(PF-1)*SdDay - 이 계수가 Vigoda 표시기의 주요 볼륨을 캡처하는 것을 방지하기 위한 상한값. 거래가 많을수록 높은 수익성을 달성하기가 더 어렵습니다.
(PF-1) - 음의 균형 표시기로 PF 승수도 음이 되도록 수행됩니다. 이것은 첫 번째 지표로 사용되므로 다음 지표도 총계의 양에 영향을 미치며 우세하지 않아야 합니다.
((PipBar+Ust)/10) -포지션을 열 때 시간은 우리에게 유리하지 않습니다. 왜냐하면 시장은 언제든지 바뀔 수 있으며 PipBar 표시기(이제 PipMin, pip/min으로 변경)는 사용된 시간의 품질을 보여줍니다. 최소 시간에 최대 포인트 수. Ust - 지속 가능성도 중요합니다. 지표가 높을수록 균형의 성장이 더 원활해집니다. 10으로 나누면 총계에 미치는 영향이 동일합니다.
(ProcDay*10)/(MD+(SrD*4)) - 이 동안 사용된 위험에 대한 잔액 성장률의 비율입니다. 10과 4를 곱하면 전체 지표에 미치는 영향도 동일해집니다.
덧셈 대신 곱셈을 사용하면 각 지표의 영향을 균형 잡기가 더 어렵습니다. 이로 인해 결과가 때때로 부당하게 점프합니다. 저를 믿으십시오. 하나의 매개변수가 약간 과대평가된 경우 모든 것이 이미 확인되었습니다. 그런 다음 곱할 때 합계를 잘못된 상단으로 가져오는 경우가 많습니다.
(PF-1)*SdDay - 이 계수가 Vigoda 표시기의 주요 볼륨을 캡처하는 것을 방지하기 위한 상한. - 1. Profit Factor에 대한 잘못된 의존성을 명시적으로 사용함을 나타냅니다. 거래가 많을수록 높은 수익성을 달성하기가 더 어렵습니다. - 2. 다르게 공식화하면 할수록 랜덤한 결과를 얻기가 어려울수록 높은 수익성으로 달성합니다.
(PF-1) - 음의 균형 표시기로 PF 승수도 음이 되도록 수행됩니다. - 3. 마이너스 잔액에는 마이너스가 있고 이익 계수는 < 1입니다. 이는 합리적이고 체계적으로 정당화됩니다. 하나를 다른 것으로 재정의하는 요점이 무엇입니까? 이것은 첫 번째 지표로 사용되므로 다음 지표도 총계에 영향을 미치며 우세하지 않아야 합니다. -
((PipBar+Ust)/10) - 포지션을 열 때 시간은 우리에게 유리하지 않습니다. 왜냐하면 시장은 언제든지 바뀔 수 있으며 PipBar 표시기(이제 PipMin, pip/min으로 변경)는 사용된 시간의 품질을 보여줍니다. 최소 시간에 최대 포인트 수. - 4. 테스트 기간의 길이에 대한 기준의 역 의존성이 더 간단하고 명확해졌습니다. Ust-안정성도 중요하지 않습니다. 지표가 높을수록 균형 평균의 성장이 더 원활해 집니다. - 5. 이익을 최대 인출액으로 나눈 잔고의 순조로운 성장과 맞지 않습니다. 나는 그것을 부르지 않을 것입니다. 10으로 나누면 총계에 미치는 영향이 동일합니다. - 6. 이것은 일부 통계 공식 계산의 결과입니까 아니면 "대략 적합" 유형의 평균 한도 경험주의입니까?
(ProcDay*10)/(MD+(SrD*4)) - 이 동안 사용된 위험에 대한 잔액 성장률의 비율입니다. 4. 테스트 기간의 길이에 대한 기준의 역 의존성은 더 간단하고 명확합니다. 10과 4를 곱하여 전체 지표에 미치는 영향을 균등하게 합니다. - 6. 이 10과 4는 일종의 통계 공식 계산 또는 "대략 적합" 유형의 평균 한도 경험주의의 결과입니까?
덧셈 대신 곱셈을 사용하면 각 지표의 영향을 균형 잡기가 더 어렵습니다. 이로부터 합계가 때때로 부당하게 점프합니다. 저를 믿으십시오. 하나의 매개 변수가 약간 과대 평가되면 모든 것이 이미 확인되었으며 곱할 때 종종 합계를 잘못된 상단으로 가져옵니다. - 1. Profit Factor, Profit, Maximum Drawdown, 테스트 기간의 길이에 대한 잘못된 의존성의 명시적 사용을 나타냅니다.
공식을 계속 수정하고 있으며 나중에 업데이트 및 비교를 게시할 예정입니다...
간단한 예를 보여 드리면 귀하의 접근 방식이 방법론적으로 올바르지 않다는 것을 이해하게 될 것입니다.
균형 표시기는 "더 많은 돈"이라는 꿈과 비교하기 때문에 우리에게 가치가 있습니다. 잔고와 "더 많은 돈"은 같은 성질의 지표이며 잔고가 클수록 "더 많은 돈"에 가깝습니다.
최대 손실액의 지표는 "예금이 사라졌습니다"라는 악몽과 비교하기 때문에 우리에게 가치가 있습니다. 최대 인출액과 "손실된 보증금"은 다시 동일한 성격의 지표이며, 최대 인출액이 작을수록 "손실된 보증금"에서 멀어집니다.
이익 요소는 모든 이익의 합계를 모든 손실의 합계와 비교하기 때문에 우리에게 가치가 있습니다. 놀랍게도 사실은 모든 이익의 합과 모든 손실의 합이 다시 같은 성질의 지표이며 이익이 많을수록 손실이 적을수록 우리에게 더 가치있는 지표라는 것입니다.
동질적인 지표를 비교(더하기, 나누기, 곱하기)하는 것이 얼마나 중요한지 대략적으로 이해하셨으리라 생각합니다. 같은 성격의 지표. 그렇지 않으면 비네그레트가 됩니다.
이제 SrD로 돌아가십시오. 그의 예를 사용하여 환자의 평균 체온에 따라 적절하게 모든 거래에 대한 평균 하락을 계산할 수 있기 때문에 지표를 입력해야 한다는 점을 지적하고 싶습니다. SrD가 점수에 추가되는 사항을 설명할 수 있습니까? 제 생각에는 절대적으로 아무것도 아닙니다. 1,11,1,11,1,11,...의 드로우다운은 SrD의 6,6,6,6,6,6,..의 드로다운과 동일합니다. 나는 당신이 그러한 평가에 동의할 지지자를 여기에서 찾을 것이라고 생각하지 않습니다. 특히 예금의 사망이 10의 인출에서 발생하는 경우. 최대 인출이 왜 가치가 있는지 이해합니까? 그것은 당신의 예금이 얼마나 죽음에 가까웠는지 그리고 결승선에서 그가 살았는지 죽었는지를 나타냅니다. SrD 자체는 아무 것도 나타내지 않습니다. 같은 성질의 지표와 비교하지 않고 그냥 공중에 매달아 평가도 하지 않고 아무 가치가 없습니다. 정말로 이와 같은 것을 입력하고 싶다면 SrProfit을 계산하여 SrD와 비교하지만 MD는 비교하지 않으며, 잔액의 성장률과는 비교도 하지 마십시오.
지표를 얻은 후에는 지표를 곱해야합니다. 한 지표가 다른 지표보다 더 중요하다면 더 "강력한" 기능을 사용해야 합니다. 예를 들어, 더 중요한 지표를 제곱하거나 덜 중요한 지표에서 로그, 제곱근 등을 취합니다. 등. 기능을 사용하여 지표에 가중치를 부여하는 것은 취향과 선호의 문제입니다. 이러한 곱셈 뒤에는 통계가 없으며, 이는 대략적인 근사치일 뿐이므로 의미가 있습니다. 즉, 귀하에게 중요한 지표에 대한 기준의 비례성입니다. 하지만 당신이 하는 일 - 이익을 막대로 나누고 성장률을 다른 감소로 나눈 값을 더하고, 10초와 4초로 눈으로 정규화하려고 시도합니다. - 계산 뒤에 엄격한 수학 공식이 있다면 이것은 사실일 것입니다. 장소를 지정하는 동안 공식은 대략적인 근사치도 아닙니다. 왜냐하면 지표가 없습니다.
이제 SrD로 돌아가십시오. 그의 예를 사용하여 환자의 평균 체온에 따라 적절하게 모든 거래에 대한 평균 하락을 계산할 수 있기 때문에 지표를 입력해야 한다는 점을 지적하고 싶습니다. SrD가 점수에 추가되는 것을 설명할 수 있습니까? 제 생각에는 절대적으로 아무것도 아닙니다. 1,11,1,11,1,11,...의 드로우다운은 SrD의 6,6,6,6,6,6,..의 드로다운과 동일합니다. 나는 당신이 그러한 평가에 동의할 지지자를 여기에서 찾을 것이라고 생각하지 않습니다. 특히 드로다운이 10일 때 보증금이 소멸되는 경우입니다. 왜 최대 드로다운이 가치가 있는지 이해하십니까? 그것은 당신의 예금이 얼마나 죽음에 가까웠는지 그리고 결승선에서 그가 살았는지 죽었는지를 나타냅니다. SrD 자체는 아무 것도 나타내지 않습니다. 같은 성질의 지표와 비교하지 않고 그냥 공중에 매달아 평가도 하지 않고 아무 가치가 없습니다. 정말로 이와 같은 것을 입력하고 싶다면 SrProfit을 계산하여 SrD와 비교하지만 MD는 비교하지 않으며, 잔액의 성장률과는 비교도 하지 마십시오.
MD는 가장 중요한 지표 중 하나입니다. 그리고 우리의 임무는 이 지표의 정직성을 드러내는 것입니다. 무슨 뜻인가요? 예를 들어 설명하겠습니다. 서로 비슷한 두 개의 구절이 있고 둘 다 같은 단점이 있고 다른 모든 것도 근처에 있다고 가정합니다. 처음에는 근본적인 차이가 없습니다. 사실, 한 구절에서 드로우다운은 위험한 거래(열지 않고 우리가 보지 못하는)에 맞도록 조정되고, 다른 하나에서는 반대로 드로우다운이 대부분 작고 만 한 번의 무작위 거래에서 동일한 수준에 도달했습니다. 결과적으로 우리는 근본적으로 다른 두 가지 패스를 얻습니다. 각 트랜잭션의 드로우다운이 셰이딩이라고 상상하면 SrD는 이 셰이딩의 밀도와 반경을 결정하고 최대 드로우다운(예: 15%)이 우연히 일치한다는 것을 분명히 보여줍니다. -30%(신호에서 밀리미터 단위로 열리지 않아 보이지 않음) 또는 그 반대로 실수로 5-10%에서 빠져 나옵니다(모든 위치에서 최대 개방).
PF는 또한 가장 중요한 지표 중 하나입니다. 또한 밀리미터 단위로 위험한 거래를 우회하여 쉽게 최적화할 수 있습니다. 나를 위해 모든 거래를 열고 PF 1.8을 얻는 것이 좋습니다. 그러나 모든 위험하고 안전한 거래를 확인하고 실제로(최적화 후) 신호를 약간 좁히고 PF 2-3을 얻으십시오. 최적화에서 차량의 수명은 험난해야 하지만 실제로는 작업이 더 쉬워질 수 있습니다. 게다가 여기서 잃는 거래는 더 이상 필요하지 않습니다... "배우기는 어렵다 - 싸우는 것은 쉽다"는 말처럼 그래야만 합니다...
PipBar - 예를 들어 중요성을 설명합니다. 다시 말하지만 두 개의 패스는 서로 비슷하며 트랜잭션 수는 동일합니다. 한 번의 패스에서만 거래가 평균적으로 열리고 반나절 동안 산재되어 잘 닫힙니다. 다른 하나에서는 열리고 5-10분 후에 점프가 있고 검정색에서도 닫힙니다. 결과는 같지만 시간 사용이 근본적으로 다릅니다. 테스트 기간은 동일하지만(예: 1년). PipBar - 사용된 시간의 품질을 투명하게 보여줍니다. TS는 잔액에서 돈을 빌려 최소 기간 동안 최대 수익으로 거래를 완료합니다!
MD는 가장 중요한 지표 중 하나입니다. 그리고 우리의 임무는이 지표의 정직성을 밝히는 것입니다. 무슨 뜻인가요? 예를 들어 설명하겠습니다. 서로 비슷한 두 개의 구절이 있고 둘 다 같은 단점이 있고 다른 모든 것도 근처에 있다고 가정합니다. 처음에는 근본적인 차이가 없습니다. 사실, 패스 중 하나에서 드로우다운은 위험한 거래(열지 않았고 보이지 않음)에 맞도록 조정됩니다 . 어떻게 깨끗한 물 SRD로 가져오는가? - 그리고 반대로 드로우다운이 거의 없는 편인데, 랜덤거래 1건에서만 같은 수준 -위험한 거래 수준에 도달했겠죠? . 결과적으로 우리는 근본적으로 다른 두 가지 패스를 얻습니다. 각 트랜잭션의 드로우다운이 셰이딩이라고 상상하면 SrD는 이 셰이딩의 밀도와 반경을 결정하고 최대 드로우다운(예: 15%)이 우연히 일치한다는 것을 분명히 보여줍니다. -30%(신호에서 밀리미터 단위로 열리지 않아 보이지 않음) 또는 그 반대로 실수로 5-10%에서 빠져 나옵니다(모든 위치에서 최대 개방). - 1-11-1-11-... 대 위험한 거래의 예를 들었습니다.
PF는 또한 가장 중요한 지표 중 하나입니다. 또한 밀리미터 단위로 위험한 거래를 우회하여 쉽게 최적화할 수 있습니다. 저에게는 모든 거래를 열고 PF 1.8을 받는 것이 좋습니다. 그러나 모든 위험하고 안전한 거래를 보려면 위험하고 안전한 거래에 대한 정의가 있으며 언제 열리나요? 위에서, 당신은 그것들을 드로다운과 연관시킵니다. 그것이 무엇인지 이해하기 어렵습니다. 실제로 (최적화 후) 신호를 약간 좁히고 PF 2-3을 얻습니다. 최적화에서 차량의 수명은 험난해야 하지만 실제로는 작업이 더 쉬워질 수 있습니다. 게다가 여기서 지는 거래는 더 이상 필요하지 않습니다... "배우기는 어렵다 - 싸우기는 쉽다", 그래야만 합니다... - 직관적으로, 나는 당신이 성취하고자 하는 바를 이해합니다. 최적화를 위해 매개변수 PF=1.8을 설정하고 PF=1.8로 실행하는지 의심스럽습니다. 그러나 작업을 위해 PF=2-3으로 설정합니다. 물론 최적화 및 작업 옵션은 다른 매개변수에서 다릅니다. 그리고 최적화 모드에서 "위험하고 안전한" 거래를 수집하고 모든 것이 최고인지 확인한 다음 "위험한" 거래를 끄고 염두에 두십시오. "위험한"거래를 알고 있으면 나는 그들을 통제합니다. 결국 나는 작업 버전에서 그것을 끄고 발생하더라도 나에게 위협이되지 않습니다. 이것은 환상입니다. "내가 뭘 하고 있는 거지? 나는 악어를 몰아낸다 - 그래서 그들은 여기서 태어난 것이 아니다 - 내가 그들을 너무 잘 몰아내었기 때문이다. 그리고 과학적으로, 빈 세트의 어떤 요소에 대한 어떤 진술도 사실이다. 무엇이든 존재하지 않는 거래, 작동하는 변형 및 기타 항목에서 열리지 않은 거래를 생각할 수 있습니다. 모든 것이 정확할 것입니다. "모든 거래를 여는 것이 더 좋습니다"는 최적화된 매개변수 세트 하나로 현실을 보여줍니다. "약간 좁음 신호 " - 처음부터 거래가없는 또 다른 현실. 좁은 신호에서 열리지 않은 존재하지 않는 거래는 당신의 상상에만 존재합니다. 그리고 자연스럽게, 당신은 그것들이 "존재"한다는 것을 알고 있습니다. 모든 것이 통제되고 있다는 것 - "신호 좁히기"로 그들을 겁먹게 만들었습니다. "좁은 신호"의 조건에서 미개봉 거래가 없다는 것을 이해하려고 노력하십시오. 우리는 그들의 속성을 모르지만 그것에 대해 무엇이든 상상할 수 있습니다 . 이리야 신호로 현실을 바꿉니다. 나는 팬텀의 무게를 재는 데 시간을 낭비하지 않을 것입니다. 사실에서 시작하십시오. 각 실행마다 다릅니다.
PipBar - 예를 들어 중요성을 설명합니다. 다시 말하지만 두 개의 패스는 서로 비슷하며 트랜잭션 수는 동일합니다. 한 번의 패스에서만 거래가 평균적으로 열리고 반나절 동안 산재되어 잘 닫힙니다. 다른 하나에서는 열리고 5-10분 후에 점프가 있고 검정색에서도 닫힙니다. 결과는 같지만 시간 사용이 근본적으로 다릅니다. 테스트 기간은 동일하지만(예: 1년). PipBar - 사용된 시간의 품질을 투명하게 보여줍니다. TS는 잔액에서 돈을 빌려 최소 기간 동안 최대 수익으로 거래를 완료합니다! - 욕망은 이해하지만 방법론적 접근이 잘못된 것이다. 거래(들)을 위해 보증금에서 빌린 돈의 가치를 계산하고 그것을 같은 성격의 것과 비교하십시오. 그 비용이 당신에게 옳게 보일 것입니다. 또는 비용의 역수에 기준을 곱합니다. 비용이 높을수록 더 나빠집니다. 그래서 그렇지? 그리고 당신은 그것을 안정성에 추가합니다. 당신이 하고 있는 것은 다음과 같은 유형의 기준에 대한 계수를 보정하려는 시도입니다: 최대 속도 / 자동차 비용 + 에어백 수 / 100km당 연료 소비 + 전력 / 크레딧 %
일정한 로트로 최적화할 때 대답하고자 하는 첫 번째 질문은 TS에서 예상되는 감소 수준입니다. 인출 수준이 초기 보증금의 30%라고 가정해 보겠습니다. 최적화 과정에서 불필요한 옵션이 제거되도록 실제로 이 기준을 구현하는 방법은 무엇입니까? 예를 들면 다음과 같습니다.
if( optimization ){double equity =AccountEquity();if( equity > MaxEqu ) MaxEqu = equity ;if( MaxEqu - equity > MaxDD ) MaxDD = MaxEqu - equity ;// MaxDDn - уровень максиальнодопустимой просадки// Min.Loss.Series - минимальная серия убыточных сделок. Критерий для оптимизацииif( MaxDD > MaxDDn ){for( i =1; i <= Min . Loss . Series ; i ++){int last . ticket =OrderSend(Symbol(),OP_BUY, absAmount ,Ask,3,0,0,"", Magic_№ ,0,CLR_NONE);OrderClose( last . ticket , absAmount ,Bid,3,CLR_NONE);}return(0);}}
최적화 후 Excel로 전송하는 옵션을 선택합니다. 기준에 따라 정렬 - 회복 계수(이익/최대 손실).
두 번째 질문은 실제 거래에서 어떤 옵션을 사용할 것인가입니다. 최상의 옵션이 10%의 손실을 제공한다고 가정해 보겠습니다. 우리는 3배 더 인출을 허용합니다. 즉, 거래량을 3배 늘릴 수 있습니다. 하지만... 앞으로 선택한 옵션의 매개변수가 저하될 수 있습니다. 일반적으로 이런 일이 발생합니다.
그런 다음 하나의 옵션 대신 단일 로트(0.01, 0.1, 1 등)와 동일한 거래량이 있는 옵션 그룹을 동시에 사용할 수 있습니다. 동시에 동시에 열려 있는 트랜잭션 수에 대한 제한을 설정합니다. 예를 들어, 우리는 20명의 Expert Advisors를 거래하도록 설정했지만 단일 볼륨으로 3개의 포지션만 열 수 있습니다. 포지션을 열기 전에 다음을 확인합니다.
저것. 1명이 아닌 20명의 전문가가 초기 보증금의 30%를 잠재적으로 인출할 확률을 재분배합니다.
이제 이 20명의 전문가를 선택하는 것이 과제입니까? 상위 20개 옵션을 선택하는 것은 잘못된 결정입니다. 결국 많은 옵션은 최적화 기간 동안 동일한 수의 트랜잭션 을 갖습니다. 즉, 동기적으로 작동합니다. 따라서 트랜잭션 수와 복구 요소를 기준으로 정렬합니다. 각 그룹에서 최상의 옵션을 선택합니다.
주제가 잠잠해졌습니다. 질문이 공중에 떠 있습니다. "멍청한"(단일 패스) 최적화에서 수익성이 있는 많은 Expert Advisors를 사용한 다음 포워드가 아닌 경우 병합한 다음 데모에서, 데모가 아닌 경우 실제에서 병합할 때까지 깨달았습니다. 나는이 질문을 스스로 결정합니다. 더 이상 움직이지 않을 것입니다 .... 아무데도 :) ..............
가치가 있는 것이 무엇인지 확인하면 전체 간격에 대해 2개, 최대 3개 및 최종 최적화의 그룹화를 수행합니다. 가장 좋은 것을 선택한 다음 데모를 선택합니다. ... 보장 없음, 아니오 아직 통계 :)
........................................................... 이 게시물은 2008년 10월 4일 오후 12시 5분에 작성되었습니다. 통계가 이미 표시되어야 합니다!!!
게시물로 판단하면 모든 사람이 자신의 기준과 FNP(최종 매개변수 집합) 선택 결과에 어느 정도 만족합니다. ........................................... 그래서 질문을 던집니다. 3주 기록에 대해 최적화하는 특정 TS가 있다고 가정하고 최적화 결과를 기반으로 FRR을 선택한 다음 실제(또는 OOS)에 대한 한 주 동안 FRR은 해당 주 동안 변경되지 않습니다. 주말에 결과를 수정합니다. 따라서 우리는 52주기(주)를 반복하며, 한 주 앞으로 이동합니다. 일년.
주간 거래(테스트) 결과가 양수이거나 0이면 성공으로 간주합니다.
질문: 최종 매개변수 세트를 선택하는 기준과 방법을 적용하면 얼마나 많은 성공을 거둘 수 있습니까?
때문에 질문드립니다. 최적화 결과를 바탕으로 FNP를 선정하는 방법론을 찾는 데 그 자신도 깊숙이 관여했다. 나는 이 주제에 대한 나의 경험에 대해 조금 후에 글을 쓸 것입니다.
으어어어어! 으어어어어어어어어어어어어어어어어어어어어어! 다들 어디 숨어있니? 나는 당신이 여기 있다는 것을 알고 있습니다...))) 좋아, 네가 숨어 있는 동안 내 이야기를 할 시간이 있어. .............. a) 시장이 불안정하다는 것을 이해한 후, b) 오랫동안 고정된 매개변수로 수익을 내는 Expert Advisor를 만드는 것은 불가능할 것입니다. c) ... 기타 중요한 이해, 작업은 다음과 같이 설정되었습니다. Expert Advisor 최적화의 결과 중에서 이러한 최종 매개변수 집합(FNP)을 선택하는 방법을 학습하는 것입니다. 이를 사용하면 통계적으로 안정적으로 긍정적인 수학적 기대치를 제공할 수 있습니다. 모든 것이 명확해 보이지만 만일을 대비하여 이전 게시물의 예를 들어 설명하겠습니다.
3주간의 이력에 대해 최적화하는 특정 TS가 있다고 가정하고 최적화 결과를 기반으로 FNP를 선택한 다음 실제(또는 OoS 테스트)의 경우 일주일 동안 발견된 매개변수가 변경, 주말에 결과를 수정합니다. 따라서 우리는 52주기(주)를 반복하며, 한 주 앞으로 이동합니다. 일년. 주간 거래(테스트) 결과가 양수이거나 0이면 성공으로 간주합니다.
저것들. 예를 들어, 52주 중 40주 결과가 성공적이고 12주 실패 중 평균 손실이 1126 USD인 경우, 평균 수익성이 있는 주는 -1777 USD와 같으며 문제를 완벽하게 해결했다고 믿습니다. (우리는 520주 또는 5200주 표본의 결과를 갖는 것이 더 낫다는 것을 이해합니다. 그러나 우리는 이 크기의 표본에서도 결과의 비율이 변하지 않는다고 가정할 이유가 있습니다) ....... 작업이 심각하다는 데 동의합니다. 찾는 성배보다 더 시원합니다. 왜냐하면 이론적으로 이 방법에 따르면 모든 MTS를 사용할 수 있습니다. topic-starter도 이에 대해 우리에게 씁니다.
- 단계적으로 (deinit에서) 어드바이저의 모든 외부 매개변수와 필요한 기준을 csv 파일에 씁니다. - 최적화가 끝나면 Excel에 로드하고 1분 안에 모든 패스가 포함된 형식이 지정되고 바로 사용할 수 있는 xls 파일이 생성됩니다.
그리고 여기서 질문이 생깁니다. 이 모든 "부"로 다음에 무엇을 해야 할까요?
이미 대략적으로 설명된 모델에 대해 FNP를 선택하는 프로세스를 자동화하는 것부터 시작하기로 결정했습니다. 예를 들어: 1차에서 300차까지 1차 하위 그룹 최적화 패스를 취합니다. 1. 50개 미만의 거래 - 필터링(220개 남음) 2. ProfitFactor가 2보다 작음 - 필터링(78개 남음) 3. 30% 미만 또는 70% 이상의 이익(중간) - 필터링(33개 남음) .... 필터를 사용하여 절대값, 상대값(%), 위치 번호별로 총 6개의 기준을 처리할 수 있습니다. 두 가지 유형의 필터 - 대역 통과(내부, 외부) 및 경계(더, 적음) 7. FNP를 직접 선택합니다. 예를 들어 균형 곡선의 진직도를 담당하는 기준이 최대값을 갖는 집합일 것입니다.
이제 사용 가능한 FNP 패스 번호에 따라 테스트에서 이 하위 그룹(OoS와 같은 종류)의 300개 패스에 해당하는 패스를 찾아 수익을 수정합니다. 각 하위 그룹에 대해서도 마찬가지입니다.
결과적으로 대차 대조표와 주간(이 경우) "트랜잭션" 지표로 수행된 작업에 대한 보고서를 받습니다. 모든 것이 화려해 보입니다. 하지만...
결과: 선택 방법에서 안정적인 패턴을 찾을 수 없었습니다. 모든 것이 괜찮은 것 같지만 뭔가 잘못되었습니다. 난 믿지 않아!!! (위대한 분이 말했듯이...) 동시에, 이 접근 방식은 잠재력이 있고 거대하다고 믿어집니다. 이 문제를 오랫동안 다루지 않고 한가지 전략만 테스트 해봤습니다(이제 이 주제를 개발하고 난 후 어디서, 왜 겪었는지 기억을 하려고 합니다....)
질문: 1. 어떻게 생각하세요? 모든 차량이 그러한 치료에 적합하지 않을 수 있습니까? 저것들. 시간적으로 더 안정적이고 이 안정성의 어떤 기준을 도입하여 즉시 결정해야 하는지 - Our TS / Not our TS. 2. 여기서 무엇이 잘못되었습니까? 다른 접근 방식을 본 사람이 있습니까? 3. 나는 여전히 당신의 결과에 대해 듣고 싶습니다. 이 페이지의 첫 번째 게시물(y)에서 이미 질문을 했습니다.
권하다: 하나의 기성 전략을 집합적으로 선택하고(MTS 또는 신뢰할 수 있는 작성자가 이미 디버그함) 다시 집합적으로 문제 해결을 시도합니다(또는 적어도 솔루션에 더 가까워짐). 내가 설명한 기능을 사용하여 (그러나 나는 그것이 가능하고 또 다른 유사한 제안이라고 주장하지 않습니다).
테스트 결과가 여기에 게시될지, 여기에 게시되지 않을지, 다시 한 번 함께 결정할 수 있습니다. 원하는 경우 새 스레드를 열 수 있습니다. 결과 만 있고 이 주제가 사라지지 않고 발전했다면.
덧셈. 1. 도구는 매우 유연합니다. 최적화 결과를 선택하기 위한 모든 방법을 공식화할 수 있습니다. 물론입니다. 2. 최종 매개변수 집합을 찾는 방법을 최적화하는 기능이 있다는 말은 전혀 하지 않았습니다. 유형 최적화 최적화 매개변수. 각 기준에 대한 범위와 단계, 경계 유형 및 필터 모드를 선택하고 최적화를 시작합니다. 한 번 보는 게 낫지...
(PF-1)*SdDay - 이 계수가 Vigoda 표시기의 주요 볼륨을 캡처하는 것을 방지하기 위한 상한값. 거래가 많을수록 높은 수익성을 달성하기가 더 어렵습니다.
(PF-1) - 음의 균형 표시기로 PF 승수도 음이 되도록 수행됩니다. 이것은 첫 번째 지표로 사용되므로 다음 지표도 총계의 양에 영향을 미치며 우세하지 않아야 합니다.
((PipBar+Ust)/10) - 포지션을 열 때 시간은 우리에게 유리하지 않습니다. 왜냐하면 시장은 언제든지 바뀔 수 있으며 PipBar 표시기(이제 PipMin, pip/min으로 변경)는 사용된 시간의 품질을 보여줍니다. 최소 시간에 최대 포인트 수. Ust - 지속 가능성도 중요합니다. 지표가 높을수록 균형의 성장이 더 원활해집니다. 10으로 나누면 총계에 미치는 영향이 동일합니다.
(ProcDay*10)/(MD+(SrD*4)) - 이 동안 사용된 위험에 대한 잔액 성장률의 비율입니다. 10과 4를 곱하면 전체 지표에 미치는 영향도 동일해집니다.
덧셈 대신 곱셈을 사용하면 각 지표의 영향을 균형 잡기가 더 어렵습니다. 이로 인해 결과가 때때로 부당하게 점프합니다. 저를 믿으십시오. 하나의 매개변수가 약간 과대평가된 경우 모든 것이 이미 확인되었습니다. 그런 다음 곱할 때 합계를 잘못된 상단으로 가져오는 경우가 많습니다.
계속해서 공식을 수정하고 있으며 나중에 업데이트 및 비교를 게시할 예정입니다...
(PF-1)*SdDay - 이 계수가 Vigoda 표시기의 주요 볼륨을 캡처하는 것을 방지하기 위한 상한. - 1. Profit Factor에 대한 잘못된 의존성을 명시적으로 사용함을 나타냅니다. 거래가 많을수록 높은 수익성을 달성하기가 더 어렵습니다. - 2. 다르게 공식화하면 할수록 랜덤한 결과를 얻기가 어려울수록 높은 수익성으로 달성합니다.
(PF-1) - 음의 균형 표시기로 PF 승수도 음이 되도록 수행됩니다. - 3. 마이너스 잔액에는 마이너스가 있고 이익 계수는 < 1입니다. 이는 합리적이고 체계적으로 정당화됩니다. 하나를 다른 것으로 재정의하는 요점이 무엇입니까? 이것은 첫 번째 지표로 사용되므로 다음 지표도 총계에 영향을 미치며 우세하지 않아야 합니다. -
((PipBar+Ust)/10) - 포지션을 열 때 시간은 우리에게 유리하지 않습니다. 왜냐하면 시장은 언제든지 바뀔 수 있으며 PipBar 표시기(이제 PipMin, pip/min으로 변경)는 사용된 시간의 품질을 보여줍니다. 최소 시간에 최대 포인트 수. - 4. 테스트 기간의 길이에 대한 기준의 역 의존성이 더 간단하고 명확해졌습니다. Ust-안정성도 중요하지 않습니다. 지표가 높을수록 균형 평균의 성장이 더 원활해 집니다. - 5. 이익을 최대 인출액으로 나눈 잔고의 순조로운 성장과 맞지 않습니다. 나는 그것을 부르지 않을 것입니다. 10으로 나누면 총계에 미치는 영향이 동일합니다. - 6. 이것은 일부 통계 공식 계산의 결과입니까 아니면 "대략 적합" 유형의 평균 한도 경험주의입니까?
(ProcDay*10)/(MD+(SrD*4)) - 이 동안 사용된 위험에 대한 잔액 성장률의 비율입니다. 4. 테스트 기간의 길이에 대한 기준의 역 의존성은 더 간단하고 명확합니다. 10과 4를 곱하여 전체 지표에 미치는 영향을 균등하게 합니다. - 6. 이 10과 4는 일종의 통계 공식 계산 또는 "대략 적합" 유형의 평균 한도 경험주의의 결과입니까?
덧셈 대신 곱셈을 사용하면 각 지표의 영향을 균형 잡기가 더 어렵습니다. 이로부터 합계가 때때로 부당하게 점프합니다. 저를 믿으십시오. 하나의 매개 변수가 약간 과대 평가되면 모든 것이 이미 확인되었으며 곱할 때 종종 합계를 잘못된 상단으로 가져옵니다. - 1. Profit Factor, Profit, Maximum Drawdown, 테스트 기간의 길이에 대한 잘못된 의존성의 명시적 사용을 나타냅니다.
공식을 계속 수정하고 있으며 나중에 업데이트 및 비교를 게시할 예정입니다...
간단한 예를 보여 드리면 귀하의 접근 방식이 방법론적으로 올바르지 않다는 것을 이해하게 될 것입니다.
균형 표시기는 "더 많은 돈"이라는 꿈과 비교하기 때문에 우리에게 가치가 있습니다. 잔고와 "더 많은 돈"은 같은 성질의 지표이며 잔고가 클수록 "더 많은 돈"에 가깝습니다.
최대 손실액의 지표는 "예금이 사라졌습니다"라는 악몽과 비교하기 때문에 우리에게 가치가 있습니다. 최대 인출액과 "손실된 보증금"은 다시 동일한 성격의 지표이며, 최대 인출액이 작을수록 "손실된 보증금"에서 멀어집니다.
이익 요소는 모든 이익의 합계를 모든 손실의 합계와 비교하기 때문에 우리에게 가치가 있습니다. 놀랍게도 사실은 모든 이익의 합과 모든 손실의 합이 다시 같은 성질의 지표이며 이익이 많을수록 손실이 적을수록 우리에게 더 가치있는 지표라는 것입니다.
동질적인 지표를 비교(더하기, 나누기, 곱하기)하는 것이 얼마나 중요한지 대략적으로 이해하셨으리라 생각합니다. 같은 성격의 지표. 그렇지 않으면 비네그레트가 됩니다.
이제 SrD로 돌아가십시오. 그의 예를 사용하여 환자의 평균 체온에 따라 적절하게 모든 거래에 대한 평균 하락을 계산할 수 있기 때문에 지표를 입력해야 한다는 점을 지적하고 싶습니다. SrD가 점수에 추가되는 사항을 설명할 수 있습니까? 제 생각에는 절대적으로 아무것도 아닙니다. 1,11,1,11,1,11,...의 드로우다운은 SrD의 6,6,6,6,6,6,..의 드로다운과 동일합니다. 나는 당신이 그러한 평가에 동의할 지지자를 여기에서 찾을 것이라고 생각하지 않습니다. 특히 예금의 사망이 10의 인출에서 발생하는 경우. 최대 인출이 왜 가치가 있는지 이해합니까? 그것은 당신의 예금이 얼마나 죽음에 가까웠는지 그리고 결승선에서 그가 살았는지 죽었는지를 나타냅니다. SrD 자체는 아무 것도 나타내지 않습니다. 같은 성질의 지표와 비교하지 않고 그냥 공중에 매달아 평가도 하지 않고 아무 가치가 없습니다. 정말로 이와 같은 것을 입력하고 싶다면 SrProfit을 계산하여 SrD와 비교하지만 MD는 비교하지 않으며, 잔액의 성장률과는 비교도 하지 마십시오.
지표를 얻은 후에는 지표를 곱해야합니다. 한 지표가 다른 지표보다 더 중요하다면 더 "강력한" 기능을 사용해야 합니다. 예를 들어, 더 중요한 지표를 제곱하거나 덜 중요한 지표에서 로그, 제곱근 등을 취합니다. 등. 기능을 사용하여 지표에 가중치를 부여하는 것은 취향과 선호의 문제입니다. 이러한 곱셈 뒤에는 통계가 없으며, 이는 대략적인 근사치일 뿐이므로 의미가 있습니다. 즉, 귀하에게 중요한 지표에 대한 기준의 비례성입니다. 하지만 당신이 하는 일 - 이익을 막대로 나누고 성장률을 다른 감소로 나눈 값을 더하고, 10초와 4초로 눈으로 정규화하려고 시도합니다. - 계산 뒤에 엄격한 수학 공식이 있다면 이것은 사실일 것입니다. 장소를 지정하는 동안 공식은 대략적인 근사치도 아닙니다. 왜냐하면 지표가 없습니다.
Vita писал(а) >>
이제 SrD로 돌아가십시오. 그의 예를 사용하여 환자의 평균 체온에 따라 적절하게 모든 거래에 대한 평균 하락을 계산할 수 있기 때문에 지표를 입력해야 한다는 점을 지적하고 싶습니다. SrD가 점수에 추가되는 것을 설명할 수 있습니까? 제 생각에는 절대적으로 아무것도 아닙니다. 1,11,1,11,1,11,...의 드로우다운은 SrD의 6,6,6,6,6,6,..의 드로다운과 동일합니다. 나는 당신이 그러한 평가에 동의할 지지자를 여기에서 찾을 것이라고 생각하지 않습니다. 특히 드로다운이 10일 때 보증금이 소멸되는 경우입니다. 왜 최대 드로다운이 가치가 있는지 이해하십니까? 그것은 당신의 예금이 얼마나 죽음에 가까웠는지 그리고 결승선에서 그가 살았는지 죽었는지를 나타냅니다. SrD 자체는 아무 것도 나타내지 않습니다. 같은 성질의 지표와 비교하지 않고 그냥 공중에 매달아 평가도 하지 않고 아무 가치가 없습니다. 정말로 이와 같은 것을 입력하고 싶다면 SrProfit을 계산하여 SrD와 비교하지만 MD는 비교하지 않으며, 잔액의 성장률과는 비교도 하지 마십시오.
MD는 가장 중요한 지표 중 하나입니다. 그리고 우리의 임무는 이 지표의 정직성을 드러내는 것입니다. 무슨 뜻인가요? 예를 들어 설명하겠습니다. 서로 비슷한 두 개의 구절이 있고 둘 다 같은 단점이 있고 다른 모든 것도 근처에 있다고 가정합니다. 처음에는 근본적인 차이가 없습니다. 사실, 한 구절에서 드로우다운은 위험한 거래(열지 않고 우리가 보지 못하는)에 맞도록 조정되고, 다른 하나에서는 반대로 드로우다운이 대부분 작고 만 한 번의 무작위 거래에서 동일한 수준에 도달했습니다. 결과적으로 우리는 근본적으로 다른 두 가지 패스를 얻습니다. 각 트랜잭션의 드로우다운이 셰이딩이라고 상상하면 SrD는 이 셰이딩의 밀도와 반경을 결정하고 최대 드로우다운(예: 15%)이 우연히 일치한다는 것을 분명히 보여줍니다. -30%(신호에서 밀리미터 단위로 열리지 않아 보이지 않음) 또는 그 반대로 실수로 5-10%에서 빠져 나옵니다(모든 위치에서 최대 개방).
PF는 또한 가장 중요한 지표 중 하나입니다. 또한 밀리미터 단위로 위험한 거래를 우회하여 쉽게 최적화할 수 있습니다. 나를 위해 모든 거래를 열고 PF 1.8을 얻는 것이 좋습니다. 그러나 모든 위험하고 안전한 거래를 확인하고 실제로(최적화 후) 신호를 약간 좁히고 PF 2-3을 얻으십시오. 최적화에서 차량의 수명은 험난해야 하지만 실제로는 작업이 더 쉬워질 수 있습니다. 게다가 여기서 잃는 거래는 더 이상 필요하지 않습니다... "배우기는 어렵다 - 싸우는 것은 쉽다"는 말처럼 그래야만 합니다...
PipBar - 예를 들어 중요성을 설명합니다. 다시 말하지만 두 개의 패스는 서로 비슷하며 트랜잭션 수는 동일합니다. 한 번의 패스에서만 거래가 평균적으로 열리고 반나절 동안 산재되어 잘 닫힙니다. 다른 하나에서는 열리고 5-10분 후에 점프가 있고 검정색에서도 닫힙니다. 결과는 같지만 시간 사용이 근본적으로 다릅니다. 테스트 기간은 동일하지만(예: 1년). PipBar - 사용된 시간의 품질을 투명하게 보여줍니다. TS는 잔액에서 돈을 빌려 최소 기간 동안 최대 수익으로 거래를 완료합니다!
나머지는 나중에 쓰겠습니다...
MD는 가장 중요한 지표 중 하나입니다. 그리고 우리의 임무는이 지표의 정직성을 밝히는 것입니다. 무슨 뜻인가요? 예를 들어 설명하겠습니다. 서로 비슷한 두 개의 구절이 있고 둘 다 같은 단점이 있고 다른 모든 것도 근처에 있다고 가정합니다. 처음에는 근본적인 차이가 없습니다. 사실, 패스 중 하나에서 드로우다운은 위험한 거래(열지 않았고 보이지 않음)에 맞도록 조정됩니다 . 어떻게 깨끗한 물 SRD로 가져오는가? - 그리고 반대로 드로우다운이 거의 없는 편인데, 랜덤거래 1건에서만 같은 수준 -위험한 거래 수준에 도달했겠죠? . 결과적으로 우리는 근본적으로 다른 두 가지 패스를 얻습니다. 각 트랜잭션의 드로우다운이 셰이딩이라고 상상하면 SrD는 이 셰이딩의 밀도와 반경을 결정하고 최대 드로우다운(예: 15%)이 우연히 일치한다는 것을 분명히 보여줍니다. -30%(신호에서 밀리미터 단위로 열리지 않아 보이지 않음) 또는 그 반대로 실수로 5-10%에서 빠져 나옵니다(모든 위치에서 최대 개방). - 1-11-1-11-... 대 위험한 거래의 예를 들었습니다.
PF는 또한 가장 중요한 지표 중 하나입니다. 또한 밀리미터 단위로 위험한 거래를 우회하여 쉽게 최적화할 수 있습니다. 저에게는 모든 거래를 열고 PF 1.8을 받는 것이 좋습니다. 그러나 모든 위험하고 안전한 거래를 보려면 위험하고 안전한 거래에 대한 정의가 있으며 언제 열리나요? 위에서, 당신은 그것들을 드로다운과 연관시킵니다. 그것이 무엇인지 이해하기 어렵습니다. 실제로 (최적화 후) 신호를 약간 좁히고 PF 2-3을 얻습니다. 최적화에서 차량의 수명은 험난해야 하지만 실제로는 작업이 더 쉬워질 수 있습니다. 게다가 여기서 지는 거래는 더 이상 필요하지 않습니다... "배우기는 어렵다 - 싸우기는 쉽다", 그래야만 합니다... - 직관적으로, 나는 당신이 성취하고자 하는 바를 이해합니다. 최적화를 위해 매개변수 PF=1.8을 설정하고 PF=1.8로 실행하는지 의심스럽습니다. 그러나 작업을 위해 PF=2-3으로 설정합니다. 물론 최적화 및 작업 옵션은 다른 매개변수에서 다릅니다. 그리고 최적화 모드에서 "위험하고 안전한" 거래를 수집하고 모든 것이 최고인지 확인한 다음 "위험한" 거래를 끄고 염두에 두십시오. "위험한"거래를 알고 있으면 나는 그들을 통제합니다. 결국 나는 작업 버전에서 그것을 끄고 발생하더라도 나에게 위협이되지 않습니다. 이것은 환상입니다. "내가 뭘 하고 있는 거지? 나는 악어를 몰아낸다 - 그래서 그들은 여기서 태어난 것이 아니다 - 내가 그들을 너무 잘 몰아내었기 때문이다. 그리고 과학적으로, 빈 세트의 어떤 요소에 대한 어떤 진술도 사실이다. 무엇이든 존재하지 않는 거래, 작동하는 변형 및 기타 항목에서 열리지 않은 거래를 생각할 수 있습니다. 모든 것이 정확할 것입니다. "모든 거래를 여는 것이 더 좋습니다"는 최적화된 매개변수 세트 하나로 현실을 보여줍니다. "약간 좁음 신호 " - 처음부터 거래가없는 또 다른 현실. 좁은 신호에서 열리지 않은 존재하지 않는 거래는 당신의 상상에만 존재합니다. 그리고 자연스럽게, 당신은 그것들이 "존재"한다는 것을 알고 있습니다. 모든 것이 통제되고 있다는 것 - "신호 좁히기"로 그들을 겁먹게 만들었습니다. "좁은 신호"의 조건에서 미개봉 거래가 없다는 것을 이해하려고 노력하십시오. 우리는 그들의 속성을 모르지만 그것에 대해 무엇이든 상상할 수 있습니다 . 이리야 신호로 현실을 바꿉니다. 나는 팬텀의 무게를 재는 데 시간을 낭비하지 않을 것입니다. 사실에서 시작하십시오. 각 실행마다 다릅니다.
PipBar - 예를 들어 중요성을 설명합니다. 다시 말하지만 두 개의 패스는 서로 비슷하며 트랜잭션 수는 동일합니다. 한 번의 패스에서만 거래가 평균적으로 열리고 반나절 동안 산재되어 잘 닫힙니다. 다른 하나에서는 열리고 5-10분 후에 점프가 있고 검정색에서도 닫힙니다. 결과는 같지만 시간 사용이 근본적으로 다릅니다. 테스트 기간은 동일하지만(예: 1년). PipBar - 사용된 시간의 품질을 투명하게 보여줍니다. TS는 잔액에서 돈을 빌려 최소 기간 동안 최대 수익으로 거래를 완료합니다! - 욕망은 이해하지만 방법론적 접근이 잘못된 것이다. 거래(들)을 위해 보증금에서 빌린 돈의 가치를 계산하고 그것을 같은 성격의 것과 비교하십시오. 그 비용이 당신에게 옳게 보일 것입니다. 또는 비용의 역수에 기준을 곱합니다. 비용이 높을수록 더 나빠집니다. 그래서 그렇지? 그리고 당신은 그것을 안정성에 추가합니다. 당신이 하고 있는 것은 다음과 같은 유형의 기준에 대한 계수를 보정하려는 시도입니다: 최대 속도 / 자동차 비용 + 에어백 수 / 100km당 연료 소비 + 전력 / 크레딧 %
나머지는 나중에 쓰겠습니다...
일정한 로트로 최적화할 때 대답하고자 하는 첫 번째 질문은 TS에서 예상되는 감소 수준입니다. 인출 수준이 초기 보증금의 30%라고 가정해 보겠습니다. 최적화 과정에서 불필요한 옵션이 제거되도록 실제로 이 기준을 구현하는 방법은 무엇입니까? 예를 들면 다음과 같습니다.
최적화 후 Excel로 전송하는 옵션을 선택합니다. 기준에 따라 정렬 - 회복 계수(이익/최대 손실).
두 번째 질문은 실제 거래에서 어떤 옵션을 사용할 것인가입니다. 최상의 옵션이 10%의 손실을 제공한다고 가정해 보겠습니다. 우리는 3배 더 인출을 허용합니다. 즉, 거래량을 3배 늘릴 수 있습니다. 하지만... 앞으로 선택한 옵션의 매개변수가 저하될 수 있습니다. 일반적으로 이런 일이 발생합니다.
그런 다음 하나의 옵션 대신 단일 로트(0.01, 0.1, 1 등)와 동일한 거래량이 있는 옵션 그룹을 동시에 사용할 수 있습니다. 동시에 동시에 열려 있는 트랜잭션 수에 대한 제한을 설정합니다. 예를 들어, 우리는 20명의 Expert Advisors를 거래하도록 설정했지만 단일 볼륨으로 3개의 포지션만 열 수 있습니다. 포지션을 열기 전에 다음을 확인합니다.
저것. 1명이 아닌 20명의 전문가가 초기 보증금의 30%를 잠재적으로 인출할 확률을 재분배합니다.
이제 이 20명의 전문가를 선택하는 것이 과제입니까? 상위 20개 옵션을 선택하는 것은 잘못된 결정입니다. 결국 많은 옵션은 최적화 기간 동안 동일한 수의 트랜잭션 을 갖습니다. 즉, 동기적으로 작동합니다. 따라서 트랜잭션 수와 복구 요소를 기준으로 정렬합니다. 각 그룹에서 최상의 옵션을 선택합니다.
나에게 " 최적화 결과의 자동 선택 기준." 이번에, 즉. 어떤 시간 간격으로든 시스템은 안정적이어야 합니다.
시장은 역동적이며, 결론은 최적화 출력 데이터의 역동성과 이에 대한 자동 선택의 불가능성에 대해 암시합니다.
ATS가 높은 시장 변동성을 드러내고 장중 모드로 전환하면 자동 선택은 어떻습니까?
2008년 하반기(08/01/2008-01/01/2009) 최적화가 의미가 없다고 가정하면 하나의 MA가 있는 ATS가 수익성이 있을 것입니다.
추세 및 비 추세 시간 간격의 선택은 옵션입니다(저는 고정된 2주 최적화를 선호합니다).
안정성을 달성하는 방법?
저의 선택 기준은 안정성 입니다. 접근 방식을 변경해 보세요. 저는 다음 과 같이 합니다.
M5에서 반년, 12개의 독립적인 최적화로 충분합니다.
일반적으로 매개변수에 대한 옵션은 50개 이하이지만 약 2-3개의 "동일한" 설정 패키지를 할당합니다.
pf 또는 ks에 의한 최적화 결과의 선택은 ATS 알고리즘을 작성하는 방법과 직접적인 관련이 있습니다.
사람은 걷는 법을 배우는 데 시간이 필요하고 권투 선수는 먼저 타이틀 자격을 얻기 위해 두 개 이상의 토너먼트를 거쳐야합니다. 여기에는 시간이 걸립니다 ...
데이터를 정렬하고 매개변수에 대해 선택한 옵션을 언제든지 실행하는 데 도움이 되는 기사 가 있습니다.
모두를 환영합니다!
스레드의 주제 및 최적화 결과 사용에 대한 기타 질문은 물론 모든 거래자에게 매우 중요합니다.
내 질문은 아래에 인용된 저자에게만 해당되는 것이 아닙니다....
얻은 분석은 아마도 여기 누군가가 말했듯이 "가장 완벽한 신경망은 하나입니다 - 머리"
그러나 심리적 결과와 실제 결과 모두 가치가 있다고 생각합니다.
거짓 겸손 없이), 나는 내가 어느 정도 도달했음을 주목한다. 당신의 선택에 행운을 빕니다 수동 최적화. 그러나 이 프로세스를 자동화할 방법이 없습니다. 아마도 이것은 제대로 형식화되지 않은 경험일 뿐입니다.
지금까지는 테스트 버전이지만 지표는 이미 만족 ...
글쎄, 그들은 내 매우 간단하지만 매우 효율적인 기준을 구걸했습니다.)
주제가 잠잠해졌습니다. 질문이 공중에 떠 있습니다. "멍청한"(단일 패스) 최적화에서 수익성이 있는 많은 Expert Advisors를 사용한 다음 포워드가 아닌 경우 병합한 다음 데모에서, 데모가 아닌 경우 실제에서 병합할 때까지 깨달았습니다. 나는이 질문을 스스로 결정합니다. 더 이상 움직이지 않을 것입니다 .... 아무데도 :)
..............
가치가 있는 것이 무엇인지 확인하면 전체 간격에 대해 2개, 최대 3개 및 최종 최적화의 그룹화를 수행합니다. 가장 좋은 것을 선택한 다음 데모를 선택합니다. ... 보장 없음, 아니오 아직 통계 :)
...........................................................
이 게시물은 2008년 10월 4일 오후 12시 5분에 작성되었습니다. 통계가 이미 표시되어야 합니다!!!
게시물로 판단하면 모든 사람이 자신의 기준과 FNP(최종 매개변수 집합) 선택 결과에 어느 정도 만족합니다.
...........................................
그래서 질문을 던집니다.
3주 기록에 대해 최적화하는 특정 TS가 있다고 가정하고 최적화 결과를 기반으로 FRR을 선택한 다음 실제(또는 OOS)에 대한 한 주 동안 FRR은 해당 주 동안 변경되지 않습니다. 주말에 결과를 수정합니다.
따라서 우리는 52주기(주)를 반복하며, 한 주 앞으로 이동합니다. 일년.
주간 거래(테스트) 결과가 양수이거나 0이면 성공으로 간주합니다.
질문: 최종 매개변수 세트를 선택하는 기준과 방법을 적용하면 얼마나 많은 성공을 거둘 수 있습니까?
때문에 질문드립니다. 최적화 결과를 바탕으로 FNP를 선정하는 방법론을 찾는 데 그 자신도 깊숙이 관여했다.
나는 이 주제에 대한 나의 경험에 대해 조금 후에 글을 쓸 것입니다.
모두를 환영합니다!
좋아, 네가 숨어 있는 동안 내 이야기를 할 시간이 있어.
..............
a) 시장이 불안정하다는 것을 이해한 후, b) 오랫동안 고정된 매개변수로 수익을 내는 Expert Advisor를 만드는 것은 불가능할 것입니다. c) ... 기타 중요한 이해,
작업은 다음과 같이 설정되었습니다. Expert Advisor 최적화의 결과 중에서 이러한 최종 매개변수 집합(FNP)을 선택하는 방법을 학습하는 것입니다. 이를 사용하면 통계적으로 안정적으로 긍정적인 수학적 기대치를 제공할 수 있습니다.
모든 것이 명확해 보이지만 만일을 대비하여 이전 게시물의 예를 들어 설명하겠습니다.
따라서 우리는 52주기(주)를 반복하며, 한 주 앞으로 이동합니다. 일년.
주간 거래(테스트) 결과가 양수이거나 0이면 성공으로 간주합니다.
저것들. 예를 들어, 52주 중 40주 결과가 성공적이고 12주 실패 중 평균 손실이 1126 USD인 경우,
평균 수익성이 있는 주는 -1777 USD와 같으며 문제를 완벽하게 해결했다고 믿습니다.
(우리는 520주 또는 5200주 표본의 결과를 갖는 것이 더 낫다는 것을 이해합니다. 그러나 우리는 이 크기의 표본에서도 결과의 비율이 변하지 않는다고 가정할 이유가 있습니다)
.......
작업이 심각하다는 데 동의합니다. 찾는 성배보다 더 시원합니다. 왜냐하면 이론적으로 이 방법에 따르면 모든 MTS를 사용할 수 있습니다. topic-starter도 이에 대해 우리에게 씁니다.
문제의 기술적 측면은 다음과 같이 해결되었습니다.
- Expert Advisor에 다양한 기준의 계산이 첨부됩니다. MT 보고서의 표준에 더하여 예를 들어 달성한 최대 이익, 테스트 시간의 %로 도달하는 시간, 확장된 Z-점수, 매수 및 매도당 평균 거래 시간, 매수 및 매도에 소요된 시간 테스트 시간의 % 등 .. 등 한마디로 많을수록 좋다. 추가 정보 - 발생하지 않습니다. (내 거래에 대한 정보를 의미합니다 ;-)))
- IsBackTestingTime.mqh 기능은 Expert Advisor에 첨부되어 있습니다. Copyright © 2008, Nikolay Kositsin. 다시 수정했지만 본질은 비슷합니다. 이전 예를 사용하겠습니다. EA가 각각 10개의 값으로 구성된 두 개의 매개변수를 최적화하고 하나 더 - 세 개의 값을 최적화한다고 가정해 보겠습니다. 하나의 완전한(GA 없이) 최적화를 실행하기 위해 필요한 최적화 및 테스트 기간과 이러한 기간의 이동을 설정하면 31200 = 300*52 + 300*52 패스, 즉 최적화 기간의 300개 통과 및 테스트 기간의 300개 통과로 구성된 52개의 하위 그룹(기간의 이전 통과에 비해). 엔코시신님의 글과 사진이 있습니다
나는 오랫동안 떠나지 않을 것이고, 나는 계속할 것입니다 ....
은신처 나오는중 은신좀 그만해....)))
- 단계적으로 (deinit에서) 어드바이저의 모든 외부 매개변수와 필요한 기준을 csv 파일에 씁니다.
- 최적화가 끝나면 Excel에 로드하고 1분 안에 모든 패스가 포함된 형식이 지정되고 바로 사용할 수 있는 xls 파일이 생성됩니다.
그리고 여기서 질문이 생깁니다. 이 모든 "부"로 다음에 무엇을 해야 할까요?
이미 대략적으로 설명된 모델에 대해 FNP를 선택하는 프로세스를 자동화하는 것부터 시작하기로 결정했습니다. 예를 들어:
1차에서 300차까지 1차 하위 그룹 최적화 패스를 취합니다.
1. 50개 미만의 거래 - 필터링(220개 남음)
2. ProfitFactor가 2보다 작음 - 필터링(78개 남음)
3. 30% 미만 또는 70% 이상의 이익(중간) - 필터링(33개 남음)
.... 필터를 사용하여 절대값, 상대값(%), 위치 번호별로 총 6개의 기준을 처리할 수 있습니다. 두 가지 유형의 필터 - 대역 통과(내부, 외부) 및 경계(더, 적음)
7. FNP를 직접 선택합니다. 예를 들어 균형 곡선의 진직도를 담당하는 기준이 최대값을 갖는 집합일 것입니다.
이제 사용 가능한 FNP 패스 번호에 따라 테스트에서 이 하위 그룹(OoS와 같은 종류)의 300개 패스에 해당하는 패스를 찾아 수익을 수정합니다.
각 하위 그룹에 대해서도 마찬가지입니다.
결과적으로 대차 대조표와 주간(이 경우) "트랜잭션" 지표로 수행된 작업에 대한 보고서를 받습니다. 모든 것이 화려해 보입니다. 하지만...
결과:
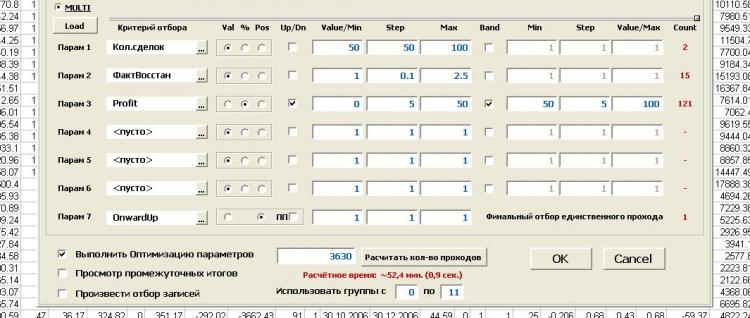
선택 방법에서 안정적인 패턴을 찾을 수 없었습니다. 모든 것이 괜찮은 것 같지만 뭔가 잘못되었습니다. 난 믿지 않아!!! (위대한 분이 말했듯이...)
동시에, 이 접근 방식은 잠재력이 있고 거대하다고 믿어집니다.
이 문제를 오랫동안 다루지 않고 한가지 전략만 테스트 해봤습니다(이제 이 주제를 개발하고 난 후 어디서, 왜 겪었는지 기억을 하려고 합니다....)
질문:
1. 어떻게 생각하세요? 모든 차량이 그러한 치료에 적합하지 않을 수 있습니까? 저것들. 시간적으로 더 안정적이고 이 안정성의 어떤 기준을 도입하여 즉시 결정해야 하는지 - Our TS / Not our TS.
2. 여기서 무엇이 잘못되었습니까? 다른 접근 방식을 본 사람이 있습니까?
3. 나는 여전히 당신의 결과에 대해 듣고 싶습니다. 이 페이지의 첫 번째 게시물(y)에서 이미 질문을 했습니다.
권하다:
하나의 기성 전략을 집합적으로 선택하고(MTS 또는 신뢰할 수 있는 작성자가 이미 디버그함) 다시 집합적으로 문제 해결을 시도합니다(또는 적어도 솔루션에 더 가까워짐).
내가 설명한 기능을 사용하여 (그러나 나는 그것이 가능하고 또 다른 유사한 제안이라고 주장하지 않습니다).
테스트 결과가 여기에 게시될지, 여기에 게시되지 않을지, 다시 한 번 함께 결정할 수 있습니다.
원하는 경우 새 스레드를 열 수 있습니다.
결과 만 있고 이 주제가 사라지지 않고 발전했다면.
덧셈.
1. 도구는 매우 유연합니다. 최적화 결과를 선택하기 위한 모든 방법을 공식화할 수 있습니다. 물론입니다.
2. 최종 매개변수 집합을 찾는 방법을 최적화하는 기능이 있다는 말은 전혀 하지 않았습니다. 유형 최적화 최적화 매개변수. 각 기준에 대한 범위와 단계, 경계 유형 및 필터 모드를 선택하고 최적화를 시작합니다. 한 번 보는 게 낫지...
그것은 모든 것과 같습니다.
추신. "뭐야, 카운트 ... 웃을 일도 ..."(c) UmaTurman