Обсуждение статьи "Эконометрические инструменты для прогнозирования волатильности: Модель GARCH"
Очень хорошая работа!
Читал в захлеб.
Спасибо!
Хорошая статья. Было бы интересным узнать ваше мнение о статье Степанова, в которой он выдвигает гипотезу о нестохастической природе колебаний волатильности.
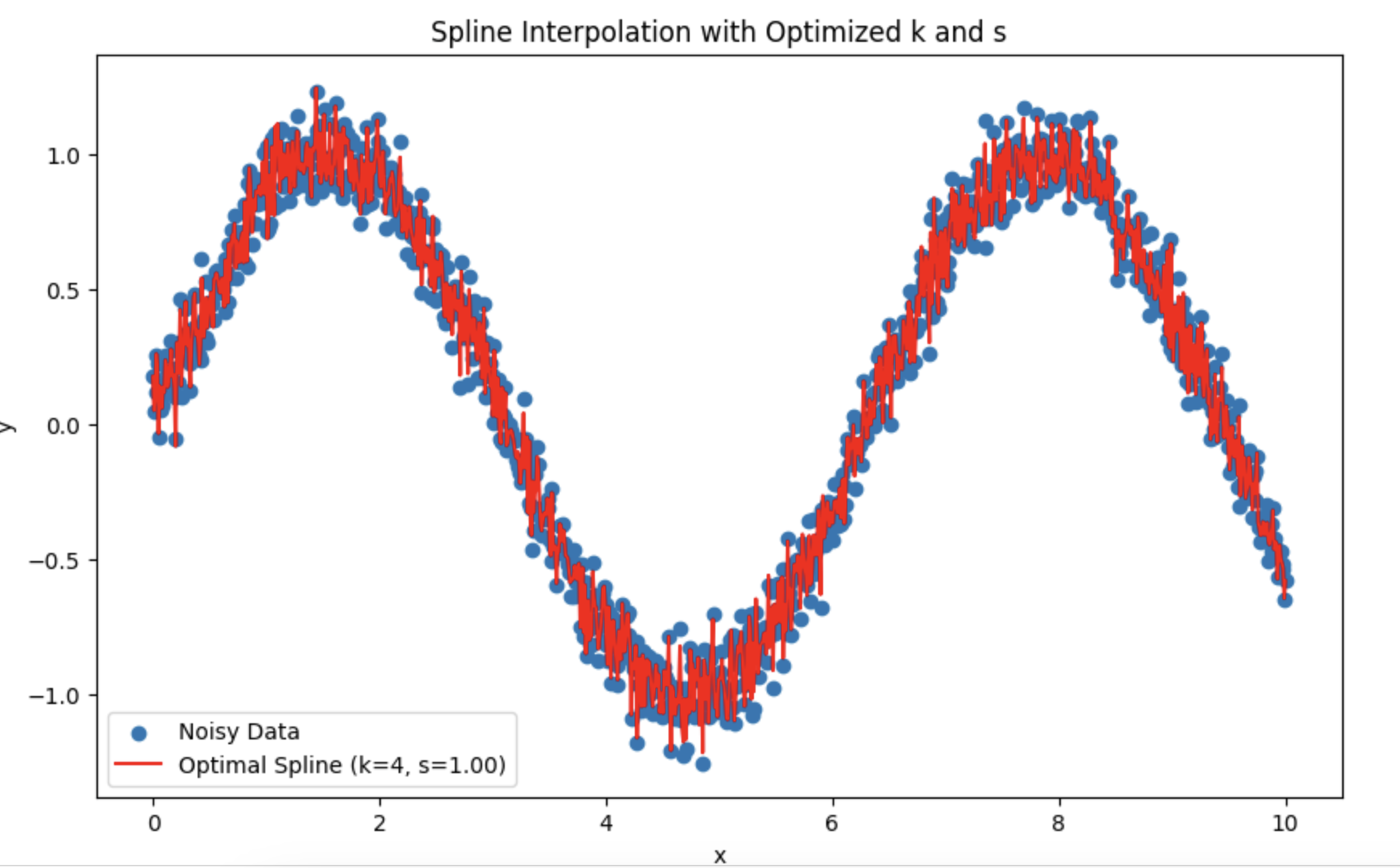
А ведь вы поразили меня прямо в мою ТС. Вместо HP пробую сплайны.
Задавался вопросом, какой лучше выбрать период и степень сглаживания.
Получается, опираться лучше на тест на нормальное распределение остатков?
А ведь вы поразили меня прямо в мою ТС. Вместо HP пробую сплайны.
Задавался вопросом, какой лучше выбрать период и степень сглаживания.
Получается, опираться лучше на тест на нормальное распределение остатков?
Хорошая статья. Было бы интересным узнать ваше мнение о статье Степанова, в которой он выдвигает гипотезу о нестохастической природе колебаний волатильности.
Статья сложная и противоречивая. Автор с одной стороны на протяжении всей статьи пользуется вероятностной терминологией, статистическими инструментами, характеризует приращение цен и волатильность как случайные величины, строит распределения различных мер волатильности и т.д., с другой стороны ему не нравятся стохастические модели волатильности.
Имхо, да, если строятся модели для приращений на постоянных промежутках времени, то нужно чтобы всё сводилось к гауссовому шуму в итоге. В этом наверное вся суть эконометрики - все неучтённые в модели факторы должны вести себя как ровный шум.
Интересно, не делал еще такое. В статье автор вроде как эмпирическим путем подобрал параметры. Но можно же сделать оптимизацию через функцию правдоподобия.
Тема для ресерча :)
Интересно, не делал еще такое. В статье автор вроде как эмпирическим путем подобрал параметры. Но можно же сделать оптимизацию через функцию правдоподобия.
Тема для ресерча :)
Сделал с божьей помощью LLM DeepSeek. Можно подставлять свои данные.
Объяснение:
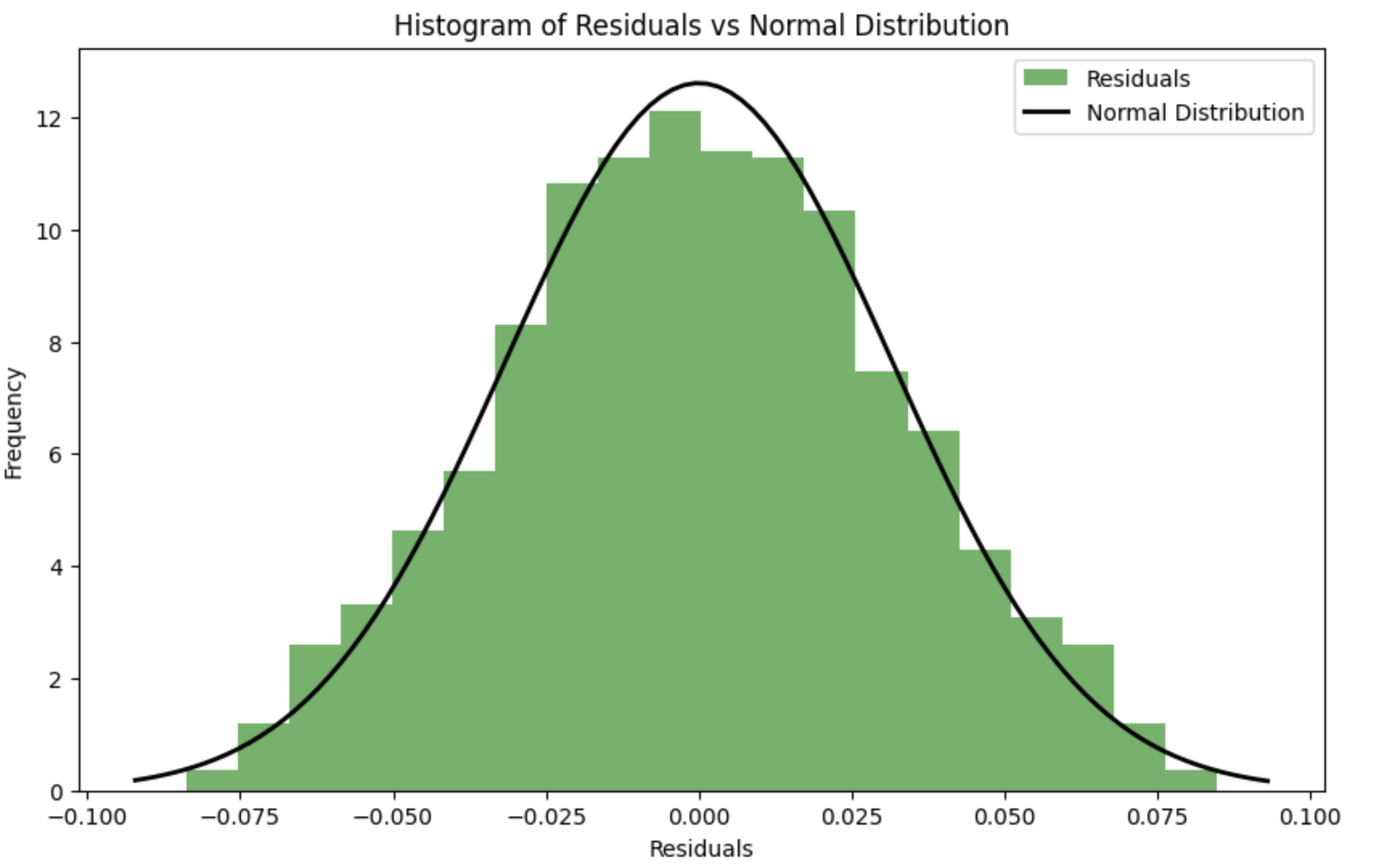
Для того чтобы остатки в процессе оптимизации максимально приближались к нормальному распределению, можно использовать критерий согласия (например, критерий Шапиро-Уилка или критерий Колмогорова-Смирнова) для оценки нормальности остатков. Затем можно оптимизировать параметры k k и s s так, чтобы минимизировать отклонение остатков от нормального распределения.
-
Функция ошибки с учетом нормальности остатков: Введена новая функция spline_error_with_normality , которая вычисляет остатки и использует критерий Шапиро-Уилка для оценки их нормальности. Отрицательное значение p-value минимизируется, чтобы максимизировать нормальность остатков.
-
Оптимизация: Используется minimize для оптимизации параметров k k и s s на основе новой функции ошибки.
Этот подход позволяет настроить параметры сплайна так, чтобы остатки максимально приближались к нормальному распределению, что может улучшить качество модели и интерпретируемость результатов.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Эконометрические инструменты для прогнозирования волатильности: Модель GARCH:
В статье дается описание свойств нелинейной модели условной гетероскедастичности(GARCH). На ее основе построен индикатор iGARCH для прогнозирования волатильности на один шаг вперед. Для оценки параметров модели используется библиотека численного анализа ALGLIB.
Волатильность является важным показателем для оценки изменчивости цен финансовых активов. При анализе котировок уже давно было подмечено, что большие изменения цен очень часто влекут за собой еще большие изменения, особенно это актуально во времена финансовых кризисов. В свою очередь, за малыми изменениями как правило следуют малые изменения цен. Таким образом, спокойные периоды волатильности сменяются периодами относительной нестабильности.
Первой моделью, которая попыталась объяснить данный феномен, была модель ARCH, разработанная Энглем (Engle), — Авторегрессионная условная гетероскедастичность (неоднородность). Помимо эффекта кластерности (группирования доходностей в пачки больших и малых значений), эта модель также объясняла появление тяжелых хвостов и положительный эксцесс, что свойственно всем распределениям приращений цен. Успех условно-гауссовской модели ARCH привел к появлению целого ряда ее обобщений, целью которых было дать объяснения ряду других феноменов, наблюдаемых при анализе финансовых временных рядов. Исторически одним из первых обобщений ARCH модели является GARCH модель (Generalized ARCH).
Основным преимуществом GARCH по сравнению с ARCH моделью является то, что она более экономна и не требует длиннолаговой структуры при подгонке выборочных данных. В данной статье я хочу дать описание того, что из себя представляет GARCH модель, а самое главное предложить готовый инструмент прогнозирования волатильности на ее основе, ведь прогноз — это одна из главных целей при анализе финансовых данных.
Автор: Евгений Черныш