Оценка статистических параметров последовательности очень важна, так как большинство математических моделей и методов строятся исходя из различного рода предположений, например, о нормальности закона распределения, или требуют знания значения дисперсии или других параметров. В статье кратко рассматриваются простейшие статистические параметры случайной последовательности и некоторые методы ее визуального анализа. Предлагается реализация этих методов на MQL5 и способ визуализации результатов расчета при помощи программы Gnuplot.
# load data
fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv'
, sep= ','
, header = T
, na.strings = 'NULL')
fx_dat <- subset(fx_data, Volume > 0)
# create open price returns
dat_return <- diff(x = fx_dat[, 2], lag = 1)
# check summary for the returns
summary(dat_return)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
# generate random normal numbers with parameters of original data
norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return))
#check summary for generated data
summary(norm_generated)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03
# test normality of original data
shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)])
Shapiro-Wilk normality test
data: dat_return[sample(length(dat_return), 4999, replace = F)]
W = 0.86826, p-value < 2.2e-16
# test normality of generated normal data
shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)])
Shapiro-Wilk normality test
data: norm_generated[sample(length(norm_generated), 4999, replace = F)]
W = 0.99967, p-value = 0.6189
####### quantiles
hour1_quantiles <- data.frame()
counter <- 1for (i in seq(from = 0.05, to = 0.95, by = 0.05)){
hour1_quantiles[counter, 1] <- i
hour1_quantiles[counter, 2] <- quantile(dat_return, probs = i)
counter <- counter + 1
}
colnames(hour1_quantiles) <- c(
'probability'
, 'value'
)
plot(hour1_quantiles$value, type = 's')
#View
hour1_quantiles
probability value10.05 -0.002537520.10 -0.001660030.15 -0.001210040.20 -0.000900050.25 -0.000680060.30 -0.000505070.35 -0.000360080.40 -0.000230090.45 -0.0001100100.500.0000000110.550.0001100120.600.0002400130.650.0003700140.700.0005100150.750.0006900160.800.0009100170.850.0012100180.900.0016600190.950.0025300
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')
## what is absolute statistics of hourly returns?
summary(abs(dat_return))
Min. 1 st Qu. Median Mean 3 rd Qu. Max.
0.0000000.0003000.0006900.0010970.0014200.068490
そして、私の魂は、正規分布とされる漸増引用符のテーマを掘り下げたいと思い続けている。
もし賛成してくれる人がいたら、なぜこのプロセスが正常でないのか、論拠を示すことにしよう。そして、これらの主張は、CPTとの整合性を図りながら、誰にでも理解できるものとなるのです。そして、これらの議論は、疑いようのないほど些細なものです。
そして、確率が表すものは、次のバーの予測なのか、次のバーの動きベクトルなのか、どちらなのでしょうか。
確率は、次のティック(増分)の予測を表します。ただ、そうしたいだけなんです。
- ベイズ式による確率が最大となる将来の Ybayes tick の値を算出する。
- Ybayesと実際に入ってくるYrealのティックを比較する .統計情報の収集と処理.
もし値の差が妥当な範囲であれば、コードを投稿し、次に何をすべきかを尋ねます。回帰?ベクター?スキャルピング?
確率は次のティック(増分)の予測値を表します。ただ、そうしたいだけなんです。
なぜダニになるのか?5分で70%の精度でティック方向を予測できるようになったとしても、100ティック先では精度が落ちるのは目に見えています。
30分前、1時間前と小刻みに試してみてください。私も興味深いので、何かお手伝いできることがあるかもしれません。
確率は次のティック(増分)の予測値を表します。ただ、そうしたいだけなんです。
- ベイズ式による確率が最大となる将来の Ybayes tick の値を算出する。
- イバイエと実際に入荷したイリアルティックを比較する .統計情報の収集と処理.
値の差が妥当な範囲であれば、コードを掲載して、次にどうすればいいか聞いてみます。回帰?ベクター? カーブ?スキャルピング?
ARIMAの何が問題なのか?パッケージでは、入力ストリームに応じて差分数(増分)が自動的に計算されます。パッケージの中には、定常性に関連する多くの微妙な要素が隠されています。
本当にそこまでやるなら、どこかのARCH?
一度試したことがあるんです。問題はこれだ。増分は簡単に計算できます。しかし、この増分の信頼区間を 増分自体に加えると、前の価格値が信頼区間の中に入るので、BUYかSELLのどちらかになってしまうのです。
そう、SanSanychが書いているように、古典的なアプローチは、データ分析、データ要件、そしてシステムエラーである。
しかし、このスレッドはベイズについてであり、私は塹壕の中の兵士が事後(経験後)確率を計算するように、ベイズ的に考えようとしているのである。上記で兵士の例を挙げました。
何をもって先験的な確率とするかは、大きな問題の一つである。つまり、ゼロバーの右側、未来のカーテンの向こうに誰を置くべきか。ガウス?ラプラス?ウィンナー?プロの数学者はここに何を書いているのだろう(私にとっては暗い「森」)。
ガウスを選んだのは、正規分布のイメージがあり、それを信じているからです。もし「撃てない」のであれば、ベイズの公式の代わりに他の法則をとってガウスに置き換えるか、ガウスと合わせて2つの確率の積とすることが可能です。私の理解が正しければ、ベイジアンネットワークを作ってみてください。
当然、私一人の力ではどうにもなりません。花束の下で定式化したガウスで問題を解きたいと思います。 有志で参加してくれる人がいれば、よろしくお願いします。ここで、実際の問題を紹介します。
所与:МТ4個の乱数発生器。
必要なもの:関数FP()としてMQL4コードを書き、標準RNGによって形成されたMT4[]配列を正規分布のND[]配列に変換する。
Vasily (私の姓は知らない) Sokolovは、https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/、私に変換式を見せてくれました。
利他と親切は、計算された配列のチャートをMT4のウィンドウで直接拡大できるのですが、その結果をグラフィックで表現します。 私のプロジェクトでは、それをやっていたのです。
しかし、私は、トレーダー、プログラマー、経済学者、哲学者が共通して理解する言語であるMQL4で話をしたいのです。
そう、SanSanychが書いているように、古典的なアプローチは、データ分析、データ要件、そしてシステムエラーである。
しかし、このスレッドはベイズについてであり、私は塹壕の中の兵士が事後(経験後)確率を計算するように、ベイズ的に考えようとしているのである。上記で兵士の例を挙げました。
何をもって先験的な確率とするかは、大きな問題の一つである。つまり、ゼロバーの右側、未来のカーテンの向こうに誰を置くべきか。ガウス?ラプラス?ウィンナー?プロの数学者はここに何を書いているのだろう(私にとっては暗い「森」)。
ガウスを選んだのは、正規分布のイメージがあり、それを信じているからです。もし「撃てない」のであれば、ベイズの公式の代わりに他の法則をとってガウスに置き換えるか、ガウスと合わせて2つの確率の積とすることが可能です。私の理解が正しければ、ベイジアンネットワークを作ってみてください。
当然、私一人の力ではどうにもなりません。花束の下で定式化したガウスで問題を解きたいと思います。 有志で参加してくれる人がいれば、よろしくお願いします。ここで、実際の問題を紹介します。
所与:МТ4個の乱数発生器。
必要性:標準RNGによって形成されたMT4[]配列を正規分布のND[]配列に変換する関数FP()としてMQL4コードを記述する。
Vasily (私の姓は知らない) Sokolovは、https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/、私に変換式を見せてくれました。
しかし、私は計算された配列のチャートを直接MT4のウィンドウで再スケールすることができます。 私は私のプロジェクトでそれを行っていました。
多くのトレーダーは、数学的なパッケージを使えば数クリックでこの問題を解決できるかもしれませんが、私は、トレーダー、プログラマー、経済学者、哲学者が一般的にアクセスできるMQL4言語を使いたいと思っています。
ここでは、正規分布を含むさまざまな分布を持つジェネレータを紹介します。
https://www.mql5.com/ru/articles/273
Rによる簡単な分布解析。
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189利用可能なクロックバーの始値刻みから正規分布のパラメータを推定し、元の系列と同じ分布の正規系列について頻度と密度を比較するためにプロットした。目で見てもわかるように、元の時棒の増分の系列は正常とは言い難い。
ちなみに、私たちは神の神殿の中にいるわけではありません。信じる必要はなく、有害でさえある。
ここで、上記の投稿の中から、私が上に書いたことと呼応する不思議な一節を紹介します。
-2.515e-02-6.800e-04 0.000e+00 -3.400e-076.900e-04 6.849e-02
クワドラントで理解する限り、オクロックの増分は全体の50%が7ピップス以下なのですそして、よりまともな増分は、太い尾の部分、つまり善悪の反対側にあるのです。
では、TSはどのようなものになるのでしょうか。それが問題なのであって、ベイスターズとか、その他、その他、その他...ではない。
それとも別の意味で理解すべきなのでしょうか?
ここで、上記の投稿の中から、私が上に書いたことと呼応する不思議な一節を紹介します。
-2.515e-02-6.800e-04 0.000e+00 -3.400e-076.900e-04 6.849e-02
クワドラントで理解する限り、1時間足の全増幅の50%が7pips以下ですそして、よりまともな増分は、太い尾の部分、つまり善悪の反対側にあるのです。
では、TSはどのようなものになるのでしょうか。それが問題なのであって、ベイスターズとか、その他、その他、その他...ではない。
それとも別の意味で理解すべきなのでしょうか?
SanSanychさん、そうなんです!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')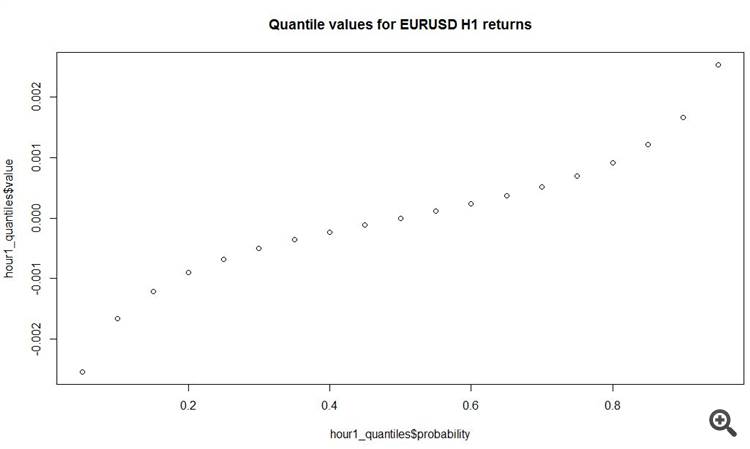
そしてもう一つ面白いのは、1時間足の平均絶対増分が11ピップスであることです!これは、1時間足の平均増分が11ピップスであることを意味します。合計
再変換が必要なので、長く作る必要がありますし...。そして、箱○はあまり好きではありません))))がないと残念なことになります。
ただ、普通の予想屋がいないと、結局あまり効果がないのが残念ですが...。