Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 27
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Здравствуйте!
Есть у меня идейка одна, хочу проверить но не знаю инструмента для реализации... нужен алгоритм который по моим данным мог бы прогнозировать на несколько точек вперед скажем на 3 или 5 (желательно чтоб это была нейросеть)
Здравствуйте!
Есть у меня идейка одна, хочу проверить но не знаю инструмента для реализации... нужен алгоритм который по моим данным мог бы прогнозировать на несколько точек вперед скажем на 3 или 5 (желательно чтоб это была нейросеть)
Я до этого работал только с класификацыей потому даже как то не понимаю как это должно выглядеть, подскажите кто нибудь как это делается или пакет порекомендуйте в R
п.с. Отличная статья Алексей
Это пакеты, которые экстраполируют существующие тенденции, например, forecast. Очень интересны разные сплайны.
Выглядит вполне солидно.
И что, полезного результата нет?
Когда запускал алгоритм в первый раз, на небольшом объёме исходных данных, положительного результата не было, получил ошибку около 50% и с y-aware pca, и с простой pca. Сейчас из mt5 достаю уже более полный набор данных - почти все стандартные индикаторы со всеми их буферами, некоторые индикаторы повторяются несколько раз с разными параметрами. Плюс на части индикаторов сделал советники и с их помощью оптимизировал параметры индикаторов на более прибыльную торговлю. На таких данных простое pca по-прежнему ошибается 50%, а с y-aware ошибка во фронттесте заметно падает, до 40%. Это очень интересно, что y-aware алгоритм просто берёт сырые данные, и делает из них классификатор который правильно работает в 6 случаев из 10. Вывод - нужно ещё больше исходных данных.
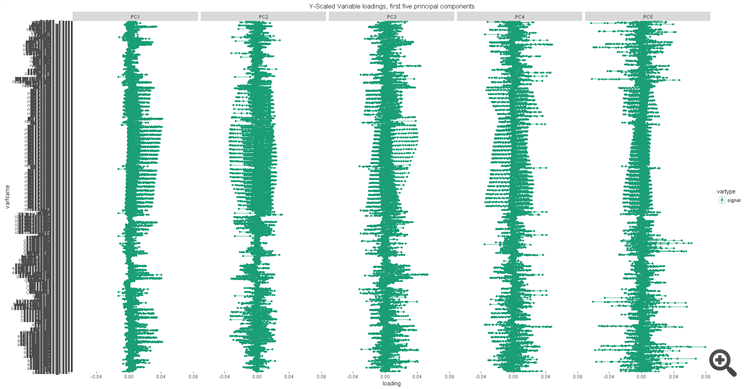
Но на этом все положительные стороны заканчиваются. Стандартных компонент для точности в 95% нужно 73. Лоадинги предикторов в компонентах колеблются с большего на меньший без явных лидеров. То есть нету вообще никаких признаков по которым можно отобрать определённые предикторы. Модель как-то работает, но что с ней сделать для улучшения результата, или как из неё вытащить полезность предикторов - непонятно.
важность компонент:
лоадинги предикторов по первым 5 компонентам:
ARIMA
Но арима принимает решения по тайм серии, а мне надо чтоб модель принимала решения от моего набора данных, то есть матрицы с предикатами и на выходе давала прогноз на несколько баров вперед
Никто вам не помешает обучить нейросеть с несколькими выходными нейронами - каждый на свой горизонт планирования. Заодно будет интересно понаблюдать за результатами.
Когда запускал алгоритм в первый раз, на небольшом объёме исходных данных, положительного результата не было, получил ошибку около 50% и с y-aware pca, и с простой pca. Сейчас из mt5 достаю уже более полный набор данных - почти все стандартные индикаторы со всеми их буферами, некоторые индикаторы повторяются несколько раз с разными параметрами. Плюс на части индикаторов сделал советники и с их помощью оптимизировал параметры индикаторов на более прибыльную торговлю. На таких данных простое pca по-прежнему ошибается 50%, а с y-aware ошибка во фронттесте заметно падает, до 40%. Это очень интересно, что y-aware алгоритм просто берёт сырые данные, и делает из них классификатор который правильно работает в 6 случаев из 10. Вывод - нужно ещё больше исходных данных.
Но на этом все положительные стороны заканчиваются. Стандартных компонент для точности в 95% нужно 73. Лоадинги предикторов в компонентах колеблются с большего на меньший без явных лидеров. То есть нету вообще никаких признаков по которым можно отобрать определённые предикторы. Модель как-то работает, но что с ней сделать для улучшения результата, или как из неё вытащить полезность предикторов - непонятно.
важность компонент:
лоадинги предикторов по первым 5 компонентам:
уже делал так, нейросеть не учиться на большем горизонте с той целевой что я ей задал
Это хорошо, что не обучилась, потому как учите на шуме. А вот если бы обучилась, да грааль, да на реал....
Заняты здесь тем, что пытаемся исключить шум. Именно поэтому берем очень много предикторов в надежде что хоть что-то останется.