문제는 우리가 앞으로 한 막대가 아니라 여러 막대에 대한 예측을 보고 싶어한다는 것입니다(음, 가격 움직임의 장기적 "추세"를 보기 위해). 모든 예측 수치는 다음 막대에 대해서만 계산하여 계산됩니다. 후속 수치의 경우 입력에 아직 없는 초기 데이터를 제공해야 합니다(결국 예측). 예측을 확인하기 위해 기존 데이터를 사용하는 경우(예: 얼마나 정확하게 예측했는지 확인) 초기 데이터를 입력으로 사용하여 미래에 막대의 값을 계산할 수 있습니다(현재+1, 현재+2, 현재 +3, .....) 역사에서 우리에게 알려진 것, 즉 암묵적으로 우리는 우리가 알지 못하고 더 많이 예측하고 싶은 미래를 들여다봅니다.
요약하면: 정직한 예측을 얻으려면 예측의 이전 단계에서 계산된 값이 예측 막대를 계산할 때 입력을 대체해야 합니다. 즉, 첫 번째 예측 값은 마지막으로 알려진 라이브 데이터에서 계산됩니다. 다음 값은 이전(첫 번째 계산) 값에서 계산되는 식입니다. 그리고 이 모든 후에야 데이터가 실제 과거 데이터와 비교됩니다.
알려진 OHLC에서 MA 값을 예측하는 조건부 문제를 취하면 앞의 여러 막대에 대해 올바르게 풀 수 없습니다. 다음 MA 값을 하나만 계산하고 두 번째 예측 MA 값을 계산하려면 없는 막대에서 새 OHLC를 입력해야 합니다. ). '검증' 이력에서 OHLC를 빼면 미래를 내다봤다는 의미다. 여기가 갈퀴가 있는 곳입니다 :(
공제액에는 새로운 것이 없습니다. 1976년에 Box는 이론을 제시했고 80년대 초반에 STATISTICA 패키지가 개발되어 오늘날에도 여전히 사용됩니다. 이 패키지에서 시계열 분석의 목적은 시계열을 예측하는 것입니다. 그것을 보면, 이 패키지(deductor와 같은)는 추세의 지속을 잘 예측하여 VR 시리즈를 노이즈에서 제거하고 계절적 사이클을 고려합니다. 문제는 예측 방법에 있는 것이 아니라 이 모든 것이 고정된 VR에서만 작동하고 VR 시리즈가 고정되어 있지 않다는 사실입니다. 따라서 예측은 추세의 연속으로만 신뢰할 수 있습니다. 반전은 예측할 수 없으며 예측 추세에는 문제가 없습니다.
내 예측을 공제액에서 잠시 짜내면 존경합니다.
나는 30 분 미만으로 접착되지 않았습니다.
공제액에 대한 경험치:
고맙습니다.
전문가가 언급하는 Exp.ded 스크립트를 여기에 배치하거나 비밀 스터핑 없이 최소한 이 스크립트의 "더미"를 배치할 수 있습니까?
아카이브에는 스크립트, 공제자 파일, 텍스트 파일이 포함되어 있습니다. M1 기간의 EURUSD 예측, 슬라이딩 윈도우 2200 닫기.
일반적으로 이 아카이브의 스크립트를 Expert Advisor에 첨부했습니다(다시 한 번 Zar에게 감사드립니다). 그리고 저는 이 신비한 사진을 얻었습니다.
무슨 뜻인가요?
내 예측을 공제액에서 잠시 짜내면 존경합니다.
나는 30 분 미만으로 접착되지 않았습니다.
예, 나는 나쁜 예측 때문에 공제자를 그만 뒀지만 여기에는 길을 잃지 않기 위해 나 자신을 위해 오래된 개발을 게시합니다. 아마도 언젠가는 더 많이 운전할 것입니다 ...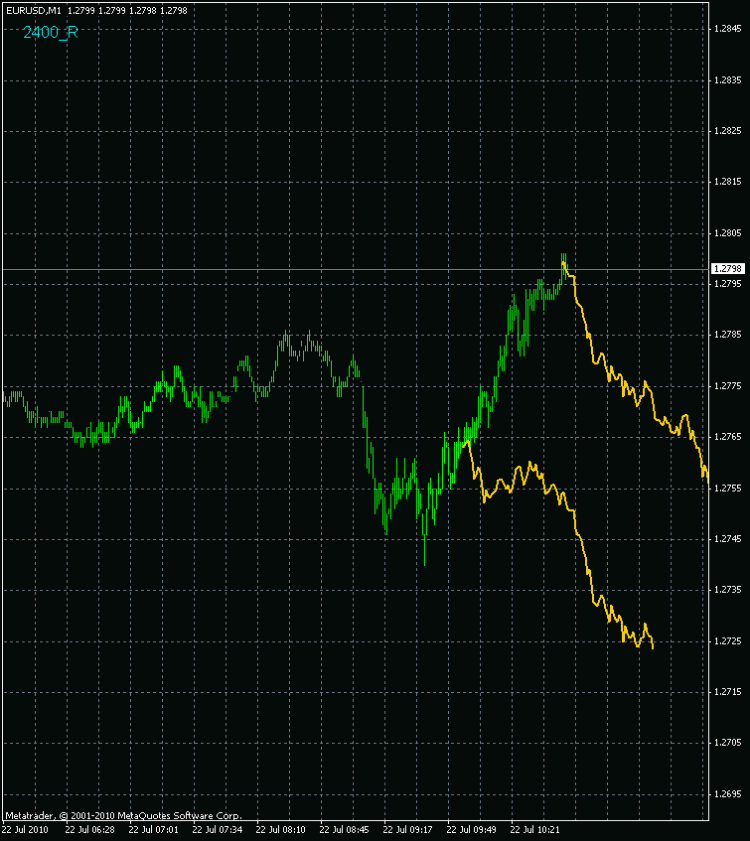
나는 s2200_Close를 다시 확인했는데 작동합니다 :)
새 데이터에 대한 재교육에는 거의 1시간이 걸립니다. :)
또 다른 옵션: 각각 40초씩 6개 시간 프레임으로 차례로 분석
s600_닫습니다.
마지막 옵션: 8 HCL 기간을 기반으로 한 분석
s7_m1, M1에서 W1까지 데이터 입력(High Close Low)
당신은 분명히 문제의 요점을 이해하지 못합니다 ;)
문제는 우리가 앞으로 한 막대가 아니라 여러 막대에 대한 예측을 보고 싶어한다는 것입니다(음, 가격 움직임의 장기적 "추세"를 보기 위해). 모든 예측 수치는 다음 막대에 대해서만 계산하여 계산됩니다. 후속 수치의 경우 입력에 아직 없는 초기 데이터를 제공해야 합니다(결국 예측). 예측을 확인하기 위해 기존 데이터를 사용하는 경우(예: 얼마나 정확하게 예측했는지 확인) 초기 데이터를 입력으로 사용하여 미래에 막대의 값을 계산할 수 있습니다(현재+1, 현재+2, 현재 +3, .....) 역사에서 우리에게 알려진 것, 즉 암묵적으로 우리는 우리가 알지 못하고 더 많이 예측하고 싶은 미래를 들여다봅니다.
요약하면: 정직한 예측을 얻으려면 예측의 이전 단계에서 계산된 값이 예측 막대를 계산할 때 입력을 대체해야 합니다. 즉, 첫 번째 예측 값은 마지막으로 알려진 라이브 데이터에서 계산됩니다. 다음 값은 이전(첫 번째 계산) 값에서 계산되는 식입니다. 그리고 이 모든 후에야 데이터가 실제 과거 데이터와 비교됩니다.
알려진 OHLC에서 MA 값을 예측하는 조건부 문제를 취하면 앞의 여러 막대에 대해 올바르게 풀 수 없습니다. 다음 MA 값을 하나만 계산하고 두 번째 예측 MA 값을 계산하려면 없는 막대에서 새 OHLC를 입력해야 합니다. ). '검증' 이력에서 OHLC를 빼면 미래를 내다봤다는 의미다. 여기가 갈퀴가 있는 곳입니다 :(
공제액에는 새로운 것이 없습니다. 1976년에 Box는 이론을 제시했고 80년대 초반에 STATISTICA 패키지가 개발되어 오늘날에도 여전히 사용됩니다. 이 패키지에서 시계열 분석의 목적은 시계열을 예측하는 것입니다. 그것을 보면, 이 패키지(deductor와 같은)는 추세의 지속을 잘 예측하여 VR 시리즈를 노이즈에서 제거하고 계절적 사이클을 고려합니다. 문제는 예측 방법에 있는 것이 아니라 이 모든 것이 고정된 VR에서만 작동하고 VR 시리즈가 고정되어 있지 않다는 사실입니다. 따라서 예측은 추세의 연속으로만 신뢰할 수 있습니다. 반전은 예측할 수 없으며 예측 추세에는 문제가 없습니다.