \r\n" "#define _DOUBLETYPE double" + i2s( _ch ) + " \r\n" " \r\n" "/// extensions for 4-, 8- and 16- scalar products \r\n" "#define dot4( a, b ) dot( a, b ) \r\n" " \r\n" "inline double dot8( double8 a, double8 b ) \r\n" "{ \r\n" " return dot4( a.lo, b.lo ) + dot4( a.hi, b.hi ); \r\n" "} \r\n" " \r\n" "inline double dot16( double16 a, double16 b ) \r\n" "{ \r\n" " double16 c = a * b; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot4( c.lo.lo + c.lo.hi + c.hi.lo + c.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double16 v16 = ( double16 ) ( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ); \r\n" " double8 v8 = v16.lo; \r\n" " double4 v4 = v16.lo.lo; \r\n" " double2 v2 = v16.lo.lo.lo; \r\n" " \r\n" " /// all vector-related with the calculated type \r\n" " _DOUBLETYPE in; \r\n" " _DOUBLETYPE xVect; \r\n" " _DOUBLETYPE sumVect = ( _DOUBLETYPE ) ( 0.0 ); \r\n" " _DOUBLETYPE doubleOneVect = ( _DOUBLETYPE ) ( 1.0 ); \r\n" " _DOUBLETYPE doubleCHVect = ( _DOUBLETYPE ) ( _CH + 0. ); \r\n" " _DOUBLETYPE doubleSTEPVect = ( _DOUBLETYPE ) ( _STEP ); \r\n" " \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in = v" + i2s( _ch ) + " + doubleCHVect * ( i * _ITERATIONS + j ); \r\n" " xVect = ( in + 0.5 ) * doubleSTEPVect; \r\n" " sumVect += 4.0 / ( xVect * xVect + 1. ); \r\n" " } \r\n" " out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n" "} \r\n";
Il programma host esterno non è cambiato molto, tranne per la nuova costante globale _ch che imposta il numero di "canali di vettorizzazione" e la costante globale _intrnCnt che è diventata _ch volte più piccola. Ecco perché l'autore ha deciso di non mostrare qui il codice del programma host. Può essere trovato nel file di script allegato di seguito alla fine dell'articolo (OCL_pi_double_parallel_straight.mq5).
Come si può vedere, a parte la funzione "main" del kernel pi(), abbiamo ora due funzioni inline che determinano il prodotto scalare dei vettori dotN( a, b ) e una sostituzione macro. Queste funzioni sono interessate dal fatto che la funzione dot() in OpenCL è definita rispetto a vettori la cui dimensione non supera 4.
La macro dot4() che ridefinisce la funzione dot() è presente solo per la comodità di chiamare la funzione dotN() con il nome calcolato:
" out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n"
Se avessimo usato la funzione dot() nella sua forma abituale, senza l'indice 4, non saremmo stati in grado di chiamarla così facilmente come è mostrato qui, quando _ch = 4 (numero di canali di vettorizzazione pari a 4).
Questa riga illustra un'altra utile caratteristica della specifica forma del kernel, la quale risiede nel fatto che il kernel in quanto tale è trattato all'interno del programma host come una stringa: possiamo usare identificatori calcolati nel kernel non solo per le funzioni, ma anche per i tipi di dati!
Il codice completo del programma host con questo kernel è allegato di seguito (OCL_pi_double_parallel_straight.mq5).
Eseguendo lo script con il vettore "width" pari a 16 ( _ch = 16 ), otteniamo quanto segue:
2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) ================================================== 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) CPUtime / GPUtime = 4.130 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The time to calculate PI was 8.830 seconds 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The value of PI is 3.141592653590 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The time to calculate PI was 8.002 seconds 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The value of PI is 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: gone = 2.138 sec. 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: pi = 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) read = 20000 elements 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) CLProgramCreate: unknown error. 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) ==================================================
Puoi vedere che anche l'ottimizzazione che utilizza i tipi di dati vettoriali non ha reso il kernel più veloce.
Ma, se esegui lo stesso codice su GPU, il guadagno di velocità sarà molto più considerevole.
Secondo le informazioni fornite da MetaDriver (scheda video - HIS Radeon HD 6930, CPU - AMD Phenom II x6 1100T), lo stesso codice produce i seguenti risultati:
2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) ================================================== 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) CPUtime / GPUtime = 84.983 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The time to calculate PI was 14.617 seconds 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The value of PI is 3.141592653590 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The time to calculate PI was 14.040 seconds 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The value of PI is 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: gone = 0.172 sec. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) read = 20000 elements 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) CLProgramCreate: unknown error. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) ==================================================
6. Il tocco finale
Ecco un altro kernel (può essere trovato nel file OCL_pi_double_several_simple_kernels.mq5 allegato qui sotto, ma qui non viene mostrato).
Lo script è un'implementazione dell'idea che l'autore ha avuto quando ha temporaneamente abbandonato il tentativo di scrivere un "unico" kernel e ha pensato di scrivere quattro semplici kernel per diverse dimensioni vettoriali (4, 8, 16, 32):
"#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _itInKern ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" " \r\n" "typedef struct \r\n" "{ \r\n" " double16 lo; \r\n" " double16 hi; \r\n" "} double32; \r\n" " \r\n" "inline double32 convert2double32( double a ) \r\n" "{ \r\n" " double32 b; \r\n" " b.lo = ( double16 )( a ); \r\n" " b.hi = ( double16 )( a ); \r\n" " return b; \r\n" "} \r\n" " \r\n" "inline double dot32( double32 a, double32 b ) \r\n" "{ \r\n" " double32 c; \r\n" " c.lo = a.lo * b.lo; \r\n" " c.hi = a.hi * b.hi; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot( c.lo.lo.lo + c.lo.lo.hi + c.lo.hi.lo + c.lo.hi.hi + \r\n" " c.hi.lo.lo + c.hi.lo.hi + c.hi.hi.lo + c.hi.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double32 _v32; \r\n" " _v32.lo = ( double16 ) ( 0., 1., 2., 3., 4., 5., 6., 7., \r\n" " 8., 9., 10., 11., 12., 13., 14., 15. ); \r\n" " _v32.hi = ( double16 ) ( 16., 17., 18., 19., 20., 21., 22., 23., \r\n" " 24., 25., 26., 27., 28., 29., 30., 31. ); \r\n" " \r\n" " /// all vector-related with undefined type \r\n" " double32 xVect; \r\n" " double32 sumVect = convert2double32( 0.0 ); \r\n" " double32 double1Vect = convert2double32( 1.0 ); \r\n" " \r\n" " double32 in; \r\n" " /// work only with 16-vectors in the loop! \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in.lo = _v32.lo + 32. * ( i * _ITERATIONS + j ); \r\n" " in.hi = _v32.hi + 32. * ( i * _ITERATIONS + j ); \r\n" " xVect.lo = ( in.lo + 0.5 ) * _STEP; \r\n" " xVect.hi = ( in.hi + 0.5 ) * _STEP; \r\n" " sumVect.lo += 4. / ( xVect.lo * xVect.lo + 1. ); \r\n" " sumVect.hi += 4. / ( xVect.hi * xVect.hi + 1. ); \r\n" " } \r\n" " out[ i ] = dot32( sumVect, double1Vect ); \r\n" "} \r\n";
Questo stesso kernel implementa la dimensione vettoriale 32. Il nuovo tipo di vettore e alcune funzioni inline necessarie sono definite al di fuori della funzione principale del kernel. Oltre a ciò (e questo è importante!), tutti i calcoli all'interno del ciclo principale sono fatti intenzionalmente solo con tipi di dati vettoriali standard; i tipi non standard vengono gestiti all'esterno del ciclo. Ciò consente di accelerare notevolmente i tempi di esecuzione del codice.
Nei nostri calcoli, questo kernel non sembra essere più lento di quando viene utilizzato per vettori con una larghezza di 16, ma non è nemmeno molto più veloce.
Secondo le informazioni fornite da MetaDriver, lo script con questo kernel (_ch=32) produce i seguenti risultati:
2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: gone = 0.156 sec. 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) read = 10000 elements 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) CLProgramCreate: unknown error or no error. 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) GetLastError returned .. 0 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _itInKern = 3125; vectorization channels - 32 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) =================================================================
Sommario e conclusioni
L'autore comprende perfettamente che il compito scelto per la dimostrazione delle risorse OpenCL non è proprio tipico di questo linguaggio.
Sarebbe stato molto più facile prendere un libro di testo e prendere un esempio standard di moltiplicazione di grandi matrici per postarlo qui. Quell'esempio sarebbe ovviamente impressionante. Tuttavia, ci sono molti utenti del forum mql5.com impegnati in calcoli finanziari che richiedono la moltiplicazione di matrici di grandi dimensioni? È abbastanza dubbio. L'autore ha voluto scegliere il proprio esempio e superare da solo tutte le difficoltà incontrate lungo il cammino, cercando allo stesso tempo di condividere la sua esperienza con gli altri. Naturalmente siete voi a giudicare, cari utenti del forum.
Il guadagno in efficienza sull'emulazione OpenCL (su CPU "nuda") si è rivelato piuttosto piccolo rispetto alle centinaia e persino migliaia ottenute utilizzando gli script di MetaDriver. Ma su una GPU adeguata, sarà almeno un ordine di grandezza maggiore rispetto all'emulazione, anche se ignoriamo un runtime leggermente più lungo su CPU con CPU AMD. Vale ancora la pena imparare OpenCL, anche se il guadagno in velocità di calcolo non è tanto!
Il prossimo articolo dell'autore affronterà i problemi relativi alle peculiarità della visualizzazione di modelli astratti OpenCL su hardware reale. Questa conoscenza a volte permette di velocizzare ulteriormente i calcoli in misura considerevole.
L'autore desidera esprimere i suoi ringraziamenti speciali a MetaDriver per i preziosi suggerimenti sulla programmazione e sull'ottimizzazione delle prestazioni e al team di supporto per la possibilità stessa di utilizzare Intel OpenCL SDK.
Contenuto dei file allegati:
- pi.mq5 - uno script in puro MQL5 con due modalità di calcolo del valore "pi";
- OCl_pi_float.mq5 - la prima implementazione dello script con il kernel OpenCL che prevede calcoli reali con il tipo float;
- OCL_pi_double.mq5 - lo stesso, coinvolgendo solo calcoli reali con il tipo double;
- OCL_pi_double_several_simple_kernels.mq5 - uno script con diversi kernel specifici per varie "larghezze" vettoriali (4, 8, 16, 32);
- OCL_pi_double_parallel_straight.mq5 - uno script con un singolo kernel per alcune "larghezze" vettoriali (4, 8, 16).
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/405
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

 Perché il Market di MQL5 è il posto migliore per la vendita di strategie di trading e indicatori tecnici
Perché il Market di MQL5 è il posto migliore per la vendita di strategie di trading e indicatori tecnici
 Programmazione basata su automi come nuovo approccio alla creazione di sistemi di trading automatizzati
Programmazione basata su automi come nuovo approccio alla creazione di sistemi di trading automatizzati
 Opportunità illimitate con MetaTrader 5 e MQL5
Opportunità illimitate con MetaTrader 5 e MQL5
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Pubblicato il nuovo articolo OpenCL: A Bridge to a Parallel World:
Di Sceptic Philozoff
Il supporto di OpenCL è un'ottima scelta, ora e in futuro l'eterogeneità delle piattaforme di elaborazione è molto evidente, ma ora gli stessi algoritmi in condizioni di utilizzo di OpenCL rispetto alle prestazioni di CUDA sono molto più bassi, forse CUDA rispetto a OpenCL è più sottostante, meglio ottimizzato per la propria GPU. Le GPU di NVIDIA hanno prestazioni migliori, un migliore slancio e il compilatore CUDA ha adottato LLVM. Le prestazioni delle GPU NVIDIA sono migliori, il momento dello sviluppo è migliore e il compilatore CUDA ha adottato LLVM, ci saranno sempre più linguaggi che supporteranno CUDA, Python può ora supportare, soprattutto CUDA6.0 nella facilità d'uso della programmazione è più importante, soprattutto la tecnologia Unified Memory, in futuro, con il supporto del runtime CUDA per la migrazione automatica dei dati è migliore, le prestazioni del programma e la produttività della programmazione saranno migliori. Il supporto di MQL5 per OpenCL è un buon inizio, e in futuro potrebbero esserci alcune cose da fare su CUDA.
L'autore o gli esperti rispondano per favore:
Dove il codice sottostante funzionerà più velocemente sulla pietra principale o nel vidicon? E ci sono delle specifiche?
void OnStart()
{
long total= 1000000000;
for(long i=0;i<total;i++)
for(long q=0;q<total;q++)
for(long w=0;w<total;w++)
for(long e=0;e<total;e++)
for(long r=0;r<total;r++)
for(long t=0;t<total;t++)
for(long y=0;y<total;y++)
for(long u=0;u<total;u++)
func(i,q,w,e,r,t,y,u);
}
Ad esempio :
Pi = 4*atan(1);
oppure
Pi = acos(-1);
Non credo che più di 7 secondi per ottenere il valore di PI su 12 decimali sia il massimo dell'efficienza.
Ho sentito parlare di OpenCV per Python e Machine Learning, che può essere utile anche in un campo altamente psicologico come quello del trading, ma mai di OpenCL. Su queste basi, oggi esiste un ambiente di interfaccia piacevole che è ZeroMQ. Immagino che la comunicazione tra la piattaforma MTx e l'ambiente Python possa richiedere un po' di tempo, soprattutto se devono passare molti dati.
Grazie per l'articolo.