implements the Hidden Markov Models (HMMs). The HMM is a generative probabilistic model, in which a sequence of observable variables is generated by a sequence of internal hidden states . The hidden states are not observed directly. The transitions between hidden states are assumed to have the form of a (first-order) Markov chain. They can be...
누군가가 HMM을 이해한다면 문제 해결에 도움을 요청하고 문제를 해결하면 성배를 공유하겠습니다)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0% B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5 %D0%BB%D1%8C-흠-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0 %B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0% BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
누군가 HMM을 이해한다면 문제 해결에 도움을 요청하고 문제를 해결하면 성배를 공유하겠습니다)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0% B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5 %D0%BB%D1%8C-흠-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0 %B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0% BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
글쎄, 상태는 Markovian이지만 어떤 모델입니까? 표 방법 또는 무엇
그래서 당신은 sk에 대한 더 많은 포인트가 필요합니다. 적어도 창
무작위 시리즈가 주어지면 50/50 외에 어떤 종류의 예측에 대해 이야기할 수 있습니까?그래서 당신은 sk에 대한 더 많은 포인트가 필요합니다. 적어도 창
그는 심지어 수천 점을 취했다고 썼다.
무작위 시리즈가 주어지면 50/50 외에 어떤 종류의 예측에 대해 이야기할 수 있습니까?
차이점이 무엇인지, 데이터는 동일하고, 모델은 동일합니다.
나는 전체 패키지의 기능을 통해 새로운 데이터 를 예측합니다 (인터넷의 모든 예에서 등 ...) 결과는 훌륭합니다
동일한 모델을 사용하여 동일한 데이터 를 예측하지만 슬라이딩 윈도우에서 결과가 다르고 수용할 수 없습니다.
그것과 실제로 질문에서 - 그게 무슨 문제입니까?그는 심지어 수천 점을 취했다고 썼다.
차이점이 무엇인지, 데이터는 동일하고, 모델은 동일합니다.
나는 전체 패키지의 기능을 통해 새로운 데이터 를 예측합니다 (인터넷의 모든 예에서 등 ...) 결과는 훌륭합니다
동일한 모델을 사용하여 동일한 데이터 를 예측하지만 슬라이딩 윈도우에서 결과가 다르고 수용할 수 없습니다.
그것과 실제로 질문에서 - 그게 무슨 문제입니까?어떤 종류의 모델과 상태를 가져오는지 명확하지 않습니다. 어떤 꾸러미도 없이 개념적으로 씻겨진 것
아마 랜덤으로 나오지 않는 rng가 있어서 1번의 경우에 예측한 것 같다. 기차의 시드를 변경하고 첫 번째 경우에 아무것도 예측할 수 없는지 확인하기 위해 테스트를 시도하십시오. 그렇지 않으면 아이디어가 어떻게 도움이 될지 명확하지 않습니다.
분류 확률에 따라 분할됩니다. 더 정확하게는 확률이 아니라 분류 오류입니다. 왜냐하면 모든 것이 훈련 계정에 알려져 있으며 우리는 확률이 아니라 정확한 추정치를 가지고 있습니다.
다른 분할 기능이 있지만, 즉. 불순물 측정(왼쪽 또는 오른쪽에 있는 샘플).
나는 지금처럼 전체가 아니라 표본에 대한 분류 정확도의 분포를 의미했습니다.
어떤 종류의 모델과 상태를 가져오는지 명확하지 않습니다. 어떤 꾸러미도 없이 개념적으로 씻겨진 것
아마 랜덤으로 나오지 않는 rng가 있어서 1번의 경우에 예측한 것 같다. 기차의 시드를 변경하고 첫 번째 경우에 아무것도 예측할 수 없는지 확인하기 위해 테스트를 시도하십시오. 그렇지 않으면 아이디어가 어떻게 도움이 될지 명확하지 않습니다.
다음은 예측 변수 "data1" 및 "data2"가 있는 가격과 두 개의 열이 있는 파일입니다.
파이썬에서 이 두 열("data1" 및 "data2")에 대해 두 가지 상태(교사가 없는 데이터 트레인에서) 만 있는 HMM을 가져오고 훈련하거나 원하는 곳 어디에서나 가격을 전혀 건드리지 않고 단지 그런 다음 시각화를 위해서만
그런 다음 Viterbi 알고리즘을 사용하여 (데이터 테스트)
우리는 두 가지 상태를 얻습니다. 다음과 같이 보일 것입니다.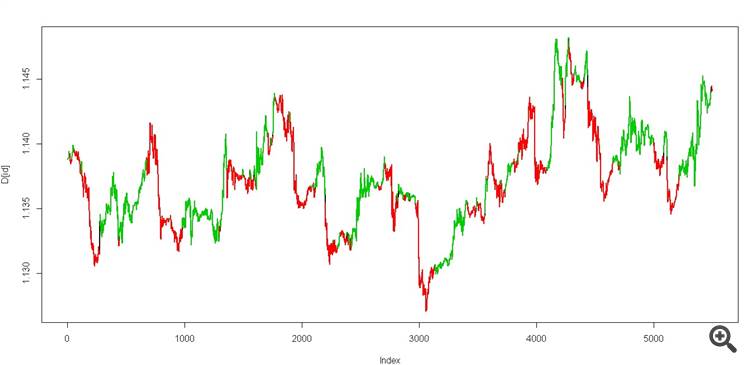
카록 성배 리얼))
그런 다음 동일한 Viterbi를 사용하여 동일한 데이터의 슬라이딩 창에서 계산합니다.
다음은 예측 변수 "data1" 및 "data2"가 있는 가격과 두 개의 열이 있는 파일입니다.
파이썬에서 이 두 열("data1" 및 "data2")에 대해 두 가지 상태(데이터 트레인에서) 만 있는 HMM을 가져오고 훈련하거나 원하는 곳 어디에서나 가격을 전혀 건드리지 않고 다음에 대해서만 심상
그런 다음 Viterbi 알고리즘을 사용하여 (데이터 테스트)
우리는 두 가지 상태를 얻습니다. 다음과 같이 보일 것입니다.
카록 성배 리얼))
그런 다음 동일한 Viterbi를 사용하여 동일한 데이터의 슬라이딩 창에서 계산합니다.
senk, pozyryu che 네 나중에, 구독 취소, tk. 나는 마르코프와 함께 일한다
senk, pozyryu che 네 나중에 구독 취소하겠습니다, tk. 나는 마르코프와 함께 일한다
어떻게 지내세요?
어떻게 지내세요?
아직 안봤어 쉬는날) 시간나면 끄적여, 이따 이번주 의미로
보는 동안 패키지. https://hmmlearn.readthedocs.io/en/latest/tutorial.html 이 할 것이라고 생각합니다.