
From Basic to Intermediate: Array (I)

Introduction
The content presented here is intended solely for educational purposes. Under no circumstances should the application be viewed for any purpose other than to learn and master the concepts presented.
In the previous article, From Basic to Intermediate: Arrays and Strings (III), I explained and demonstrated, using code tailored to the current level of knowledge shown thus far, how the standard library can convert binary values into decimal, octal, and hexadecimal representations. I also covered how it can generate a binary string representation, making it easier for us to visualize the result.
In addition to this basic concept, I also demonstrated how we could define a password length based on a secret phrase. By a fortunate coincidence, the resulting password contained a repeated sequence of characters. This was a remarkable outcome, considering this was not the intended goal. In fact, it was simply a lucky accident. However, it presents an excellent opportunity to explain several other concepts and points related to arrays and strings.
Some readers might be expecting me to delve into the workings of each function or procedure in the standard library. But that is not my intention. My actual goal is to reveal the concepts behind each decision. You can make your own choices based on the nature of the problem you need to solve. Although we are still at a fairly basic level, we already have some real-world programming possibilities to work with. This allows us to start applying slightly more advanced concepts.
This not only simplifies the coding process but also enables you, dear reader, to read more complex code with greater ease. There's no need to worry about what's to come. I will introduce changes gradually so you can become familiar with them and read my code comfortably. I tend to minimize or compress expressions in ways that might be confusing to beginners, and I want to ease you into that style.
That said, let's begin this article by reviewing what we covered in the previous one. In other words, let's learn one of many possible ways to avoid the very outcome produced by the factorization process used to generate a password from a secret phrase.
One Among Many Solutions
Very well. Today we'll start by making the code more a bit more elegant. The original code is shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Code 01
In my view, this code is somewhat inelegant. This is because the variables declared on lines 16 and 17 are used only within the loop on line 21. If, for any reason, we later need a variable with the same name or of a different type, we would have to put in extra work just to adjust the code. As we've seen in previous articles, it is possible to declare variables directly within a FOR loop.
Now pay close attention, dear reader. When declaring more than one variable intended solely for use within a FOR loop, all of them must be of the same type. It is NOT POSSIBLE to declare and initialize variables of different types in the first expression of a FOR loop. So, we need to make a small decision here. The variables 'pos' and 'i', declared on lines 16 and 17, are of type uchar, while the variable 'c', declared within the FOR loop, is of type int. We can either change 'pos' and 'i' to int, or change 'c' to uchar. In my opinion, it doesn't make much sense for a phrase to exceed 255 characters. Therefore, we can settle on a middle ground and define all three variables as type ushort, since they are used solely as indexing variables. With this explanation in mind, let's modify Code 01 into Code 02.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+
Code 02
Despite the apparent complexity that Code 02 might present, it still performs the same task as Code 01. However, I'd like to draw your attention to line 20. Notice that in the first expression of the for loop, we are now declaring all the variables that will be used exclusively within the loop. Take a close look at the third expression of the FOR statement. In this case, it wouldn't be possible to adjust the value of the variable 'i' in this way without using the ternary operator. However, it's important to note that this adjustment merely ensures that the index stays within the bounds of the array since the actual increment is performed in line 23.
Despite this change, the output remains exactly the same. That is, when you run the code, you'll see something on your terminal similar to the image shown below.
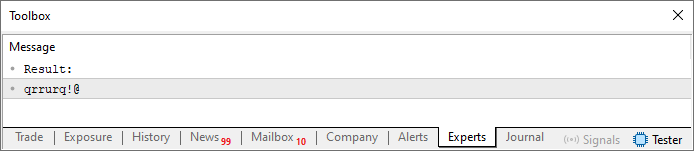
Figure 01
Now let's think a bit. The repetition of symbols in the output string is happening because, on line 27, we're referencing the same position in the szCodePhrase string. In other words, by reducing the values to stay within the string length as defined on line 13, we end up pointing to the same location repeatedly. But (and here's the important moment) if we sum the current position with the previous one, we can generate a new index, entirely different from the last. Since the string on line 13 contains no repeated characters, the output string, i.e. our password, would also have no repeated characters.
There's something important to keep in mind here: this technique doesn't always work. That's because the number of characters in the string defined on line 13 might not be ideal. In another scenario, the values might fall into a perfect cycle. This happens because we are essentially working with a loop of characters or symbols declared on line 13, where the first character (a closing parenthesis) is linked to the last character, which is the number nine. It's like a snake biting its own tail.
Many non-programmers don't understand this concept. But things like this always come up in one form or another when working with code.
Alright, now that I've explained what we're going to do, let's take a look at the code. It's shown just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 0) + psw[c]) % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+s
Code 03
This approach is very interesting. Notice that I've barely changed anything in the code. Only line 27 is new. I did something very similar to what was done in the third expression of the for loop, which you can see on line 20. But before diving into that, let's look at the result. It can be seen just below.
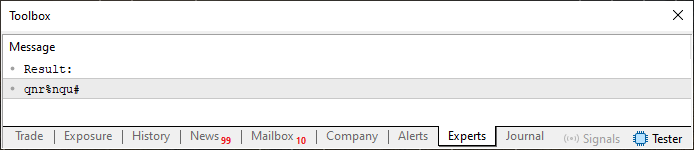
Figure 02
You’ll see that the repeated characters we had earlier are no longer present. However, things can be improved even further by changing a single line in Code 03. As explained in previous articles, the ternary operator used on line 27 functions like an IF statement. Because of that, the first value being calculated does not undergo any adjustment. All subsequent values, however, are adjusted based on the index used in the previous iteration. Pay close attention here: the array value used for this adjustment is not the one calculated in the loop on line 20. It is the one obtained from the string defined on line 13. So to determine its exact value, you'll need to consult the ASCII table and add that value to the one calculated in the loop on line 20. It may seem a bit confusing, but it's actually quite simple once you pause to think it through.
Now, I want to draw your attention to the zero value used in the ternary operator. This is why the first index remains unchanged. But what if we replaced that zero with another value? Suppose we modify line 27 as shown below.
psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 5) + psw[c]) % StringLen(szCodePhrase)]);
The result would be quite different, as you can see in the following image.
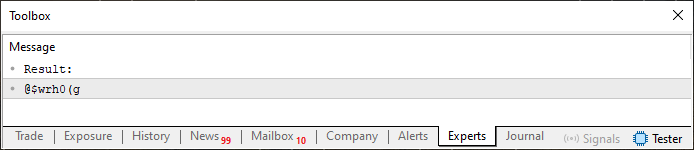
Figure 03
Interesting, isn't it? With just a simple change, we can generate what many would consider a strong password. And we've done this using basic calculations and two easy-to-remember phrases. Keep in mind that we accomplished all this using a level of programming knowledge I would still classify as beginner. Not bad at all for someone just starting out. So, dear reader, have fun exploring and experimenting with new possibilities. What I've shown here is just a simple, basic example, something an experienced programmer could implement in just a few minutes.
Great, that was the easiest part of the demonstration on using arrays. However, we are not quite finished yet. Before we can take further steps toward more advanced and complex topics, we need to cover some additional details about arrays. So let's move on to a new topic.
Data Types and Their Relationship with Arrays
One of the most complex, confusing, and difficult-to-master topics in programming is precisely the subject of this section. Perhaps, and quite likely, you, dear reader, may not yet grasp just how complex this topic truly is. Some consider themselves good programmers yet have no idea how things are interrelated. As a result, they claim that certain tasks are impossible or more difficult than they actually are.
As you gradually absorb this topic, you'll begin to understand many other concepts that, at first glance, may seem unrelated, but at a deeper level, they are all fundamentally connected.
Let's start by thinking about computer memory. It doesn't matter whether the processor is 8-bit, 16-bit, 32-bit, 64-bit, or even something unusual like 48-bit. That's irrelevant. Likewise, it doesn't matter whether we're dealing with binary, octal, hexadecimal, or any other number system. That also makes no difference. What truly matters is how the data structures are being set up or constructed. For example: who decided that a byte must have eight bits? And why eight? Couldn't it be ten bits, or twelve?
Maybe this line of thinking doesn't make much sense right now. That's because it really is difficult to distill decades of experience into something understandable for beginners. Without delving into certain concepts prematurely, discussing topics like this can be quite difficult. However, based on what we've already covered in previous articles, we can have a little fun here. Let's work with an array of one data type, and a variable of a completely different type. But there's a small rule: the data type used in the array MUST NOT BE THE SAME as that of the variable. Even so, we can make them communicate with each other and even hold the same kind of value, as long as we follow a few simple rules.
Sounds complicated, like something that would require far more programming knowledge, right? Let's try it out and see for ourselves. To make things even more enjoyable, we'll bring back the function from the previous article - the one we used to convert binary values into other formats.
Sounds like a good plan. And since we'll be using that kind of implementation extensively to explain several concepts, let's place that function into a header file. This leads us to the code shown just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Code 04
Now, an important detail: since Code 04 is a header file that will be included and intended solely for tutorial scripts, it will be placed inside a folder within the scripts directory. As I've explained before, this has specific implications for anything created here, and I won't repeat that explanation. So let's move forward. Great. Take note of this, dear reader: all values we're going to convert should be treated as unsigned values, at least until we correct this small detail in the function shown in Code 04.
Once this is in place, we can test whether everything is working properly. To do this, we'll use a simple script:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation via standard library.\n" + 11. "Decimal: %I64u\n" + 12. "Octal : %I64o\n" + 13. "Hex : %I64X", 14. value, value, value 15. ); 16. PrintFormat("Translation personal.\n" + 17. "Decimal: %s\n" + 18. "Octal : %s\n" + 19. "Hex : %s\n" + 20. "Binary : %s", 21. ValueToString(value, 0), 22. ValueToString(value, 1), 23. ValueToString(value, 2), 24. ValueToString(value, 3) 25. ); 26. } 27. //+------------------------------------------------------------------+
Code 05
Upon executing this script, the output will be as shown in the image below:
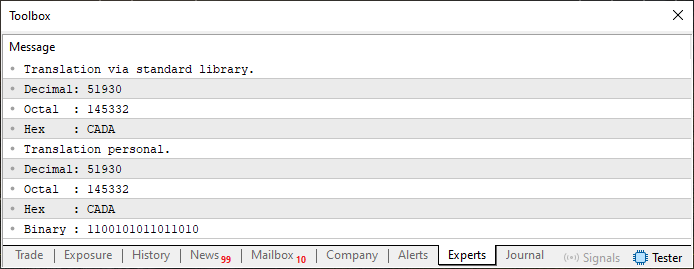
Figure 04
It clearly works. With that, we're ready to begin experimenting with arrays and variables of different data types. This will help you start to grasp a very curious behavior, one that only occurs in certain programming languages. To begin, we'll make a slight modification to Code 05. This version will serve as our starting point, which I'll call "POINT ZERO". This is shown below:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA}; 09. ushort value = 0; 10. 11. value = (array[0] << 8) | (array[1]); 12. 13. PrintFormat("Translation personal.\n" + 14. "Decimal: %s\n" + 15. "Octal : %s\n" + 16. "Hex : %s\n" + 17. "Binary : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2), 21. ValueToString(value, 3) 22. ); 23. } 24. //+------------------------------------------------------------------+
Code 06
Now, I ask you, dear reader, to put aside any distractions or anything that may draw your attention away. I need you to fully focus on what we are about to explore from this point onward. Because what I'm about to explain is something that many beginner programmers find extremely confusing. Not all programmers, but particularly those who use certain languages, like MQL5, for example.
Before we dive into an explanation, let's take a look at the result of running Code 06. You can see it just below:
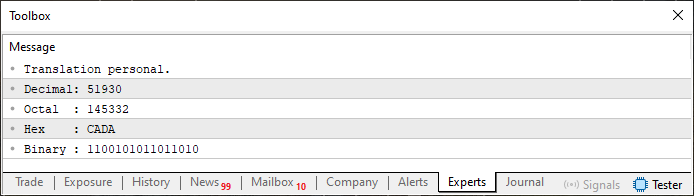
Figure 05
What you're seeing here in Code 06 forms the foundation for a wide range of concepts. If you're able to truly understand this code, you'll be able to comprehend all the related topics that will follow with ease. That's because many of those topics stem in some way from what this code is doing.
At first glance, you may not realize just how complex this seemingly simple code really is, or what can be accomplished simply because this implementation is possible. So let's take it slow. For those who already have some experience, none of what follows will be new. But for those who are still learning, the explanations here might seem confusing.
Alright, maybe I got ahead of myself a bit. So let's rewind slightly and ask: Which part of Code 06 do you not understand, based solely on what has been explained so far? Most likely, it's lines 8 and 11. Actually, for someone just starting out, those lines don't seem to make much sense. In earlier sections of this same article, we did see something similar. Take a look at Code 03, specifically lines 15, 20, 23, and 27.
However, in Code 06, things work a bit differently - not entirely, but enough to cause confusion. And perhaps that's because I made a mistake by using arrays before properly explaining them. For that, I apologize. Especially if you're now feeling a bit lost, as might be the case when seeing the output in Figure 05, which results from running Code 06.
So let's take a step back and do things the right way. Let's start with line 11 of Code 06. What we have there is equivalent to the following line of code, shown just below:
value = (0xCA << 8) | (0xDA);
At first glance, this may seem a bit complicated. Even though we've already discussed how the bit-shift operator works. Let's turn to a visual aid. It will make things much easier to understand.
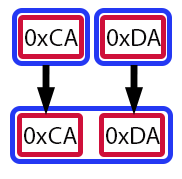
Figure 06
In this illustration, each red rectangle represents a byte or, more precisely, a value of type uchar. The blue rectangles represent variables. The arrows indicate how the values move and transform throughout the process. In other words, Figure 06 shows how the value of the variable value was formed in line 11. Let me see if I've got this right: you're saying that, even though value is of type ushort, we can insert values of type uchar into it? And in doing so, we can construct an entirely new value? Exactly, dear reader. But it doesn't stop there. Let's take it slow so the concept can be fully understood.
As you already know, the memory region defined in line 8 is a constant region. But there is something more. Since we're initializing values within this memory block, you could think of it as a kind of ROM cartridge, similar to the old-school game cartridges used in vintage video game consoles.

Figure 07
It may sound odd to talk about creating ROM inside RAM, but yes, that's essentially what line 8 is doing.
But hold on. What's the size of the ROM we've just created in line 8? It depends, dear reader. And no, I'm not trying to dodge the question. I am entirely honest. Fortunately, there's a function in the standard library that lets us determine the size of the allocated block. Keep in mind that an array is a string - but a string is a special kind of array, as we've discussed before. Unlike the arrays used in the previous examples, where we generated passwords from simple phrases, the array in Code 06 is a pure array. That is, it's not a string, but it's meant to represent any kind of value. However, because we declared it as an array of uchar, we limit the range of values we can store within it. Here's where things get interesting: we can use a larger type to interpret the values stored in the array.
To do this, we need a data type capable of holding all the bits present in the array. That's exactly what Image 06 is trying to show. The blue section represents the collection of bits that make up the array, seen as a single unit. To make this concept even clearer, let's add a bit more information to line 08 and see what happens. But in order to keep things simple, we'll need to adjust the code as shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+
Code 07
Yes, I know. What we're doing in Code 07 may seem like complete madness. But take a look at the result we get when executing this code. You can see it below.
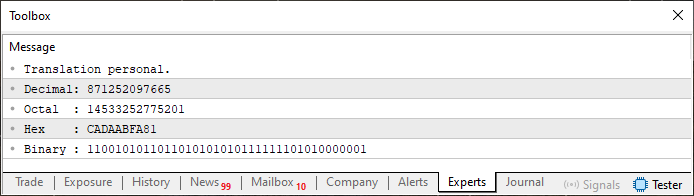
Figure 08
Now this is what you might call totally crazy. But as you can see, dear reader, it works. In other words, we've combined binary values, hexadecimal values, and decimal values within a single array. And in the end, we've built a small ROM-like memory block containing some kind of information. But the wildest part - What you're seeing here is just the tip of a massive iceberg.
Before we dive deeper, let's take a moment to understand what actually happened here, and what limitations and precautions we need to consider when working with this kind of setup.
You may have noticed that in line eight, I simply added more data. What's the maximum amount of data we can place there? The answer is: AN INFINITE AMOUNT, or at least as much as your system allows. In practice, the amount of data you can include depends entirely on your machine's memory capacity. However, while we can put virtually unlimited values into the array in line 8, the same doesn't apply to the 'value' variable. That's where a hard limit comes into play. In this example, I wanted to give you, dear reader, the freedom to experiment as much as possible. So, I used the maximum bit capacity currently supported in MQL5 - 64 bits, or eight bytes. Does that mean we can only store eight bytes in the value variable? Not quite. What it really means is this: once you reach 64 bits, any new data will overwrite the old values. This creates a data flow model that we'll explore in more detail later on.
It's important to understand that the variable can hold up to 64 bits. But that doesn't necessarily mean eight values. And this is exactly where things start to get tricky for those who jumped straight into this article without reading the earlier ones or practicing what was explained there.
Now, before we dive into the loop in line 11 and explore what's happening in line 12, let's modify one small detail in Code 07. This change will make the concept of array size and the amount of information within it much clearer. That small modification is shown in the line of code just below.
const ushort array[] = {0xCADA, B'1010101111111010', 0x81}; Now, looking at the modified line above, you'll notice that our array no longer has five elements - it has just three. And it's important to observe that even though we've changed the number of elements, we're still using almost the same amount of memory. The difference is that now we're wasting 8 bits of memory. That's because, unlike what we saw in Code 07, where each byte was being fully utilized, in this new structure, the last value in the array only uses 8 of the 16 bits available to it. It might seem like an acceptable level of waste. And we will discuss this further later on. For now, just keep in mind: the data type you use affects memory usage. It also influences how your code behaves in some cases.
However, there’s an even worse scenario: when you use something like the line shown below.
const int array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; I know many developers don't worry about using the most appropriate data type for every variable. But even though there seems to be (and in our current case, there really isn't) any issue with using that line in Code 07, you're no longer wasting just 8 bits per element. You're now wasting 16 bits per element in the array. With five elements, that's a waste of 80 bits, or 10 bytes, which is more than the width of the password we built at the start of the article.
Again, this amount of memory waste may seem negligible, especially considering today's machines often come with 32 GB or more of RAM. And even with this waste in our current example, the behavior of the code will not change. This is thanks to the logic on lines 11 and 12, which we'll now break down.
Here we tell the code that, for each element in the array, we want the value stored in value to be shifted left by 8 bits, making space for the new element. That's what happens in line 12. But this line specifically targets a certain element in the array indicated by the variable 'c'. How do we know how many elements are in the array? Take a look at line 11. The second expression in the for-loop condition provides that information. What we're doing here is calling a standard library function in MQL5.
This function is equivalent to using ArraySize(). And that's how we determine how many elements exist in the array, regardless of how many bits each element actually uses.
To experiment with this behavior, simply modify the code so that it looks like the version shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. Print("Number of elements in the array: ", ArraySize(array)); 25. } 26. //+------------------------------------------------------------------+
Code 08
When we run Code 08, we will be able to see the number of elements present in the array as shown in the highlighted area in the figure below.
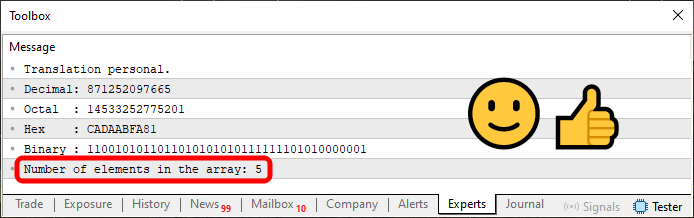
Figure 09
Final Thoughts
Well, my dear reader, this article already contains a wealth of material for you to study and absorb. Because of that, I'll give you some time to review and practice everything we've covered so far. Try to truly understand these foundational concepts related to working with arrays. Even though the arrays used in this article are of the ROM type, meaning their contents cannot be modified, it's still crucially important that you do your best to grasp what's being explained here. I know this material can be tough to digest all at once, but I encourage you to put in the effort and stay dedicated in your pursuit of deeper understanding.
Mastering the concepts in this and previous articles will greatly support your growth as a programmer. And as the material continues to get more complex from here on out, you'll be increasingly challenged. But don't be discouraged by the difficulty - embrace it. Make sure to practice, and refer to the attached files to help you understand topics that weren't fully demonstrated in the article but were mentioned in passing. Some examples include code modifications that were discussed but whose outputs weren't shown. It's very important that you understand how those changes affect memory. So, enjoy exploring the attached files.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/15462
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use