글쎄, 조금 후에(2-3시간 후), 이익(또는 네트워크에서 얻고자 하는 것이 무엇이든 상관없이)이 피트니스 기능에 어떻게 의존하는지 합리적으로 보여주려고 노력할 것입니다. 그리고 물론 아무도 우리가 미래에 이익을 얻을 것이라고 보장할 수 없습니다. 그러나 그리드가 추구해야 하는 대상은 아마도 명확하게 정의해야 합니다.
약속대로 사진과 설명을 올립니다. 네트워크: MLP 하나의 히든 레이어. 훈련에서 2000 포인트. 1000 on out of sample) 첫 번째 사진의 EMA의 현재 및 사전 값과 첫 번째 및 두 번째 사진의 사전 마감이 입력으로 주어졌습니다. 모두! 왜 모든 것이 그렇게 작습니까? 네, 뉴런, 레이어, 입력 등의 수가 증가했기 때문입니다. 결과에 전혀 영향을 미치지 않습니다. 이것은 나를 두렵게 한다) 게다가, 예측으로 보여지는 것은 핸들로 간주되는 매우 간단한 공식에 의해 얻어질 수 있다. 왜 나에게 그렇게 불분명. 변경해야 할 사항은 무엇입니까? 더 잘 할 수 있습니까?
약속대로 사진과 설명을 올립니다. 네트워크: MLP 하나의 히든 레이어. 훈련에서 2000 포인트. 샘플 외에서 1000) 입력은 첫 번째 사진의 현재 및 pre-EMA 값과첫 번째 및 두 번째 사진의 사전 마감 이었습니다. 모두! 왜 모든 것이 그렇게 작습니까? 네, 뉴런, 레이어, 입력 등의 수가 증가했기 때문입니다. 결과에 전혀 영향을 미치지 않습니다. 이것은 나를 두렵게 한다) 게다가, 예측으로 보여지는 것은 핸들로 간주되는 매우 간단한 공식에 의해 얻어질 수 있다. 왜 나에게 그렇게 불분명. 변경해야 할 사항은 무엇입니까? 더 잘 할 수 있습니까?
근사 문제를 설명했습니다. 두 개의 "참조" 포인트로는 양식을 설명하기에 충분하지 않습니다. 또한 곡률뿐만 아니라 직선을 설명하는 가까운 점을 하나 더 제공합니다. 각 입력 세트에서 최소 3점을 시도하십시오. 저것들. 3개의 EMA 포인트와 3개의 클로즈 포인트, 그리고 총 6개의 입력 뉴런, 은닉층에서 6~12개 뉴런. 은닉층에 더 많은 수의 뉴런이 있는 것은 이 작업에 적합하지 않습니다.
처음에 나는 첫 번째 차트와 두 번째 차트에서 마지막 닫기 40개와 첫 번째 차트에서 oma 값 40개를 제공했습니다. 결과는 거의 동일합니다! 그는 복근 대신 % 증분을 주었습니다. 똑같은 것입니다! 그 차이는 100분의 1%에 불과합니다. 최종 '예측'이 더 매끄러웠지만 차이를 느끼지 못했다면. 출력에서 가져와야 하는 EMA 사전 값 중 하나를 제출할 수 있습니다. 이 경우 예측은 100%입니다. 기억하시겠지만 EMA 공식은 반복적이지만 이 경우에는 네트워크가 필요하지 않습니다.))))) 그래서 나는 그것이 무엇인지, 어디가 틀렸는지 이해할 수 없습니다.
mrstock>> : Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
동의한다. 그래서 나는 오류와 이익 사이의 관계가 무엇인지 물었습니다. 가급적이면 OOS에서 ....)))
너무주님은 데이터 정규화로 인한 결과일 수 있다고 말씀하셨는데 저는 그렇지 않다고 답했습니다.
추신 오차 기준이 항상 최종 수익을 결정하는 것은 아니라는 레오의 말에는 동의하지만, 지금 내가 직면한 과제에서 중요한 것은 오차입니다. 어제는 예보의 질과 가능한 개선점에 대해 다른 분들의 의견을 알아보기 위해 그리드에서 작성한 예보를 포스팅하겠습니다.)
글쎄, 조금 후에(2-3시간 후), 이익(또는 네트워크에서 얻고자 하는 것이 무엇이든 상관없이)이 피트니스 기능에 어떻게 의존하는지 합리적으로 보여주려고 노력할 것입니다.
그리고 물론 아무도 우리가 미래에 이익을 얻을 것이라고 보장할 수 없습니다. 그러나 그리드가 추구해야 하는 대상은 아마도 명확하게 정의해야 합니다.
때문에 시간을 낭비할 수 없습니다. "원하다"와 "얻다" 사이의 차이는 비록 그것이 "주관적"과 "객관적"이라는 철학적 개념에 의해 공식화되었지만 전혀 철학적이지 않습니다.
피팅 결과가 평균 제곱근 오차에 반비례한다는 사실은 우리가 당신 없이 알고 있는 것입니다.
확실히 그리드는 OOS에서 이익을 위해 노력해야 합니다. 그렇지 않으면 아무 의미가 없습니다.
피팅 결과가 평균 제곱근 오차에 반비례한다는 사실은 우리가 당신 없이 알고 있는 것입니다.
평균 제곱 오차도 사용하고 있습니까? 당신은 emcuel 네트워크의 아버지입니다. :)
레셰토프 가 쓴 >>
확실히 그리드는 OOS에서 이익을 위해 노력해야 합니다. 그렇지 않으면 아무 의미가 없습니다.
이것은 당연합니다. 또 다른 질문은 그녀가 이것을 위해 어떻게 노력해야 하는지입니다.
평균 제곱 오차도 사용하고 있습니까? 당신은 emcuel 네트워크의 아버지입니다. :)
이것은 당연합니다. 또 다른 질문은 그녀가 이것을 위해 어떻게 노력해야 하는지입니다.
거래의 경우 제곱 평균 제곱근 오차를 사용하지 않습니다. 핏의 품질만을 특징짓습니다.
따라서 표본 오차는 다음과 같은 경향이 있어서는 안 됩니다.
약속대로 사진과 설명을 올립니다. 네트워크: MLP 하나의 히든 레이어. 훈련에서 2000 포인트. 1000 on out of sample) 첫 번째 사진의 EMA의 현재 및 사전 값과 첫 번째 및 두 번째 사진의 사전 마감이 입력으로 주어졌습니다. 모두! 왜 모든 것이 그렇게 작습니까? 네, 뉴런, 레이어, 입력 등의 수가 증가했기 때문입니다. 결과에 전혀 영향을 미치지 않습니다. 이것은 나를 두렵게 한다) 게다가, 예측으로 보여지는 것은 핸들로 간주되는 매우 간단한 공식에 의해 얻어질 수 있다. 왜 나에게 그렇게 불분명. 변경해야 할 사항은 무엇입니까? 더 잘 할 수 있습니까?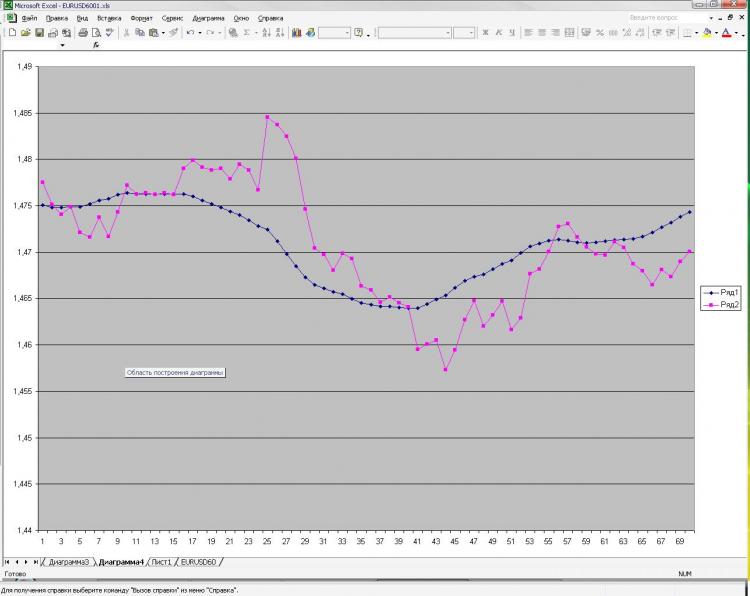
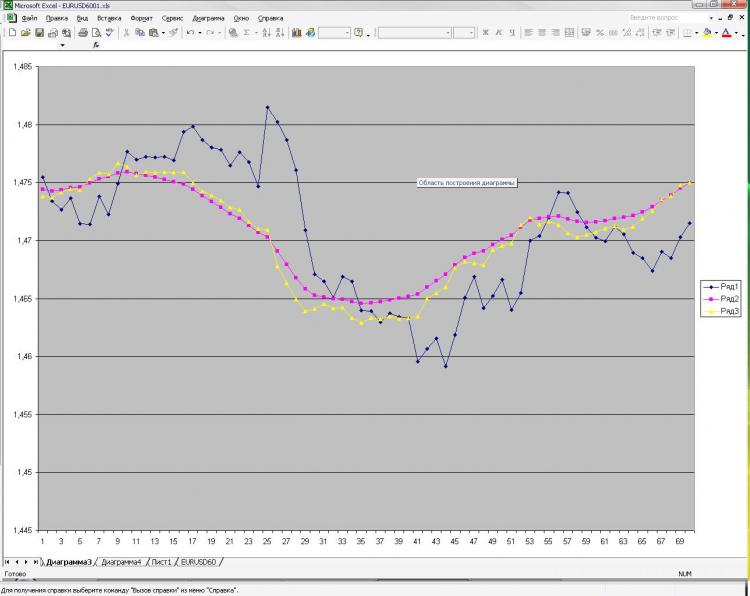
약속대로 사진과 설명을 올립니다. 네트워크: MLP 하나의 히든 레이어. 훈련에서 2000 포인트. 샘플 외에서 1000) 입력은 첫 번째 사진의 현재 및 pre-EMA 값과 첫 번째 및 두 번째 사진의 사전 마감 이었습니다. 모두! 왜 모든 것이 그렇게 작습니까? 네, 뉴런, 레이어, 입력 등의 수가 증가했기 때문입니다. 결과에 전혀 영향을 미치지 않습니다. 이것은 나를 두렵게 한다) 게다가, 예측으로 보여지는 것은 핸들로 간주되는 매우 간단한 공식에 의해 얻어질 수 있다. 왜 나에게 그렇게 불분명. 변경해야 할 사항은 무엇입니까? 더 잘 할 수 있습니까?
근사 문제를 설명했습니다. 두 개의 "참조" 포인트로는 양식을 설명하기에 충분하지 않습니다. 또한 곡률뿐만 아니라 직선을 설명하는 가까운 점을 하나 더 제공합니다. 각 입력 세트에서 최소 3점을 시도하십시오. 저것들. 3개의 EMA 포인트와 3개의 클로즈 포인트, 그리고 총 6개의 입력 뉴런, 은닉층에서 6~12개 뉴런. 은닉층에 더 많은 수의 뉴런이 있는 것은 이 작업에 적합하지 않습니다.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
여기에서 샘플링해 보겠습니다. Statistica에서 시도하겠습니다.